大模型中词嵌入层(Token Embedding Layer)的核心参数矩阵,也是模型把离散的「词元 ID」转换成连续的「词向量」的唯一依据
模型不会直接认识文字 / 词元,词元嵌入权重就是模型给每个词元分配的「初始数值身份卡」
训练前是随机初始化的,训练中会通过反向传播不断优化,最终让语义相近的词元,对应的「身份卡数值」也相近
词元(Token):模型能处理的最小文本单位(如汉字、英文单词、子词,比如「苹果」是一个词元,ID 可能是123)
词元 ID:给所有词元编的唯一整数编号(词表 Vocab 的核心,比如词表大小 10000,ID 范围 0~9999),是文本输入模型的原始形式(模型只认数字,不认文字)
词向量(Token Vector/Embedding Vector):词元 ID 经嵌入层转换后的连续浮点型向量(比如 768 维),是模型后续所有计算(自注意力、FFN)的输入特征
词元文字 → 词元ID(离散) → 词元嵌入权重(矩阵) → 词向量(连续),词元嵌入权重是这个转换的核心桥梁
官方定义
词元嵌入权重是一个二维可学习参数矩阵,记为 Wemb,是大模型输入层的核心可训练权重,也是大模型总参数量的重要组成部分
(比如 7B 模型的词嵌入权重占比约 5%~10%)
固定维度结构(所有大模型通用)
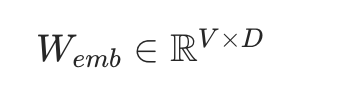
V:词表大小(Vocab Size):即模型能识别的所有词元总数(比如 10000、32000、65536),对应矩阵的行数,每一行对应一个词元 ID
D:嵌入维度(Embedding Dimension):即转换后的词向量维度(比如 768、4096),对应矩阵列数, 每一列是词向量一个特征维度
矩阵有 V 行 D 列,每一行就是对应词元 ID 的「初始词向量」,行号和词元 ID 严格一一对应
极简例子
假设模型的词表大小 V=5(仅 5 个词元),嵌入维度 D=3(词向量 3 维),随机初始化的词元嵌入权重矩阵如下:
词元 词元 ID 词元嵌入权重(矩阵的某一行)= 初始词向量
我 0 0.2, 0.5, -0.1(矩阵第 0 行)
爱 1 0.8, -0.3, 0.4(矩阵第 1 行)
吃 2 -0.5, 0.1, 0.7(矩阵第 2 行)
苹 3 0.3, 0.6, -0.2(矩阵第 3 行)
果 4 0.4, -0.5, 0.3(矩阵第 4 行)
此时词元嵌入权重矩阵 Wemb 就是 5 行 3 列的二维数组:
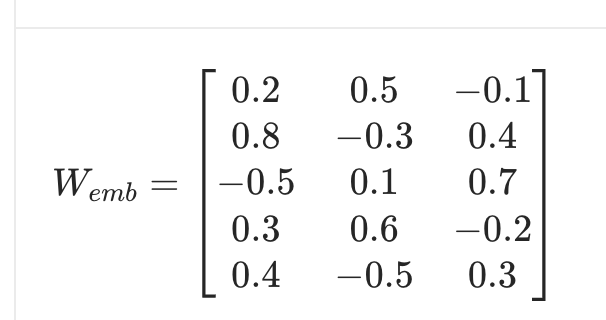
词元嵌入权重的核心作用:把「数字 ID」变成「模型能理解的向量」
权重最基础也最核心的作用,过程本质是 「查表 / 矩阵索引」,无复杂计算,和之前的 softmax 概率索引是同一逻辑:
转换逻辑(极简版)
对于任意词元 ID i,其对应的词向量 ei,就是词元嵌入权重矩阵 Wemb 的第 i 行,即:
ei =Wembi,:
结合上面的例子
词元「爱」的 ID=1 → 取Wemb 第 1 行 → 词向量 = 0.8, -0.3, 0.4;
词元「果」的 ID=4 → 取Wemb 第 4 行 → 词向量 =0.4, -0.5, 0.3;
实操中的批量转换
大模型处理一句话(如「我爱吃苹果」)时,会先把所有词元转成 ID 序列0,1,2,3,4,再通过矩阵索引 / 切片一次性从 Wemb 中取出对应行,拼成批次词向量矩阵(形状seq_len, D,序列长度 × 嵌入维度),作为模型隐藏层的输入
注意:
这个转换过程是纯查表 / 索引,无任何线性计算(如矩阵乘法),是大模型中最轻量化的层操作,目的只是「把离散 ID 映射成连续向量」
词元嵌入权重的「训练逻辑」(和反向传播强关联,核心重点)
它不是固定不变的,而是和隐藏层的自注意力、FFN 权重一样,是可学习的参数
全程参与模型的训练和反向传播,这也是为什么训练后模型能理解词元语义的核心原因
初始化:训练前的「随机身份卡」
模型训练开始前,词元嵌入权重
Wemb 会被随机初始化(比如用正态分布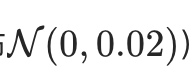
此时的权重矩阵没有任何语义信息,语义相近的词元(如「苹果」和「香蕉」),对应的行向量可能数值差异极大,模型此时完全「不认词」
训练中:通过反向传播不断优化(和其他权重无区别)
模型训练的「前向传播 + 反向传播 + 梯度下降」循环中,词元嵌入权重会和隐藏层的 WQ/WK/WV、FFN 的W1/W2一起被优化:
前向传播:通过 Wemb 把词元 ID 转成词向量,经隐藏层层层加工后输出 logits,计算损失
反向传播:从损失出发,通过链式求导:
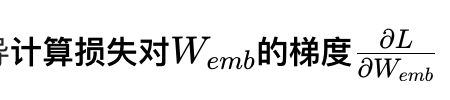
(核心:哪个词元的向量导致了损失,就计算该词元对应行的梯度)
梯度下降:用优化器(如 AdamW)沿梯度反方向更新Wemb 的数值(仅更新损失相关词元的对应行,无需全量更新)
训练后:形成「有语义的权重矩阵」
经过海量文本的训练,Wemb 会被优化成具备语义信息的矩阵,核心特征是:
语义相近,向量相似:
语义越接近的词元,其在 Wemb 中对应的行向量,余弦相似度越高
(比如「苹果」和「香蕉」的行向量几乎平行,「我」和「你」的行向量相似度高)
语义相关,向量可运算:
比如大模型中经典的「国王 - 男人 + 女人 = 女王」,本质就是 Wemb 中对应词元行向量的算术运算
结果和「女王」的行向量高度相似
词元的位置 = 语义的位置:
Wemb 的每一行,就是对应词元在模型「语义空间」中的唯一坐标,这是模型理解自然语言的基础。
词元嵌入权重的 2 个关键特性
- 是大模型唯一的「输入层可训练权重」
大模型的输入层包含「词嵌入层 + 位置编码」,其中:
词嵌入层:核心是可训练的词元嵌入权重 Wemb
位置编码:
要么是固定的(如 Transformer 原始的正弦余弦位置编码)
要么是可训练的位置嵌入权重(和词元嵌入权重结构完全一致,只是映射的是位置 ID)
结论:
词元嵌入权重是模型从「文本输入」到「特征计算」的第一个可训练参数,也是模型理解词元的起点。
- 权重的「行 / 列维度」直接影响模型能力和参数量
行维度 V(词表大小):
V 越大,模型能识别的词元越多,能处理的文本越丰富(但参数量会增加)
比如小模型 V=10000,大模型 V=65536
列维度 D(嵌入维度):
D 越大,词向量的表达能力越强,能容纳的词元语义信息越丰富(但参数量和计算量会大幅增加)
比如基础模型 D=768,大模型 D=4096/8192
实操重点:
从零构建模型时,词元嵌入权重的维度是超参数,需要根据硬件资源选择(比如显卡显存小,就选 V=5000、D=128)
总结
本质:词元嵌入权重是词嵌入层的可训练参数矩阵(V×D),行对应词元 ID,列对应嵌入维度,是离散词元 ID 到连续词向量的转换桥梁
作用:训练前是随机映射表,训练后是模型的语义字典,让模型能把文字转换成可计算的数值特征,是理解自然语言的基础
训练:和隐藏层所有权重一样,通过反向传播计算梯度、梯度下降更新数值,训练后语义相近的词元对应行向量相似度高
关键:是大模型输入层唯一的可训练权重,其维度(V/D)是影响模型参数量和表达能力的核心超参数
词元嵌入权重就是大模型的「数字词典」
训练前是乱序的无字词典,训练后是按语义排序的精准词典,模型所有的语言理解和生成,都从查这本「词典」开始