本专栏前文已经完成索引模块程序:
https://blog.csdn.net/m0_63299495/article/details/157582494?spm=1011.2415.3001.5331![]() https://blog.csdn.net/m0_63299495/article/details/157582494?spm=1011.2415.3001.5331本文介绍另一优化点:使用缓存节省读盘时间。
https://blog.csdn.net/m0_63299495/article/details/157582494?spm=1011.2415.3001.5331本文介绍另一优化点:使用缓存节省读盘时间。
在之前的程序中,使用FileReader提供的read方法直接读取文件。使用fileReader.read()每次读取一个字符,即使操作系统存在缓存优化,也存在较多的读盘次数。
Java标准库中提供了BufferedReader类,可以搭配FileReader使用。BufferedReader内部内置了一个缓冲区,可以自动地把FileReader中的一些内容预读到内存中,从而减少读盘次数。
修改Paser类的parseContent方法如下:
java
// 解析HTML的正文
public String parseContent(File f) {
// 去标签
// try (FileReader fileReader=new FileReader(f)){
try (BufferedReader bufferedReader = new BufferedReader(new FileReader(f),1024 * 1024)){
// 拷贝标志位
boolean isCopy=true;
// 创建保存结果的StringBuilder
StringBuilder content=new StringBuilder();
while(true){
// 使用字符流读取方式fileReader
// read方法的返回值是整型,当返回-1时表示文件读取结束
// int ret = fileReader.read();
int ret = bufferedReader.read();
if(ret==-1){
break;
}
char c= (char)ret;
if(isCopy){
// 开关打开:进行拷贝
if(c=='<'){
isCopy=false;
continue;
}
// 去除正文信息中的空行:若当前字符为换行符或回车符,则替换为空格
if(c=='\n' || c=='\r'){
c=' ';
}
// 其他字符则进行拷贝
content.append(c);
}else{
// 开关关闭:不进行拷贝
if(c=='>'){
isCopy=true;
}
}
}
return content.toString();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}其中,BufferedReader还支持指定缓冲区大小:
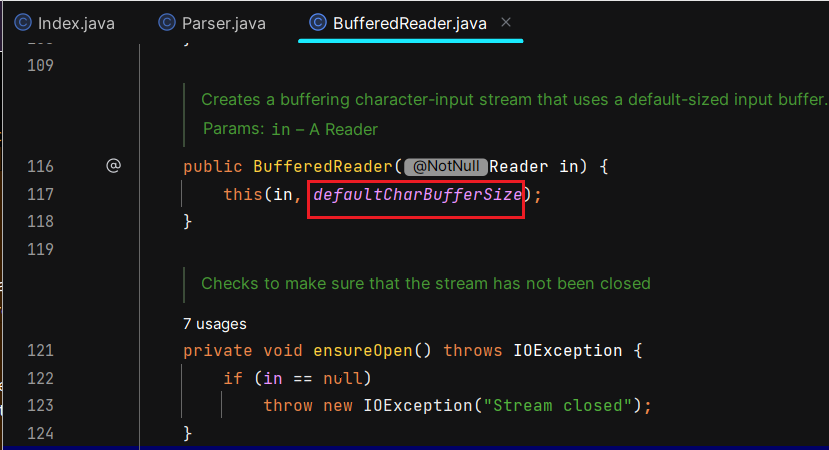
并且其默认缓冲区大小为8KB:
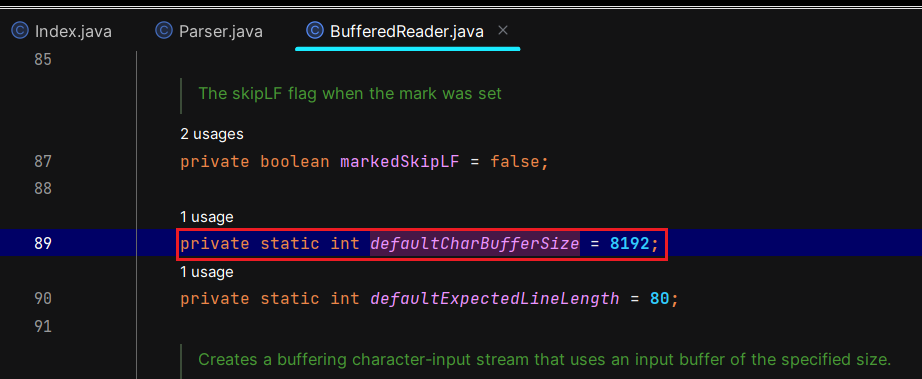
为了确定合适大小的缓冲区,需要参考HTML文件的大小:
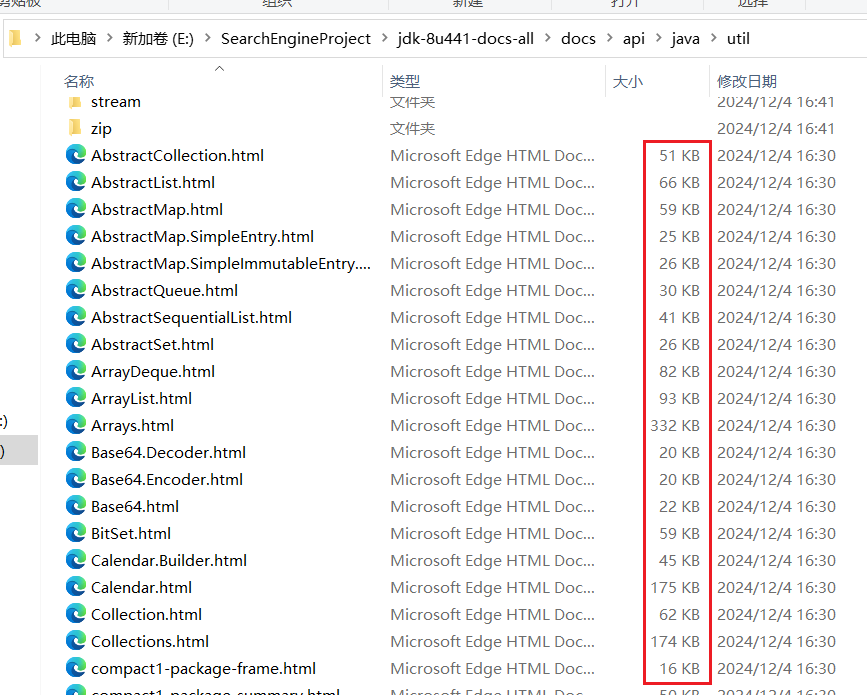
可见大多数HTML文件大小都在20~200KB之间,故BufferedReader默认的8KB大小的缓冲区并不合适,可将缓冲区大小默认设置为1MB:
java
BufferedReader bufferedReader = new BufferedReader(new FileReader(f),1024 * 1024