1.读取数据
2.数据预处理:加空格,处理标点
3.分词:去掉第三列,并改为按单词分词
4.序列截断或填充
5.序列最后加结束符,并计算有效长度
6.生成数据集
def data_nmt(path='D:/PycharmDocument/limu/data/fra.txt'):
with open(path,'r',encoding='utf-8',errors='ignore') as f:
return f.read()
raw_txt=data_nmt()
# print(raw_txt[:175])
def preprocess_nmt(text):
def no_space(char,prev_char):
return char in set(',.!?') and prev_char !=' '
text=text.replace('\u202f',' ').replace('\xa0',' ').lower()#将(窄)不换行空格换成普通空格
out=[' '+char if i>0 and no_space(char,text[i-1]) else char for i,char in enumerate(text)]#如果是char标点符号,标点符号前加空格,否则直接加char
return ''.join(out)
text=preprocess_nmt(raw_txt)
# print(text[:80])
def tokenize_nmt(text,num_examples=None):#划分标签和输入集
sourch,target = [],[]
for i,line in enumerate(text.split('\n')):
if num_examples and i>num_examples:
break
parts=line.split('\t')[:2]
if len(parts)==2:
sourch.append(list(parts[0].split(' ')))
target.append(list(parts[1].split(' ')))
return sourch,target
source,target=tokenize_nmt(text)
# print(source[:6],target[:6])
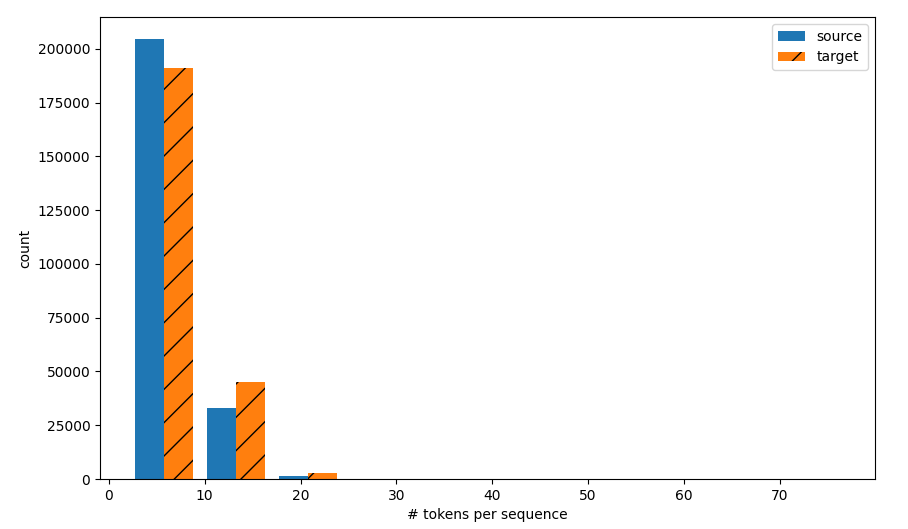
def show_list_len_pair_hist(legend,xlabel,ylabel,xlist,ylist):
plt.figure(figsize=(10,6))
_,_,patches=plt.hist([[len(l) for l in xlist],[len(l) for l in ylist]])
plt.xlabel(xlabel)
plt.ylabel(ylabel)
for patch in patches[1].patches:
patch.set_hatch('/')
plt.legend(legend)
plt.show()
show_list_len_pair_hist(['source','target'],'# tokens per sequence','count',source,target)
复制代码
src_voc=test52text_process.Vocab(source,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])#句子填充、句子开始、结束
def truncate_pad(line,num_steps,padding_token):
if len(line)>num_steps:
return line[:num_steps]
return line+[padding_token]*(num_steps-len(line))
def build_array_nmt(lines,vocab,num_steps):
lines=[vocab[l] for l in lines]
array=torch.tensor([truncate_pad(l, num_steps,vocab['<pad>']) for l in lines])
valid_len=(array!=vocab['<pad>']).type(torch.int32).sum(1)
return array,valid_len
train_iter,src_vocab,tgt_vocab=load_data_nmt(2,8)
for X,X_valid_len,Y,Y_valid_len in train_iter:
print(X.type(torch.int32))
print(X_valid_len)
print(Y.type(torch.int32))
print(Y_valid_len)
break