数据结构------Map和Set
- 一、搜索树
- 二、搜索
- 三、Map的使用
- 四、Set的说明
- 五、哈希表
-
- 5.1概念
- 5.2冲突-避免
-
- 一、哈希冲突的必然性
- [二、5.4 冲突-避免-哈希函数设计](#二、5.4 冲突-避免-哈希函数设计)
- 哈希函数设计方法及关键信息
- 5.5冲突---避免------负载因子调节
一、搜索树
1.1概念
二叉搜索树又称为二叉排序树,它或者是一棵空树,或者
- 左子树不为空则左子树所有节点的值小于根节点
- 右子树不为空则右子树所有节点的值小于根节点
- 左右子树也分别为二叉搜索树
1.2操作-查找
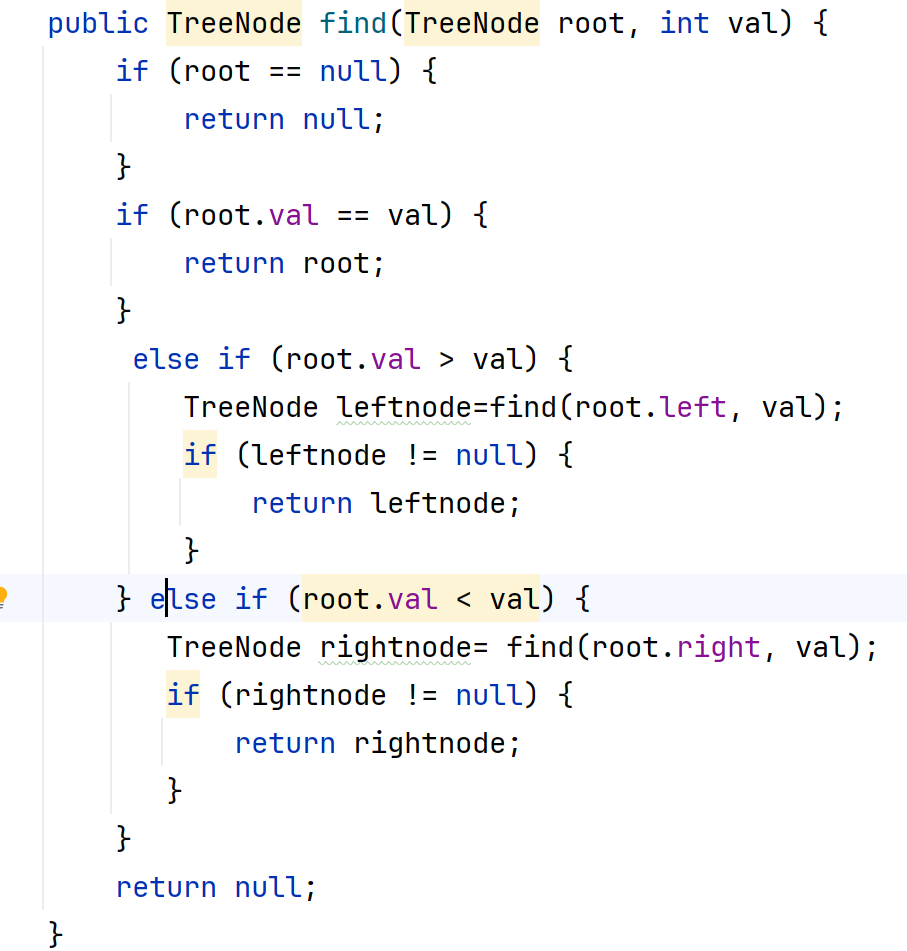
1.3操作-插入
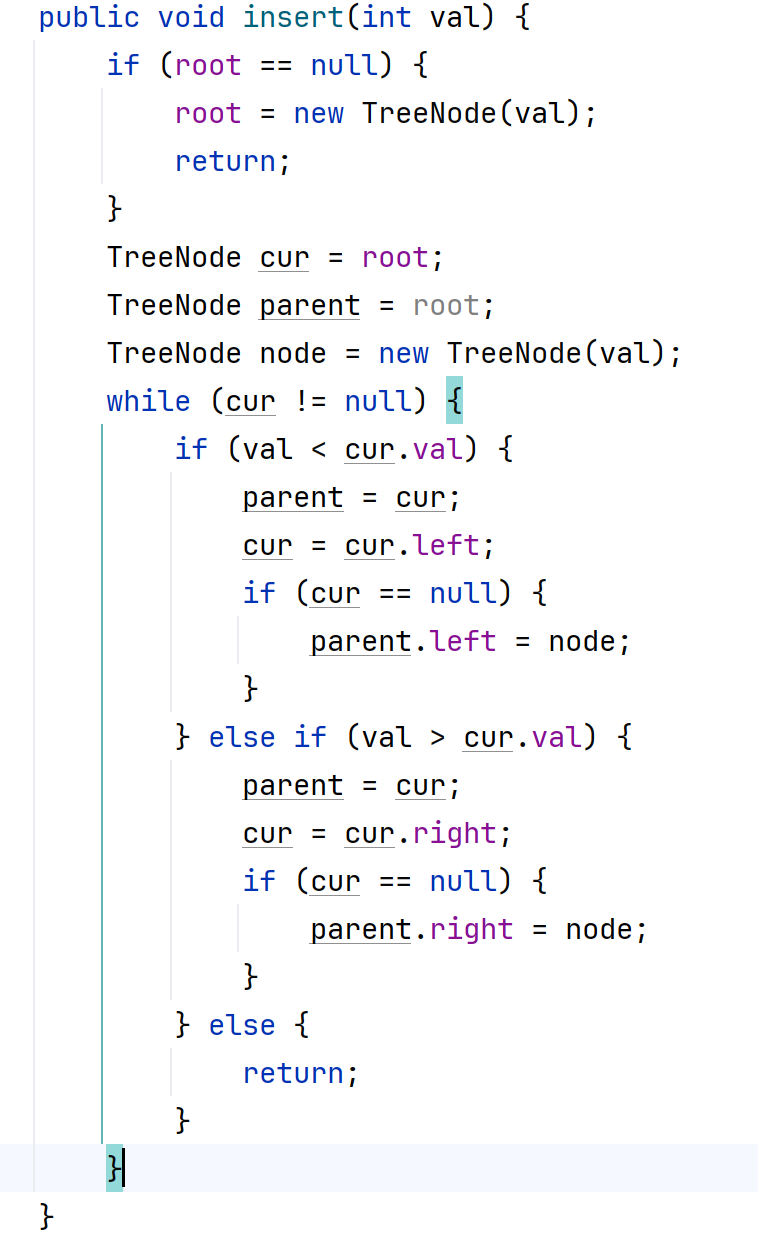
1.4操作-删除
java
public void remove( int val) {
if (root == null) {
return;
}
TreeNode cur = root;
TreeNode parent = root;
while (cur != null) {
if (val < cur.val) {
parent = cur;
cur = cur.left;
} else if (val > cur.val) {
parent = cur;
cur = cur.right;
} else {
delete(cur, parent);
return;
}
}
}
private void delete(TreeNode cur, TreeNode parent) {
//cur的左子树为空
if (cur.left == null) {
if (cur == root) {
root = null;
} else if (cur == parent.left) {
parent.left = cur.right;
} else {
parent.right = cur.right;
}
}
//cur的右子树为空
if (cur.right == null) {
if (cur == root) {
root = null;
} else if (cur == parent.right) {
parent.right = cur.left;
} else {
parent.left = cur.left;
}
}
//cur的左右子树都不为空
if (cur.left != null && cur.right != null) {
TreeNode tp = cur.right;
TreeNode t = tp;
while (t.left != null) {
tp = t;
t = t.left;
}
cur.val = t.val;
if (t.right == null) {
tp.left = null;
} else {
if (tp.left == t) {
tp.left = t.right;
} else {
tp.right = t.right;
}
}
}
}1.6性能分析
最优情况下,二叉树为完全二叉树,其平均比较次数为log2N
最差情况下,为单支树,其平均比较次数为N/2
1.7与java类集的关系
TreemMap和TreeSet即java中利用搜索树实现的Map和Set,实际上用的是红黑树,而红黑树是一棵近似平衡的二叉搜索树,即在二叉搜索树的基础上+颜色以及红黑树 性质验证,关于红黑树内容后续进行详解。
二、搜索
2.1概念
Map和Set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其实例化的子类有关,以前常见的搜索方式有:
1.直接遍历,O(N),元素多则效率慢
2.二分查找,O(log2N),但搜索前必须有序
上面的查找适合静态查找,不会对区间进行插入和删除了,但现实中例如根据姓名查询成绩,可能查找时要进行插入和删除操作,即动态查找,那么Map和Set是一种适合动态查找的集合容器。
2.2模型
Map:Key-Value模型
Set:纯Key模型
三、Map的使用
3.1概念
Map是一个接口类,该类没有继承Collection,该类中存储的是<K,V>结构的键值对,K是唯一不能重复
3.2Map.Entry<K,V>
Map.Entry<K,V>是Map内部实现的用来存放<key,value>键值对映射关系的内部类
| 方法 | 解释 |
|---|---|
| K getKey() | 返回entry中的key |
| V getValue() | 返回entry中的value |
| V setValue(V value | 将键值对中的value替换为指定value |
- Map.Entry<K,V>没有提供设置Key的方法
3.3Map常用方法的使用
| 方法 | 解释 |
|---|---|
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value |
| V remove(Object key) | 删除 key 对应的映射关系 |
| Set keySet() | 返回所有 key 的不重复集合 |
| Collection values() | 返回所有 value 的可重复集合 |
| Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
注意:
- Map是一个接口,不能直接实例化对象,如果要实例化对象,只能实例化其实现类TreeMap或者HashMap
- Key是唯一的,value是可以重复的
- TreeMap中插入键值对是,Key不能为空Value可以
- Map中的Key值可以全部分离出来,存储在Set中进行访问(因为Key不能重复)
- Map中的Value值可以全部分离出来,c存储在Collection的任何一个子集中(Value可能重复)
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,必须删除原有key
- TreeMap与HashMap的区别
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | (O(log2N)) | (O(1)) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
3.4TreeMap的使用案例
java
public static void TestMap(){
Map<Integer,String> map= new TreeMap<>();
map.put(1,"a");
map.put(2,"b");
map.put(3,"c");
map.put(4,"d");
map.put(5,"e");
System.out.println(map);
//value可为空
map.put(6,null);
System.out.println(map.get(5));
System.out.println(map.get(6));
//key存在返回对应的value不存在返回defaultValue
System.out.println(map.getOrDefault(5,null));
System.out.println(map.getOrDefault(7,"h"));
//检测key是否存在
System.out.println(map.containsKey(7));
System.out.println(map.containsKey(4));
// 检测key是否存在
System.out.println(map.containsValue("a"));
System.out.println(map.containsValue("A"));
//打印所有的key,KeySet()返回所有key的不重复集合
for(int k:map.keySet()){
System.out.println(k);
}
System.out.println();
//打印所有value,values()返回所有value的可重复集合
for(String s:map.values()){
System.out.println(s);
}
System.out.println();
//打印所有键值对
for(Map.Entry<Integer,String> entry:map.entrySet()){
System.out.println(entry.getKey()+"->"+entry.getValue());
}
System.out.println();
}运行结果:


四、Set的说明
4.1常见方法
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断 o 是否在集合中 |
| Iterator iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object\[\] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回false |
| boolean addAll(Collection<? extends E> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
注意:
- Set是继承自Collection的一个接口类
- 只存储key,并且要求唯一
- TreeSet底层用Map来实现,其使用key与Object的一个默认对象作为键值对插入到Map中的
- set最大功能就是对集合中元素去重
- 实现Set的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet基础上维护了一个双链表来纪录元素的插入顺序。
- Set中的Key不能修改,要修改先将原来的删除
- TreeSet中不能插入null的key,HashSet可以
- TreeSet与HashSet区别:
| Set底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | (O(log2N)) | (O(1)) |
| 是否有序 | 关于Key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1.先计算key的哈希地址2.然后进行插入和删除 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
java
public static void TestSet(){
Set<String> set = new TreeSet<>();
set.add("1");
set.add("2");
set.add("3");
set.add("4");
set.add("5");
//已存在返回false
set.add("1");
System.out.println(set.size());
System.out.println(set);
//key为null空指针异常
//set.add(null);
set.remove("1");
System.out.println(set);
//通过迭代器逐个获取集合中的元素,并输出
Iterator<String> it= set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
System.out.println();
}输出结果:

五、哈希表
5.1概念
顺序结构以及平衡树中,关键码以及其存储位置之间没有对于=应关系,因此在查找一个元素时必须结果关键码多次比较。
理想搜索方法:不经过任何比较,一次直接从表中达得到要搜索元素,通过某种函数使得以元素的存储位置与它关键码之间能建立--一一映射关系,那么将很快找到这个元素
当向该结构中
插入元素 :根据关键码的哈希函数计算存储位置并存放。
搜索元素 :对关键码计算哈希值,按该位置取元素比较,关键码相等则搜索成功。
该方法即哈希(散列)方法,哈希方法中使用转换函数称为哈希(散列)函数,构造出的结构称为哈希表(HashTable)(散列表)
- 示例:数据集合 {1, 7, 6, 4, 5, 9} ,哈希函数 hash(key) = key % capacity ( capacity = 10 ),各元素哈希地址计算为: hash(1)=1 、 hash(7)=7 、 hash(6)=6 、 hash(4)=4 、 hash(5)=5 、 hash(9)=9 ,对应哈希表存储位置如表格所示。
| 哈希地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 存储元素 | 1 | 4 | 5 | 6 | 7 | 9 |
5.2冲突-避免
一、哈希冲突的必然性
由于哈希表底层数组容量往往小于实际要存储的关键字数量,冲突的发生是必然的,我们应尽量降低冲突率。
二、5.4 冲突-避免-哈希函数设计
(1)哈希冲突的原因
哈希函数设计不够合理可能引发哈希冲突。
(2)哈希函数设计原则
- 定义域必须包含需要存储的全部关键码,若散列表允许有( m )个地址,其值域必须在( 0 )到( m-1 )之间。
- 计算出的地址能均匀分布在整个空间中。
- 函数本身应该比较简单。
常见哈希函数:
哈希函数设计方法及关键信息
| 方法 | 定义/公式 | 优点/特点 | 适用场景 |
|---|---|---|---|
| 直接定制法 | Hash(Key) = A*Key + B (线性函数) | 简单、均匀 | 查找范围小且连续 |
| 除留余数法 | Hash(key)=key%p(p 是不大于散列表地址数( m )的质数) | 常用、高效 | 多数哈希表场景 |
| 平方取中法 | 对关键字平方后抽取中间几位作为哈希地址 | 无需知道关键字分布 | 关键字位数不大且分布未知 |
| 折叠法 | 将关键字分割成等长部分(最后部分可短),叠加后取后几位作为地址 | 无需知道关键字分布 | 关键字位数较多 |
| 随机数法 | H(key)=random(key)(随机函数) | 灵活性高 | 关键字长度不等 |
| 数学分析法 | 选择关键字中分布均匀的位作为散列地址 | 基于符号分布均匀性设计 | 关键字各位符号分布有规律(如手机号等) |
注意:设计越精妙,产生哈希冲突可能性越小,但不能避免
常见哈希冲突处理:闭散列(线性探测、二次探测)、开散列(链地址法)、多次散列
5.5冲突---避免------负载因子调节
一、散列表载荷因子(负载因子)
定义:
α=填入表中的元素个数/散列表的长度
意义:是散列表装满程度的标志因子。
α 越大,填入元素越多,冲突可能性越大;
α 越小,冲突可能性越小。散列表平均查找长度是
α 的函数,不同冲突处理方法对应不同函数。
二、负载因子的工程限制
对于开放定址法,负载因子需严格限制在 0.7−0.8 以下。若超过 0.8,查表时 CPU 缓存不命中(cache missing)会按指数曲线上升。例如 Java 系统库中采用开放定址法的 hash 库,限制负载因子为 0.75,超过则会 resize 散列表。
三、负载因子与冲突率的关系
从 "负载因子和冲突率的关系粗略演示" 图可见,冲突率随负载因子增大而上升,且在负载因子达到一定值后,冲突率呈快速上升趋势。当冲突率过高时,可通过降低负载因子(调整哈希表数组大小)来变相降低冲突率。