目录
[1. 向量到向量(Vector to Vector)任务](#1. 向量到向量(Vector to Vector)任务)
[2. 序列到序列(Sequence to Sequence)任务](#2. 序列到序列(Sequence to Sequence)任务)
[3. 词性标注任务示例](#3. 词性标注任务示例)
[1. 滑动窗口方法](#1. 滑动窗口方法)
[2. 循环神经网络(RNN)](#2. 循环神经网络(RNN))
[3. 注意力机制(Attention Mechanism)](#3. 注意力机制(Attention Mechanism))
[1. 自注意力层计算](#1. 自注意力层计算)
[2. 位置信息处理](#2. 位置信息处理)
[3. 多头注意力机制](#3. 多头注意力机制)
[1. Decoder 模块](#1. Decoder 模块)
[2. MLP 层结构](#2. MLP 层结构)
[1. 词表构建与分词方法](#1. 词表构建与分词方法)
[2. 向量表示方法](#2. 向量表示方法)
本节课正式开启大模型推理系统的核心内容讲解,作为六节系列课程的第二课,重点解析支撑现代大语言模型的 Transformer 架构与自注意力机制。
人工神经网络基础
1. 向量到向量(Vector to Vector)任务
-
• 输入输出均为向量,如手写数字识别。
-
• 局限:无法处理向量间关系,如序列任务。
2. 序列到序列(Sequence to Sequence)任务
-
• 输入输出为向量序列,如翻译、对话、文本生成。
-
• 特点:输入输出向量数量任意,且输入向量间相互影响。
3. 词性标注任务示例
-
• 输入文字,输出每个词的词性。
-
• 感知器无法处理上下文信息,引出上下文处理需求。
上下文信息处理
1. 滑动窗口方法
-
• 原理:将上下文绑定输入模型。
-
• 缺点:窗口大小固定,无法捕捉长距离上下文。
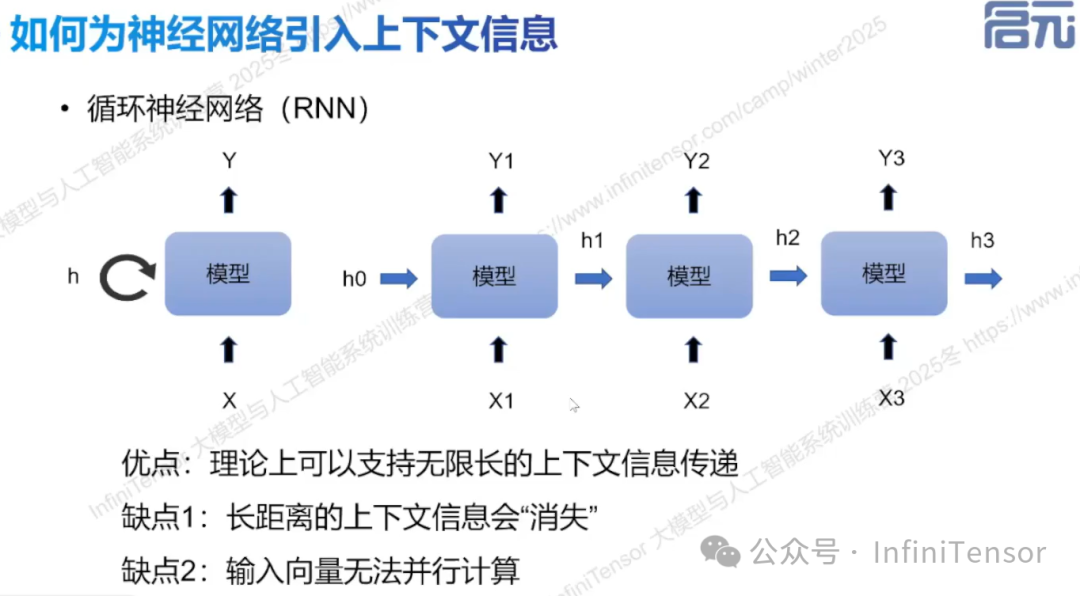
2. 循环神经网络(RNN)
-
• 原理:维护记忆模块,随输入序列更新。
-
• 缺点:长链条信息弱化,计算顺序性强,降低效率。
3. 注意力机制(Attention Mechanism)
-
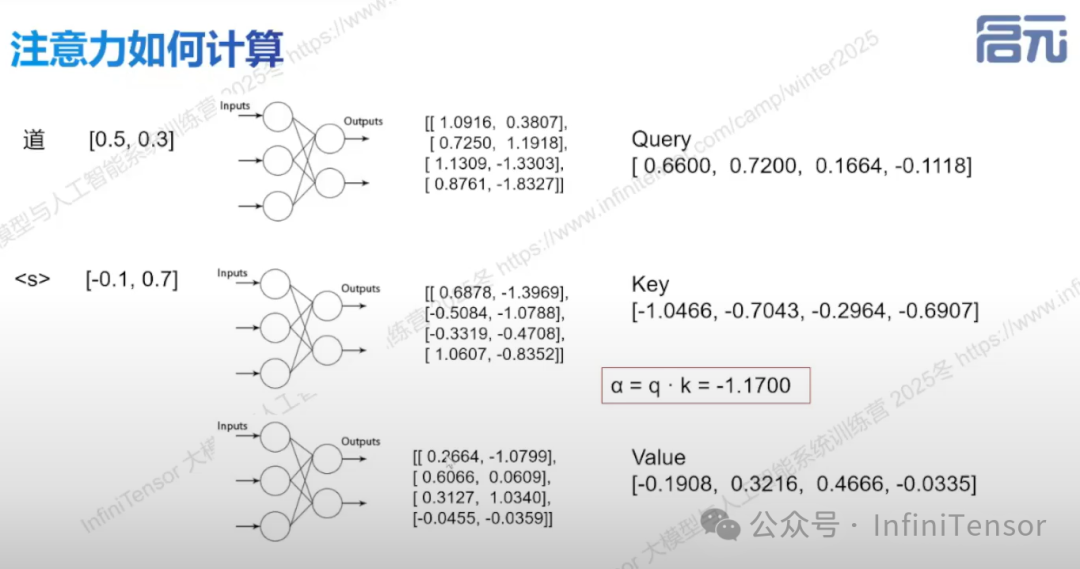
• 上下文信息通过计算输入之间的相似度分数,并经 Softmax 归一化得到注意力权重分布
-
• 计算流程:query、key、value 向量映射,计算相关程度,Softmax 处理,得到注意力输出。
-
• 具体计算流程:它通过将输入的词向量(如"道")与学习到的权重矩阵相乘,分别映射为 Query(查询)、**Key(键)**和 Value(值) 三个向量,并通过计算 Query 与 Key 的点积(如图中的 )来衡量不同输入之间的相关性权重,从而实现模型对重要特征的聚焦。
-
• Softmax 的原理:它通过指数映射和归一化处理,将任意范围的激活值转换为总和为 1 的概率分布;
-
• 数值稳定版本 Safe Softmax:为了防止在计算过程中因输入值过大导致数值溢出,Safe Softmax 引入了减去向量最大值 () 的技巧,在保证数学等价性的前提下提升了算子在工程实现中的稳定性。

自注意力机制
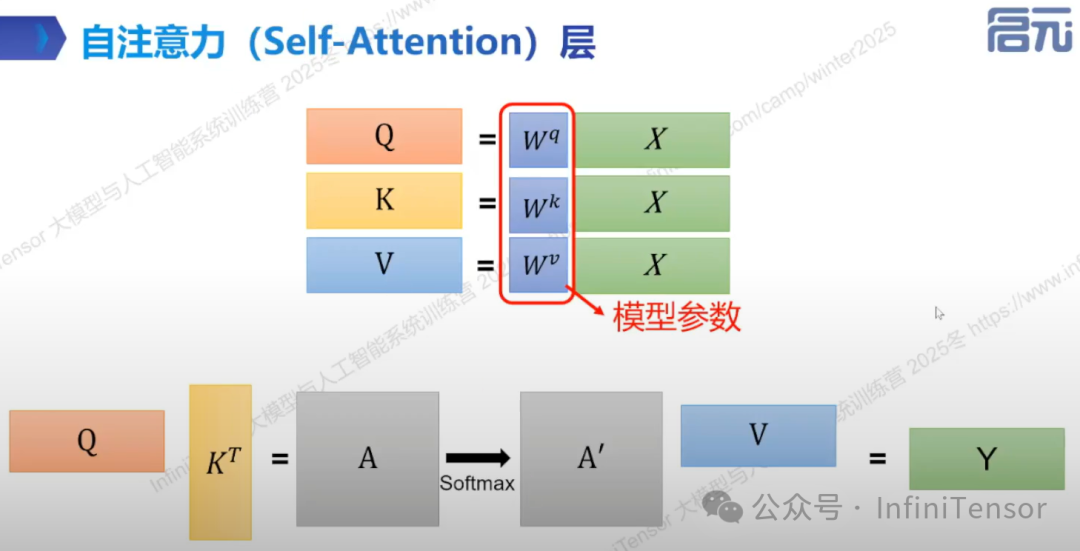
1. 自注意力层计算
2. 位置信息处理
- • 旋转位置编码(Rotary Position Embedding, RoPE):通过角度表示位置关系,保持计算稳定性。
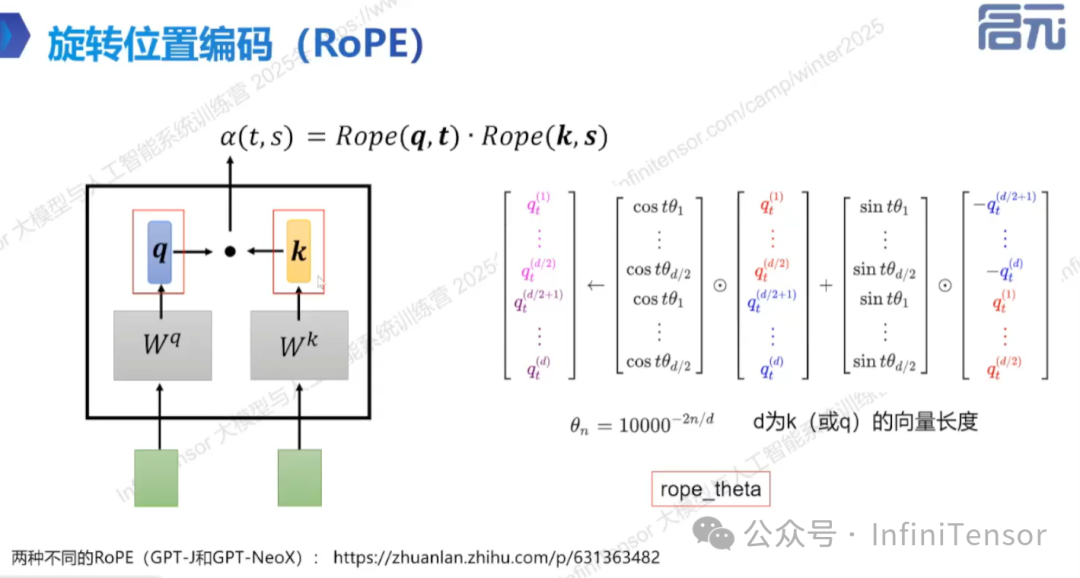
- • 主流算法:GPT-J 与 GPT-Neox,数学无本质区别,角度排布不同。
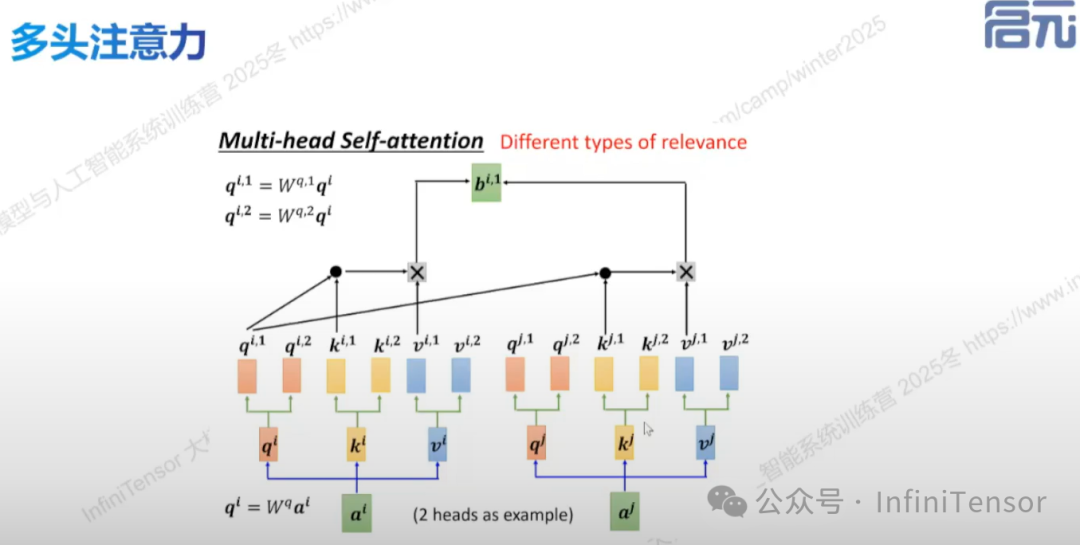
3. 多头注意力机制
-
• 原理:通过将 q、k、v 向量在特征维度上拆分为多个子空间(heads),并行建模不同子空间的注意力关系。
-
• 优势:并行计算,提高效率。
大模型结构详解
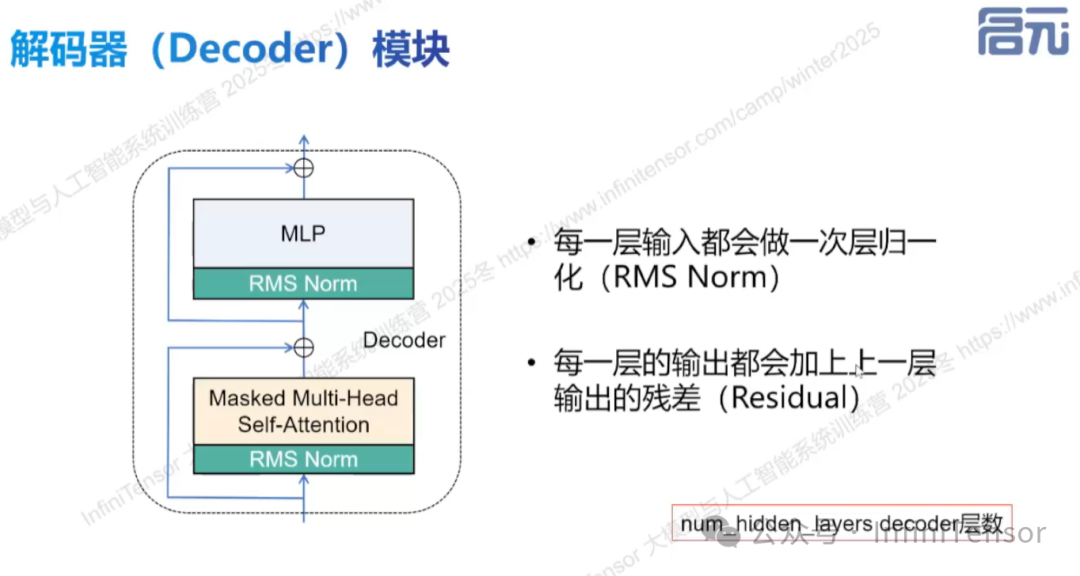
1. Decoder 模块
-
• 组成:自注意力层与 MLP 层首尾相连。
-
• 层归一化(RMSNorm)与残差结构:保证计算稳定,防止信息损失。
2. MLP 层结构
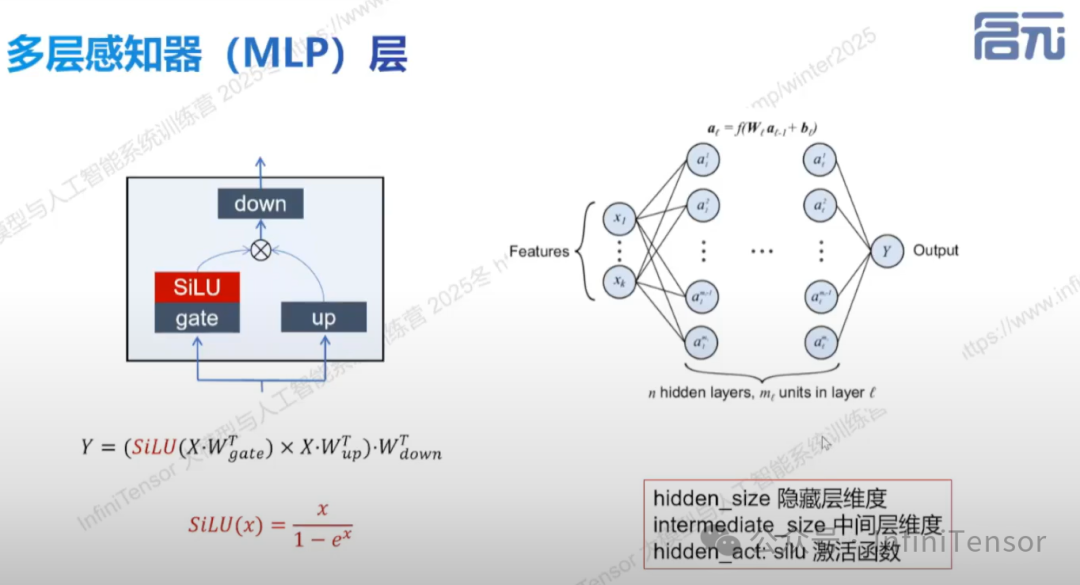
- • 参数:hidden size 与 intermediate size,控制输入输出维度与中间层维度。
文本向量化处理
1. 词表构建与分词方法
-
• 词表构建:BPE 算法,高频组合优先成词。
-
• Tokenizer 作用:将文本转换为 toke-id 序列。
2. 向量表示方法
-
• One-hot 编码:简单但低效。
-
• 输入嵌入层(Input Embedding):神经网络映射 token-id 为连续向量,保留语义信息。
-
• 输出嵌入层(Output Embedding):将向量映射回词表长度概率分布,用于文本生成。