Is Mamba Effective for Time Series Forecasting ?
它提出基于Transformer模型 在真实场景的时间序列预测中面临的问题:缺乏处理大规模数据 的计算效率 和资源扩展性
由于Transformer架构的固有二次方计算复杂度,随着数据量的增加 ,其计算成本呈现爆炸式增长 ,导致它缺乏在资源受限或高实时性要求场景下的生存能力。
1、缺乏线性的计算效率
Transformer的注意力机制在计算时,其运算量与输入序列长度或变量数量的平方成正比 ,这意味着,如果输入数据的长度或变量数量增加一倍 ,计算量会增加四倍 。在真实场景中,往往涉及大量的传感器和需要回溯很长的历史数据 ,这会导致计算开销急剧增加。相比之下,线性模型或Mamba 这类状态空间模型(State Space Model, SSM)具有线性复杂度(O(N)O(N)O(N)), 运算速度更快。
2、缺乏低资源占用的轻量化特性
由于计算复杂度高,Transformer模型在处理长序列时会消耗大量的GPU资源,这会导致模型在推理过程中对硬件设备要求较高。
3、缺乏处理"高维变量"时的全局捕捉能力
为了捕捉变量间的相关性,Transformer需要进行全局注意力计算。随着变量数量的增加 ,计算负载呈现指数级上升,这使得在变量众多的场景下,使用Transformer变得不切合实际。
总的来说:尽管 Transformer 在捕捉模式上很强大 ,但它缺乏像 Mamba 或线性模型那样的高效性与低成本特性 。
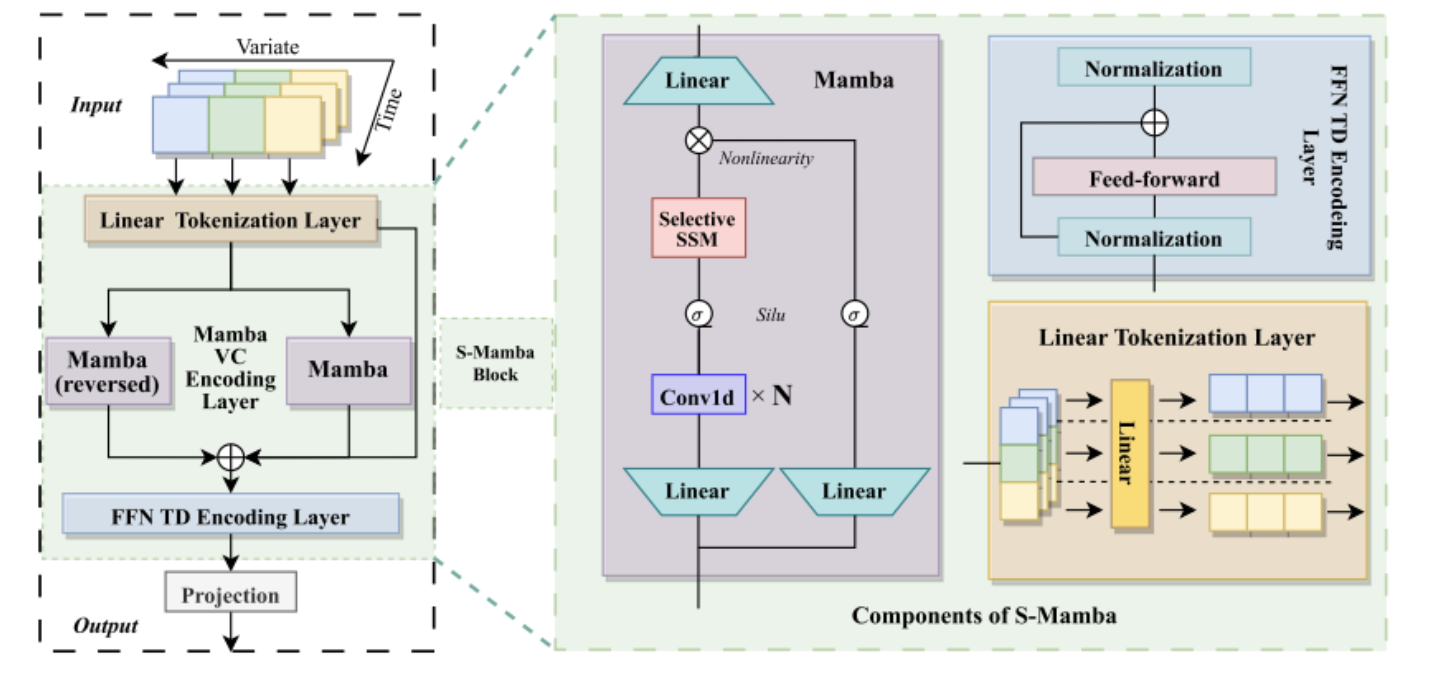
Mamba Block 处理输入序列 X (维度为 B ×V ×D) 的过程可以分为以下几个关键步骤:
1、线性投影与扩展 (Linear Projection)
- 输入数据首先通过线性层进行投影,将隐藏层维度扩展为原来的 E 倍(通常 E=2)。
- 这一步生成了两个分支:主分支 x 和 残差门控分支 z。
2、卷积与激活 (Convolution & Activation)
- 主分支 x 会经过一个一维卷积层 (Conv1D) 和 SiLU 激活函数处理,得到 x′。
- 作用: 这里的小卷积核主要用于捕捉局部的上下文信息,类似于给数据做一个平滑处理或局部特征提取
3、选择性状态空间模型 (Selective SSM)
传统的 SSM 参数是固定的,而 Mamba 让参数变成**"输入依赖" (Input-Dependent)** 的。
(1)参数生成: 模型根据当前的输入 x′,通过线性层动态计算出三个关键参数:
① Δ (步长/时间尺度)
② B (输入控制矩阵)
③ C (输出控制矩阵)
(2)离散化 (Discretization): 利用生成的 Δ,将连续的状态矩阵 A 和 B 转化为离散形式 (A ˉ,Bˉ)。这一步让模型能够适应不同采样率的数据,。
(3)状态递归: 执行核心的递归计算 ht=Aht−1+Bxth_t=Ah_{t−1}+Bx_tht=Aht−1+Bxt。
选择性机制的意义: 因为 Δ, B , C 是随输入变化的,模型可以根据当前输入的内容,自主决定是**"记住"这个信息(更新进隐状态hth_tht),还是 "遗忘"它(重置状态)。这实现了类似 Transformer 注意力机制的信息筛选功能**。
4、门控与输出 (Gating & Output)
经过 SSM 处理后的输出 y ,会与第一步生成的门控分支 z (经过 SiLU 激活后) 进行逐元素相乘(y ′=y ⊗SiLU(z))。
最后,通过一个线性层将维度映射回原始大小 ,得到最终输出 Y。
Mamba架构相比Transformer架构,计算速度快在哪?
Mamba 基于状态空间模型 (SSM),它将历史信息压缩到一个固定的隐状态 (Hidden State)中,无论序列多长,它在每个时间步的计算量 是固定的。因此,其计算复杂度随序列长度呈线性增长 (O(N)O(N)O(N))
Mamba 的数学基础是离散化的状态空间模型,递归计算 ht=Aht−1+Bxth_t=Ah_{t−1}+Bx_tht=Aht−1+Bxt。只用计算上一步的隐藏状态和当前输入即可计算下一步的状态。
Mamba 在生成第 N +1 个点时,它不需要看之前的 N 个输入,只需要看上一时刻的一个固定大小的隐状态(Hidden State) h**t 。 无论历史序列长度是 100 还是 10000,Mamba 生成下一步的计算量永远是常数级 O(1)。