Kimi K2.5震撼发布:视觉智能体革命,多智能体并行让AI提速4.5倍!
研究背景
大语言模型(LLM)正在快速向智能体(Agent)方向演进。像GPT-5.2、Claude Opus 4.5这些模型虽然在工具调用和推理上已经很强了,但它们有个致命缺陷------所有任务都是串行执行的。就像一个人再厉害,也得一件事一件事地做,遇到复杂任务就会陷入"排队等待"的困境,延迟高得让人抓狂。
Moonshot AI团队推出的Kimi K2.5要解决的就是这个痛点。这篇论文提出了两个核心创新:
- 文本和视觉的联合优化:不是简单地把视觉能力"贴"到语言模型上,而是让两种模态从训练之初就相互促进、共同成长
- Agent Swarm(智能体蜂群):一个能动态分解任务、并行执行的多智能体框架,把"单线程"变成"多核处理器"
最牛的是,Kimi K2.5不仅在编程、视觉理解、推理等各个领域达到了业界顶尖水平,在需要大规模搜索的任务上,延迟降低了4.5倍。更重要的是,他们把训练好的模型开源了,让整个社区都能基于此进行研究和应用开发。
相关工作
传统的多模态大模型训练思路是:先训练一个强大的语言模型,然后在训练后期加入大量视觉数据(占比可能高达50%以上),期望快速获得视觉能力。这种"先文本后视觉"的策略看似合理,但实际上存在两个问题:
第一,模态冲突。语言和视觉是两套完全不同的"语言系统",后期强行融合容易导致一方能力的退化。就像一个专业翻译突然要兼职做摄影师,很可能两头都做不好。
第二,串行执行的瓶颈。现有的智能体系统,即使能进行数百步推理(比如Kimi K2-Thinking),但每一步都要等上一步完成,遇到需要同时查询多个信息源、处理多个分支任务的场景,等待时间会线性增长,用户体验极差。
已有的一些方法尝试通过上下文管理(比如丢弃工具结果、总结历史)来缓解这个问题,但这些都是"被动应对"------相当于内存不够了就删东西,而不是从根本上解决并行处理的问题。
核心方法
文本视觉联合优化
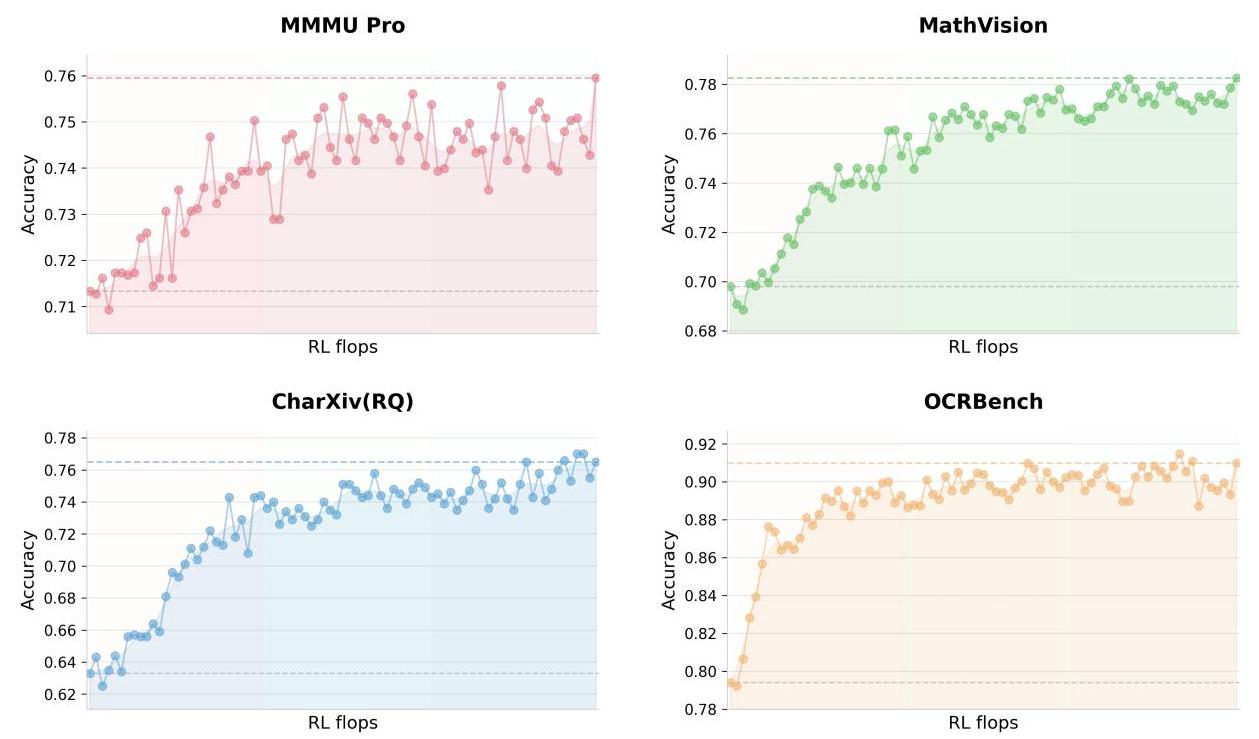
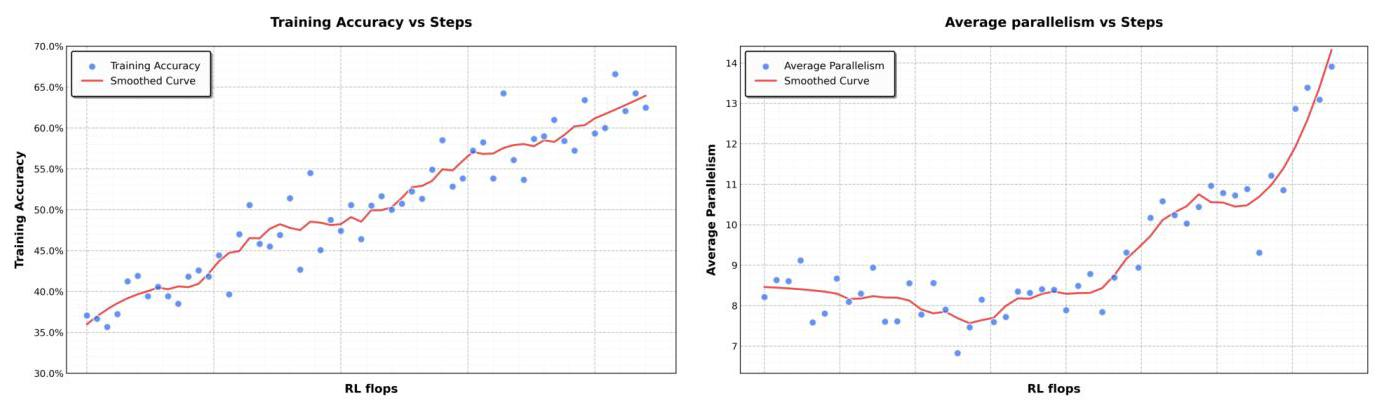
Kimi K2.5的第一个核心洞察是:给定固定的训练预算,早期以较低比例引入视觉数据,比后期集中灌入大量视觉数据效果更好。
他们做了一系列实验(见表1),发现在总token预算相同的情况下:
- 早期融合(从训练0%时刻开始)+ 低视觉比例(10%)
- 中期融合(从训练50%时刻开始)+ 中视觉比例(20%)
- 后期融合(从训练80%时刻开始)+ 高视觉比例(50%)
结果是早期融合效果最好!这完全颠覆了传统认知。
基于这个发现,Kimi K2.5采用了"原生多模态预训练"策略------从训练一开始就以恒定比例混合文本和视觉token,让模型自然地发展出平衡的多模态表征。
MoonViT-3D:图像视频共享的视觉编码器
在架构上,他们设计了MoonViT-3D视觉编码器。这个编码器的巧妙之处在于:
- 原生分辨率处理:不需要把图片切成小块再拼接,直接处理原始分辨率
- 图像视频参数共享:把连续的4帧视频打包成一个时空体积,用同一套参数处理。这样图像理解的知识可以无缝迁移到视频理解
Zero-Vision SFT:用纯文本激活视觉能力
更神奇的是"零视觉监督微调"(Zero-Vision SFT)。传统方法需要大量人工标注的"视觉推理链"数据,但K2.5发现:只用纯文本的监督微调数据,就能激活模型的视觉和工具使用能力!
秘诀在于:通过预训练阶段的联合训练,视觉和文本已经建立了强对齐关系,所以文本能力的提升可以自然地泛化到视觉任务。他们把所有图像操作都代理成IPython中的程序化操作,这样就能用丰富的文本数据来训练视觉智能体了。
联合多模态强化学习:视觉提升文本!
最让人意外的发现是:视觉强化学习不仅没有损害文本能力,反而提升了文本性能!
如表2所示,在进行视觉RL之后:
- MMLU-Pro:84.7% → 86.4%(+1.7%)
- GPQA-Diamond:84.3% → 86.4%(+2.1%)
- LongBench v2:56.7% → 58.9%(+2.2%)
分析发现,视觉RL增强了模型在需要结构化信息提取任务上的校准能力(比如计数、OCR),这些能力反过来帮助了文本推理。这种"双向增强"验证了联合训练的优越性。
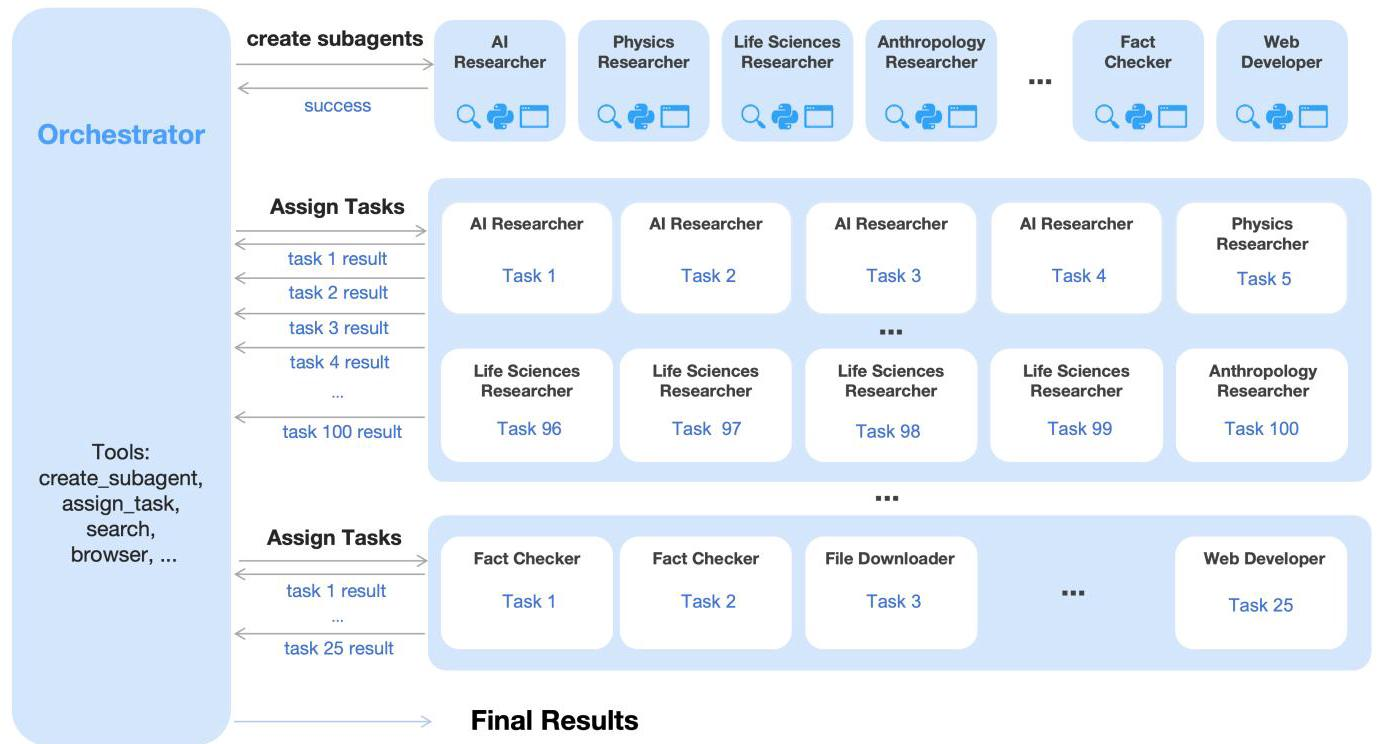
Agent Swarm------智能体蜂群并行框架
第二个核心创新是Agent Swarm框架,解决串行执行的效率瓶颈。
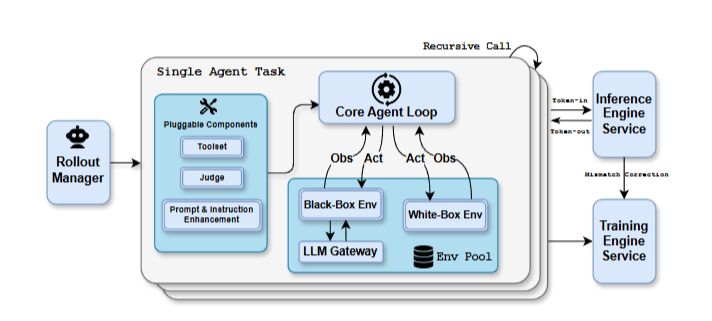
PARL:并行智能体强化学习
核心思想是:训练一个"编排者"(Orchestrator)来动态创建和调度多个"子智能体"(Sub-agents)。关键设计包括:
1. 解耦架构:编排者是可训练的,但子智能体是冻结的(来自之前的检查点)。这样避免了端到端联合优化带来的两个难题:
- 信用分配模糊性(任务成功了,不知道该奖励哪个子智能体)
- 训练不稳定性(多个智能体同时更新容易崩溃)
2. PARL奖励函数:
r PARL ( x , y ) = λ 1 ⋅ r parallel ⏟ 实例化奖励 + λ 2 ⋅ r finish ⏟ 子任务完成率 + r perf ( x , y ) ⏟ 任务级结果 r_{\text{PARL}}(x,y) = \lambda_1 \cdot \underbrace{r_{\text{parallel}}}{\text{实例化奖励}} + \lambda_2 \cdot \underbrace{r{\text{finish}}}{\text{子任务完成率}} + \underbrace{r{\text{perf}}(x,y)}_{\text{任务级结果}} rPARL(x,y)=λ1⋅实例化奖励 rparallel+λ2⋅子任务完成率 rfinish+任务级结果 rperf(x,y)
这个奖励包含三部分:
- r parallel r_{\text{parallel}} rparallel:鼓励创建子智能体,防止退化成单智能体
- r finish r_{\text{finish}} rfinish:奖励成功完成的子任务,防止胡乱创建无意义的智能体
- r perf r_{\text{perf}} rperf:最终任务的性能
训练过程中, λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2会逐渐衰减到0,确保最终目标是优化任务性能。
3. 关键步数(Critical Steps):
在并行环境中,执行时间不是看总步数,而是看"最长的那条路径"。定义为:
CriticalSteps = ∑ t = 1 T ( S main ( t ) + max i S sub , i ( t ) ) \text{CriticalSteps} = \sum_{t=1}^{T}\left(S_{\text{main}}^{(t)} + \max_i S_{\text{sub},i}^{(t)}\right) CriticalSteps=t=1∑T(Smain(t)+imaxSsub,i(t))
这里 S main ( t ) S_{\text{main}}^{(t)} Smain(t)是主智能体在第 t t t阶段的步数, S sub , i ( t ) S_{\text{sub},i}^{(t)} Ssub,i(t)是第 i i i个子智能体的步数。通过约束关键步数而非总步数,框架明确激励有效的并行化。
主动式上下文管理
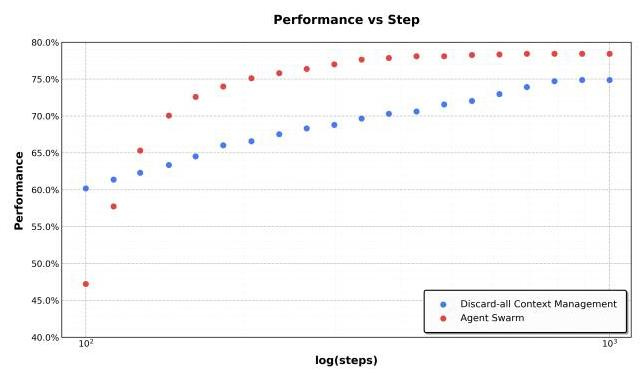
Agent Swarm不仅是性能和速度的提升,更是一种主动式的上下文管理策略。
传统的上下文管理方法(如丢弃工具结果、总结历史)是被动的------等到上下文溢出了才去压缩或删除,往往会丢失结构化信息。
而Agent Swarm通过显式编排实现主动控制:
- 长任务被分解成并行的、语义隔离的子任务
- 每个子智能体维护独立的局部上下文和工作记忆
- 只有任务相关的输出(而非完整交互轨迹)被选择性地返回给编排者
这种设计实现了"上下文分片"而非"上下文截断",在保持模块性、信息局部性和推理完整性的同时,沿着架构维度扩展了有效上下文长度。
Token高效强化学习:Toggle算法
为了在推理时做到既快又好,K2.5提出了Toggle训练启发式方法。核心思路是在训练过程中交替两个阶段:
- Phase 0(预算限制阶段):模型必须在任务相关的token预算内解决问题,培养简洁推理的能力
- Phase 1(标准扩展阶段):模型可以生成到最大token限制,充分利用计算资源
预算是根据正确回答中token长度的某个百分位数估算的:
budget ( x ) = Percentile ( { ∣ y j ∣ ∣ r ( x , y i ) = 1 , i = 1 , ... , K } , ρ ) \text{budget}(x) = \text{Percentile}\left(\{|y_j| \mid r(x,y_i)=1, i=1,\ldots,K\}, \rho\right) budget(x)=Percentile({∣yj∣∣r(x,yi)=1,i=1,...,K},ρ)
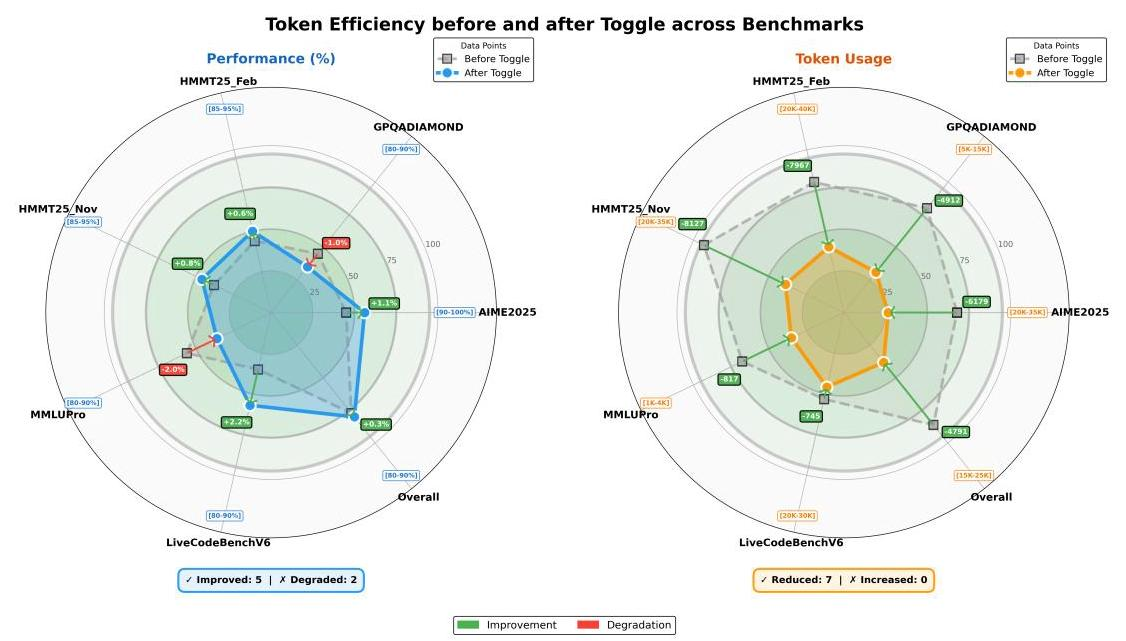
实验显示,Toggle能在几乎不影响性能的情况下,将输出token减少25-30%,并且有很强的领域泛化能力。
实验效果
综合基准测试
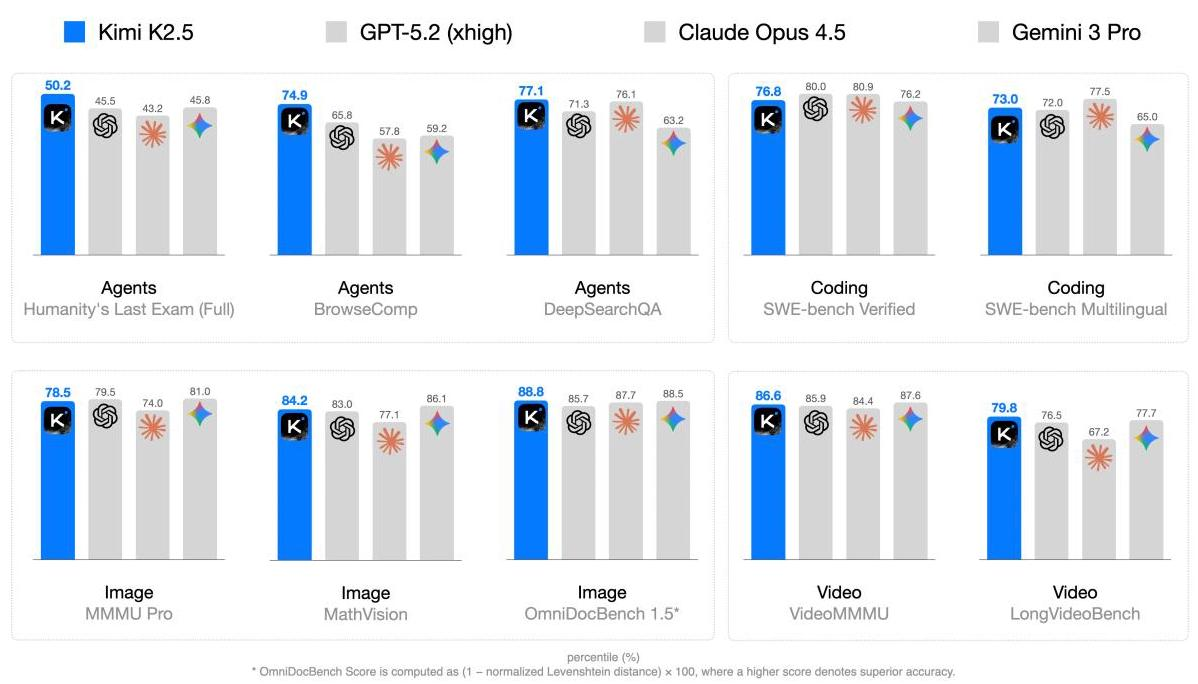
Kimi K2.5在几乎所有测试中都达到了顶尖水平(见表4)。我们挑几个亮点:
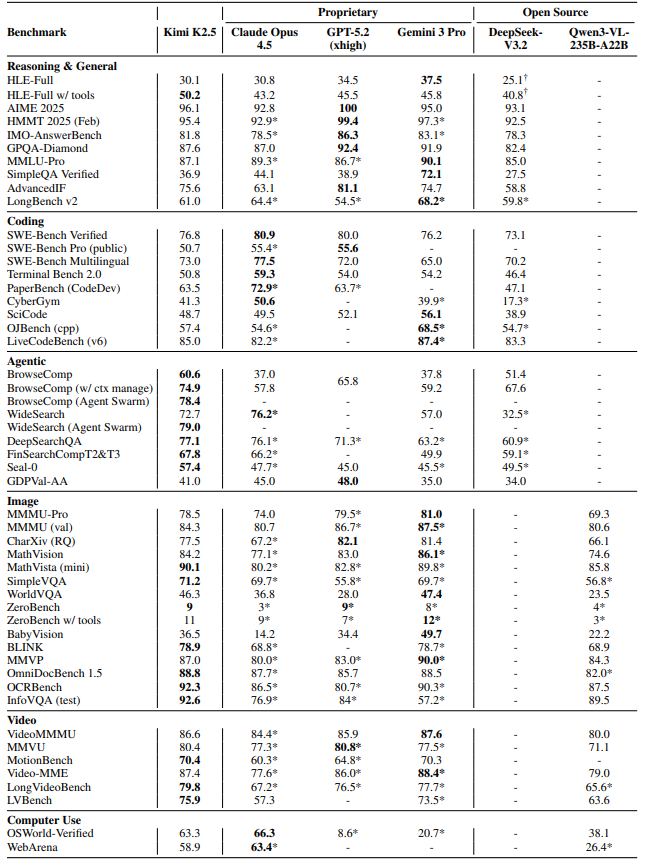
推理和通用能力:
- AIME 2025(数学):96.1%,接近GPT-5.2的满分,超过Claude Opus 4.5(92.8%)
- HMMT 2025:95.4%,展现出超强的数学推理深度
- HLE-Full(带工具):50.2%,显著超过Gemini 3 Pro(45.8%)和GPT-5.2(45.5%)
- GPQA-Diamond(科学推理):87.6%,处于第一梯队
复杂编程和软件工程:
- SWE-Bench Verified:76.8%,在真实软件工程任务上表现出色
- SWE-Bench Multilingual:73.0%,多语言代码能力强劲
- LiveCodeBench v6:85.0%,超过DeepSeek-V3.2(83.3%)和Claude Opus 4.5(82.2%)
智能体能力:这是K2.5最闪耀的地方!
- BrowseComp:60.6%(无上下文管理),74.9%(带上下文管理),78.4%(Agent Swarm)------大幅超过GPT-5.2的65.8%
- WideSearch:72.7%(单智能体),79.0%(Agent Swarm)------比Claude Opus 4.5的76.2%还高
- DeepSearchQA:77.1%,领先所有评估模型
视觉理解:
- MMMU-Pro:78.5%,多学科多模态任务表现优异
- MathVision:84.2%,视觉数学推理能力强
- OCRBench:92.3%,文档理解能力顶尖
- OmniDocBench 1.5:88.8%,达到SOTA水平
视频理解:
- VideoMMMU:86.6%,与顶级模型并驾齐驱
- LongVideoBench:79.8%,长视频理解新纪录
- LVBench:75.9%,全局SOTA
计算机使用:
- OSWorld-Verified:63.3%,大幅超过开源模型(Qwen3-VL 38.1%)和OpenAI的Operator(42.9%)
- WebArena:58.9%,超过Operator(58.1%),接近Claude Opus 4.5(63.4%)
Agent Swarm的惊人加速效果
表6展示了Agent Swarm在智能体任务上的优势:
| 基准 | K2.5 Agent Swarm | Kimi K2.5单智能体 | 提升 |
|---|---|---|---|
| BrowseComp | 78.4% | 60.6% | +17.8% |
| WideSearch | 79.0% | 72.7% | +6.3% |
| In-house Swarm Bench | 58.3% | 41.6% | +16.7% |
更震撼的是执行时间的节省:
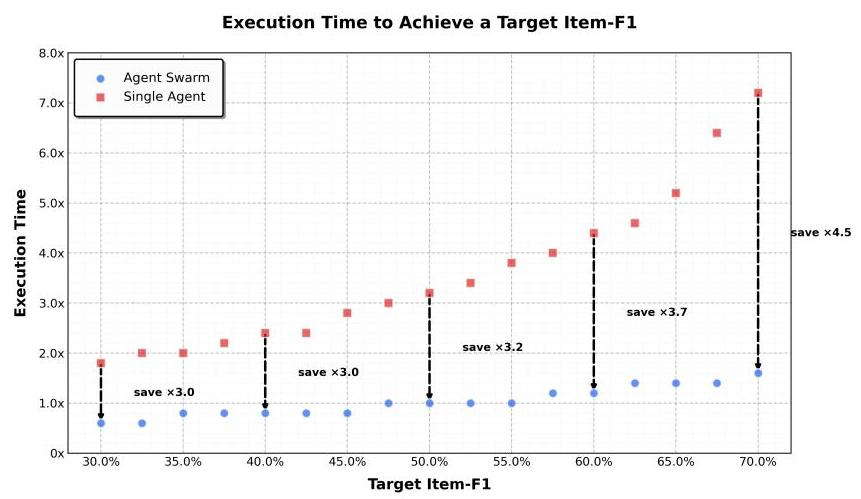
在WideSearch基准上,随着目标Item-F1从30%增加到70%:
- 单智能体的执行时间从基准的1.8倍暴涨到7倍以上
- Agent Swarm始终保持在0.6倍到1.6倍之间
最高实现了4.5倍的加速!这意味着在处理复杂任务时,用户等待时间可以从几分钟缩短到几十秒。
动态子智能体创建:涌现的专业化
Agent Swarm不是预先定义好子智能体的角色,而是让编排者自己学习创建什么样的智能体。图6展示了在测试中动态实例化的各种专业化子智能体:

包括"Award Researcher"(奖项研究员)、"Historical Researcher"(历史研究员)、"Biography Investigator"(传记调查员)等等。这些角色不是人为设计的,而是模型根据任务需求自主创建的------这是真正的"涌现智能"。
Token效率
表5对比了几个推理模型的性能和token消耗:
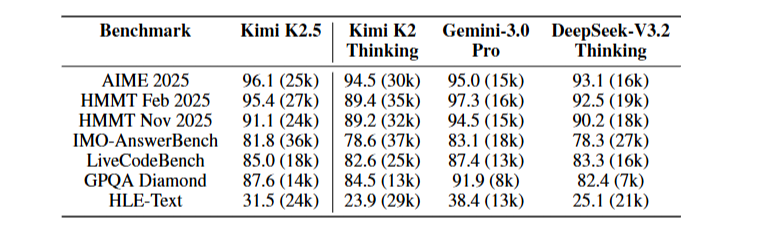
在AIME 2025上,Kimi K2.5用25k tokens达到96.1%的准确率,而Kimi K2 Thinking需要30k tokens才达到94.5%。在保持甚至提升性能的同时,token消耗明显降低。
这对于推理时扩展至关重要------既要能解决难题(需要长推理链),又不能无限制地消耗计算资源。
论文总结
Kimi K2.5的核心让视觉和语言从训练之初就相互促进,并通过多智能体并行执行把AI从"单核串行"升级到"多核并行",从而在保持强大能力的同时实现了4.5倍的速度提升。
这篇论文的意义不仅在于刷新了一堆基准测试的SOTA,更在于展示了一条通往通用智能体系统的可行路径:
- 多模态不是"拼接",而应该是"共生"
- 智能体的未来不是单打独斗,而是协同作战