此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第五课的第三周内容,与 CV 相对应的,这一课所有内容的中心只有一个:自然语言处理(Natural Language Processing,NLP) 。
应用在深度学习里,它是专门用来进行文本与序列信息建模 的模型和技术,本质上是在全连接网络与统计语言模型基础上的一次"结构化特化",也是人工智能中最贴近人类思维表达方式 的重要研究方向之一。
这一整节课同样涉及大量需要反复消化的内容,横跨机器学习、概率统计、线性代数以及语言学直觉。
语言不像图像那样"直观可见",更多是抽象符号与上下文关系的组合,因此理解门槛反而更高 。
因此,我同样会尽量补足必要的背景知识,尽可能用比喻和实例降低理解难度。
本周的内容关于序列模型和注意力机制 ,这里的序列模型其实是指多对多非等长模型,这类模型往往更加复杂,其应用领域也更加贴近工业和实际,自然也会衍生相关的模型和技术。而注意力机制则让模型在长序列中学会主动分配信息权重,而不是被动地一路传递。二者结合,为 Transformer 等现代架构奠定了基础。
本篇的内容关于注意力机制,这是如今 NLP 乃至整个深度学习领域的核心技术之一。
1.注意力机制的思想
1.1 传统编码解码框架的局限
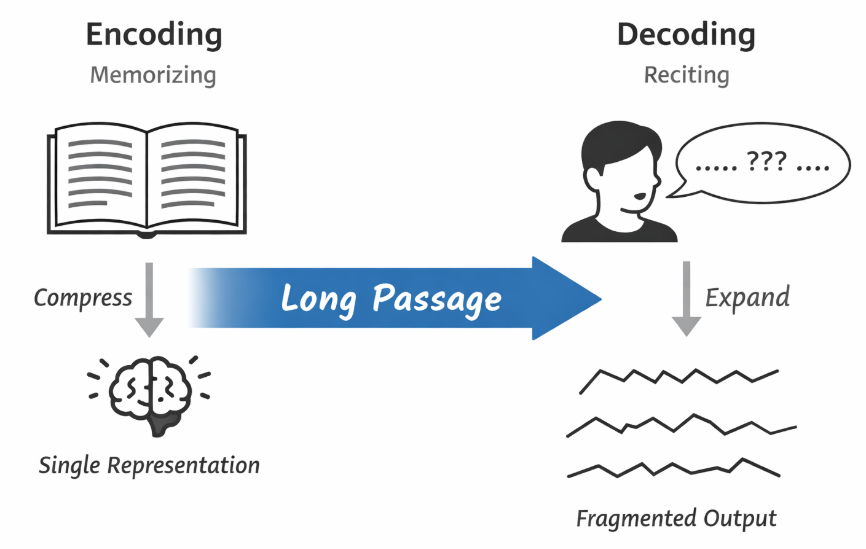
在前面的编码解码架构中我们已经了解到: 编码器的任务是将整个输入序列映射为一个固定长度的向量表示,而解码器则在此基础上逐步生成输出序列。
也就是说,无论编码器采用的是 RNN、LSTM 还是 GRU,其最终都需要将长度可变的输入序列压缩为一个定长表示 。
这种设计在形式上简洁,但在实际使用中很快暴露出一个问题,我们称之为 信息瓶颈(information bottleneck) 。
即当输入序列较长、结构较复杂时,这种"整体压缩---再逐步解码"的方式不可避免地会丢失细节信息,且这种损失会随着序列长度增长而被放大。
这不难理解,对比来说,就像我们去背课文,编码就是记忆的过程,而解码就是背诵的结果。显然,要背的内容越长,复述起来就越困难。
并且,这一框架仍存在我们之前在预测任务中提到过的问题:解码器在生成每一个输出词时,使用的是整句内容,但在机器翻译这类任务中,不同输出位置所依赖的输入信息显然是不同的。
例如,在生成目标语言中的某个名词时,真正相关的往往只是源语言中的局部片段,而非整句语义的表示结果。
正是在这一背景下,注意力机制被提出,其开创性工作在 2014 年发表的论文:Neural Machine Translation by Jointly Learning to Align and Translate。论文首次在编码解码框架中显式引入"对齐(alignment)"的概念,使解码器在每一个时间步都可以动态地从输入序列中选择相关信息,而不再依赖单一的全局向量表示。
1.2 注意力机制与 LSTM / GRU
在正式介绍注意力机制之前,有必要先进行一点概念上的澄清。
在刚刚的讨论中我们提到,注意力机制的核心作用在于:使解码器在每一个时间步,都可以动态地从输入序列中选择与当前输出相关的局部信息。
乍一看,这一点似乎与我们此前在门控机制中介绍的 LSTM、GRU 的思想十分相似:它们都针对长序列情况,并同样强调对信息的保留与遗忘。
但事实上,二者解决的是不同层面的问题。
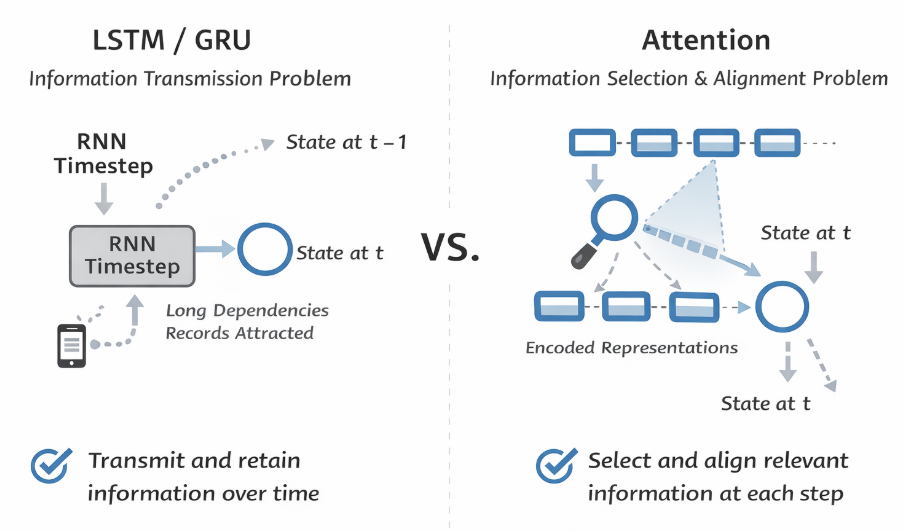
首先,LSTM 与 GRU 关注的是单个序列在时间维度上的状态传递问题 :在标准 RNN 中,隐藏状态需要在时间步之间不断递推,长距离依赖往往会在传播过程中被削弱甚至丢失。
门控机制正是为此而设计的:通过输入门、遗忘门或更新门,模型可以决定哪些历史信息应该被保留下来,哪些可以被丢弃。
因此,LSTM / GRU 回答的问题是:"当前时刻的隐藏状态,应该如何从过去的状态中更新而来?"
简单点说,它们的工作是:如何得到更好的信息。
相比之下,注意力机制关注的并不是"状态如何沿时间传播",而是已有信息如何被使用 。
在编码解码框架中,编码器已经生成了一整组隐藏状态,用于刻画输入序列在各个位置上的表示。
而注意力机制所做的,是在解码的每一个时间步,根据当前解码状态,在这组表示中显式建模输入与输出之间的关联关系,并据此对不同位置的信息进行聚合 。最终得到"对当前步的输出,哪些输入更有用 "。
总结一下:
- LSTM / GRU 解决的是信息如何在时间维度上传递与保存。
- 注意力机制解决的是在一组已有表示中,如何进行信息选择与对齐。
也正因如此,在注意力机制最初被提出时,它并不是用来取代 LSTM 或 GRU 的,而是叠加在它们之上使用。
了解了注意力机制的原理后,现在就来看看其实现:
2.注意力机制的实现
从整体上看,注意力机制并没有引入新的递推结构,也不改变原有的编码与解码流程,而是在解码的每一个时间步,引入了一次"基于当前状态的信息检索过程" 。
这一过程的核心思想可以概括为三步:
- 度量相关性:计算当前解码状态与输入序列中各个位置之间的匹配程度。
- 分配权重:将这些匹配程度归一化,得到一组注意力权重。
- 加权汇聚:根据权重,对输入表示进行加权求和,形成上下文向量。
下面我们依次展开:
2.1 对齐分数:如何度量"相关性"
首先,设编码器对输入序列产生了一组隐藏状态:
\\\{\\mathbf{a}\^{\<1\>}, \\mathbf{a}\^{\<2\>}, \\dots, \\mathbf{a}\^{\
其中 \(\mathbf{a}^{<i>}\) 表示输入序列在第 \(i\) 个位置上的编码表示 。
同样,对于解码器,在解码的第每一个时间步,同样会产生隐藏状态:
\\\{\\mathbf{s}\^{\<1\>}, \\mathbf{s}\^{\<2\>}, \\dots, \\mathbf{s}\^{\
\(\mathbf{s}^{<t>}\) 表示在解码的第 \(t\) 个时间步,解码器当前的隐藏状态 。
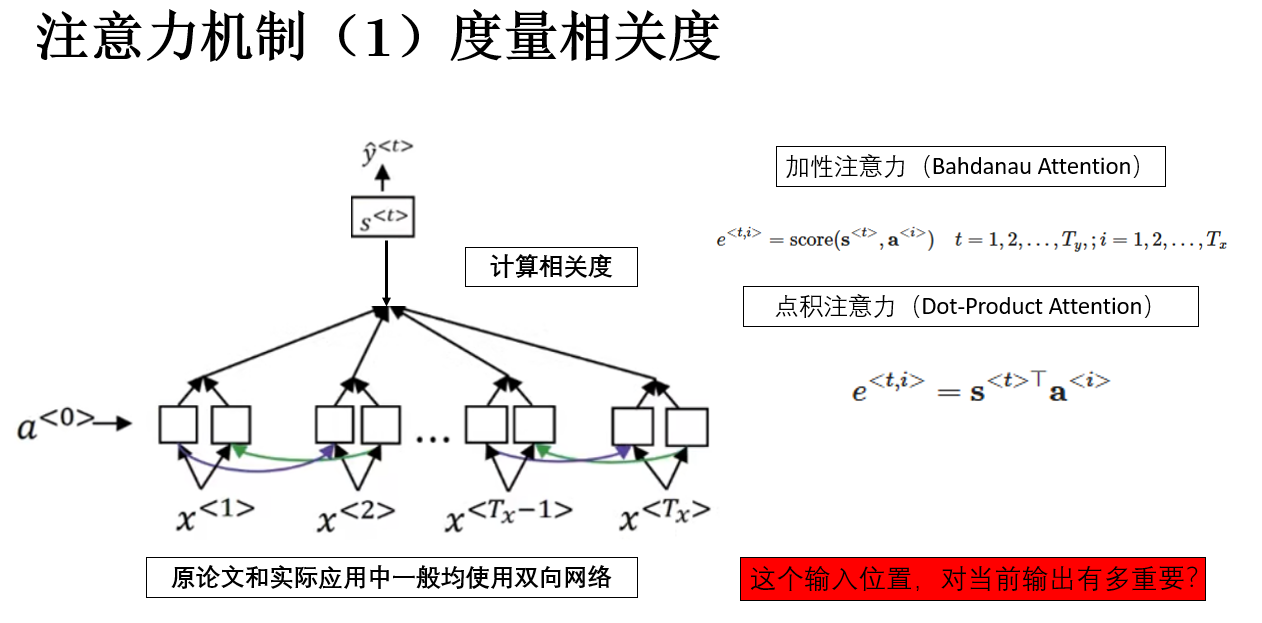
注意力机制的第一步,就是计算每一步解码与每一步编码之间的相关性分数,公式表示为:
\e\^{\
其中,\(T_y\) 是输出序列长度、\(T_x\) 是输入序列长度。
这个 score 函数的具体形式并不是唯一的,它只需要满足一个基本要求:能够反映当前输出状态与某个输入位置之间的匹配程度。
在原论文中,使用的是一个简单的前馈网络来完成这一部分:
\e\^{\
其中 \(\mathbf{W}_s, \mathbf{W}_a, \mathbf{v}\) 为可学习参数,\(\mathbf{v}\) 的作用是通过向量内积将网络输出的向量映射为一个标量分数,来量化表示"相关性"。
另一种更简单、计算效率更高的形式是直接使用向量内积:
\e\^{\
当解码器状态与某个输入位置的表示方向越接近,内积越大,对齐分数也就越高。
但无论采用哪一种形式,其语义都是一致的:这个输入位置,对当前输出有多重要?
来看一个实例:
假设输入序列长度 \(T_x=3\),输出序列长度 \(T_y=2\)。为了简化,用 二维向量表示隐藏状态:
- 编码器隐藏状态:
\ \\mathbf{a}\^{\<1\>} = \\begin{bmatrix}1 \\\\ 0\\end{bmatrix}, \\quad \\mathbf{a}\^{\<2\>} = \\begin{bmatrix}0 \\\\ 1\\end{bmatrix}, \\quad \\mathbf{a}\^{\<3\>} = \\begin{bmatrix}1 \\\\ 1\\end{bmatrix} \\
- 解码器第 1 个时间步隐藏状态:
\ \\mathbf{s}\^{\<1\>} = \\begin{bmatrix}0.8 \\\\ 0.2\\end{bmatrix} \\
- 解码器第 2 个时间步隐藏状态:
\ \\mathbf{s}\^{\<2\>} = \\begin{bmatrix}0.1 \\\\ 0.9\\end{bmatrix} \\
使用 点积注意力 计算对齐分数如下:
- 对 \(t=1\):
\ \\begin{aligned} e\^{\<1,1\>} \&= \[0.8, 0.2 \cdot 1,0 = 0.8 \\ e^{<1,2>} &= 0.8, 0.2 \cdot 0,1 = 0.2 \\ e^{<1,3>} &= 0.8, 0.2 \cdot 1,1 = 1.0 \end{aligned} \]
- 对 \(t=2\):
\ \\begin{aligned} e\^{\<2,1\>} \&= \[0.1, 0.9 \cdot 1,0 = 0.1 \\ e^{<2,2>} &= 0.1, 0.9 \cdot 0,1 = 0.9 \\ e^{<2,3>} &= 0.1, 0.9 \cdot 1,1 = 1.0 \end{aligned} \]
继续下一步:
2.2 转换注意力权重:从相关性到概率分布
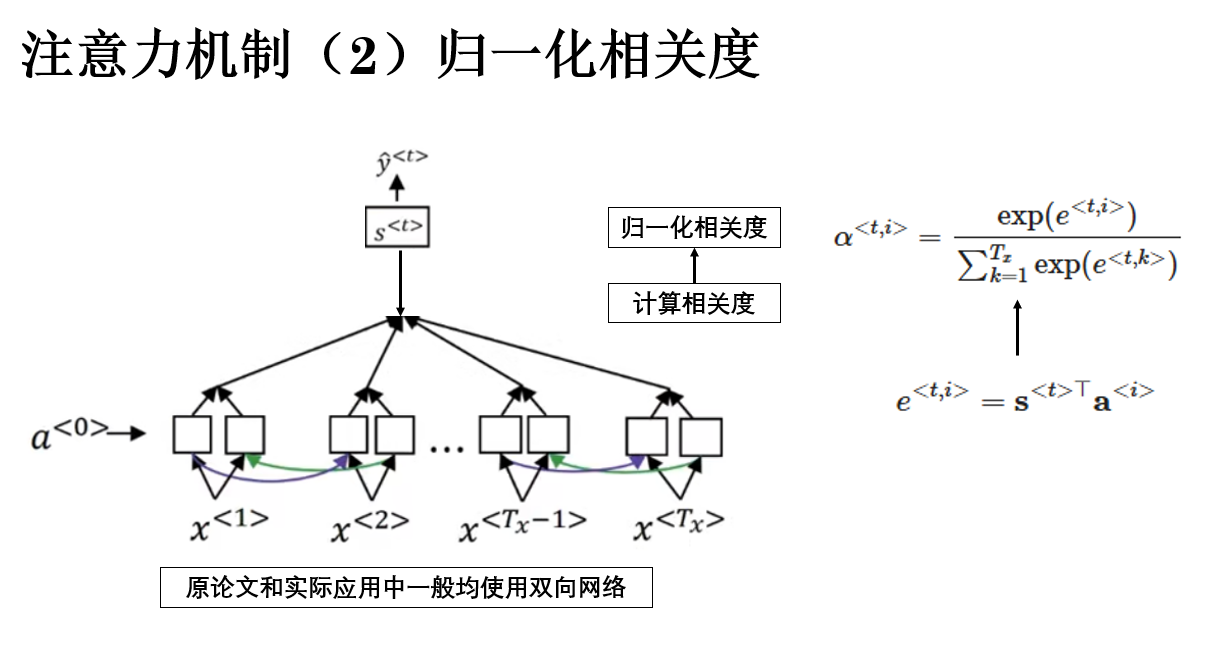
由于相关性分数本身并不具备可比性,下一步需要将其转换为一组归一化权重,最常见的做法,是在输入维度上施加 softmax 操作:
\\\alpha\^{\
此时,\(\alpha^{<t,i>}\) 可以被解释为:在解码第 \(t\) 个输出时,对输入位置 \(i\) 的注意力分配程度。
这一步并不复杂,使用 \(\exp\) 的作用是 是确保相关性为整数,并通过指数放大差异 。
我们继续刚刚的例子计算概率分布如下:
| \(t\) | \(i\) | \(e^{<t,i>}\) | \(\exp(e^{<t,i>})\) | \(\sum_k \exp(e^{<t,k>})\) | \(\alpha^{<t,i>} = \frac{\exp(e^{<t,i>})}{\sum_k \exp(e^{<t,k>})}\) |
|---|---|---|---|---|---|
| 1 | 1 | 0.8 | 2.2255 | 6.1652 | 0.361 |
| 1 | 2 | 0.2 | 1.2214 | 6.1652 | 0.198 |
| 1 | 3 | 1.0 | 2.7183 | 6.1652 | 0.441 |
| 2 | 1 | 0.1 | 1.1052 | 6.2831 | 0.176 |
| 2 | 2 | 0.9 | 2.4596 | 6.2831 | 0.391 |
| 2 | 3 | 1.0 | 2.7183 | 6.2831 | 0.433 |
这样,每个 \(\alpha^{<t,i>}\) 都是一个 非负数 ,且行内总和为 1,并且指数函数放大了较大的 \(e^{<t,i>}\),弱化了较小的 \(e^{<t,i>}\),保证注意力更集中在相关位置。
最终,归一化后得到的 \(\alpha^{<t,i>}\) 就是 解码器在第 \(t\) 步对输入第 \(i\) 个位置的关注权重 。
下面就是最后一步:
2.3 生成上下文向量
有了注意力权重 \(\alpha^{<t,i>}\) 后,下一步就是根据这些权重对编码器的隐藏状态进行加权求和 ,得到一个上下文向量(context vector) ,用于辅助解码器生成当前输出。
公式如下:
\\\mathbf{c}\^{\
其中:
- \(\mathbf{c}^{<t>}\) 表示解码器在第 \(t\) 个时间步的上下文向量;
- \(\alpha^{<t,i>}\) 是第 \(t\) 个输出对第 \(i\) 个输入位置的注意力权重;
- \(\mathbf{a}^{<i>}\) 是编码器在第 \(i\) 个输入位置的隐藏状态。
通过公式就可以得到上下文向量的语义:解码器在当前步"关注的输入信息的加权平均" 。 权重越高的输入位置,对上下文的贡献越大。
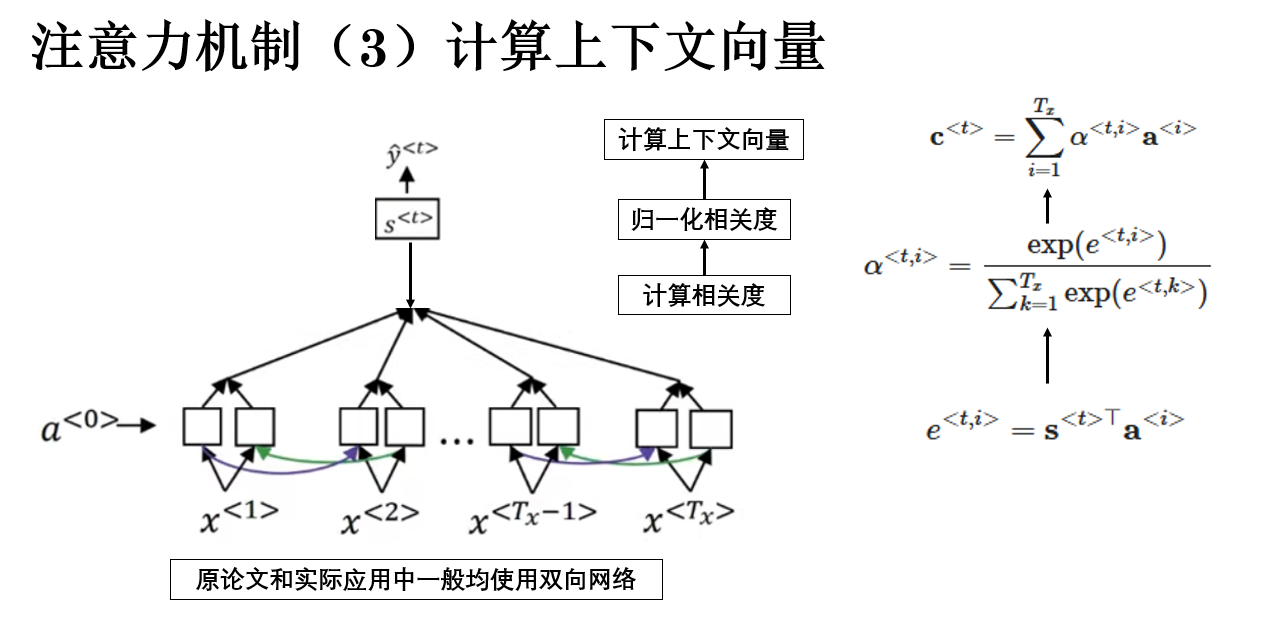
继续例子:
- 对 \(t=1\):
\\\mathbf{c}\^{\<1\>} = 0.361 \\begin{bmatrix}1\\\\0\\end{bmatrix} + 0.198 \\begin{bmatrix}0\\\\1\\end{bmatrix} + 0.441 \\begin{bmatrix}1\\\\1\\end{bmatrix} = \\begin{bmatrix}0.802\\\\0.639\\end{bmatrix} \\
- 对 \(t=2\):
\\\mathbf{c}\^{\<2\>} = 0.176 \\begin{bmatrix}1\\\\0\\end{bmatrix} + 0.391 \\begin{bmatrix}0\\\\1\\end{bmatrix} + 0.433 \\begin{bmatrix}1\\\\1\\end{bmatrix} = \\begin{bmatrix}0.609\\\\0.824\\end{bmatrix} \\
这两个上下文向量就可以与解码器的隐藏状态 \(\mathbf{s}^{<t>}\) 结合,作为生成最终输出的依据。
2.4 输出预测
在实际模型中,解码器通常会将上下文向量与当前隐藏状态拼接或通过线性变换融合:
\\\tilde{\\mathbf{s}}\^{\
然后再输入到输出层预测概率分布:
\\\hat{\\mathbf{y}}\^{\
最终:
- \(\tilde{\mathbf{s}}^{<t>}\) 是融合后的解码器状态。
- \(\mathbf{W}_c, \mathbf{W}_o, \mathbf{b}_o\) 是可学习参数。
- \(\hat{\mathbf{y}}^{<t>}\) 即该步最终输出概率分布。
这样,我们就得到了加入注意力机制的序列模型的完整传播过程:
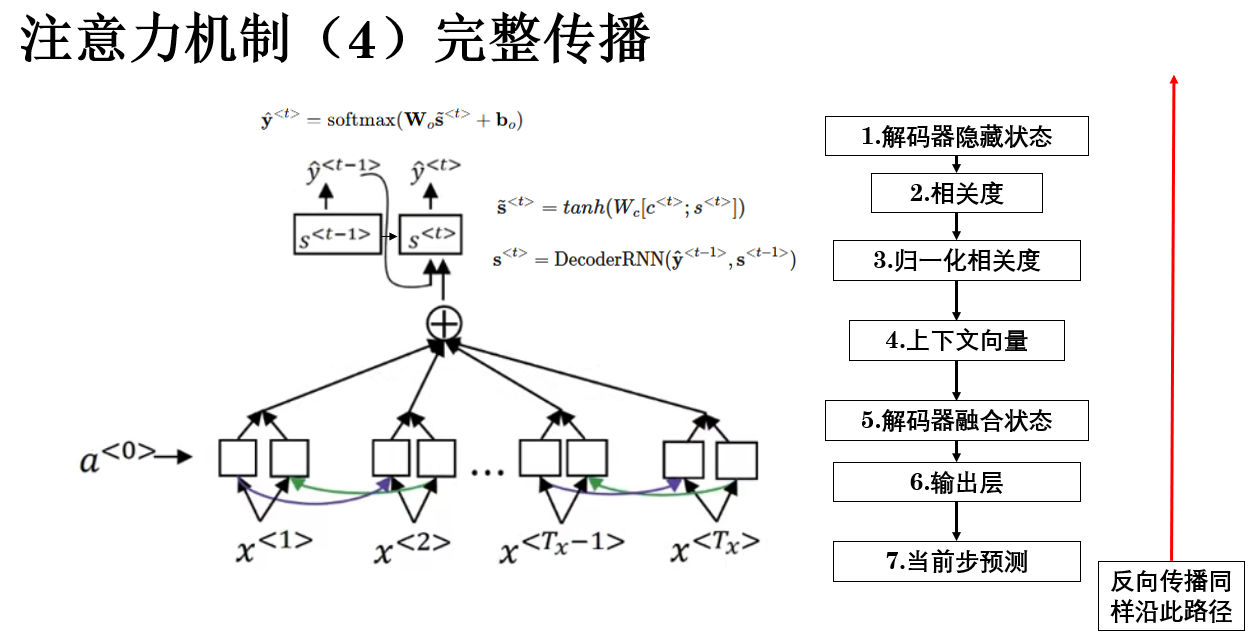
这样,通过注意力机制,解码器的参考就不仅仅是单一的整句向量,而是可以在传播中,动态地学习到,哪些输入对当前步更重要,从而提高模型性能。
在原始注意力机制之后,注意力的思想迅速发展并成为深度学习序列建模中的核心模块。注意力机制的核心价值在于:动态分配信息权重,让模型在处理长序列或复杂结构时,更加高效、可解释、性能更强。这也是 Transformer 系列及大语言模型成功的基础之一。
3. 总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 编码解码架构(Encoder-Decoder) | 将整个输入序列压缩为一个固定长度向量,解码器基于该向量逐步生成输出 | 背课文:记住整篇内容再复述,序列越长越难 |
| 信息瓶颈(Information Bottleneck) | 长序列或复杂结构在压缩成定长表示时会丢失细节信息,损失随长度增长被放大 | 背长篇课文容易遗漏细节 |
| 注意力机制(Attention) | 解码器在每步动态从输入序列中选择与当前输出相关的信息,通过计算相关性、归一化权重、加权求和生成上下文向量 | 看书时只关注当前要回答的问题所在的段落,而不是整本书 |
| 对齐分数(Alignment Score) | 度量当前解码状态与输入各位置的匹配程度,可用前馈网络或向量点积实现 | 判断哪段记忆对当前问题最相关 |
| 注意力权重(Attention Weights) | 将对齐分数通过 softmax 转换为概率分布,表示当前输出对各输入位置的关注程度 | 分配注意力资源:更重要的部分获得更多关注 |
| 上下文向量(Context Vector) | 对输入表示加权求和,得到解码器当前步参考的综合信息 | 当前问题的答案依赖的重点信息汇总 |
| 输出预测 | 将上下文向量与解码器隐藏状态融合,输入输出层生成最终概率分布 | 用精选的重点信息结合记忆生成回答 |
| 核心价值 | 动态分配信息权重,提高长序列处理能力和模型可解释性 | 聚焦关键内容,避免整句或整篇平均处理导致效率低和信息丢失 |