1.central cache架构设计
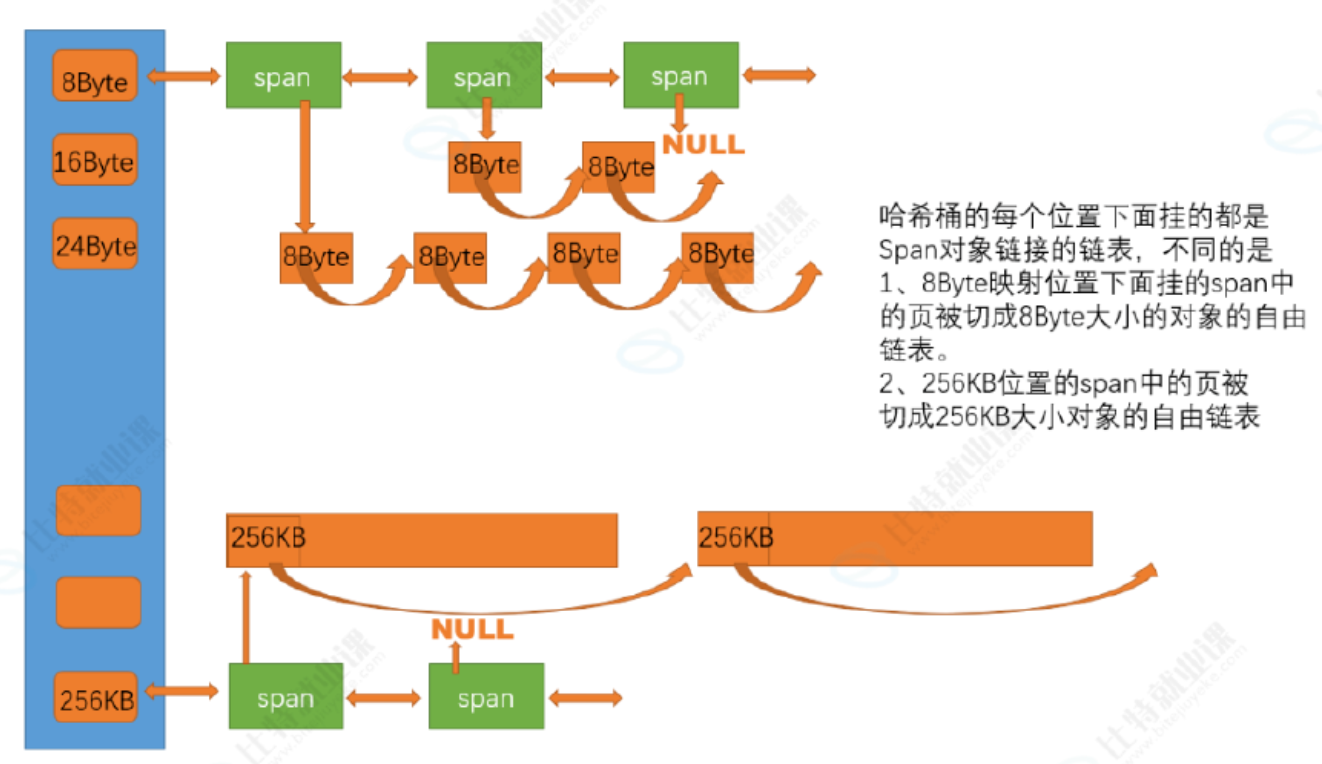
central cache也是一个哈希桶结构,他的哈希桶的映射关系跟thread cache是一样的。不同的是他的每个哈希桶位置挂是SpanList链表结构,不过每个映射桶下面的span中的大内存块被按映射关系切成了一个个小内存块对象挂在span的自由链表中。
span是什么呢?
Span ,英文释义为 跨度 ,是 tcmalloc 中管理连续物理内存页(page)的基本单元,它是连接"页级内存"和"对象级内存"的桥梁。
其是一个抽象的概念,包含一下内容:
struct Span {
// 物理位置信息
PageID startPage; // 起始页号
Length numPages; // 包含的页数(通常是 1~128 页)
// 状态信息
size_t sizeClass; // 该 span 被切分成的对象大小(0 表示未切分的大对象)
uint32_t useCount; // 已分配出去的对象计数
// 链表关系
Span* next; // SpanList 链表指针
Span* prev;
// 自由链表(当作为小对象分配时)
void* freeList; // 指向第一个空闲小对象的指针
};
申请内存:
当某个线程要申请特定的内存时,如果freelist里面有内存,就直接从freelist里面头删一块内存,给线程,完成开辟,但是要是freelist里面没有,就要像central cache进行申请,central cache也有一个哈希映射的spanlist,spanlist中挂着span,从span中取出对象给thread cache,但是当central cache映射的spanlist中所有span的都没有内存以后,则需要向page cache申请一个新的span对象,拿到span以后将span管理的内存按大小切好作为自由链表链接到一起。然后从span取对象给thread cache。central cache的中挂的span中use_count记录分配了多少个对象出去,分配一个对象给thread cache,就++use_count
释放内存:
当thread_cache过长或者线程销毁,则会将内存释放回central cache,释放回来时use_count--。当use_count减到0时则所有对象都回到了span,则将span释放回page cache,page cache中会对前后相邻的空闲页进行合并。
2.基本架构设计
我们根据刚刚的叙述先写出span的架构,并完成central cache基本框架,这里的spanlist要采用带头双向循环链表,因为在 central cache 的运作中,span 的移除操作非常频繁,而且有可能你前一个span还挂在那里的,后面那个span分配释放格外活跃,那删除和插入岂不是时间开销会很大?所以采用带头双向循环链表,不仅如此,当usecount==0时,central cache 需要立即将其从当前 SpanList 移除,还给page cache,此外,central cache是由桶锁保护的,所以别忘了私有成员加上mutex,随后设计一下成员函数就行,参考链表的设计就Ok
// 管理多个连续页大块内存跨度结构
struct Span
{
PAGE_ID _pageId = 0; // 大块内存起始页的页号
size_t _n = 0; // 页的数量
Span* _next;// 双向链表的结构
Span* _Prev;
size_t _useCount = 0; // 切好小块内存,被分配给thread cache的计数
void* _freelist = nullptr; // 切好的小块内存的自由链表
};
// 带头双向循环链表
class SpanList
{
public:
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_Prev = _head;
}
void Insert(Span* pos, Span* newSpan)
{
//双向链表的插入
assert(pos);
assert(newSpan);
Span* prev = pos->_Prev;
//prev newSpan pos
prev->_next = newSpan;
newSpan->_Prev = prev;
newSpan->_next = pos;
pos->_Prev = newSpan;
}
void Erase(Span* pos)
{
assert(pos);
assert(pos != _head); //别把哨兵节点删了就行
Span* prev = pos->_Prev;
Span* next = pos->_next;
prev->_next = next;
next->_Prev = prev;
}
private:
Span* _head;
public:
std::mutex _mtx;
};2.1 PAGE_ID
这里在定义 pageid时,我们要注意一点:32位机器和64位机器在相同条件下页数是不一样的,比如同为一页放2^13,x86环境下需要2^32/2^13=2^19个页,x64环境下需要2^64/2^13=2^51个页
所以为了不引起混乱,我们采用条件编译:
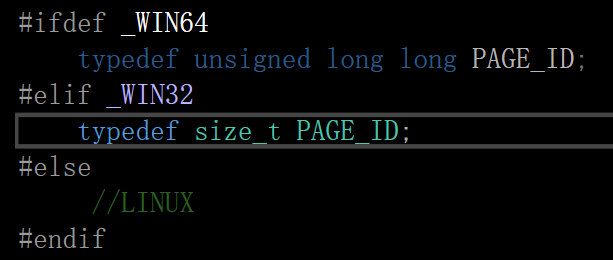
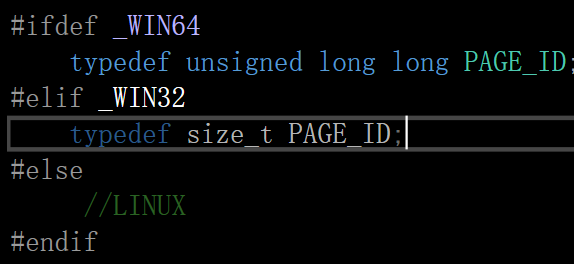
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#else
//LINUX
#endif顺序不可颠倒,因为:

我们看vs显示:颜色显示不同,亮的是定义的typedef
x86:
x64:
3.核心结构设计
我们在设计central cache的核心代码时,应该使用单例模式,这里我用了饿汉模式(上来就创建)
为什么要采取单例模式呢?因为首先它是线程安全的,不需要像饿汉模式那样加锁,其次如果不使用单例模式,那就会有多个Central Cache,造成内存池割裂,后果就是不同 central cache 管理的 span 无法互通,thread cache A 归还的内存无法被 thread cache B 利用,而且可以会增加对锁的竞争,现在不仅thread cache在central cache这里取内存要锁了,而且两个central cache可能还要竞争锁资源,导致性能降低,所以一定要用单例模式!!
#pragma once
#include"Common.h"
//单例模式
class CentralCache
{
public:
static CentralCache* GetInstance() //获取单例
{
return &_sInst;
}
// 获取一个非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);//size为单个大小,batchnum为总个数
private:
SpanList _spanLists[NFREELIST];
private:
CentralCache()
{}
CentralCache(const CentralCache&) = delete; //禁止拷贝构造
static CentralCache _sInst;
};4.内存分配
4.1 计算实际分配的数量
上文说到,thread cache内存不够时,会向central cache索要内存,central cache也不是说你要多少就定值给你多少,会一次性多给一些,剩的就放到central cache中,这样可以提高效率~
我们的步骤就是先获取索引,找到对应的桶,之后在这个freelist里面截取需要的长度
#include"CentralCache.h"
CentralCache CentralCache::_sInst;
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t byte_size)
{
//...
return nullptr;
}
// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
//先获取索引,知道size大小的是存在哪个桶里
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock(); //中心缓存是带锁的
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span->_freelist);
// 从span中获取batchNum个对象
// 如果不够batchNum个,有多少拿多少
//方法可以参考遍历链表
start = span->_freelist;
end = start;
size_t i = 0;
size_t actualNum = 1; //实际开出来的数量
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
i++;
actualNum++;
}
//此时end走到了应该停止的位置了,即batchnum的位置数
//end前面的内存就被我开辟走了,spanlist的指针要指向end后面的那一块,以备再用
span->_freelist = NextObj(end);
NextObj(end) == nullptr;
_spanLists[index]._mtx.unlock();
return actualNum;
}4.2 获取内存
那么现在的问题就是分配内存为多少合适呢?我们可以先整体这样给一分为二:
static size_t NumMoveSize(size_t size)// 一次thread cache从中心缓存获取多少个
{
assert(size > 0);
// [2, 512],一次批量移动多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 大对象一次批量上限低
int num = MAX_BYTES / size;
if (num < 2)
num = 2; //分太少了一次不值得,下次还得申请,不如这次多给点
if (num > 512)
num = 512; //分太多了也用不完,该浪费了
return num;
}用MAX_BYTES(256*1024)/size得出分配大小,之后进行二分
但是这样二分之后也有点浪费啊,所以我们还要采取慢启动的方法~具体见代码注释,注意这里我是在说从central cache向thread cache分配内存的规则,不要跟等下central cache内部的搞混!
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 慢开始反馈调节算法
// 1、最开始不会一次向central cache一次批量要太多,因为要太多了可能用不完
// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限
// 3、size越大,一次向central cache要的batchNum就越小
// 4、size越小,一次向central cache要的batchNum就越大
//这样还是不太好,比如我要1byte内存,但是通过这个函数会直接给我分配512的空间,太多了,
//size_t batchNum = SizeClass::NumMoveSize(size);
//可以这样进行慢开始:先+1+1的缓慢增长,达到一定数量后在快速增长
size_t batchNum = std::min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize()++;
}
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 1);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
_freeLists[index].PushRange(NextObj(start), end);
return start;
}
}central cache代码编写完成~