本笔记基于
extern/unitree_rl_lab源码及docs/training/unitree_rl_lab/官方文档整理,聚焦 G1-29DOF 速度跟踪与动作模仿任务的完整训练链路。
Unitree RL Lab 训练框架深度解析:从 G1-29DOF 速度跟踪到动作模仿
本笔记基于
extern/unitree_rl_lab源码及docs/training/unitree_rl_lab/官方文档整理,聚焦 G1-29DOF 速度跟踪与动作模仿任务的完整训练链路。
📖 目录
- 背景
- [阶段 1:定位与对比](#阶段 1:定位与对比)
- [阶段 2:代码架构与任务注册机制](#阶段 2:代码架构与任务注册机制)
- [阶段 3:Locomotion 速度跟踪深度解析](#阶段 3:Locomotion 速度跟踪深度解析)
- [阶段 4:Mimic 动作模仿任务](#阶段 4:Mimic 动作模仿任务)
- [阶段 5:训练、推理与导出](#阶段 5:训练、推理与导出)
- [阶段 6:Sim2Sim → Sim2Real 部署](#阶段 6:Sim2Sim → Sim2Real 部署)
- 总结
背景:
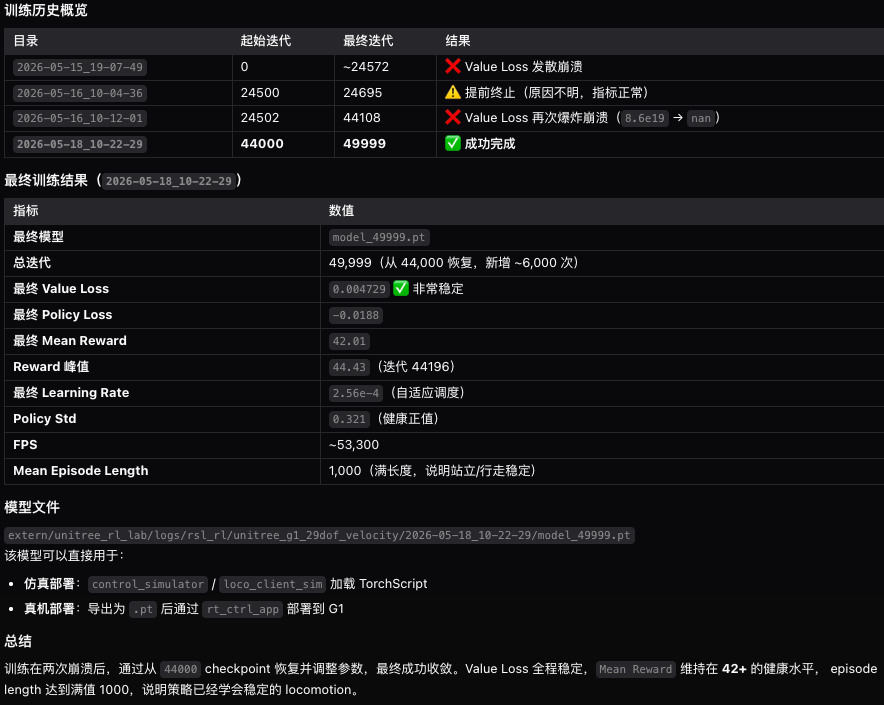
在过程中,发现sim2sim中间有不少USD-URDF等转换和适配,鉴于自己初学,先通识pipeline,所以从unitree官方的在issaclab中的训练过程下手,4090GPU训练30小时左右,目前在issaclab中的效果如下,后续再复用宇树的sim2sim走通流程:
Repo:unitree_rl_lab
阶段 1:定位与对比
一句话定义
unitree_rl_lab 是宇树官方基于 Isaac Lab(Isaac Sim 5.1) 的强化学习训练框架,核心职责是:
在 GPU 加速的并行仿真环境中训练机器人运动策略,输出
.pt/.onnx模型文件,供后续 Sim2Sim(MuJoCo)或 Sim2Real(C++ ONNX Runtime)使用。
与 workspace 中其他框架的关系
unitree_rl_gym |
isaac_lab(子模块) |
unitree_rl_lab |
|
|---|---|---|---|
| 底层仿真 | Isaac Gym(legacy) | Isaac Sim 5.1 + Isaac Lab 2.3 | Isaac Sim 5.1 + Isaac Lab 2.3 |
| 算法库 | 内置 PPO | 支持 RSL-RL / SKRL / RL-Games | RSL-RL |
| 支持机型 | G1-12/Go2/H1 | 通用 | G1-29/Go2/H1/B2 |
| 任务类型 | 速度跟踪 | 通用模板 | 速度跟踪 + 动作模仿(舞蹈) |
| 部署产出 | .pt (LibTorch) |
依赖配置 | .pt + .onnx (ONNX Runtime) |
| Workspace 场景 | configs/g1_12dof.yaml |
可选训练后端 | configs/g1_29dof.yaml |
记忆口诀 :
gym是老框架(Isaac Gym),lab是新框架(Isaac Lab)。
目录全景
unitree_rl_lab/
├── scripts/
│ ├── rsl_rl/train.py # 训练入口
│ ├── rsl_rl/play.py # 推理/回放/导出
│ └── list_envs.py # 列出所有注册任务
├── source/unitree_rl_lab/ # Isaac Lab Extension 核心源码
│ ├── assets/robots/
│ │ ├── unitree.py # 机器人 USD/URDF 配置
│ │ └── unitree_actuators.py # 执行器模型(扭矩-速度曲线 + 摩擦)
│ ├── tasks/
│ │ ├── locomotion/ # 🏃 速度跟踪任务
│ │ │ ├── robots/g1/29dof/velocity_env_cfg.py
│ │ │ ├── mdp/rewards.py
│ │ │ ├── mdp/observations.py
│ │ │ ├── mdp/curriculums.py
│ │ │ └── agents/rsl_rl_ppo_cfg.py
│ │ └── mimic/ # 💃 动作模仿任务(舞蹈/动作跟踪)
│ │ ├── robots/g1_29dof/dance_102/
│ │ ├── robots/g1_29dof/gangnam_style/
│ │ └── mdp/...
│ └── utils/
│ ├── export_deploy_cfg.py # 导出 Sim2Sim 部署配置
│ └── parser_cfg.py # 配置解析
├── deploy/ # 🚀 C++ Sim2Sim / Sim2Real 部署代码
│ ├── robots/g1_29dof/ # G1 控制器源码
│ ├── include/ # 公共头文件
│ └── thirdparty/ # 依赖(ONNX Runtime 等)
└── unitree_rl_lab.sh # 快捷脚本 (-i 安装 / -t 训练 / -p 推理 / -l 列表)阶段 2:代码架构与任务注册机制
Isaac Lab Extension 机制
unitree_rl_lab 是 Isaac Lab 的 Extension(扩展),类似于 VS Code 的插件系统:
- 核心 :
isaaclab提供仿真引擎、资产加载、场景管理 - 扩展 :
unitree_rl_lab在核心之上注册自己的机器人、任务、算法配置
安装时 ./unitree_rl_lab.sh -i 做两件事:
pip install -e source/unitree_rl_lab- 在 conda activate hook 中注入路径
三层注册体系
Layer 1: Extension 注册
source/unitree_rl_lab/unitree_rl_lab/__init__.py (空文件)
→ 包被 import 时即被视为有效扩展
Layer 2: Task Package 自动发现
tasks/__init__.py
→ from isaaclab_tasks.utils import import_packages
→ 自动递归导入所有子模块
Layer 3: Gym Env 注册
locomotion/robots/g1/29dof/__init__.py
→ gym.register(id="Unitree-G1-29dof-Velocity", ...)关键代码:
python
gym.register(
id="Unitree-G1-29dof-Velocity",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
kwargs={
"env_cfg_entry_point": f"{__name__}.velocity_env_cfg:RobotEnvCfg", # 训练配置
"play_env_cfg_entry_point": f"{__name__}.velocity_env_cfg:RobotPlayEnvCfg", # 推理配置
"rsl_rl_cfg_entry_point": f"unitree_rl_lab.tasks.locomotion.agents.rsl_rl_ppo_cfg:BasePPORunnerCfg",
},
)设计亮点:训练配置 (
RobotEnvCfg) 和推理配置 (RobotPlayEnvCfg) 分离。推理时环境数更少(32 vs 4096)。
环境配置的模块化设计(Declarative/ConfigClass)
与 unitree_rl_gym 最大的架构差异:
unitree_rl_gym |
unitree_rl_lab |
|
|---|---|---|
| 风格 | Imperative(命令式) | Declarative(声明式) |
| 代码组织 | legged_robot.py 一个 727 行的类 |
按功能拆分为独立 ConfigClass |
| 新增奖励 | 改 _compute_rewards() |
改 RewardsCfg 里的 RewTerm 条目 |
| 新增观测 | 改 _get_observations() |
改 ObservationsCfg 里的 ObsTerm 条目 |
velocity_env_cfg.py 中环境被拆成 8 个独立配置类:
| 配置类 | 职责 | 对应 unitree_rl_gym |
|---|---|---|
RobotSceneCfg |
场景:地形、机器人、传感器、灯光 | create_sim() + 地形生成 |
EventCfg |
事件:启动时随机化、重置、周期推搡 | reset_idx() + _push_robots() |
CommandsCfg |
命令:速度指令生成与重采样 | commands 配置 |
ActionsCfg |
动作:关节位置控制 | control 配置 |
ObservationsCfg |
观测:Policy + Critic 两组观测 | _get_observations() |
RewardsCfg |
奖励:十几项奖励函数的加权组合 | _compute_rewards() |
TerminationsCfg |
终止:超时、高度过低、姿态翻倒 | check_termination() |
CurriculumCfg |
课程:地形难度、速度指令难度渐进 | terrain.curriculum |
代码量对比
| 模块 | unitree_rl_gym |
unitree_rl_lab |
|---|---|---|
| 环境核心 | legged_robot.py 727 行 |
velocity_env_cfg.py 406 行配置 |
| 奖励函数 | 内嵌在类中 | mdp/rewards.py 225 行(可复用) |
| 观测函数 | 内嵌在类中 | mdp/observations.py 19 行(复用 isaaclab) |
| 课程学习 | 内嵌在 terrain.py | mdp/curriculums.py 61 行 |
机器人配置与执行器模型
source/unitree_rl_lab/assets/robots/unitree.py:
- USD/URDF 路径:指向
extern/unitree_model或extern/unitree_ros - 关节定义:29 个自由度(腿部 12 + 腰部 3 + 手臂 14)
- 非理想执行器 (
unitree_actuators.py):含扭矩-速度饱和曲线、摩擦、延迟
unitree_rl_gym使用理想 PD 控制器,lab的执行器模型对 Sim2Real 更友好。
阶段 3:Locomotion 速度跟踪深度解析
3.1 CommandsCfg:速度指令的「双层边界」设计
python
base_velocity = mdp.UniformLevelVelocityCommandCfg(
resampling_time_range=(10.0, 10.0), # 每 10 秒换一次目标速度
rel_standing_envs=0.02, # 2% 的环境指令强制为 0(学站立)
heading_command=False,
ranges=mdp.UniformLevelVelocityCommandCfg.Ranges(
lin_vel_x=(-0.1, 0.1), # ← 初始采样范围:很小!
lin_vel_y=(-0.1, 0.1),
ang_vel_z=(-0.1, 0.1)
),
limit_ranges=mdp.UniformLevelVelocityCommandCfg.Ranges(
lin_vel_x=(-0.5, 1.0), # ← 上限:最终要达到的速度
lin_vel_y=(-0.3, 0.3),
ang_vel_z=(-0.2, 0.2)
),
)| 字段 | 作用 | 初始值 | 最终值 |
|---|---|---|---|
ranges |
当前实际采样范围 | ±0.1 m/s | 通过课程学习逐步扩大到 limit_ranges |
limit_ranges |
绝对上限,课程学习不会突破 | -0.5~1.0 m/s | 固定不变 |
3.2 ObservationsCfg:Policy vs Critic 分离 + 历史帧
python
class PolicyCfg(ObsGroup):
base_ang_vel = ObsTerm(func=mdp.base_ang_vel, scale=0.2, noise=Unoise(n_min=-0.2, n_max=0.2))
projected_gravity = ObsTerm(func=mdp.projected_gravity, noise=...)
velocity_commands = ObsTerm(func=mdp.generated_commands, params={"command_name": "base_velocity"})
joint_pos_rel = ObsTerm(func=mdp.joint_pos_rel, noise=...)
joint_vel_rel = ObsTerm(func=mdp.joint_vel_rel, scale=0.05, noise=...)
last_action = ObsTerm(func=mdp.last_action)
def __post_init__(self):
self.history_length = 5 # ← 保留最近 5 帧
self.enable_corruption = True # ← Policy 观测加噪声(模拟传感器)
self.concatenate_terms = True
class CriticCfg(ObsGroup):
base_lin_vel = ObsTerm(func=mdp.base_lin_vel) # ← Critic 有 privileged info:线速度
# ... 其他同 Policy,但没有 noise与 unitree_rl_gym 对比:
| 特性 | unitree_rl_gym (G1-12DOF) |
unitree_rl_lab (G1-29DOF) |
|---|---|---|
| 观测维度 | 47 | 更大(29 关节位置 + 29 关节速度 + ...) |
| 历史帧 | ❌ 无 | ✅ history_length=5 |
| 噪声 | 全局 add_noise=True |
✅ 逐项配置 noise= |
| Policy/Critic 分离 | ❌ 同一个 obs | ✅ Critic 有 privileged(线速度) |
| 相位 | ✅ sin/cos(phase) |
❌ 未使用(用 feet_gait 替代) |
3.3 RewardsCfg:29DOF 全身协调的精细化奖励
Task 奖励
| 奖励项 | 权重 | 说明 |
|---|---|---|
track_lin_vel_xy |
+1.0 | 跟踪线速度指令(核心) |
track_ang_vel_z |
+0.5 | 跟踪角速度指令 |
alive |
+0.15 | 存活 |
Base 惩罚
| 惩罚项 | 权重 | 说明 |
|---|---|---|
lin_vel_z |
-2.0 | 上下弹跳 |
ang_vel_xy |
-0.05 | 翻滚/俯仰 |
joint_vel |
-0.001 | 关节速度(节能) |
joint_acc |
-2.5e-7 | 关节加速度(平滑) |
action_rate |
-0.05 | 动作变化率 |
dof_pos_limits |
-5.0 | 关节限位 |
energy |
-2e-5 | 功耗 = Σ|τ·ω|(全新!) |
全身协调(29DOF 特有)
| 部位 | 权重 | 目的 |
|---|---|---|
手臂 (joint_deviation_arms) |
-0.1 | 保持手臂贴近默认姿态 |
腰部 (joint_deviation_waists) |
-1.0 | 腰部稳定 |
腿部 (joint_deviation_legs) |
-1.0 | 惩罚髋关节异常外展/内旋 |
足端行为(lab 特有且精细)
feet_gait:周期步态奖励
python
feet_gait = RewTerm(func=mdp.feet_gait, weight=0.5,
params={"period": 0.8, "offset": [0.0, 0.5], "threshold": 0.55, ...})period=0.8:步态周期 0.8 秒offset=[0.0, 0.5]:左右腿相位差 0.5(半周期,交替迈步)- 计算全局相位,判断每条腿「应该触地」还是「应该摆动」,与传感器实际接触状态对比,匹配则奖励
替代了
unitree_rl_gym的sin/cos(phase)观测。gym 把相位信息喂给网络让它自己学;lab 直接把「步态是否正确」作为奖励信号。
feet_clearance:摆动足离地高度奖励
- 奖励摆动足抬到 10cm 高度
- 只在「摆动相」有效(通过脚的水平速度 tanh 加权)
- 防止拖着脚走路
feet_slide:惩罚触地滑动
- 脚在接触地面时水平速度不为 0 → 惩罚
- 防止「滑冰」步态
undesired_contacts:惩罚意外接触
- 正则表达式
(?!.*ankle.*).*表示除脚踝外的所有部位 - 膝盖触地、躯干触地 → 大惩罚
3.4 EventCfg:三类事件的声明式管理
| 模式 | 触发时机 | 用途 |
|---|---|---|
mode="startup" |
环境初始化时执行一次 | 摩擦随机化、质量随机化 |
mode="reset" |
每回合重置时执行 | 根位置/姿态、关节状态 |
mode="interval" |
按固定间隔执行 | 周期推搡机器人(每 5 秒推一把) |
3.5 CurriculumCfg:双层课程学习
第一层:terrain_levels(地形难度)
- Isaac Lab 内置:表现好 → 自动分配到更难的地形块
第二层:lin_vel_cmd_levels(速度指令难度)------ lab 特有
python
def lin_vel_cmd_levels(env, env_ids, reward_term_name="track_lin_vel_xy"):
reward = torch.mean(env.reward_manager._episode_sums[...]) / env.max_episode_length_s
if reward > reward_term.weight * 0.8: # 如果跟踪奖励 > 0.8(达标)
ranges.lin_vel_x += [-0.1, 0.1] # 扩大指令范围
ranges.lin_vel_y += [-0.1, 0.1]
# 但不超过 limit_ranges机器人先学「走得很慢但稳」,达标后再学「走快一点」,一步步从 ±0.1 m/s 扩展到 ±1.0 m/s。
3.6 sin/cos(phase) vs feet_gait 深度对比
sin/cos(phase)(gym) |
feet_gait(lab) |
|
|---|---|---|
| 方式 | 告诉网络「现在几点了」,让它自己决定抬哪只脚 | 直接检查「脚抬对了吗」,对了就给钱 |
| 哲学 | 隐式学习(Implicit) | 显式塑造(Explicit) |
| 网络输入 | ✅ 观测向量多了 2 维(sin, cos) | ❌ 网络不知道 phase |
| 步态控制 | 网络自己学出来的 | 奖励函数硬约束的 |
sin/cos(phase) 的原理:
phase = (episode_length_buf * dt) % period / period------ 全局相位 0~1sin_phase = sin(2π·phase),cos_phase = cos(2π·phase)------ 转成连续平滑的周期性编码- 网络观测到 phase 后,隐式学会「什么时候该抬脚」
feet_gait 的原理:
- 计算全局相位,判断每条腿「应该支撑」还是「应该摆动」
- 与实际接触传感器对比,匹配则奖励
- 直接把「人走路时两条腿交替迈步」的先验知识写进奖励函数
阶段 4:Mimic 动作模仿任务
4.1 Mimic 与 Locomotion 的根本区别
| Locomotion(速度跟踪) | Mimic(动作模仿) | |
|---|---|---|
| 目标 | 跟踪速度指令(vx, vy, ω) | 跟踪动作捕捉数据(MoCap) |
| 参考信号 | 每 10 秒随机生成的速度指令 | BVH 文件中的关节轨迹 + 身体位姿 |
| 任务本质 | 自主运动控制 | 复刻一段舞蹈/动作 |
| 地形 | 复杂地形(斜坡、楼梯、障碍) | 平底(plane) |
| 全身协调 | 惩罚偏离(消极约束) | 主动跟踪参考姿态(积极驱动) |
4.2 数据来源:BVH → CSV → NPZ
原始动捕数据(BVH 格式)
↓
G1_Take_102.bvh_60hz.csv ← 已重定向到 G1 骨骼的 CSV(60Hz)
↓
python scripts/mimic/csv_to_npz.py ← 预处理脚本
↓
G1_Take_102.bvh_60hz.npz ← 训练时加载的 numpy 压缩文件.npz 文件内容:
joint_pos/joint_vel:参考关节位置/速度body_pos_w/body_quat_w:参考身体部位的世界坐标/姿态body_lin_vel_w/body_ang_vel_w:参考线速度/角速度fps:帧率(60Hz)
4.3 MotionCommand:替代速度指令的参考轨迹播放器
Locomotion 用 UniformLevelVelocityCommandCfg;Mimic 用 MotionCommandCfg。
核心设计:
python
class MotionCommand(CommandTerm):
def __init__(self, cfg, env):
self.motion = MotionLoader(self.cfg.motion_file, ...) # 加载 .npz
self.time_steps = torch.zeros(num_envs) # 每个环境当前播放到第几帧
@property
def command(self) -> torch.Tensor:
return torch.cat([self.joint_pos, self.joint_vel], dim=1)
# ↑ Policy 观测中直接包含「参考关节位置 + 参考关节速度」4.4 自适应采样(Adaptive Sampling)
问题:一段舞蹈有 5000 帧,有的简单(站立),有的难(空翻)。随机重置会浪费时间在简单帧。
解决方案 :_adaptive_sampling
- 把 5000 帧分成 N 个 bin(比如 100 个 bin)
- 统计每个 bin 的失败率(机器人在该 bin 内摔倒的次数)
- 失败率高的 bin,采样概率更高
- 用卷积核平滑概率分布
| 参数 | 作用 |
|---|---|
adaptive_uniform_ratio=0.1 |
保留 10% 均匀随机采样(探索) |
adaptive_lambda=0.8 |
卷积核衰减系数,平滑概率 |
adaptive_alpha=0.001 |
失败计数 EMA 更新率 |
4.5 观测空间
Policy 观测:
| 观测项 | 含义 |
|---|---|
motion_command |
参考关节位置 + 速度(来自 .npz) |
motion_anchor_ori_b |
参考轨迹锚点(torso)的姿态,相对机器人坐标系 |
base_ang_vel |
自身角速度 |
joint_pos_rel / joint_vel_rel |
自身关节位置/速度 |
Mimic 的 Policy 没有
projected_gravity和velocity_commands,因为任务不是跟踪速度。
Critic Privileged 观测:
motion_anchor_pos_b:参考锚点位置body_pos/body_ori:自身各部位位置/姿态base_lin_vel等
4.6 奖励函数:全是跟踪误差
Mimic 几乎没有「惩罚不良行为」的负奖励,全是「跟踪有多准」的正奖励:
python
# 基础惩罚(权重很小)
joint_acc = RewTerm(func=mdp.joint_acc_l2, weight=-2.5e-7)
joint_torque = RewTerm(func=mdp.joint_torques_l2, weight=-1e-5)
action_rate_l2 = RewTerm(func=mdp.action_rate_l2, weight=-1e-1)
joint_limit = RewTerm(func=mdp.joint_pos_limits, weight=-10.0)
# 跟踪奖励(核心!全是 exp(-error²/std²))
motion_global_anchor_pos = RewTerm(func=mdp.motion_global_anchor_position_error_exp, weight=0.5, ...)
motion_global_anchor_ori = RewTerm(func=mdp.motion_global_anchor_orientation_error_exp, ...)
motion_relative_body_pos = RewTerm(func=mdp.motion_relative_body_position_error_exp, ...)
motion_relative_body_ori = RewTerm(func=mdp.motion_relative_body_orientation_error_exp, ...)
motion_body_lin_vel = RewTerm(func=mdp.motion_global_body_linear_velocity_error_exp, ...)
motion_body_ang_vel = RewTerm(func=mdp.motion_global_body_angular_velocity_error_exp, ...)跟踪项解析:
| 跟踪项 | 跟踪对象 |
|---|---|
motion_global_anchor_pos |
躯干(torso)的世界坐标位置 |
motion_global_anchor_ori |
躯干的姿态 |
motion_relative_body_pos |
各身体部位相对躯干的位置 |
motion_relative_body_ori |
各身体部位相对躯干的姿态 |
motion_body_lin_vel |
各部位线速度 |
motion_body_ang_vel |
各部位角速度 |
为什么跟踪「相对位置」? 如果只跟踪绝对世界坐标,机器人会学会「站在原地做动作」;跟踪相对位置可以让机器人边走边跳。
4.7 地形与事件
python
# 地形:纯平底
terrain = TerrainImporterCfg(terrain_type="plane", ...)
# 推搡:每 1~3 秒推一把(比 locomotion 更频繁)
push_robot = EventTerm(func=mdp.push_by_setting_velocity, mode="interval",
interval_range_s=(1.0, 3.0), ...)Mimic 的域随机化更激进:
- 摩擦范围
(0.3, 1.6) - 额外随机化 关节默认位置
- 额外随机化 质心位置
阶段 5:训练、推理与导出
5.1 train.py 工作流程
1. AppLauncher 启动 Isaac Sim(必须先启动 Omniverse)
2. Hydra 加载配置(@hydra_task_config 装饰器)
3. gym.make 创建环境
4. RslRlVecEnvWrapper 包装环境(统一接口 + action clip)
5. OnPolicyRunner 创建并开始训练
→ runner.learn(num_learning_iterations=..., init_at_random_ep_len=True)init_at_random_ep_len=True:训练开始时每个环境的 Episode 长度随机初始化,避免 4096 个环境同时重置导致数据相关性过高。
5.2 PPO 配置解析与网络设计
网络结构
python
class BasePPORunnerCfg(RslRlOnPolicyRunnerCfg):
num_steps_per_env = 24 # 每轮每个环境走 24 步
max_iterations = 50000 # 总共 50000 轮
save_interval = 100 # 每 100 轮保存一次
policy = RslRlPpoActorCriticCfg(
init_noise_std=1.0,
actor_hidden_dims=[512, 256, 128], # Actor: 3 层 MLP
critic_hidden_dims=[512, 256, 128], # Critic: 3 层 MLP
activation="elu",
)| 参数 | 值 | 意义 |
|---|---|---|
num_steps_per_env |
24 | 每轮收集 24 × 4096 = 98,304 样本 |
num_learning_epochs |
5 | 每轮数据复用 5 个 epoch |
num_mini_batches |
4 | 分成 4 个 minibatch,每个约 24,576 样本 |
clip_param |
0.2 | PPO 策略更新裁剪范围 |
entropy_coef |
0.01 | 熵正则,鼓励探索 |
learning_rate |
1e-3 | 初始学习率 |
schedule |
adaptive |
根据 KL 散度自适应调整 LR |
自适应学习率调度:
python
if KL > 1.5 * desired_kl: lr *= 0.5 # 策略变化太激进 → 降 LR
elif KL < 0.5 * desired_kl: lr *= 1.5 # 策略变化太慢 → 升 LRActor 输入 480 维的构成
单帧 6 个观测项:
| 观测项 | 维度 |
|---|---|
base_ang_vel |
3 |
projected_gravity |
3 |
velocity_commands |
3 |
joint_pos_rel |
29 |
joint_vel_rel |
29 |
last_action |
29 |
| 单帧总计 | 96 |
history_length = 5 时,Isaac Lab 的 ObservationManager 把最近 5 帧观测拼成一个大向量:
总输入维度 = 96 × 5 = 480排列顺序:[frame_t-4] + [frame_t-3] + [frame_t-2] + [frame_t-1] + [frame_t]
为什么是 [512, 256, 128]?
第一层 512 > 输入 480(冗余设计):
- 如果第一层 ≤ 输入,网络一上来就被迫压缩信息,可能丢失关键特征
- 512 只比 480 大 6.7%,给了冗余空间学习非线性组合,又不会过度参数化
逐层减半(金字塔结构):
| 层级 | 维度 | 作用 |
|---|---|---|
| Layer 1 | 512 | 特征提取与分离 |
| Layer 2 | 256 | 抽象与压缩 |
| Layer 3 | 128 | 高层语义 |
| Output | 29 | 动作输出 |
3 层是足式机器人的「甜蜜点」:
| 层数 | 表达能力 | 训练速度 | 泛化能力 | 结论 |
|---|---|---|---|---|
| 1 层 | 只能学线性 | 极快 | 很好 | 太简单 |
| 2 层 | 简单非线性 | 快 | 好 | 姿态僵硬 |
| 3 层 | 复杂非线性 | 适中 | 好 | 最佳平衡 |
| 4 层+ | 更复杂 | 较慢 | 易过拟合 | 收益递减 |
- 1 层提取原始特征 → 2 层组合中级特征(如"正在迈左腿")→ 3 层形成高层决策
- 4 层+ 容易记住训练地形的细节,换个地形就摔倒(过拟合)
Critic 输入 483 维 = 480 + 3(privileged info)
Asymmetric Actor-Critic(非对称设计):
| Actor | Critic | |
|---|---|---|
| 输入 | 480(Policy 观测) | 483(+ base_lin_vel 线速度 3 维) |
| 用途 | 做决策 | 评判决策好坏 |
| 推理时 | ✅ 使用 | ❌ 不需要 |
为什么 Critic 需要多 3 维?
Critic 只在训练时使用,仿真中 base_lin_vel 是物理引擎给出的精确值。Critic 知道线速度后,价值估计更准确,从而给 Actor 更好的 Advantage 信号。
例:机器人正在下坡,感官上直立(Actor 觉得稳),但 Critic 看到
base_lin_vel = (0.3, 0, 0)知道其实在往前滑 → 给出负 Advantage → Actor 学会微调动作防止下滑。
PPO 更新核心:ratio 与 clip
python
ratio = torch.exp(log_prob_new - torch.squeeze(batch.old_actions_log_prob))
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_param, 1 + clip_param) * advantages
actor_loss = -torch.min(surr1, surr2).mean()torch.squeeze(batch.old_actions_log_prob):[N, 1]→[N],与log_prob_new对齐维度ratio = π_new(a|s) / π_old(a|s):新旧策略对同一动作的偏好比clip_param = 0.2:ratio 限制在 0.8, 1.2,防止策略更新过猛torch.min(surr1, surr2):取悲观估计。ratio 偏离 1 太远时 clip 兜底,ratio 在安全范围内则正常用
Actor 输入 480 维的显式拆解
单帧 6 项 × history_length=5:
| 观测项 | 维度 | 含义 |
|---|---|---|
base_ang_vel |
3 | 躯干角速度 |
projected_gravity |
3 | 重力方向投影 |
velocity_commands |
3 | 目标速度指令 |
joint_pos_rel |
29 | 关节位置(相对默认值) |
joint_vel_rel |
29 | 关节速度 |
last_action |
29 | 上一帧动作 |
| 单帧 | 96 | |
| 5 帧拼接 | 480 | 96 × 5 |
Critic 多 3 维 base_lin_vel → 483 维。
5.3 play.py 工作流程
1. 解析配置(加载 play_env_cfg_entry_point = RobotPlayEnvCfg)
2. 定位 checkpoint(默认最新 run 的最新 checkpoint)
3. 创建环境并加载模型
4. 获取推理策略:policy = runner.get_inference_policy()
5. 自动导出模型:
- exported/policy.pt (TorchScript)
- exported/policy.onnx (ONNX)
6. 进入实时推理循环推理循环:
python
while simulation_app.is_running():
with torch.inference_mode():
actions = policy(obs)
obs, _, _, _ = env.step(actions)Play 环境 vs 训练环境:
| 参数 | 训练 | 推理 |
|---|---|---|
num_envs |
4096 | 32 |
terrain.num_rows |
9 | 2 |
terrain.num_cols |
21 | 10 |
commands.ranges |
(-0.1, 0.1) | limit_ranges 全开 |
5.4 模型导出机制
推理时自动导出三种产物:
| 文件 | 格式 | 用途 |
|---|---|---|
exported/policy.pt |
TorchScript | Sim2Sim(MuJoCo Python 部署) |
exported/policy.onnx |
ONNX | Sim2Real(C++ ONNX Runtime 部署) |
params/deploy.yaml |
YAML | C++ 端重建观测/动作逻辑的「契约文件」 |
导出原理对比:
TorchScript (.pt) |
ONNX (.onnx) |
|
|---|---|---|
| 导出函数 | torch.jit.script() |
torch.onnx.export() |
| 本质 | PyTorch 专用静态图 | 通用跨框架计算图 |
| 部署方式 | LibTorch C++ API | ONNX Runtime / TensorRT |
| 依赖体积 | LibTorch(~100MB+) | ONNX Runtime(~10MB) |
| 性能 | 好 | 更好(图优化、算子融合) |
| 硬件加速 | CUDA / CPU | CUDA / CPU / TensorRT |
| 跨平台 | PyTorch 支持的平台 | 几乎所有平台(ARM、x86、边缘设备) |
| 本项目用途 | Sim2Sim(MuJoCo Python) | Sim2Real(C++ 真机部署) |
deploy.yaml 包含:
joint_ids_map:关节名称 → ID 映射step_dt:控制周期(0.02s = 0.005 × 4)stiffness/damping:各关节 PD 参数default_joint_pos:默认关节位置commands:速度指令范围actions:动作 scale、offset、clipobservations:各观测项的 scale、history_length
5.5 日志目录结构
logs/rsl_rl/Unitree-G1-29dof-Velocity/
└── 2025-05-15_10-30-00/
├── params/
│ ├── env.yaml
│ ├── agent.yaml
│ ├── deploy.yaml
│ └── velocity_env_cfg.py
├── exported/
│ ├── policy.pt
│ └── policy.onnx
├── videos/
├── model_100.pt
├── model_200.pt
├── ...
├── model_50000.pt
└── events.out.tfevents.*5.6 与 unitree_rl_gym 的导出对比
unitree_rl_gym |
unitree_rl_lab |
|
|---|---|---|
| 导出脚本 | train/export_b2_policy.py / export_mujoco_policy.py |
集成在 play.py 中 |
| 产出格式 | .pt(LibTorch) |
.pt + .onnx |
| 部署配置 | 无统一格式 | deploy.yaml 标准化导出 |
| Sim2Real | LibTorch C++ API | ONNX Runtime(更轻量、跨平台) |
阶段 6:Sim2Sim → Sim2Real 部署
对应源码:
deploy/目录(C++ Sim2Sim / Sim2Real 部署代码)
6.1 C++ 部署代码架构
deploy/
├── include/
│ ├── isaaclab/ # C++ 版 Isaac Lab 环境逻辑
│ │ ├── envs/manager_based_rl_env.h
│ │ ├── envs/mdp/observations/observations.h
│ │ ├── envs/mdp/actions/joint_actions.h
│ │ ├── algorithms/algorithms.h # OrtRunner (ONNX Runtime)
│ │ └── assets/articulation/articulation.h
│ ├── FSM/ # 有限状态机
│ │ ├── CtrlFSM.h
│ │ ├── State_Passive.h
│ │ ├── State_FixStand.h
│ │ └── State_RLBase.h
│ └── param.h
└── robots/g1_29dof/
├── main.cpp
├── src/State_RLBase.cpp
├── src/State_Mimic.cpp
└── config/6.2 C++ 端如何复现 Python 环境?
核心设计:C++ 端重新实现了 ManagerBasedRLEnv 的观测和动作逻辑。
cpp
State_RLBase::State_RLBase(...) {
// 1. 加载 deploy.yaml(训练时导出的部署配置)
env = std::make_unique<isaaclab::ManagerBasedRLEnv>(
YAML::LoadFile(policy_dir / "params" / "deploy.yaml"),
std::make_shared<unitree::BaseArticulation<LowState_t::SharedPtr>>(FSMState::lowstate)
);
// 2. 加载 ONNX 策略模型
env->alg = std::make_unique<isaaclab::OrtRunner>(
policy_dir / "exported" / "policy.onnx"
);
}
void State_RLBase::run() {
auto action = env->action_manager->processed_actions();
for(int i = 0; i < env->robot->data.joint_ids_map.size(); i++) {
lowcmd->msg_.motor_cmd()[env->robot->data.joint_ids_map[i]].q() = action[i];
}
}关键点:
- C++ 端没有 Isaac Sim,但有真实机器人 (通过
unitree_sdk2读取LowState) deploy.yaml定义了「如何从LowState计算观测」和「如何将动作映射到LowCmd」observations.h实现了与 Python 端完全一致的观测函数
6.3 ONNX Runtime 推理
cpp
class OrtRunner : public Algorithms {
OrtRunner(std::string model_path) {
env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "onnx_model");
session = Ort::Session(env, model_path.c_str(), session_options);
}
// 输入:观测向量(与 Python Actor 输入同维度)
// 输出:动作向量(29 维)
};为什么用 ONNX Runtime 而不是 LibTorch?
- 更轻量:体积比 LibTorch 小很多
- 跨平台:标准格式,可在 ARM(Orin)、x86 上运行
- 推理更快:有图优化和算子融合
6.4 Sim2Sim 验证流程
bash
# 1. 编译 C++ Controller
cd extern/unitree_rl_lab/deploy/robots/g1_29dof
mkdir build && cd build && cmake .. && make
# 2. 启动 MuJoCo 仿真
cd extern/unitree_mujoco/simulate/build
./unitree_mujoco -r g1 -s scene_29dof.xml
# 3. 运行 Controller(连接 MuJoCo 的 DDS)
cd extern/unitree_rl_lab/deploy/robots/g1_29dof/build
./g1_ctrlSim2Sim 操作步骤:
[L2 + Up]→ 站立- MuJoCo 窗口按
8→ 脚触地 [R1 + X]→ 启动策略- MuJoCo 窗口按
9→ 关闭弹性带
6.5 Sim2Real 真机部署
bash
# 直接上真机(需先关闭机器人 onboard 控制程序)
./g1_ctrl --network eth0真机与 Sim2Sim 的区别:
- Sim2Sim:
lowstate来自 MuJoCo 仿真(DDS 话题) - Sim2Real:
lowstate来自真实机器人的关节编码器 + IMU - 代码完全一致,只需切换网络接口
总结
| 阶段 | 主题 | 关键收获 |
|---|---|---|
| 1 | 定位与对比 | lab 基于 Isaac Lab,gym 基于 Isaac Gym;G1-29DOF 走 lab |
| 2 | 代码架构 | 声明式 ConfigClass 组装,8 大模块解耦 |
| 3 | Locomotion | 双层边界指令、feet_gait 替代 phase、双层课程、全身协调奖励 |
| 4 | Mimic | MotionCommand 播放参考轨迹、自适应采样、全是跟踪奖励 |
| 5 | 训练推理 | train→play→导出 .pt+.onnx+deploy.yaml |
| 6 | 部署 | C++ 复现观测逻辑 + ONNX Runtime + FSM 状态机 |
完整链路 :Isaac Lab 训练 → play.py 导出 ONNX → C++ OrtRunner 加载 → Sim2Sim 验证 → Sim2Real 部署