文章目录
- 引言:为什么需要动态字符串处理?
- 一、框架设计核心思想
-
- [1.1 架构设计原则](#1.1 架构设计原则)
- [1.2 技术选型优势](#1.2 技术选型优势)
- 二、核心架构设计详解
-
- [2.1 统一处理器接口设计](#2.1 统一处理器接口设计)
- [2.2 工厂模式实现处理器管理](#2.2 工厂模式实现处理器管理)
- 三、处理器实现示例
-
- [3.1 基础文本处理处理器](#3.1 基础文本处理处理器)
- [3.2 高级文本处理处理器](#3.2 高级文本处理处理器)
- 四、Flink算子集成
-
- [4.1 灵活的处理链构建器](#4.1 灵活的处理链构建器)
- [4.2 带状态的处理函数](#4.2 带状态的处理函数)
- 五、配置与部署实践
-
- [5.1 配置管理策略](#5.1 配置管理策略)
- [5.2 热配置更新机制](#5.2 热配置更新机制)
- 六、监控与运维
-
- [6.1 监控指标设计](#6.1 监控指标设计)
- [6.2 性能优化建议](#6.2 性能优化建议)
- 七、实战案例:电商日志处理
-
- [7.1 业务场景](#7.1 业务场景)
- [7.2 处理流程配置](#7.2 处理流程配置)
- 八、总结与展望
-
- [8.1 框架优势总结](#8.1 框架优势总结)
- [8.2 未来演进方向](#8.2 未来演进方向)
- [8.3 最佳实践建议](#8.3 最佳实践建议)
- 附录:完整项目结构
引言:为什么需要动态字符串处理?
在实时数据处理场景中,字符串处理是最常见但也是最复杂的任务之一。传统的Flink作业往往将处理逻辑硬编码在算子函数中,导致以下问题:
- 代码僵化:每次业务逻辑变更都需要重新编译部署
- 复用性差:相似的处理逻辑无法在不同作业间复用
- 维护困难:随着业务增长,代码变得越来越臃肿
- 测试复杂:每个算子函数都需要单独测试验证
本文将介绍一种基于Flink的动态字符串处理框架,通过设计模式 、配置驱动 和模块化架构,实现处理逻辑的动态组合与灵活配置。
一、框架设计核心思想
1.1 架构设计原则
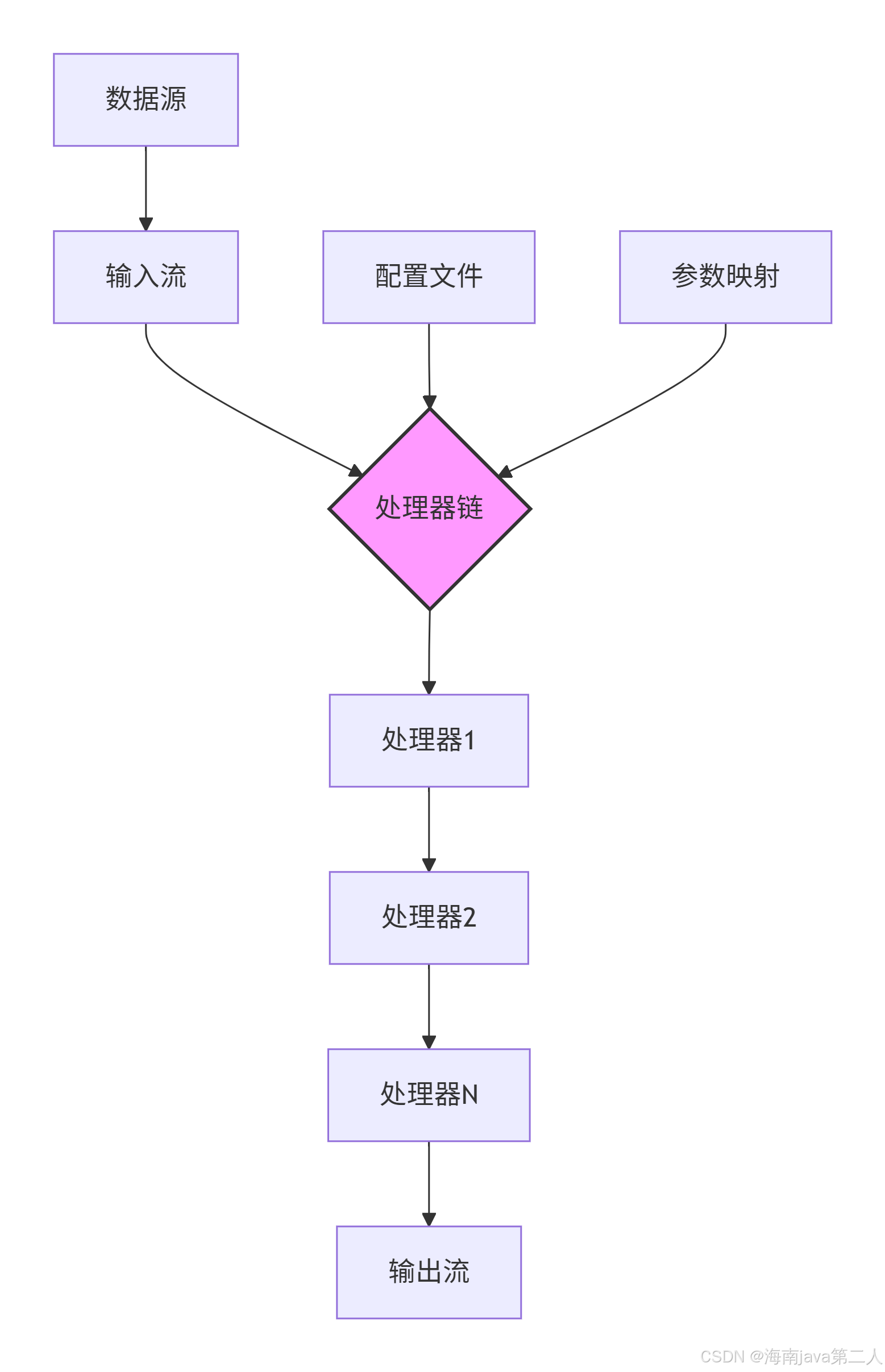
核心设计原则:
- 开闭原则:对扩展开放,对修改关闭
- 单一职责:每个处理器只负责一种处理逻辑
- 依赖倒置:依赖抽象接口而非具体实现
- 配置驱动:处理逻辑通过配置而非代码定义
1.2 技术选型优势
| 特性 | 传统方式 | 动态框架 |
|---|---|---|
| 代码复杂度 | 高(硬编码) | 低(配置化) |
| 部署频率 | 每次修改需部署 | 热配置更新 |
| 测试难度 | 集成测试困难 | 单元测试简单 |
| 复用性 | 低 | 高 |
| 可维护性 | 差 | 优秀 |
二、核心架构设计详解
2.1 统一处理器接口设计
java
/**
* 字符串处理器接口 - 统一处理契约
*
* 设计要点:
* 1. 统一的处理接口,便于扩展
* 2. 名称标识,支持动态查找
* 3. 支持处理前后的钩子方法(预留)
*/
public interface StringProcessor {
/**
* 处理字符串
* @param input 输入字符串
* @return 处理后的字符串,返回null表示过滤掉
*/
String process(String input);
/**
* 获取处理器名称
* 用于配置识别和日志追踪
*/
String getName();
/**
* 获取处理器描述
* 用于监控和管理界面展示
*/
default String getDescription() {
return "字符串处理器:" + getName();
}
/**
* 处理器初始化(可选)
* 用于加载资源或建立连接
*/
default void init() throws Exception {
// 默认空实现
}
/**
* 处理器清理(可选)
* 用于释放资源
*/
default void cleanup() throws Exception {
// 默认空实现
}
}2.2 工厂模式实现处理器管理
java
/**
* 处理器工厂 - 基于工厂模式管理所有处理器实例
*
* 核心功能:
* 1. 集中注册所有处理器类型
* 2. 支持参数化处理器实例创建
* 3. 提供处理器缓存机制
* 4. 支持处理器热加载
*/
public class ProcessorFactory {
// 处理器注册表 - 线程安全
private static final ConcurrentHashMap<String, Class<? extends StringProcessor>>
processorRegistry = new ConcurrentHashMap<>();
// 处理器实例缓存 - 减少对象创建开销
private static final ConcurrentHashMap<String, StringProcessor>
processorCache = new ConcurrentHashMap<>();
static {
// 自动扫描并注册处理器
registerDefaultProcessors();
}
/**
* 注册处理器类
* @param name 处理器名称
* @param processorClass 处理器类
*/
public static void registerProcessor(String name,
Class<? extends StringProcessor> processorClass) {
processorRegistry.put(name, processorClass);
processorCache.remove(name); // 清除缓存,确保使用新配置
}
/**
* 创建或获取处理器实例
* @param name 处理器名称
* @param params 处理器参数
* @return 处理器实例
*/
public static StringProcessor getProcessor(String name,
Map<String, Object> params) {
String cacheKey = name + "#" + hashParams(params);
// 双重检查锁定模式获取缓存实例
StringProcessor processor = processorCache.get(cacheKey);
if (processor == null) {
synchronized (ProcessorFactory.class) {
processor = processorCache.get(cacheKey);
if (processor == null) {
processor = createProcessorInstance(name, params);
processorCache.put(cacheKey, processor);
}
}
}
return processor;
}
/**
* 批量创建处理器实例
* 支持处理器依赖解析
*/
public static List<StringProcessor> getProcessors(List<String> processorChain,
Map<String, Map<String, Object>> paramsMap) {
List<StringProcessor> processors = new ArrayList<>();
for (String processorName : processorChain) {
try {
Map<String, Object> params = paramsMap.getOrDefault(processorName,
Collections.emptyMap());
// 检查处理器依赖
checkDependencies(processorName, params);
StringProcessor processor = getProcessor(processorName, params);
processors.add(processor);
} catch (Exception e) {
throw new IllegalStateException("创建处理器失败: " + processorName, e);
}
}
return processors;
}
private static StringProcessor createProcessorInstance(String name,
Map<String, Object> params) {
Class<? extends StringProcessor> clazz = processorRegistry.get(name);
if (clazz == null) {
throw new IllegalArgumentException("未注册的处理器: " + name);
}
try {
StringProcessor processor = clazz.newInstance();
// 如果处理器支持参数注入
if (processor instanceof ParameterizedProcessor) {
processor = ((ParameterizedProcessor) processor).createWithParams(params);
} else if (processor instanceof BaseProcessor) {
((BaseProcessor) processor).setParams(params);
}
// 初始化处理器
processor.init();
return processor;
} catch (Exception e) {
throw new RuntimeException("创建处理器实例失败: " + name, e);
}
}
// 其他辅助方法...
}三、处理器实现示例
3.1 基础文本处理处理器
java
/**
* 大写转换处理器
* 功能:将输入字符串转换为大写
* 应用场景:统一日志格式、数据标准化
*/
public class UpperCaseProcessor extends BaseProcessor {
public UpperCaseProcessor() {
super("uppercase", "将字符串转换为大写");
}
@Override
public String process(String input) {
if (input == null) return null;
long startTime = System.nanoTime();
try {
return input.toUpperCase();
} finally {
// 性能监控埋点
recordProcessTime(System.nanoTime() - startTime);
}
}
// 性能监控方法
private void recordProcessTime(long nanos) {
// 实际项目中可以接入监控系统
MetricRegistry.record("processor.uppercase.time", nanos);
}
}
/**
* 智能空格清理处理器
* 功能:智能清理字符串中的多余空格
* 特点:可配置保留模式
*/
public class SmartTrimProcessor extends BaseProcessor implements ParameterizedProcessor {
public enum TrimMode {
ALL, // 清理所有空格
EXTERNAL, // 只清理首尾空格
DUPLICATE // 清理重复空格
}
private TrimMode mode = TrimMode.EXTERNAL;
private boolean keepNewline = true;
public SmartTrimProcessor() {
super("smart_trim", "智能空格清理");
}
@Override
public String process(String input) {
if (input == null) return null;
switch (mode) {
case ALL:
return input.replaceAll("\\s+", "");
case EXTERNAL:
return input.trim();
case DUPLICATE:
String result = input.trim();
result = result.replaceAll("\\s+", " ");
if (!keepNewline) {
result = result.replaceAll("\\r?\\n", " ");
}
return result;
default:
return input.trim();
}
}
@Override
public StringProcessor createWithParams(Map<String, Object> params) {
SmartTrimProcessor processor = new SmartTrimProcessor();
if (params.containsKey("mode")) {
processor.mode = TrimMode.valueOf(
params.get("mode").toString().toUpperCase()
);
}
if (params.containsKey("keep_newline")) {
processor.keepNewline = Boolean.parseBoolean(
params.get("keep_newline").toString()
);
}
return processor;
}
}3.2 高级文本处理处理器
java
/**
* 正则表达式替换处理器
* 支持复杂文本模式匹配和替换
*/
public class RegexReplaceProcessor extends BaseProcessor implements ParameterizedProcessor {
private Pattern pattern;
private String replacement;
private int timeoutMs = 100; // 超时时间,防止ReDoS攻击
public RegexReplaceProcessor() {
super("regex_replace", "正则表达式替换");
}
@Override
public String process(String input) {
if (input == null || pattern == null) return input;
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<String> future = executor.submit(() ->
pattern.matcher(input).replaceAll(replacement)
);
try {
return future.get(timeoutMs, TimeUnit.MILLISECONDS);
} catch (TimeoutException e) {
future.cancel(true);
log.warn("正则处理超时,跳过处理: {}", input.substring(0, Math.min(50, input.length())));
return input; // 超时返回原字符串
} catch (Exception e) {
throw new RuntimeException("正则处理失败", e);
} finally {
executor.shutdownNow();
}
}
@Override
public StringProcessor createWithParams(Map<String, Object> params) {
RegexReplaceProcessor processor = new RegexReplaceProcessor();
String regex = (String) params.get("regex");
if (regex == null) {
throw new IllegalArgumentException("正则表达式不能为空");
}
processor.replacement = (String) params.getOrDefault("replacement", "");
processor.timeoutMs = (int) params.getOrDefault("timeout_ms", 100);
// 编译正则表达式,支持性能优化标志
int flags = 0;
if (Boolean.parseBoolean(params.getOrDefault("case_insensitive", "false").toString())) {
flags |= Pattern.CASE_INSENSITIVE;
}
processor.pattern = Pattern.compile(regex, flags);
return processor;
}
}
/**
* 敏感信息脱敏处理器
* 支持多种脱敏策略
*/
public class DataMaskingProcessor extends BaseProcessor implements ParameterizedProcessor {
public enum MaskingStrategy {
PHONE, // 手机号:138****1234
ID_CARD, // 身份证:110***********1234
EMAIL, // 邮箱:t***@example.com
BANK_CARD, // 银行卡:6222 **** **** 1234
CUSTOM // 自定义脱敏
}
private MaskingStrategy strategy;
private Pattern customPattern;
private String maskChar = "*";
@Override
public String process(String input) {
if (input == null) return null;
switch (strategy) {
case PHONE:
return maskPhone(input);
case ID_CARD:
return maskIdCard(input);
case EMAIL:
return maskEmail(input);
case BANK_CARD:
return maskBankCard(input);
case CUSTOM:
return customPattern != null ?
customPattern.matcher(input).replaceAll(maskChar.repeat(4)) : input;
default:
return input;
}
}
private String maskPhone(String phone) {
if (phone.length() >= 7) {
return phone.substring(0, 3) +
maskChar.repeat(4) +
phone.substring(7);
}
return phone;
}
// 其他脱敏方法实现...
}四、Flink算子集成
4.1 灵活的处理链构建器
java
/**
* 处理器链构建器
* 支持多种处理模式:
* 1. 顺序处理链
* 2. 条件分支处理
* 3. 并行处理
* 4. 带状态处理
*/
public class ProcessorChainBuilder {
/**
* 构建顺序处理链
*/
public static DataStream<String> buildSequentialChain(
DataStream<String> inputStream,
List<String> processorNames,
Map<String, Map<String, Object>> paramsMap,
ExecutionConfig config) {
DataStream<String> currentStream = inputStream;
for (int i = 0; i < processorNames.size(); i++) {
final String processorName = processorNames.get(i);
final int stage = i;
currentStream = currentStream
.map(new RichMapFunction<String, String>() {
private transient StringProcessor processor;
private transient MetricGroup metrics;
private transient Counter processedCounter;
private transient Counter errorCounter;
@Override
public void open(Configuration parameters) {
Map<String, Object> params = paramsMap.getOrDefault(
processorName, Collections.emptyMap()
);
this.processor = ProcessorFactory.getProcessor(processorName, params);
// 初始化监控指标
this.metrics = getRuntimeContext().getMetricGroup();
this.processedCounter = metrics.counter("processed_count");
this.errorCounter = metrics.counter("error_count");
// 初始化处理器
try {
processor.init();
} catch (Exception e) {
throw new RuntimeException("处理器初始化失败: " + processorName, e);
}
}
@Override
public String map(String value) {
processedCounter.inc();
long startTime = System.currentTimeMillis();
try {
String result = processor.process(value);
// 记录处理延迟
metrics.histogram("process_latency")
.update(System.currentTimeMillis() - startTime);
return result;
} catch (Exception e) {
errorCounter.inc();
metrics.meter("error_rate").markEvent();
// 错误处理策略:跳过、重试或使用默认值
if (config.isSkipOnError()) {
return config.getDefaultValue();
}
throw e;
}
}
@Override
public void close() {
if (processor != null) {
try {
processor.cleanup();
} catch (Exception e) {
log.error("处理器清理失败", e);
}
}
}
})
.name(String.format("processor-%s-stage-%d", processorName, stage))
.setParallelism(config.getParallelism())
.uid(String.format("processor-%s-%d", processorName, stage)); // 设置UID便于状态恢复
// 添加检查点屏障对齐
if (config.isCheckpointEnabled()) {
currentStream = currentStream
.map(value -> value)
.name("checkpoint-barrier")
.uid(String.format("barrier-%d", stage));
}
}
return currentStream;
}
/**
* 构建条件分支处理链
*/
public static DataStream<String> buildConditionalChain(
DataStream<String> inputStream,
Map<String, Predicate<String>> conditions,
Map<String, List<String>> branchProcessors,
Map<String, Map<String, Map<String, Object>>> branchParams) {
// 为每个分支创建OutputTag
Map<String, OutputTag<String>> outputTags = new HashMap<>();
conditions.keySet().forEach(branch ->
outputTags.put(branch, new OutputTag<String>(branch + "-output") {})
);
// 主流程处理
SingleOutputStreamOperator<String> mainStream = inputStream
.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, Context ctx,
Collector<String> out) {
boolean matched = false;
// 检查每个条件
for (Map.Entry<String, Predicate<String>> entry : conditions.entrySet()) {
if (entry.getValue().test(value)) {
ctx.output(outputTags.get(entry.getKey()), value);
matched = true;
break;
}
}
// 默认分支
if (!matched) {
out.collect(value);
}
}
});
// 为每个分支构建处理链
Map<String, DataStream<String>> branchStreams = new HashMap<>();
for (String branch : conditions.keySet()) {
DataStream<String> branchStream = mainStream.getSideOutput(outputTags.get(branch));
List<String> processors = branchProcessors.get(branch);
Map<String, Map<String, Object>> params = branchParams.get(branch);
if (processors != null && !processors.isEmpty()) {
branchStream = buildSequentialChain(branchStream, processors, params,
new ExecutionConfig());
}
branchStreams.put(branch, branchStream);
}
// 合并所有分支结果
DataStream<String> defaultStream = mainStream;
for (DataStream<String> branchStream : branchStreams.values()) {
defaultStream = defaultStream.union(branchStream);
}
return defaultStream;
}
}4.2 带状态的处理函数
java
/**
* 带状态的字符串处理器
* 支持窗口聚合、去重等状态操作
*/
public class StatefulProcessor extends RichMapFunction<String, String> {
// 值状态:存储最新处理结果
private transient ValueState<String> lastProcessedState;
// 列表状态:存储历史记录
private transient ListState<String> historyState;
// 聚合状态:统计信息
private transient AggregatingState<String, ProcessingStats> statsState;
// 广播状态:存储配置
private transient BroadcastState<String, String> configState;
@Override
public void open(Configuration parameters) {
// 初始化值状态
ValueStateDescriptor<String> lastProcessedDesc =
new ValueStateDescriptor<>("last-processed", String.class);
lastProcessedState = getRuntimeContext().getState(lastProcessedDesc);
// 初始化列表状态
ListStateDescriptor<String> historyDesc =
new ListStateDescriptor<>("history", String.class);
historyState = getRuntimeContext().getListState(historyDesc);
// 初始化聚合状态
AggregatingStateDescriptor<String, ProcessingStats, ProcessingStats> statsDesc =
new AggregatingStateDescriptor<>(
"processing-stats",
new StatsAggregateFunction(),
ProcessingStats.class
);
statsState = getRuntimeContext().getAggregatingState(statsDesc);
}
@Override
public String map(String value) throws Exception {
// 获取上次处理结果进行对比
String lastProcessed = lastProcessedState.value();
lastProcessedState.update(value);
// 保存到历史记录
historyState.add(value);
// 更新统计信息
statsState.add(value);
// 应用处理逻辑
String result = processWithState(value, lastProcessed);
return result;
}
private String processWithState(String current, String previous) {
// 基于状态的复杂处理逻辑
if (previous != null && current.equals(previous)) {
return "REPEATED: " + current;
}
return "UNIQUE: " + current;
}
/**
* 清理过期的历史记录
*/
public void cleanupOldHistory(long maxHistorySize) throws Exception {
List<String> history = Lists.newArrayList(historyState.get().iterator());
if (history.size() > maxHistorySize) {
historyState.clear();
// 保留最新的记录
for (String record : history.subList(history.size() - (int)maxHistorySize,
history.size())) {
historyState.add(record);
}
}
}
// 统计信息聚合函数
private static class StatsAggregateFunction
implements AggregateFunction<String, ProcessingStats, ProcessingStats> {
@Override
public ProcessingStats createAccumulator() {
return new ProcessingStats();
}
@Override
public ProcessingStats add(String value, ProcessingStats accumulator) {
accumulator.incrementCount();
accumulator.addLength(value.length());
return accumulator;
}
@Override
public ProcessingStats getResult(ProcessingStats accumulator) {
return accumulator;
}
@Override
public ProcessingStats merge(ProcessingStats a, ProcessingStats b) {
return ProcessingStats.merge(a, b);
}
}
}五、配置与部署实践
5.1 配置管理策略
yaml
# application.yaml
flink:
job:
name: "dynamic-string-processor"
parallelism: 4
checkpoint:
enabled: true
interval: 60000
mode: EXACTLY_ONCE
processors:
chain:
- name: "input_validation"
processors: ["trim", "filter_empty", "validate_length"]
params:
filter_empty:
remove_null: true
validate_length:
min: 1
max: 1000
- name: "data_cleaning"
processors: ["remove_html", "smart_trim", "normalize_encoding"]
params:
remove_html:
keep_breaks: true
normalize_encoding:
target: "UTF-8"
- name: "data_masking"
processors: ["mask_sensitive"]
params:
mask_sensitive:
patterns:
- type: "PHONE"
- type: "EMAIL"
- type: "ID_CARD"
- name: "data_enrichment"
processors: ["add_timestamp", "add_metadata"]
params:
add_timestamp:
format: "yyyy-MM-dd HH:mm:ss"
add_metadata:
source: "dynamic-processor"
version: "1.0"
monitoring:
metrics:
enabled: true
reporters:
- type: "jmx"
- type: "prometheus"
port: 9250
logging:
level: "INFO"
format: "json"
error_handling:
strategy: "SKIP_AND_LOG"
max_retries: 3
retry_delay: 1000
dead_letter_queue:
enabled: true
topic: "dlq.string-processing"5.2 热配置更新机制
java
/**
* 热配置更新管理器
* 支持运行时动态更新处理器配置
*/
public class HotConfigManager {
private final BroadcastStream<ConfigUpdateEvent> configStream;
private final MapStateDescriptor<String, String> configDescriptor;
public HotConfigManager(StreamExecutionEnvironment env) {
// 配置更新事件流(可以从Kafka、文件系统等读取)
DataStream<ConfigUpdateEvent> configSource = env
.addSource(new ConfigUpdateSource())
.name("config-update-source");
// 广播配置更新
configDescriptor = new MapStateDescriptor<>(
"processor-configs",
String.class,
String.class
);
this.configStream = configSource
.broadcast(configDescriptor);
}
/**
* 连接配置流与数据流
*/
public DataStream<String> connectWithConfig(
DataStream<String> dataStream,
String processorChainId) {
return dataStream
.connect(configStream)
.process(new ConfigAwareProcessorFunction(processorChainId))
.name("config-aware-processor")
.uid("config-aware-" + processorChainId);
}
/**
* 配置感知的处理器函数
*/
private static class ConfigAwareProcessorFunction
extends BroadcastProcessFunction<String, ConfigUpdateEvent, String> {
private final String chainId;
private transient List<StringProcessor> currentProcessors;
private transient long lastUpdateTime;
public ConfigAwareProcessorFunction(String chainId) {
this.chainId = chainId;
}
@Override
public void open(Configuration parameters) throws Exception {
// 从广播状态加载初始配置
loadProcessors(getRuntimeContext().getBroadcastState(configDescriptor));
}
@Override
public void processElement(String value, ReadOnlyContext ctx,
Collector<String> output) throws Exception {
// 检查配置是否需要更新(例如,每分钟检查一次)
if (System.currentTimeMillis() - lastUpdateTime > 60000) {
loadProcessors(ctx.getBroadcastState(configDescriptor));
lastUpdateTime = System.currentTimeMillis();
}
// 应用当前处理器链
String result = value;
for (StringProcessor processor : currentProcessors) {
result = processor.process(result);
if (result == null) {
return; // 被过滤掉
}
}
output.collect(result);
}
@Override
public void processBroadcastElement(ConfigUpdateEvent event, Context ctx,
Collector<String> output) throws Exception {
// 更新广播状态
BroadcastState<String, String> state = ctx.getBroadcastState(configDescriptor);
state.put(event.getKey(), event.getValue());
// 立即更新本地处理器(可选)
if (event.getChainId().equals(chainId)) {
loadProcessors(state);
}
}
private void loadProcessors(ReadOnlyBroadcastState<String, String> state)
throws Exception {
String configJson = state.get(chainId);
if (configJson != null) {
ProcessorChainConfig config = parseConfig(configJson);
this.currentProcessors = ProcessorFactory.getProcessors(
config.getProcessors(),
config.getParams()
);
}
}
}
}六、监控与运维
6.1 监控指标设计
java
/**
* 监控指标管理器
*/
public class MetricsManager {
public static void registerProcessorMetrics(String processorName,
MetricGroup metricGroup) {
// 处理计数器
Counter processedCounter = metricGroup.counter("processed_total");
Counter errorCounter = metricGroup.counter("errors_total");
// 处理延迟直方图
Histogram latencyHistogram = metricGroup.histogram("process_latency_ms",
new SlidingWindowHistogram(1000, 100));
// 吞吐量计量器
Meter throughputMeter = metricGroup.meter("throughput",
new SlidingWindowMovingAverage(60));
// 队列长度计量
Gauge<Integer> queueSizeGauge = () -> getQueueSize(processorName);
metricGroup.gauge("queue_size", queueSizeGauge);
// 状态大小监控(针对有状态处理器)
Gauge<Long> stateSizeGauge = () -> getStateSize(processorName);
metricGroup.gauge("state_size_bytes", stateSizeGauge);
}
/**
* 健康检查端点
*/
@RestController
@RequestMapping("/health")
public static class HealthController {
@Autowired
private ProcessorHealthChecker healthChecker;
@GetMapping("/processor/{name}")
public ResponseEntity<HealthStatus> checkProcessorHealth(
@PathVariable String name) {
HealthStatus status = healthChecker.checkProcessor(name);
return status.isHealthy() ?
ResponseEntity.ok(status) :
ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE).body(status);
}
@GetMapping("/chain/{chainId}")
public ResponseEntity<ChainHealth> checkChainHealth(
@PathVariable String chainId,
@RequestParam(defaultValue = "false") boolean deepCheck) {
ChainHealth health = healthChecker.checkChain(chainId, deepCheck);
return health.isOperational() ?
ResponseEntity.ok(health) :
ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE).body(health);
}
}
}6.2 性能优化建议
-
并行度优化:
java// 根据处理器类型设置不同的并行度 public class ParallelismOptimizer { public static int optimizeParallelism(String processorType, long estimatedQps) { switch (processorType) { case "cpu_intensive": // CPU密集型:正则、加密等 return Runtime.getRuntime().availableProcessors() * 2; case "io_intensive": // IO密集型:外部服务调用 return Runtime.getRuntime().availableProcessors() * 4; case "memory_intensive": // 内存密集型:大对象处理 return Math.max(1, Runtime.getRuntime().availableProcessors() / 2); default: return Runtime.getRuntime().availableProcessors(); } } } -
状态优化:
java// 使用TTL清理过期状态 StateTtlConfig ttlConfig = StateTtlConfig .newBuilder(Time.days(7)) .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) .cleanupInRocksdbCompactFilter(1000) .build(); stateDescriptor.enableTimeToLive(ttlConfig);
七、实战案例:电商日志处理
7.1 业务场景
- 需求:实时处理电商用户行为日志
- 挑战:数据格式多样、包含敏感信息、需要实时统计
7.2 处理流程配置
json
{
"processing_pipeline": {
"name": "ecommerce_log_processor",
"description": "电商日志实时处理流水线",
"stages": [
{
"name": "raw_log_parser",
"processors": ["json_extract", "validate_schema"],
"params": {
"json_extract": {
"fields": ["userId", "action", "timestamp", "productId", "price"],
"required": ["userId", "action", "timestamp"]
},
"validate_schema": {
"schema_file": "log_schema.json"
}
}
},
{
"name": "data_cleaning",
"processors": ["trim_all", "normalize_action", "filter_invalid"],
"params": {
"normalize_action": {
"mappings": {
"view": "PAGE_VIEW",
"click": "BUTTON_CLICK",
"buy": "PURCHASE"
}
},
"filter_invalid": {
"rules": [
{"field": "userId", "pattern": "^U\\d{8}$"},
{"field": "timestamp", "min": 1609459200000}
]
}
}
},
{
"name": "data_enrichment",
"processors": ["add_user_segment", "add_product_category"],
"params": {
"add_user_segment": {
"lookup_table": "user_segments",
"cache_ttl": 300
},
"add_product_category": {
"service_url": "http://product-service/category",
"timeout": 1000
}
}
},
{
"name": "data_masking",
"processors": ["mask_pii"],
"params": {
"mask_pii": {
"fields": ["ip", "deviceId", "email"],
"strategy": "partial_mask"
}
}
}
],
"outputs": [
{
"type": "kafka",
"topic": "cleaned_logs",
"format": "json"
},
{
"type": "elasticsearch",
"index": "user_behavior",
"id_field": "logId"
}
],
"monitoring": {
"alerts": [
{
"metric": "error_rate",
"threshold": 0.01,
"window": "5m",
"severity": "warning"
},
{
"metric": "processing_latency_p99",
"threshold": 1000,
"window": "10m",
"severity": "critical"
}
]
}
}
}八、总结与展望
8.1 框架优势总结
- 高度可配置:通过配置而非代码定义处理流程
- 灵活扩展:易于添加新的处理器类型
- 生产就绪:完善的监控、容错和运维支持
- 性能优异:支持并行处理、状态优化和资源控制
- 易于维护:清晰的模块边界和标准接口
8.2 未来演进方向
- AI集成:支持机器学习模型作为处理器
- 动态编排:基于流量模式的自动处理器调度
- 多语言支持:通过gRPC集成Python/Go编写的处理器
- Serverless部署:按需分配处理资源
- 可视化编排:图形界面拖拽式构建处理流水线
8.3 最佳实践建议
- 渐进式部署:先在小流量环境验证,再逐步推广
- 全面监控:建立完整的监控告警体系
- 定期审计:定期检查处理器配置和运行状态
- 文档完善:为每个处理器编写详细的使用文档
- 性能测试:定期进行压力测试和性能优化
如需获取更多关于 Flink流处理核心机制、状态管理与容错、实时数仓架构 等深度解析,请持续关注本专栏《Flink核心技术深度与实践》系列文章。
附录:完整项目结构
dynamic-flink-processor/
├── README.md # 项目说明文档
├── pom.xml # Maven配置文件
├── src/main/java/
│ ├── config/ # 配置管理
│ │ ├── ProcessorConfig.java
│ │ ├── PipelineConfig.java
│ │ └── HotConfigManager.java
│ ├── core/ # 核心接口
│ │ ├── StringProcessor.java
│ │ ├── ParameterizedProcessor.java
│ │ └── BaseProcessor.java
│ ├── factory/ # 工厂类
│ │ └── ProcessorFactory.java
│ ├── processors/ # 处理器实现
│ │ ├── basic/ # 基础处理器
│ │ ├── advanced/ # 高级处理器
│ │ └── custom/ # 自定义处理器
│ ├── flink/ # Flink集成
│ │ ├── ProcessorChainBuilder.java
│ │ ├── StatefulProcessor.java
│ │ └── BroadcastProcessor.java
│ ├── monitor/ # 监控模块
│ │ ├── MetricsManager.java
│ │ ├── HealthChecker.java
│ │ └── AlertManager.java
│ └── utils/ # 工具类
│ ├── JsonUtils.java
│ ├── ValidationUtils.java
│ └── PerformanceUtils.java
├── src/main/resources/
│ ├── application.yaml # 主配置文件
│ ├── processor-definitions/ # 处理器定义文件
│ └── schemas/ # 数据模式定义
├── src/test/ # 测试代码
│ ├── unit/ # 单元测试
│ └── integration/ # 集成测试
└── docs/ # 文档
├── api-guide.md # API指南
├── deployment-guide.md # 部署指南
└── troubleshooting.md # 故障排查