摘要
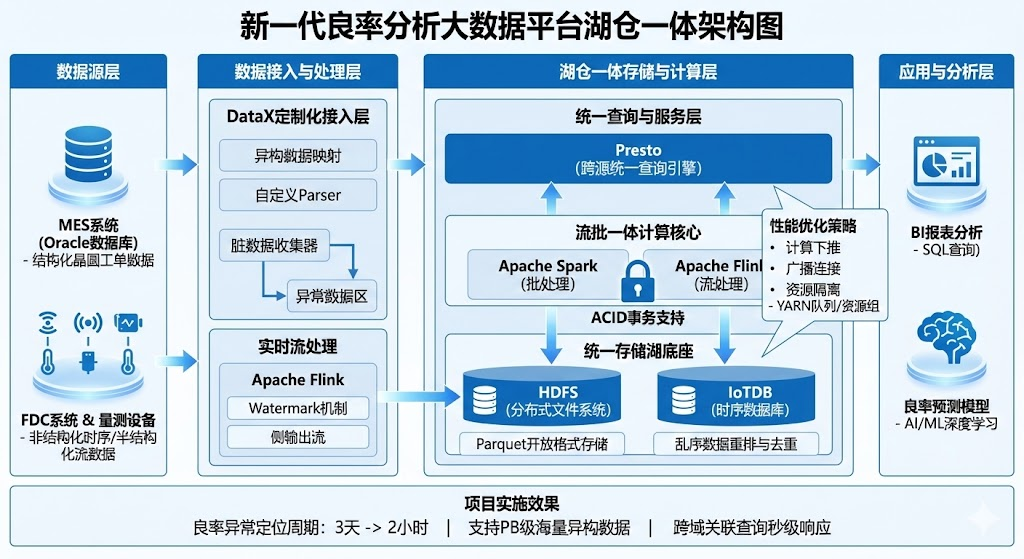
2024年3月,我参与了某大型半导体晶圆制造企业"新一代良率分析大数据平台"的研发工作,在项目中担任系统架构师,负责整体架构设计与技术选型。该企业面临生产数据规模大(PB级)、类型异构(结构化MES数据与非结构化时序数据并存)、时效性要求高的问题。传统单一的数据湖或数据仓库架构已难以满足全流程良率归因分析的需求。为此,我设计了一套基于"湖仓一体"理念的现代大数据架构:底层采用HDFS与IoTDB构建统一存储湖,使用Parquet开放格式存储数据;中间层利用Spark与Flink引擎实现流批一体计算,并引入ACID事务支持;上层通过Presto引擎实现跨源统一查询。本文将结合项目实践,论述湖仓一体架构的事务一致性支持、开放存储格式、存算分离、多样化计算支持四大关键特征,并详细阐述在项目实施过程中如何解决异构数据类型映射、乱序数据处理及跨域关联查询性能优化等实际问题。平台上线后,良率异常定位周期从3天缩短至2小时,有效支撑了先进制程的良率爬坡。
正文
一、项目背景与问题分析
半导体集成电路制造流程极长,涉及光刻、刻蚀等数百道工序。我所在的半导体企业随着产能扩张,数据管理面临严峻挑战。作为架构师,我经过调研发现,原有的烟囱式架构存在三大痛点:一是数据异构严重,MES的结构化数据、FDC的毫秒级时序数据及量测设备的半结构化文件分散在不同系统;二是时效性与成本的矛盾,传统数仓难以兼顾实时报警与海量历史分析;三是跨域分析困难,良率工程师需要关联分析"光刻机参数(时序数据)"与"晶圆工单(关系型数据)",原有架构查询效率极低。
面对海量、多模态、高并发的数据处理需求,传统的数据仓库无法处理半结构化数据,而单纯的数据湖缺乏事务管理和高性能查询能力。因此,我决定采用"湖仓一体(Lakehouse)"架构,旨在构建一个既拥有数据湖的灵活性与低成本,又具备数据仓库的管理能力与高性能的新一代数据平台。
二、湖仓一体架构的核心特征分析
湖仓一体架构是大数据体系演进的最新形态,它打破了数据湖与数据仓库的物理壁垒。结合本项目实践,我认为其具备以下四大关键特征:
-
支持事务的一致性: 这是湖仓区别于传统数据湖的核心。它允许在并发读写环境下保证数据的原子性、一致性、隔离性和持久性,解决了数据湖中常见的脏读和更新困难问题,使得在湖上直接进行即席查询和数据修正成为可能。
-
开放的标准存储格式: 湖仓一体通常采用Parquet、ORC等开源列式存储格式,而非数据库厂商的私有格式。这意味着数据只需存储一份,即可被Spark、Presto、Flink等多种计算引擎直接读取,无需并在引擎间通过ETL搬运,极大提升了效率。
-
存算分离: 存储资源(如对象存储或HDFS)与计算资源(如Spark集群)独立扩展。在半导体场景中,历史数据量巨大但计算频率相对较低,存算分离能让我们以低廉的成本存储PB级数据,仅在需要分析时动态扩容计算节点。
-
多样化的数据分析支持: 统一的数据底座既能支持BI报表(SQL查询),也能支持机器学习(AI/ML)。这对于良率分析至关重要,因为我们既需要看报表,也需要运行深度学习模型来预测设备故障。
三、项目的具体实施与问题解决
在本项目中,我设计了"IoTDB + HDFS"作为统一存储底座,Flink与Spark作为计算核心,Presto作为统一服务接口的湖仓架构。以下详述我在设计与实现过程中,针对上述特征遇到的实际问题及解决方案。
1. 针对"开放存储格式与多源异构"特征:解决异构数据类型的统一映射问题
问题描述: 湖仓一体要求底层存储尽可能标准化。然而,核心生产系统MES(Oracle数据库)使用了大量非标准的自定义数据类型,而FDC系统产生的是私有格式的二进制流。直接同步至湖仓的Parquet或Hive表时,经常出现精度丢失、乱码或类型不兼容,破坏了数据的可用性。
解决方案: 我基于DataX 中间件开发了定制化的"数据接入层"。针对Oracle的特殊类型,我重写了Reader插件,建立了一套严格的元数据映射标准,例如将Oracle的NUMBER类型精准映射为Hive/Parquet的DECIMAL类型,并在写入前进行预处理。对于非结构化数据,通过自定义Parser将其元数据抽取为标准格式。同时,配置脏数据收集器(Dirty Data Collector),将清洗失败的数据分流至异常区,确保进入"湖仓"的数据必须符合开放标准格式的要求。
2. 针对"事务一致性"特征:解决实时流数据乱序与修正问题
问题描述: 在构建实时数仓层时,设备传感器每秒产生数千万条日志。由于工厂网络波动,数据经常出现乱序甚至迟到。在传统数据湖中,一旦文件写入完成,很难对历史数据进行精准的行级更新或插入,导致实时分析结果不准确,违背了ACID中的一致性要求。
解决方案: 我利用Flink 结合IoTDB构建了流批一体的处理层。首先,在Flink中引入Watermark(水位线)机制,允许数据延迟5秒到达,处理轻微乱序。对于严重迟到的数据,通过侧输出流(Side Output)捕获。更关键的是,利用IoTDB作为时序数据的特化"湖仓存储",它原生支持乱序数据的自动重排与去重写入。通过这种机制,我们在流式写入的高并发场景下,依然保证了最终数据的一致性,满足了生产监控的严苛要求。
3. 针对"存算分离"特征:解决跨域联邦查询的内存溢出(OOM)
问题描述: 平台上线初期,良率工程师经常执行此类查询:"分析过去三个月所有涉及光刻机A(位于IoTDB海量存储)的工单(位于Hive/HDFS)的良率"。这是典型的存算分离场景下的跨域Join。由于数据量极大(亿级Join千万级),计算引擎Presto经常发生内存溢出(OOM),导致集群崩溃。
解决方案: 这一问题的根源在于计算节点试图将海量存储数据全部拉取到内存中计算。我采取了"计算下推(Push Down)"与"广播连接(Broadcast Join)"相结合的策略:
-
计算下推: 开发IoTDB的Presto Connector,将时间范围过滤(Filter)和降采样聚合算子下推至存储层(IoTDB)执行。这样,网络传输的不再是数亿条原始明细,而是聚合后的数千条统计数据,充分利用了存储层的计算能力。
-
广播连接: 针对工单维度表较小的特点,强制开启Broadcast Join,将工单表广播至所有计算节点,避免了大表Shuffle带来的巨大开销。 通过上述优化,在不增加硬件成本的情况下,跨源复杂查询响应时间从分钟级降低至秒级,充分发挥了存算分离的优势。
4. 针对"多样化计算支持"特征:实现BI与AI负载的资源隔离
问题描述: 随着平台推广,BI报表查询和数据科学家的模型训练任务经常争抢资源,导致关键生产报表延迟。
解决方案: 我利用Presto的资源组和YARN队列,对不同负载实施了严格的资源隔离。将高优先级的BI查询路由至"交互式队列",保证低延迟;将耗资源的良率预测模型训练任务路由至"批处理队列"。这种基于策略的调度,确保了同一套湖仓数据底座能同时服务于敏捷BI和深度学习两种截然不同的业务场景。
四、总结与展望
本项目成功构建了基于湖仓一体架构的良率分析平台,纳管了全厂PB级数据,彻底打破了MES与FDC之间的数据孤岛。实践证明,湖仓一体架构通过开放格式、存算分离和统一查询引擎,完美契合了现代高端制造业对于海量异构数据处理的复杂需求。
当然,当前架构在处理非结构化图像(如晶圆缺陷AOI图片)时,仍主要依赖文件索引,检索效率有待提升。未来,我计划引入向量数据库(Vector DB)和多模态大模型技术,赋予湖仓架构"以图搜图"的智能化检索能力,进一步挖掘数据的深层价值。