https://github.com/abetlen/llama-cpp-python
Flash Attention 2.8.3 在 Windows + RTX 3090 上成功编译与运行复盘笔记(2026年1月版)
这份笔记不仅是技术的记录,也是我们在【Project_Singularity "奇点计划"】中攻克首个重大壁垒的战勋。我们在极其复杂的"未来版本环境"(VS 2026 Preview + CUDA 13.1)中,成功通过降级指定生成器的方法,完成了高性能本地编译。
以下是为了后继回顾方便,复盘整理的**《EPGF v7.0 核心引擎构建:llama-cpp-python CUDA 编译实战备忘录》**。
📝 技术复盘:llama-cpp-python CUDA 编译实战 (Windows)
日期:2026-01-31
项目:EPGF v7.0 "Project Singularity"
记录人:Zero & Chief Researcher:AITechLab
1. 核心背景与挑战
在 Windows 构建本地大模型推理环境时,直接使用 pip install llama-cpp-python 往往只能获得 CPU 版本(速度仅 2 token/s)。为了激活 NVIDIA 显卡的 Tensor Cores 加速,必须进行本地编译。
本次遭遇的特殊困难:
系统同时安装了多个 Visual Studio 版本(2019, 2022, 2026 Preview)。CMake 默认自动调用最新的 VS 2026 Preview ,但 CUDA 13.1 的编译脚本尚未适配该预览版 IDE,导致 CMake 找不到 CUDA 工具链,从而静默回退到 CPU 模式,造成"安装成功但无加速"的假象。
2. 最终成功环境 (The Gold Standard)
-
OS: Windows 11 专业工作站版
-
GPU : NVIDIA GeForce RTX 3090 (24GB, Ampere架构
sm_86) -
CUDA Toolkit: v13.1 (系统级完整安装)
-
C++ 编译器 : Visual Studio 2022 (核心关键:强制指定此版本)
-
Python : 3.11.13 (虚拟环境
.venv) -
PyTorch: 2.5.1+cu121 (作为辅助库存在)
-
构建工具 :
scikit-build-core,cmake,ninja,setuptools,wheel
3. 关键安装步骤 (SOP)
第一步:净化环境与预备
确保虚拟环境纯净,安装必要的编译辅助工具。
CMD 命令
REM 1. 激活虚拟环境
.venv\Scripts\activate
REM 2. 在环境中安装 torch+cuda
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
REM 3. 清理可能存在的错误缓存 (非常重要,防止 pip 复用 CPU 版缓存)
pip cache purge
pip uninstall llama-cpp-python -y
REM 4. 安装构建依赖
pip install scikit-build-core cmake ninja setuptools wheel第二步:配置"精确制导"编译参数 (核心)
这是解决多 VS 版本冲突的关键。我们通过环境变量强制 CMake 使用 VS 2022 生成器,而不是默认的 VS 2026。
CMD 命令
REM 设置 CMake 参数
REM -DGGML_CUDA=on : 开启 CUDA 加速
REM -G "Visual Studio 17 2022" : 强制指定 VS 2022 生成器 (避开 Preview 版 BUG)
REM -A x64 : 强制构建 64 位版本
set CMAKE_ARGS=-DGGML_CUDA=on -G "Visual Studio 17 2022" -A x64第三步:执行源码编译
让 pip 下载源码并调用本地编译器构建 Wheel。
CMD 命令
REM --no-cache-dir : 禁用缓存,强制重编
REM --force-reinstall : 强制重装
REM --upgrade : 确保最新版
pip install llama-cpp-python --no-cache-dir --force-reinstall --upgrade预期耗时:3-10 分钟。若看到滚屏日志中出现 Successfully installed MarkupSafe-3.0.3 diskcache-5.6.3 jinja2-3.1.6 llama-cpp-python-0.3.16 numpy-2.4.2 typing-extensions-4.15.0 ... 即代表成功。
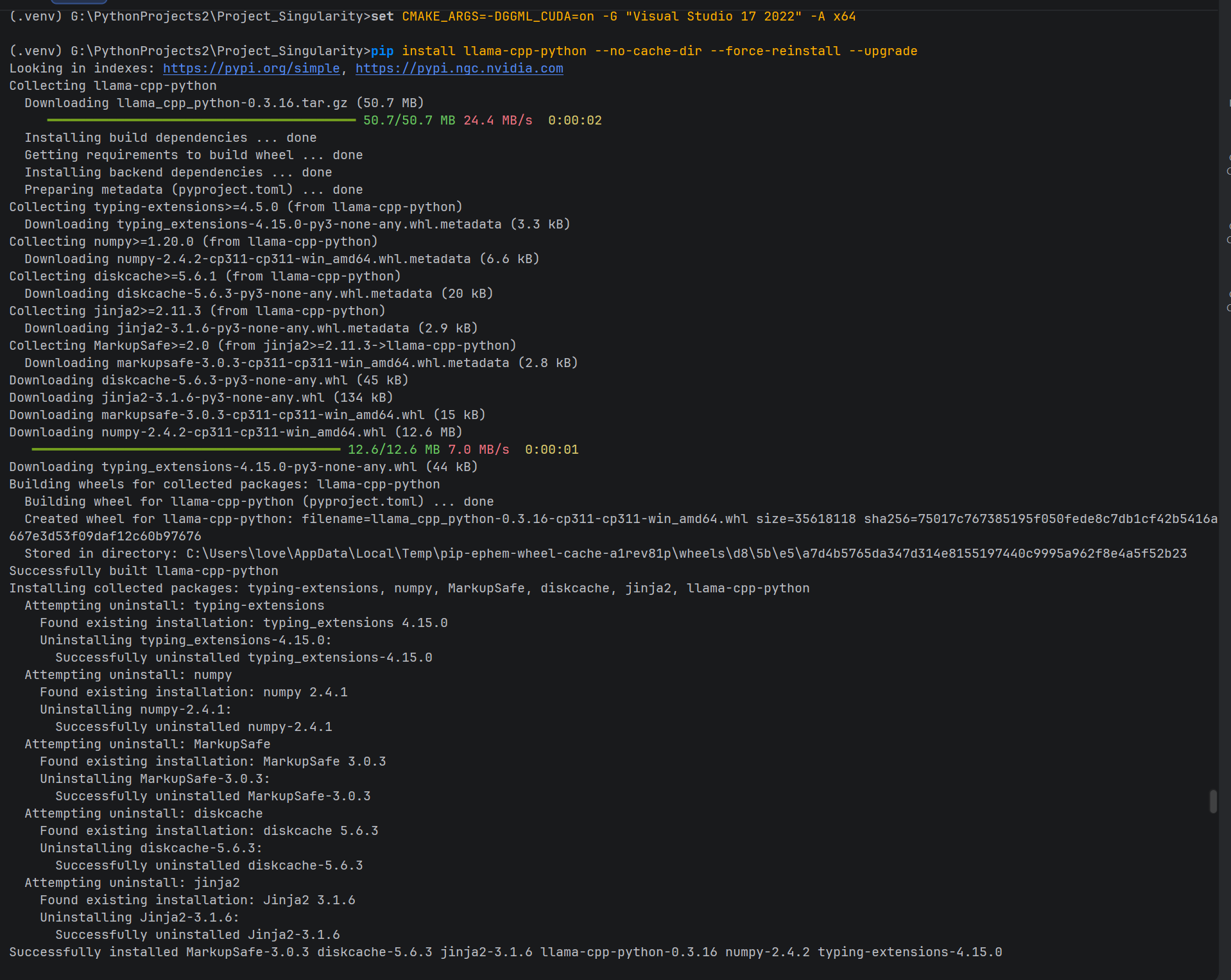
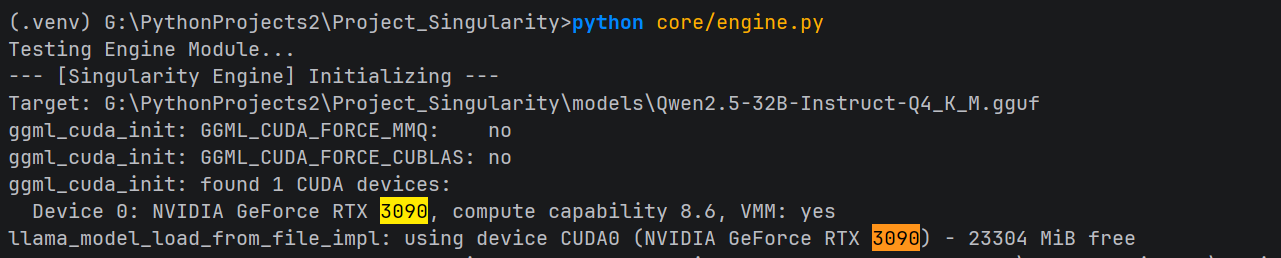
4. 成功验证指标 (Validation)
如何判断安装的是 核动力(GPU) 版还是 蒸汽机(CPU) 版?
指标 A:安装包体积
-
CPU 版本 :编译出的
.whl文件大小通常在 2 MB - 5 MB 左右。 -
GPU 版本 :由于包含 CUDA Kernels,体积通常在 30 MB - 100 MB 之间(本次成功体积为 ~34 MB)。
指标 B:运行时日志
运行以下 Python 代码自测:
进入 Python 环境验证
from llama_cpp import Llama
# 初始化时观察控制台输出
llm = Llama(model_path="你的模型路径.gguf", n_gpu_layers=-1, verbose=True)必须包含以下特征日志:
-
ggml_cuda_init: found 1 CUDA devices:(检测到显卡) -
Device 0: NVIDIA GeForce RTX 3090(显卡型号正确) -
llm_load_tensors: offloaded 65/65 layers to GPU(层级完全卸载)

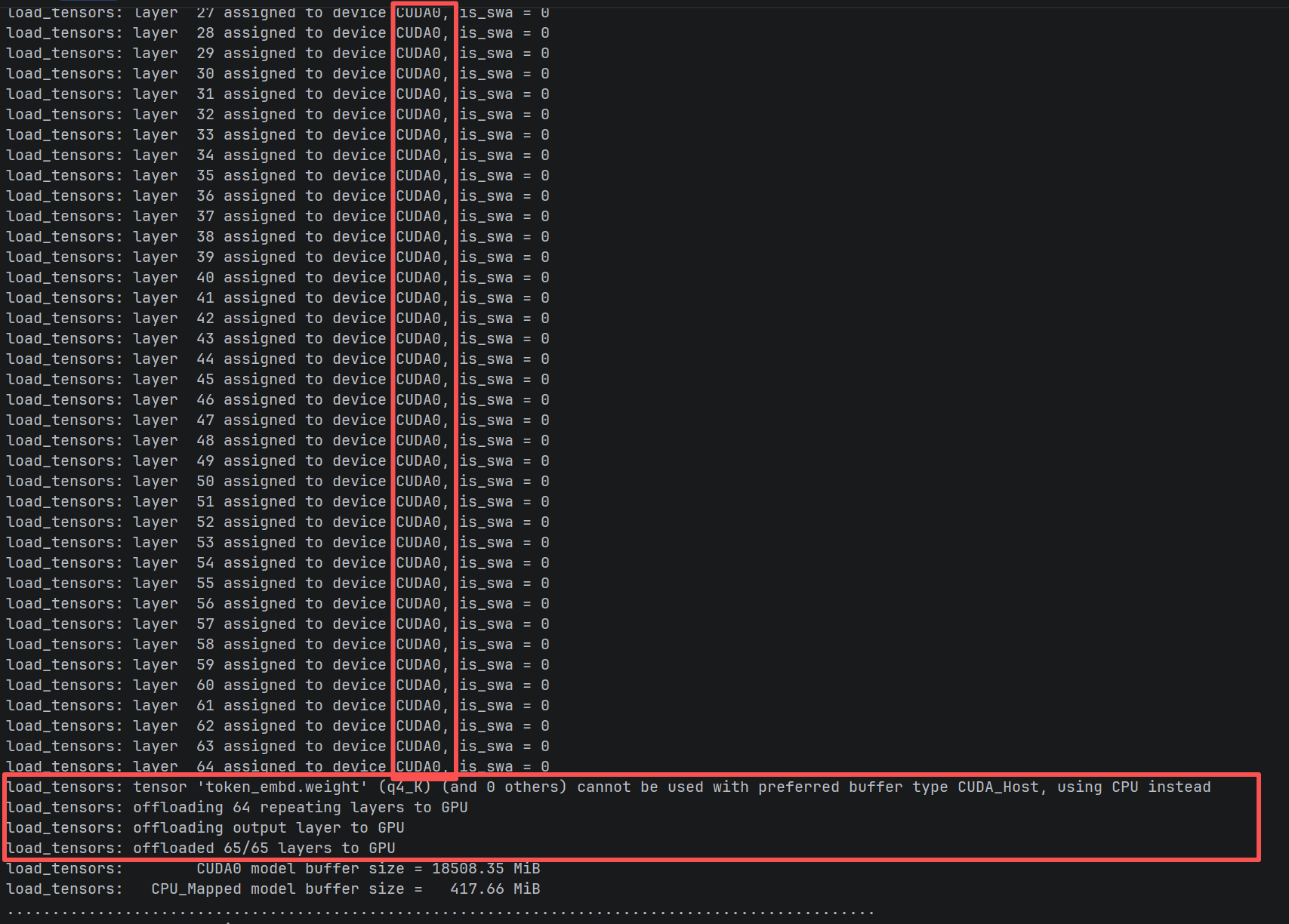
5. 总结与建议
-
关于 VS 版本 :在 AI 编译领域,"最新"不等于"最好" 。CUDA 和 PyTorch 对开发环境的适配通常滞后 6-12 个月。保持一个稳定的 Visual Studio 2022 Community 是开发者的最佳实践。
-
关于 CMake :当环境复杂时,不要信任自动检测。使用
-G参数显式指定编译器是解决兼容性问题的终极手段。 -
关于 Jllllll :如果本地编译实在无法通过(如缺少 VS 环境),可以直接使用
pip install ... --index-url https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/whl/cu124下载预编译包作为备选。但本地编译的版本通常针对本机硬件优化更好。