过去两年,AI 大模型的关键词是刷榜与融资。
大模型团队通过刷高榜单分数来证明技术实力,进而获取融资。
由此催生的早期应用------各类 Chatbot(聊天机器人),虽然惊艳,却更多停留在"图一乐"层面。
但从去年下半年以来,AI 正在快速驶入下半场:行业焦点从训练刷榜,全面转向了推理与应用。
在接受《高工智算》采访时,后摩智能联合创始人项之初给出了一个笃定的判断:
"2026 年,一定会出现百万量级的 AI 端侧爆款,甚至更多。"
如果说上半场是各家模型团队通过跑分炫技的军备竞赛,那么下半场则是检验 AI 能否真正改变人类生活的落地大考。
当 AI 开始从云端落地,我们距离百万级 AI 端侧爆款产品,还缺什么?
01
AI 从"读万卷书"到"行万里路"
当下,AI 的形态正在进行着一些关键的进化。
一个是 Agentic AI(智能体)的成熟。与早期仅提供情绪价值的 Chatbot 不同,Agent 开始真正介入生产力流程。
它不再仅仅陪你聊天,而是开始完成具体任务:不管是去年豆包 X 中兴推出的可以帮助用户点外卖的 AI 手机,抑或是其他的一些 Agent 能辅助用户进行头脑风暴、完成一些案头研究。

AI 已然在切切实实的影响和改变着大家的工作习惯和流程,它的角色已然从一个提供咨询的旁观者,蜕变成了屏幕内的辅助者。
而更具颠覆性的进阶,则是 Physical AI(物理智能)。
当 AI 拥有了眼睛(传感器)、大脑(端侧算力)和四肢(执行器),它便不再局限于屏幕内的任务,而是开始与我们的现实世界产生交互。
对此,项之初给出了一个比喻:
"原来的大语言模型(LLM)更像是一个读万卷书的好学生。
它博学,但处理的是一维的抽象符号,带有明显的书呆子气,因为它没有去过很多地方,没有与真实世界发生交互。
而 Physical AI 的出现,意味着 AI 终于开始行万里路。"
这种从抽象符号到物理反馈的跨越,是 AI 真正改变人类生活的落脚点,也是端侧应用爆发的逻辑原点。
02
从"表演"走向"刚需",端侧算力告急
当市场热度从概念验证回归商业落地,端侧 AI 的需求正在经历一场从"表演"到"刚需"的转变。
项之初在产业一线观察到,早期那些偏向炫技的"表演"------例如机器人后空翻,如今已不再稀缺,甚至仅需一个月便能复现。
客户的焦点已全面转移至更具体、更细分的场景:从实时性要求极高的离线翻译、游戏 AI 队友,到对成本极其敏感的本地推理替代方案,"能不能用、值不值得买"成为了新的审视标准。
这种务实的需求转变,直接引爆了硬件侧算力的跨越式增长。
端侧算力的实际使用量正在以翻倍的速度提升:旗舰手机 NPU 算力已从早期的三四十 TOPS 飙升至 80-100 TOPS(如高通骁龙系列);而在自动驾驶与人形机器人领域,NVIDIA 等早就将门槛推高到了上千TOPS 的量级。

"算力意味着智能化程度。"但为什么我们不能继续依赖强大的云端算力来解决这些问题?
项之初指出,一旦进入多模态与 Physical AI 阶段,云端不仅不是万能药,反而是瓶颈所在。
首先是物理带宽的极限。
Physical AI 意味着传感器(摄像头、麦克风)的全面打开,海量的视频流与音频流将产生巨大的数据吞吐。
项之初引用马斯克的一项估算指出:如果未来所有的视觉交互都依赖云端,仅 4K 分辨率的视频流计算需求,就能耗尽目前全球所有的海底光缆带宽,且仅能满足 4000 万用户的使用。
其次是多模态交互的实时性门槛。
如果仅仅是将场景拍照上传解读,云端尚能应付。但 Physical AI 的核心在于对现实世界的"深度理解与实时反馈"。
项之初举例,当用户进门时,陪伴机器人需要瞬间捕捉其微表情,分析是沮丧还是欢愉,并据此主动发起对话或播放音乐。
这种对三维信息、实时情绪的深度理解,决不能容忍云端传输带来的延迟与割裂。
正如自动驾驶仅仅是在二维平面上移动就需要千 TOPS 的算力来处理高速图像流。
未来的家庭机器人等应用要在更复杂的三维空间中实现真正的智能交互,对本地算力的渴求将是指数级的。
就目前的情况来看,面对 Physical AI 的爆发,端侧算力显然还存在着巨大的缺口。
03
保守的加减法还是激进的重构?
在端侧硬件的演进路径上,产业链内部正在形成显性的产品形态分化。
从硬件架构来看,端侧算力正分化为 iNPU(集成 NPU)与 dNPU(独立 NPU)两条路径。
项之初在采访中打了一个通俗的比方:"iNPU 相当于集成显卡,只不过它集成的是加速卡;而 dNPU 就是独立的加速卡,更像英伟达当年的那种独显。"
以英特尔、AMD、高通为代表的传统芯片巨头,倾向于将 NPU 集成在 SoC 内部的逻辑。
例如,在刚刚结束的 CES 2026 上,Intel 与 AMD 推出的新一代 AI CPU------酷睿 Ultra 300 与 Ryzen AI 400 系列,其 NPU 算力仍徘徊在 50-60 TOPS 关口。

这种集成式 NPU 受限于算力与显存带宽的天然短板,仅能勉强支撑 3B 至 7B 的小参数模型,且在多模态并发与大模型推理速度上存在明显瓶颈。
相比之下,dNPU 则类似"独立显卡",通过提供独立的算力与带宽,更能满足大模型对极致性能与高并发的需求。
但也面临着能耗、成本和面积等方面的制约。这也正是存算一体、3D 堆叠等新技术方案异军突起的原因。
表层来看是架构之争,但深层折射出的,是对 AI 端侧产品定义逻辑的差异:是做保守的"加减法",还是进行"正向设计"的重构?
可以看到,受制于财报压力与原有产品线包袱等因素,传统芯片及终端大厂大多沿用"做加法"的惯性思维,即在原有架构上塞入一颗算力有限的 iNPU。
项之初直言这是一种"比较懒惰的思路",并将其比作电动车产业的早期阶段:"大家把前面发动机拿掉以后,在前备箱放电池。"
这种"油改电"式的改良,本质上是在旧有的舒适区内修补,而非架构层面的革新。

与此类似的,目前市面上的端侧产品还大多停留在"加个 Wi-Fi 模组、接上云端 API"的形态,它们并未触及端侧智能的核心------即通过本地算力实现对用户意图的深度理解与实时响应。
在项之初看来,与之相对的"正向设计",则更像功能机向智能机的转换。
"功能机原来卖 1000 多块,续航还能有一星期;但到智能手机你续航只有一天,大家同样愿意花大几千到一万去买。"
项之初指出,这背后的逻辑在于,用户愿意为了质变的智能化体验而容忍续航的折损以及更高的价格,因为"你本身变成了不同的产品"。
"以前做加法的逻辑其实已经被证伪了,现在大家越来越转向把体验做到极致的逻辑。"
项之初以去年的"豆包手机"为例,它与传统 AI 手机最大的不同在于,它做了一个系统级的 Agent,将大模型直接嵌入了操作系统层面,可以在后台直接注入事件(Inject Events)。
"这就是典型的正向设计。"项之初坦言,尽管这种模式在推行中难免会触碰到部分大厂生态的壁垒(Block),但他坚定地认为,这种阻碍只是暂时的:"在商业维度上,这种博弈或许能减缓它的步伐,但绝挡不住历史的洪流。"
在项之初看来,只有这种打穿底层的正向重构,才能承载真正的端侧智能,并最终催生百万量级的爆款单品。
04
更锋利的铲子能更快地挖出 Killer App 吗?
当端侧算力的供给开始出现突破,应用侧的爆发还需要多久?
作为端侧智能产业链上游的观察者,项之初观察到的是,即便铲子已经足够锋利,但由于但由于成本、认知与工具链的滞后,挖掘宝藏的过程依然面临着不少的挑战。
从单纯的硬件维度来看,端侧算力其实已经跨过了"能用"的门槛。

后摩智能于去年发布的 M50 芯片,在典型功耗仅 10W 的前提下,已能提供 160 TOPS 的算力;并配备最大 48GB LPDDR5 内存;带宽速度达到 153.6 GB/s;可以支撑 30B 大模型 25+ Tokens 的推理速度。
项之初透露,后摩智能 M50 自发布以来,收到了超出预期的下游客户测试需求。
但这更多代表了研发侧的测试需求旺盛,真正的考验在于今年后续的量产交付。
当端侧算力的供给开始出现突破,应用侧的爆发是否会如期而至?从目前的产业节奏来看,硬件的准备显然跑在了应用的前面。
相比于芯片的节奏,行业期待的 Killer App(杀手级应用)则显得更为迟缓。
项之初坦承,目前端侧尚未出现真正意义上的现象级应用。这并非单纯的技术卡点,而是受限于行业认知的惯性与产业链的物理周期。

首先是认知的滞后。长期以来,端侧开发者的思维被禁锢在 10W 功耗、30TOPS 算力的贫瘠土壤里。
当供应链突然提供了一把更锋利的铲子,芯片厂商反而需要支付昂贵的教育成本。
"大家还不知道端侧可以跑这么大的模型。"项之初指出,客户往往还是基于旧有的算力天花板去构想产品,需要时间去适应并重新定义:"原来我可以跑更大的模型,那我是不是能做点不一样的?"
其次是漫长的导入期。一个大厂从接触芯片、验证测试到最终推出产品,通常需要至少 12 个月的周期。在这个过程中,厂商需要将 AI 真正嵌入到垂直行业的工作流中,而非像早期那样简单推出一个"封装了云端 API 的盒子"。
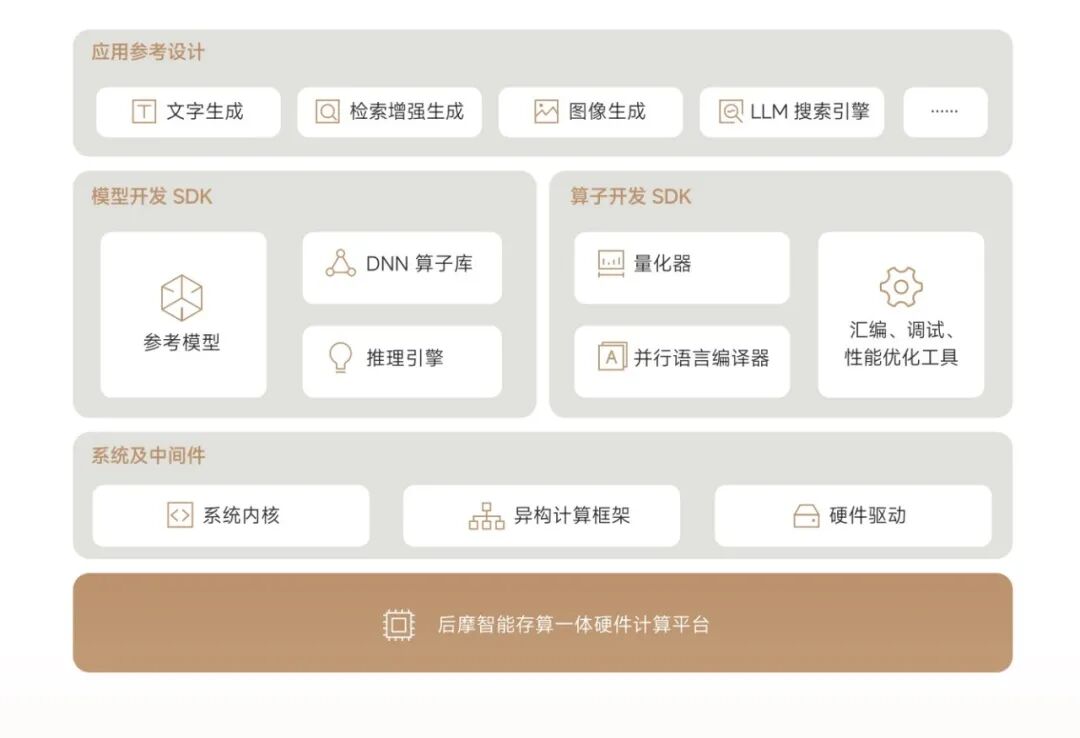
除了时间差,"好用"是端侧 AI 芯片厂商面临的另一道现实门槛。
不同于通用 GPU 拥有成熟的 CUDA 生态,后摩智能的存算一体芯片作为一种全新的非冯・诺依曼架构,其底层的编译器和工具链必须由原厂从头构建。当然谷歌TPU或其他ASIC芯片也走过同样的路程。
项之初直言,解决工具链成熟度的唯一路径是"被客户虐"。"好的客户会不停地虐你,你不停地迭代编译器版本。"
这意味着,芯片厂商不能再只充当"卖铲人"的角色,必须深度介入客户的开发过程,提供从量化器、算子库到推理引擎的全栈支持。
这也对团队基因提出了严苛要求:纯学术背景的团队往往能跑出漂亮的 PPT 数据,但在面对复杂的软件迁移成本和量产一致性挑战时容易折戟。
只有具备工业界背景、懂编译器和大规模量产的团队,才能将理论上的 PPA 优势转化为客户可用的产品。
05
被忽视的非共识市场,先行一步的出货红利
在当下行业聚光灯聚焦的 AI PC、具身智能等显性赛道上,后摩智能已经实现了与多家客户的合作。此外,更是在一些"不起眼"的基础设施缝隙里看到了数十万的出货量。
最先撕开缺口的,是运营商渠道的无感升级与私有云形态的下沉。
运营商的 AI 网关是这种务实逻辑的典型代表。
不同于需要消费者主动购买的独立硬件,这种网关的商业逻辑是在传统的 ToB 路由器中直接嵌入高算力芯片。
这一微小的硬件改动,在物理层面上将一个部门的互联网入口升级为了"轻量级私有云"。
用户接入 Wi-Fi 后,即可调用本地的知识库与大模型,无需重新部署服务器。这种借力运营商既有专线与推广团队的模式,以极低的摩擦力在 B 端市场迅速撕开了一个数十万量级的缺口。
这种"边缘私有云"的逻辑不仅限于网关,更在向 Home Center(家庭中心)与 NAS(网络存储)等形态蔓延。
项之初指出,家庭与企业正在出现一种新的形态需求:不仅是存储数据,更要通过边缘算力构建一个既是"端"也是"边"的智能中心。
无论是运营商推广的网关,还是正在兴起的企业级 NAS,本质上都是以极低成本、更灵活的方式,在本地构建起数据安全的堡垒。
这些需求正在成为端侧市场最先兑现的红利。
另一个值得关注的增量市场是面向海外极客的口袋级超算中心。
这种新型产品形态的 Mini PC 的核心价值在于通过一个插件式的硬件,让人们在现有设备的基础上,搭建一个可以在本地跑 AI 的能力。
这类产品即使在不联网的状态下,也能在本地流畅运行 120B 参数的大模型。
这种对超大模型的承载力,吸引了大量追求隐私和极致性能的海外极客,他们利用这一便携式算力平台,在各种场景下开发和运行本地 AI 应用。
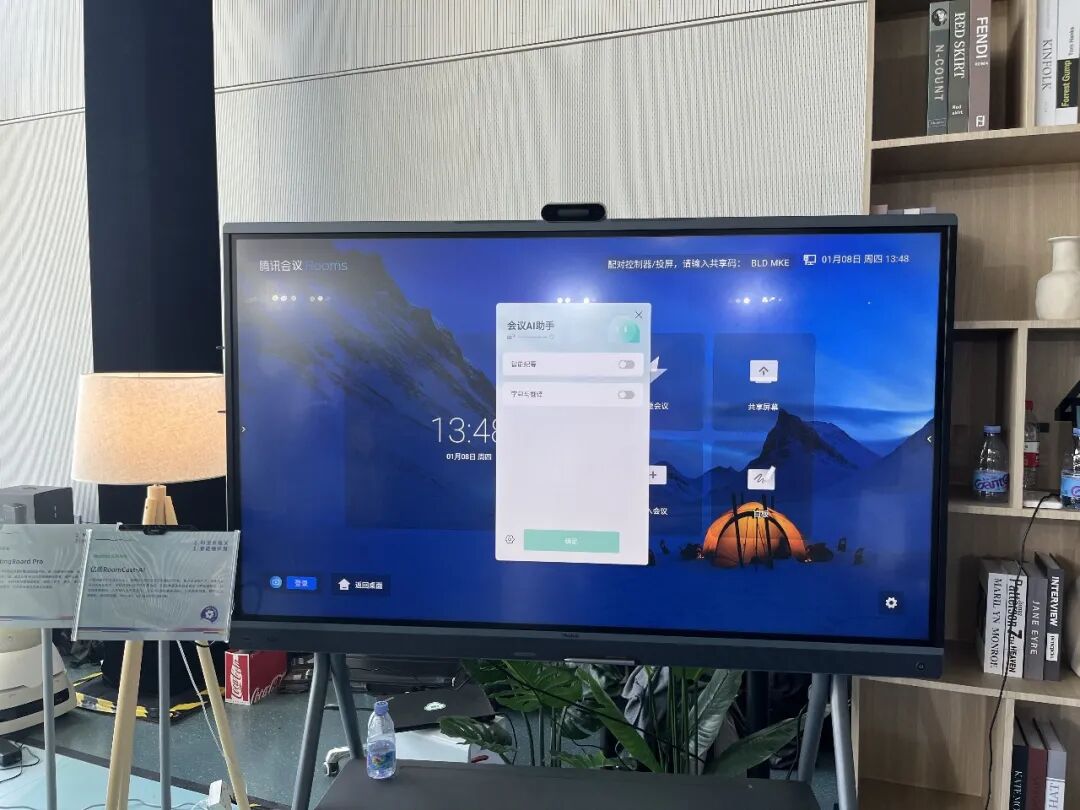
最后一类被忽视的增长点,是会议系统的智能纪要和实时翻译。
相对于极客群体对性能的主动探索,商务协作市场的本地化需求,更多源于企业对数据安全的防御性考量。
项之初表示,现在越来越多的企业对于会议记录有了"拒云"的趋势。
这种离线需求正在演变出新的产品形态------高算力会议盒子与一体机。
为了在本地状态下,复刻云端大模型长达数千 Token 的上下文理解力与多语种翻译精度,行业头部客户已经将端侧算力推高至 300 TOPS。
此外,这种高算力会议盒子在出海市场也非常受欢迎。因为出海场景对会议的实时翻译功能的需求非常强。
这种便携式的本地算力设备,完美规避了异国网络基建差、计费复杂及数据跨境合规的风险。
06
云端镜像,等待那个"iPhone 4"时刻
在采访的尾声,关于端侧 AI 的终局演变,项之初提出了一个基于算力结构演变的"云端镜像"判断。
黄仁勋曾指出,数据中心的算力结构在过去几年间发生了根本性的翻转------从 CPU 控制为主演变为以 AI 计算为主,两者比例从 9:1 倒置为 1:9。
项之初认为,这一剧烈的"权位交替"同样会在边缘侧发生。未来的端侧设备,其核心将不再是 CPU,而是以 NPU 为代表的 AI 加速单元。
这标志着端侧设备将完成从"功能机叠加 AI 模块"到"以 AI 为核心架构"的物种跨越。届时,NPU 将从协处理器跃升为计算架构的主角,定义设备的体验上限。
然而,在架构反转与"iPhone 4 时刻"真正到来之间,产业链仍需穿越一段充满博弈的迷雾期。
面对当前应用场景尚不明确、下游厂商对成本极其敏感的现状,上游芯片厂商被迫在"高性能"与"低成本"之间寻找灰度生存空间。
项之初在采访中揭示了当前阶段的生存法则------"算力与成本的解耦交付"。
"这是一个双向试探的过程。"项之初直言,"如果客户对成本敏感,我们未来可以提供裁剪版或迭代版------你要一半的价格,我就给你一半的算力,或者三分之二的算力。"
这种灵活性的背后,是初创芯片企业为了切入存量市场、维持现金流而不得不做的战术妥协,而拐点在于规模效应。
项之初的逻辑很清晰:一旦单品突破百万级门槛,芯片的边际成本将被迅速摊薄,届时才能通过更成熟的技术方案(如手机芯片的架构扩展)实现高性能算力的低成本普及。
行业仍在等待那个"点火"的瞬间。
面对应用爆发的不确定性,这家端侧 AI 芯片公司的策略被浓缩为一句话:"我们无法预知下一个爆款应用具体长什么样,但我们可以把铲子磨得更锋利,加速它的到来。"
在项之初看来,扎根中国这一全球最大的端侧与机器人供应链中心,服务好这里的创业者,做一名耐心的"卖铲人",或许是芯片厂商在黎明前最好的生存法则。