目录
[二、Block Group](#二、Block Group)
[三、Block Group内部结构](#三、Block Group内部结构)
[3.1、超级块------Super Block](#3.1、超级块——Super Block)
[3.3、块位图------Block Bitmap](#3.3、块位图——Block Bitmap)
[3.4、inode位图------Inode Bitmap](#3.4、inode位图——Inode Bitmap)
[3.5、i 节点表 ------inode Table](#3.5、i 节点表 ——inode Table)
[3.6、数据块------Data Blocks](#3.6、数据块——Data Blocks)
[4.1、 inode和datablock映射](#4.1、 inode和datablock映射)
[思考:基于 inode 号的文件增、删、查、改到底在做什么?](#思考:基于 inode 号的文件增、删、查、改到底在做什么?)
[1. 查:根据 inode 号定位并读取文件](#1. 查:根据 inode 号定位并读取文件)
[2. 改:修改文件内容或元数据](#2. 改:修改文件内容或元数据)
[3. 增:基于 inode 号创建新文件](#3. 增:基于 inode 号创建新文件)
[4. 删:删除文件或硬链接](#4. 删:删除文件或硬链接)
[💡 结论:](#💡 结论:)
前言
上一篇博客我们还遗留了几个问题,说到底就是文件系统的管理逻辑,那么今天我们就以经典的Ext2文件系统进行讲解,让我们更深入理解文件在磁盘上的管理,并与前面的文件也IO联系起来。
一、宏观认识
磁盘的空间一般都非常大,操作系统想要直接进行管理就比较困难,这时候就可以借鉴"分治"的管理思想。
比如国家的管理:先划分省,再由省划分市,再由市划分乡镇...,这样只要管理好乡镇,就相当于管理好了市,管理好了市,就相当于管理好了省,以此类推,就管理好了整个国家。
操作系统对磁盘的管理也是这样,先将磁盘进行划区(Partition) ,然后对一个区引入文件系统进行管理,其他区复制该管理方式即可实现对整盘的管理。本质就是将区格式化为某种格式的文件系统。
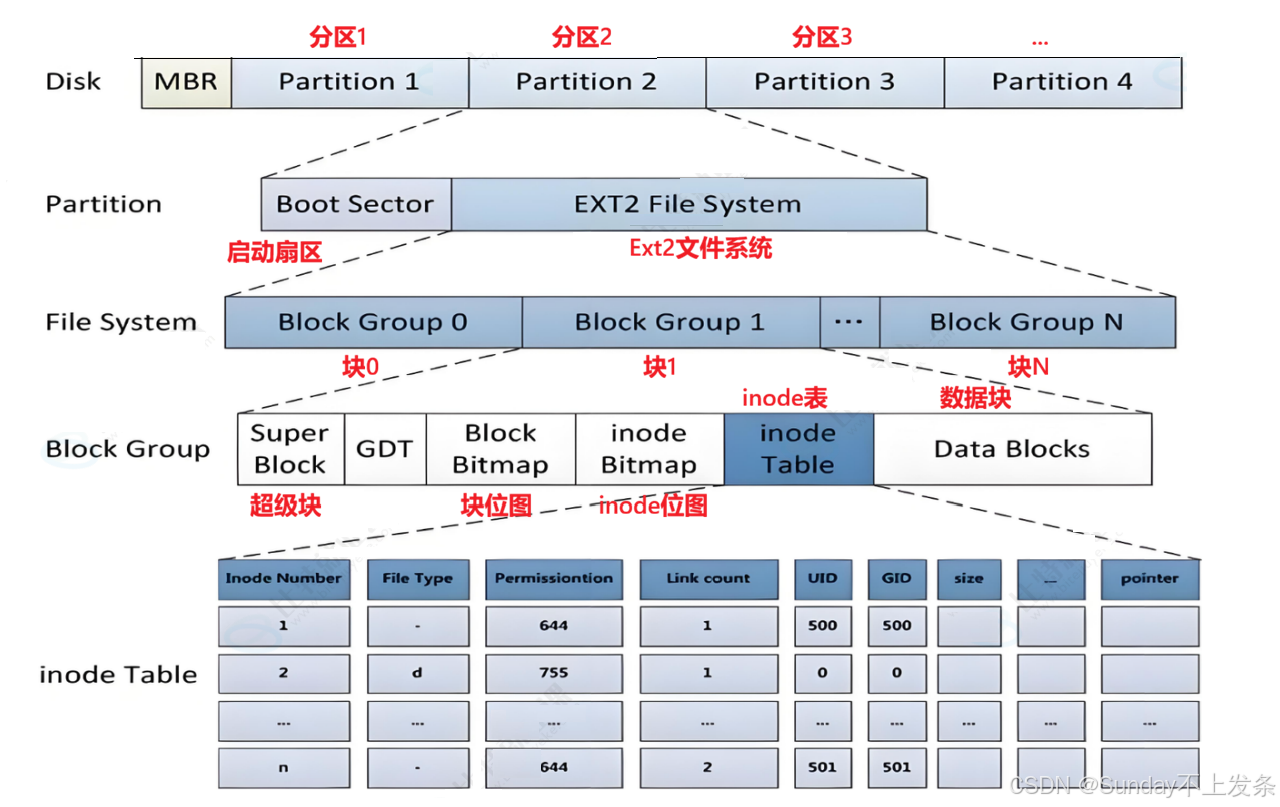
上图中启动块(Boot Sector)的大小是确定的,为1KB,由PC标准规定,用来存储磁盘分区信 息和启动信息,任何文件系统都不能修改启动块。启动块之后才是ext2文件系统的开始。
二、Block Group
前面讲到磁盘的最小存储单元是扇区(0.5KB) ,但如果以扇区为单位向磁盘读写数据就会导致效率太低,所以Ext2文件系统以数据块(常见为4KB,8个扇区)为单位进行数据的读写 。而系统默认的一个Block Group包含8192个数据块,即32MB。
以最小数据块为单位访问磁盘,不仅能一次性读写更多数据,还能利用数据的局部性原理提前缓存相关数据,从而显著提高内存缓存命中率和操作系统的整体效率。
所以,Ext2文件系统将区又划分块进行管理 ,类似于省分治市。每个块都有相同的结构,最小数据块的大小在格式化时进行配置,常见的块大小有 1KB、2KB、4KB,部分架构下最大支持 8KB,Block Group的大小根据数据块大小而异。通常情况下块的大小为4KB(8个扇区)。
++注意:++
文件系统最小存储单位为 数据块(假设4KB),所以在Block Group中所有的结构都是以 最小数据块为单位进行存储的。即超级块,位图,inode节点表,inode节点,数据块的大小都是以 最小数据块(4KB)为单位的。
三、Block Group内部结构
3.1、超级块------Super Block
存放文件系统本身的结构信息,描述整个分区的文件系统信息。
记录的信息主要有:bolck 和 inode的 总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写 入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
可见其重要性,如果Super Block的信息被破坏,可 以说整个文件系统结构就被破坏了。所以,Super Block没有放在区分里,而是放在块中,相当于有多个备份,这些Super Block中的数据保持一致。
/*
* Structure of the super block
*/
// 超级块的结构定义
struct ext2_super_block
{
__le32 s_inodes_count; // 索引节点(inode)总数
__le32 s_blocks_count; // 数据块总数
__le32 s_r_blocks_count; // 保留数据块总数(预留供超级用户/系统使用,防止磁盘占满导致系统异常)
__le32 s_free_blocks_count; // 空闲数据块数量(动态更新)
__le32 s_free_inodes_count; // 空闲索引节点(inode)数量(动态更新)
__le32 s_first_data_block; // 第一个数据块的编号(标记文件系统中数据块的起始位置)
__le32 s_log_block_size; // 数据块大小(以对数形式存储,实际大小=1024×2^该字段值)
__le32 s_log_frag_size; // 碎片大小(以对数形式存储,用于碎片管理)
__le32 s_blocks_per_group; // 每个块组包含的数据块数量
__le32 s_frags_per_group; // 每个块组包含的碎片数量
__le32 s_inodes_per_group; // 每个块组包含的索引节点(inode)数量
__le32 s_mtime; // 最后一次挂载文件系统的时间(时间戳格式)
__le32 s_wtime; // 最后一次对文件系统执行写操作的时间(时间戳格式)
__le16 s_mnt_count; // 累计挂载次数(挂载一次则自增1)
__le16 s_max_mnt_count; // 最大允许挂载次数(达到该次数后,建议执行fsck文件系统检查)
// ...
__le16 s_inode_size; // 单个索引节点(inode)结构体的大小(字节数)
__le16 s_block_group_nr; // 该超级块所属的块组编号(用于备份超级块的识别)
char s_last_mounted[64]; // 最后一次挂载的目录路径(记录该文件系统上次挂载到系统中的哪个目录)
// ...
};3.2、块组描述符表------GDT
描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。
每个块组描 述符存储一个块组 的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
/*
* Structure of a blocks group descriptor
*/
// 块组描述符的结构定义
struct ext2_group_desc
{
__le32 bg_block_bitmap; // 该块组中块位图所在的数据块编号(通过该编号可直接找到块位图)
__le32 bg_inode_bitmap; // 该块组中inode位图所在的数据块编号(通过该编号可直接找到inode位图)
__le32 bg_inode_table; // 该块组中 inode表的起始数据块编号(通过该编号可直接找到 inode 表的起始位置)
__le16 bg_free_blocks_count; // 该块组中当前的空闲 数据块数量(动态更新,创建/删除文件时变化)
__le16 bg_free_inodes_count; // 该块组中当前的空闲 inode数量(动态更新,创建/删除文件时变化)
__le16 bg_used_dirs_count; // 该块组中当前已创建的 目录数量(动态更新,创建/删除目录时变化)
__le16 bg_pad;// 填充字段(用于内存对齐,保证后续字段符合 CPU 访问规范,提升读写效率)
__le32 bg_reserved[3]; // 预留字段(为 Ext2 后续版本扩展预留空间,当前未使用)
};3.3、块位图------Block Bitmap
Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。
用一个比特位映射一个数据块(Data Blocks),以 0/1 标记对应的数据块的占用情况。
3.4、inode位图------Inode Bitmap
与块位图类似,Inode Bitmap的每个bit表示一个inode是否空闲可用。
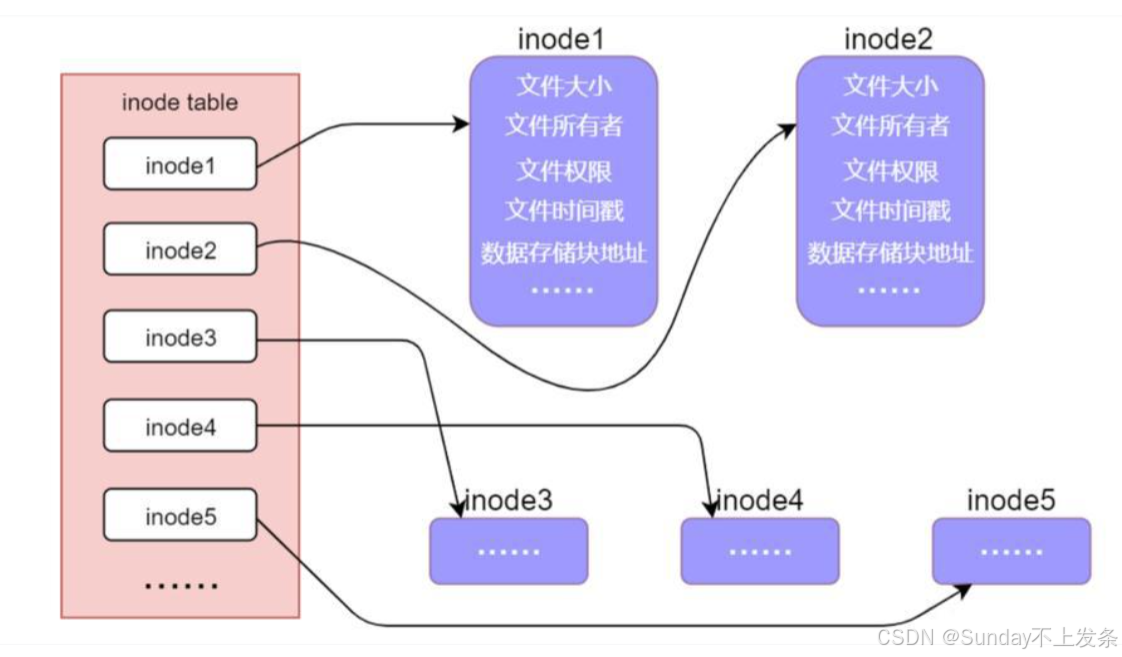
3.5、i 节点表 ------inode Table
文件 = 属性 + 内容,属性数据就存储在inode Table 中。
- 存放文件属性 如 文件大小,所有者,最近修改时间等
- 当前分组所有Inode属性的集合
- inode编号以分区为单位,整体划分,不可跨分区,说明另一个分区的inode编号又从1开始。
/*
* Structure of an inode on the disk
*/
// 磁盘上的 inode 结构体定义(即 inode 表中单个节点的结构)
struct ext2_inode
{
__le16 i_mode; // 文件类型与访问权限(如普通文件、目录、读写执行权限等,对应 chmod 命令修改的内容)
__le16 i_uid; // 文件所有者的用户 ID(通常 root 为 0,普通用户为递增数值)
__le32 i_size; // 文件大小(以字节为单位,仅对普通文件有效)
__le32 i_atime; // 最后一次访问文件的时间(如 cat 读取文件,不会修改该文件的内容,仅更新此时间)
__le32 i_ctime; // 文件元数据最后修改的时间(如修改文件权限、所有者,会更新此时间;创建文件时初始化)
__le32 i_mtime; // 文件内容最后修改的时间(如 vim 编辑保存文件,会更新此时间,对应 stat 命令查看的 mtime)
__le32 i_dtime; // 文件删除时间(文件被删除时记录此时间戳,未删除时为 0)
__le16 i_gid; // 文件所有者的用户组 ID(对应文件所属的用户组)
__le16 i_links_count; // 硬链接数量(文件的硬链接计数,当计数为 0 时,才会真正释放 inode 和数据块)
__le32 i_blocks; // 该文件占用的数据块总数(注意:此处块通常为 512 字节一个,与 Ext2 的文件系统块不同)
__le32 i_flags; // 文件标志位(用于控制文件的特殊行为,如是否允许追加写入、是否为只读等)
// ...
__le32 i_block[15]; // 数据块指针(直接+间接,共15个)
// 文件数据块的指针数组(共 15 个指针,分为 3 类:
// 1-12:直接指针,直接指向存储文件内容的数据块
// 13:一级间接指针,指向一个存储数据块编号的间接块
// 14:二级间接指针,指向一个存储一级间接块编号的块
// 15:三级间接指针,指向一个存储二级间接块编号的块)
// ...
};++补充:++
- 每个inode 大小均为 128 字节,而一个最小的数据块为4KB(4096字节),则一个数据块可以存储4096 / 128 = 32 个inode。
- 通过inode号就能索引到inode table。
3.6、数据块------Data Blocks
数据块:存放文件内容,也就是一个一个的Block。
根据不同的文件类型有以下几种情况:
- 对于普通文件,文件的数据存储在数据块中。
- 对于目录文件,该目录下的所有文件名和目录名存储在所在目录的数据块中(即目录文件的文件内容为文件名和目录名),除了文件名外,ls -l命令 看到的其它信息保存在该文件的inode中。
- Data Block 号按照分区划分,不可跨分区。
Data Blocks的大小和最小存储单元数据块的大小一致为4KB。
/*
* Structure of a directory entry
*/
// 目录项的结构定义
struct ext2_dir_entry
{
__le32 inode; // 该文件名对应的 inode 编号(通过该编号可找到对应的 ext2_inode 结构体,获取文件元数据)
__le16 rec_len; // 该目录项的总长度(字节数,用于跳过当前目录项,查找下一个目录项,支持变长对齐)
__le16 name_len; // 文件名的实际长度(字节数,最大不超过 255)
char name[]; // 文件名(变长数组,存储实际的文件名,长度由 name_len 指定,无结束符 '\0')
};通过inode 就可以索引到对应文件的数据块。
四、inode索引数据块逻辑
4.1、inode和datablock映射
在 Ext2 文件系统中创建文件并写入数据时:
(1)操作系统先通过 inode 位图找到空闲 inode 节点并标记为已用,再通过块位图分配足够的空闲数据块并完成标记;
(2)随后将数据块编号存入 inode 的 **i_block[15] **指针数组,建立 inode 与数据块的关联,把文件数据写入对应数据块并完善 inode 元数据;
(3)最后在所属目录的数据块中新增 **ext2_dir_entry **结构体,完成「文件名 - inode 号」的映射,整个创建与写入流程就此完成。
struct ext2_inode
{
// ...
__le32 i_block[15]; // 数据块指针(直接+间接,共15个)
// 文件数据块的指针数组(共 15 个指针,分为 3 类:
// 1-12:直接指针,直接指向存储文件内容的数据块
// 13:一级间接指针,指向一个存储数据块编号的间接块
// 14:二级间接指针,指向一个存储一级间接块编号的块
// 15:三级间接指针,指向一个存储二级间接块编号的块)
// ...
};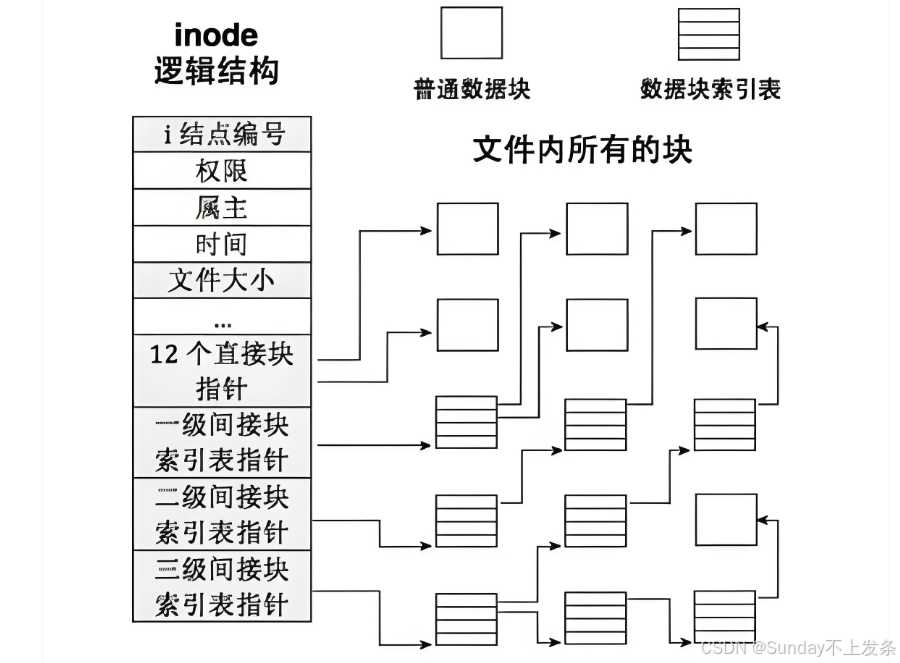
对于比较小的文件,inode 直接索引一个数据块进行存储;
一级间接块索引表指针指向一个数据块,32为下一个指针大小为4字节,而一个数据块为4096字节,则可以存储4096 / 4 = 1024 个指针,可以索引1024个数据块存储文件内容数据,大小为 1024 * 4KB = 4MB;
二级间接块索引表指针指向一个数据块,存储1024个指针,然后每个指针又指向一个数据块,则可以索引 1024 * 1024 = 1048576个数据块,大小为 4GB。
三级间接块索引表指针最终可以索引 1024^3 = 1073741824 个数据块,存储4TB数据。
思考:基于 inode 号的文件增、删、查、改到底在做什么?
1. 查:根据 inode 号定位并读取文件
- 核心操作 :
- 通过 inode 号在分区的**
inode table**中找到对应的 inode 节点。 - 读取 inode 节点中存储的元数据(权限、大小、时间戳、数据块指针等)。
- 按照 inode 中的数据块指针(直接 / 间接索引),找到所有数据块并读取内容。
- 通过 inode 号在分区的**
- 本质:通过 inode 号直接绕过文件名,定位到文件的元数据和实际存储位置,是最底层的文件读取方式。
2. 改:修改文件内容或元数据
改操作分为两种场景,底层逻辑不同:
- 修改文件内容 :
- 定位 inode 节点,检查 inode 的写权限。
- 若写入内容未超出已分配的数据块大小:直接在原数据块中覆盖写入。
- 若写入内容需要扩展:inode 会申请新的数据块,并更新自身的索引指针,同时修改 inode 中的文件大小、修改时间戳。
- 修改文件元数据:直接修改 inode 节点中存储的信息(如权限、所有者、时间戳),无需改动数据块。
3. 增:基于 inode 号创建新文件
bash
touch test.c // 创建文件
ls -i test.c // 查看文件inode号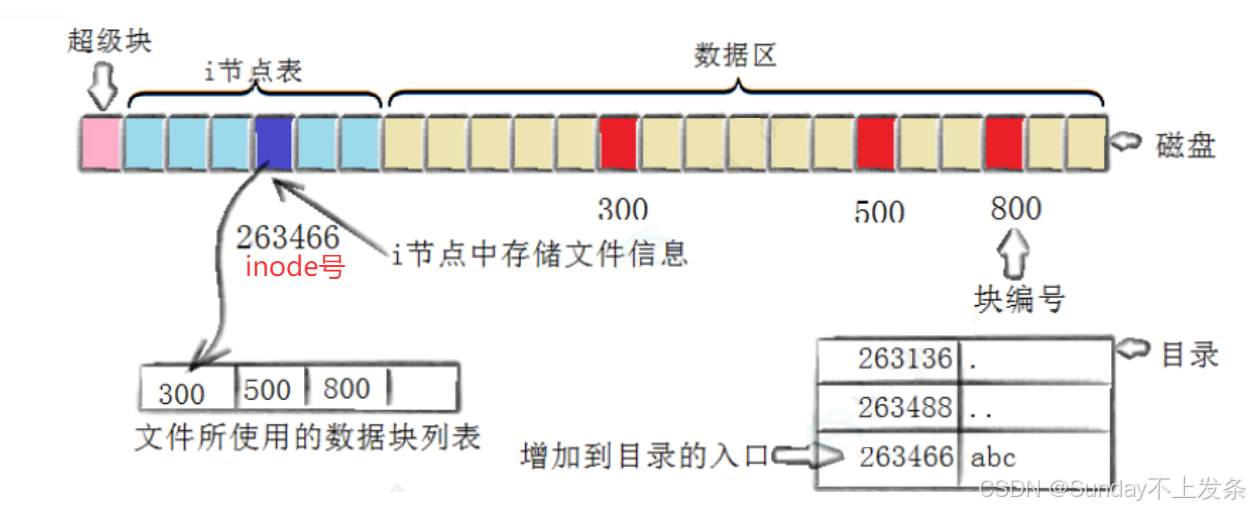
创建一个新文件主要有以下4个操作:
- **存储属性:**内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。
- **存储数据:**该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块 数据复制到300,下一块复制到500,以此类推。
- **记录分配情况:**文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
- **添加文件名到目录:**新的文件名abc。linux如何在当前的目录中记录这个文件?内核将入口(263466,abc)添加到 目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
4. 删:删除文件或硬链接
删除操作的核心是处理 inode 的链接计数和数据块回收:
- 找到目标 inode 号对应的 inode 节点,将其链接计数(link count)-1。
- 从对应目录的目录项中,删除 "文件名→inode 号" 的映射记录。
- 若链接计数降至 0:
- 将 inode 节点标记为 "空闲",回收至 inode table 的空闲链表。
- 将 inode 指向的所有数据块标记为 "空闲",回收至块位图(block bitmap)。
- 本质:文件真正的删除发生在 "链接计数为 0" 时,此时系统才会回收 inode 和数据块;若仅删除一个硬链接,只要链接计数 > 0,文件数据仍存在。
💡 结论:
- 分区之后的格式化操作,就是对分区进行分组,在每个分组中写入SB、GDT、Block Bitmap、Inode Bitmap等管理信息,这些管理信息统称: 文件系统
- 只要知道文件的inode号,就能在指定分区中确定是哪一个分组,进而在哪一个分组确定 是哪一个inode。
- 拿到inode文件属性和内容就全部都有了。
定位inode table的过程完全不需要 inode 号、也不需要任何 inode 节点 ,**inode table**是文件系统格式化时就固定在分区的独立元数据区域。系统通过 ** 超级块(Super Block)** 即可直接定位,inode 号仅用于定位**
inode table**内部的某个具体 inode 节点。
struct ext2_super_block { /* 1. 块大小相关:辅助计算 inode table 占用的磁盘块数、间接推导偏移 */ __le32 s_log_block_size; /* 2. 单个 inode 节点的大小(字节):核心用于计算 inode 在 table 中的偏移 */ __le16 s_inode_size; /* 3. 每个块组的 inode 总数:描述单个块组中 inode table 的容量 */ __le32 s_inodes_per_group; /* 4. 整个分区的 inode 总数:间接推导 inode table 的总规模(跨所有块组) */ __le32 s_inodes_count; /* 5. 第一个可用的 inode 号:限定 inode table 的有效索引范围 */ __le32 s_first_ino; /* 6. 单个块组中 inode 位图的起始块号:辅助管理 inode table 的空闲状态 */ __le32 s_inode_bitmap; /* 7. 单个块组中 inode table 的起始块号:直接定位 inode table 的物理位置(核心中的核心) */ __le32 s_inode_table; };
4.2、文件与目录名
💡 我们在访问文件时使用的都是文件名,没有用到 inode 号啊?
💡 目录是不是文件呢?
Linux中一切皆文件,目录当然也是一个文件,所以目录也有属性和内容。属性与普通文件相同;而其内容则是文件名与 inode号的映射关系。
4.2.1、路径解析
💡 问题:打开当前工作目录文件,查看当前工作目录文件的内容,还得知道当前工作目录的上级目录文件的inode,不也得知道当前工作目录的上级目录吗?
答:由于文件再带路径,所以系统会自动递归解析文件的完整路径,逐层查找目录项。
举个例子:访问**
/home/user/test.txt**,系统的底层操作是:
- 先找到根目录
/的 inode 号(固定为 2,系统保留),解析根目录的目录项,找到home对应的 inode 号;- 再通过**
home** 的 inode 号找到其目录数据块,解析目录项,找到**user** 对应的 inode 号;- 最后通过
user的 inode 号找到其目录数据块,解析目录项,找到 **test.txt**对应的 inode 号;- 拿到
test.txt的 inode 号后,进行后续的增删改查操作。
💡 问题:可是路径谁提供?
创建文件本质就是在磁盘文件系统中,新建目录文件。而你新建的任何文件,都在你或者系 统指定的目录下新建,而这就是天然就有路径!
💡注意:
- 所以,我们知道了:访问文件必须要有目录+文件名=路径的原因
- 根目录固定文件名,inode号,无需查找,系统开机之后就必须知道
4.2.2、路径缓存
通过上面我们就知道了,访问文件都要从根目录开始进行路径解析,但每次这样不是太慢了嘛!
所以,当我们打开目录时,Linux会进行进行路径缓存,即操作系统在内存进行路径维护。
Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
bash
struct dentry
{
atomic_t d_count; // 目录项引用计数
unsigned int d_flags; // 目录项标志位(由d_lock自旋锁保护)
spinlock_t d_lock; // 每个目录项的专属自旋锁
struct inode *d_inode; // 该文件名所属的inode节点指针
// 若为NULL,表示此为负目录项(对应不存在的文件/目录)
struct hlist_node d_hash; // 哈希查找链表的节点(用于目录项哈希表)
struct dentry *d_parent; // 指向父目录的目录项指针
struct qstr d_name; // 封装后的目录项文件名(含名、长度、哈希值)
struct list_head d_lru; // 最近最少使用链表的节点(用于缓存回收)
union
{
struct list_head d_child; // 加入父目录子节点链表的节点
struct rcu_head d_rcu; // RCU机制的回收头(用于安全释放目录项内存)
} d_u;
struct list_head d_subdirs; // 指向当前目录项的所有子目录/文件节点链表头
struct list_head d_alias; // 指向同一inode的别名目录项链表(硬链接专用)
unsigned long d_time; // 时间戳(由d_revalidate函数使用,验证目录项有效性)
struct dentry_operations *d_op; // 指向目录项的操作函数集指针
struct super_block *d_sb; // 指向目录项树的根超级块(所属文件系统的超级块)
void *d_fsdata; // 文件系统专属的私有数据
#ifdef CONFIG_PROFILING // 若开启性能分析配置
struct dcookie_struct *d_cookie; // 性能分析的cookie结构(若有)
#endif
int d_mounted; // 标记是否为文件系统挂载点
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; // 内嵌短文件名缓冲区(存储短文件名,内存优化)
};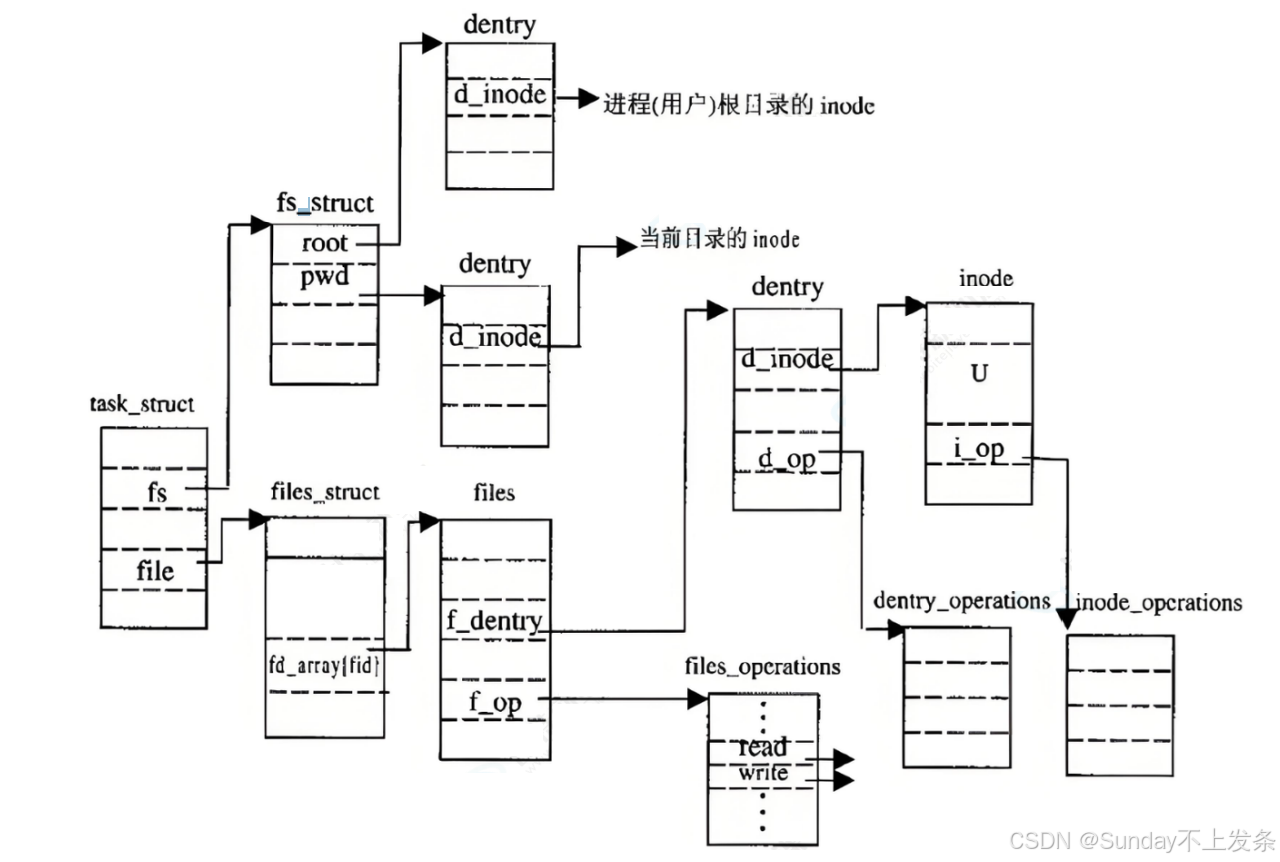
注意:
• 每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构;
• 整个树形节点也同时会隶属于LRU (Least Recently Used,最近最少使用) 结构中,进行节点淘汰;
• 整个树形节点也同时会隶属于Hash,方便快速查找;
• 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这 棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry 结构,缓存新路径。
4.3、挂载分区
有个问题,inode 号是以分区为单位进行划分的,仅在同一分区不冲突,即分区1,分区2,分区3...,中就会都有一个inode n(n号节点),那这些相同的inode 号会不会相互影响?
答:当然不会,因为Linux 将不同的磁盘分区挂载到不同目录下,形成统一的文件路径体系,所以根据路径就能够区分inode号来自哪个分区。
无论哪个分区的文件,最终都会有一个唯一的绝对路径,Linux 通过这个路径先定位到文件所属的分区,再在该分区内通过 inode 编号找到对应的 inode 结构体,后续再通过 inode 的索引机制访问数据块。路径成为了跨分区识别 inode 的 "唯一标识",从根本上解决了 inode 编号重复的问题。
五、软硬链接
5.1、硬链接
硬链接本质为让多个文件名与一个inode 关联,创建硬链接后,所有链接文件的 inode 编号、文件内容、权限完全一致,内核会记录该 inode 的 "硬链接数"(即绑定的文件名数量)。
bashln abc def // 让 def文件与abc建立硬链接 ls -i abc def // 查看abc与def的inode
文件 abc与文件def 的inode 相同。
bashls -li abc // 查看abc的硬链接数
💡++注意:++
当我们删除硬链接的文件时,只有当硬链接数变为0时,系统才会释放该 inode 对应的磁盘空间(真正删除文件内容)。
5.2、软链接
软链接是 Linux 中基于文件路径的引用方式 ,核心是创建一个特殊的小文件 ,该文件本身仅存储目标文件 / 目录的绝对 / 相对路径,而非目标的 inode 号或数据,访问软链接时,系统会自动根据存储的路径跳转到目标文件 / 目录,类似 Windows 的快捷方式,是 Linux 中跨分区、跨文件系统引用文件的核心方式。
bash
ln -s abc abc.s // 创建abc的软链接abc.s
ls -li // 查看文件信息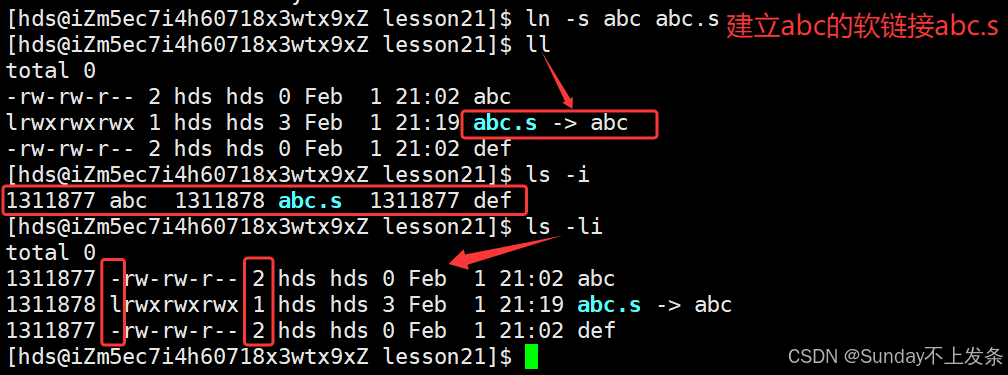
软链接是创建一个新文件,inode 不同。
😄 创作不易,你的点赞和关注都是对我莫大的鼓励,再次感谢您的观看😘