1、有下面两张表,user(用户表)和thread(帖子表),假设有100W用户,500W帖子,写一条SQL,显示前十名发帖最多的用户的名字及帖子数量,并针对该语句指出如何设计合理的索引字段。
如何确认你写的sql会用到哪个索引,另外请说明下你写的SQL是否是最优解
表名 字段
user uid, username, password, create_time
thread tid, uid, title, content, create_time
解答:
SELECT u.username, COUNT(t.user_id) AS post_count FROM user uJOIN thread t ON u.id = t.user_idGROUP BY u.idORDER BY post_count DESCLIMIT 10;
2、innodb一次主键查询、普通索引查询、无索引查询的区别是什么?
innodb关系型存储引擎
javascript
总体概况
-- 创建普通索引示例
CREATE TABLE user (
id INT PRIMARY KEY, -- 聚簇索引
username VARCHAR(50),
email VARCHAR(100),
age INT,
INDEX idx_username (username), -- 普通索引
INDEX idx_age_email (age, email) -- 复合普通索引
);基础介绍:
- 缓冲池:遵循"检查点"和"写回"机制,而不是每次修改都写盘,常使用LRU管理页的淘汰
- 写缓冲 :优化""非唯一"二级索引更新操作而设计,当需要更新一个二级索引页,而该页又不在缓冲池时,这个改动不会立即从磁盘加载索引页,而是先记录到写缓冲中 。待未来该页被读取时,再合并改动。这减少了大量的随机磁盘I/O
自适应哈希索引:发现某些索引值被非常频繁地用等值查询(=)访问,它会在内存中基于缓冲池的B+树页,为其建立一个哈希索引。下次查询可直接通过哈希O(1)定位,无需从B+树根开始查找。
javascript
eg:domo案例分析
-- 1.测试中发现锁竞争
SHOW ENGINE INNODB STATUS\G 检查引擎状态
-----当SEMAPHORES部分显示大量等待时
2.SELECT IF(@ENABLE_Detailed_semaphore),
'信息量详细信息:',
'跳过详细信号量检查') AS check_point;
3.监控当前锁情况
SELECT IF(@enable_lock_wait_info,
CONCAT('当前时间: ', NOW(), ' - 锁等待监控'),
'锁等待监控已禁用') AS lock_monitor;
-- ----创建死锁监控表
CREATE TABLE deadlock_monitor (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
deadlock_time DATETIME DEFAULT CURRENT_TIMESTAMP,
victim_trx_id BIGINT,
details TEXT,
resolved_by ENUM('timeout', 'detection') DEFAULT 'detection'
);
4. 定期检查死锁统计
SELECT
DATE(deadlock_time) as day,
HOUR(deadlock_time) as hour,
COUNT(*) as deadlock_count,
GROUP_CONCAT(DISTINCT resolved_by) as resolution_types
FROM deadlock_monitor
GROUP BY DATE(deadlock_time), HOUR(deadlock_time)
ORDER BY day DESC, hour DESC;3、请用尽可能少的代码实现一个函数,用于计算用户一个月共计交费多少港元。(代码请写的尽量清晰简洁,我们希望能够看到你的编码风格和习惯)
用户在富途的平台上进行交易,需要交平台使用费。平台使用费的梯度收费方案如下:
每月累计订单数 每笔订单(港元)
梯度1:1-5笔 => 30.00
梯度2:6-20笔 => 15.00
梯度3:21-50笔 => 10.00
梯度4:51笔及以上 => 1.00
假设一个用户,一个月交易了6笔订单,则在梯度1交费共计: 30港元*5=150港元,在梯度二交费:15港元,一共交费165港元。
javascript
```python
在这里插入代码片def calculate_fee(order_count: int) -> float:
"""
计算用户月度平台使用费
Args:
order_count: 月度订单总数
Returns:
总费用(港元)
"""
# 梯度费率表:每笔订单费用(港元)
fee_rates = [
(5, 30.00), # 梯度1: 1-5笔
(15, 15.00), # 梯度2: 6-20笔(累计到20笔)
(30, 10.00), # 梯度3: 21-50笔(累计到50笔)
(float('inf'), 1.00) # 梯度4: 51笔及以上
]
total_fee = 0.0
remaining_orders = order_count
for threshold, rate in fee_rates:
if remaining_orders <= 0:
break
# 当前梯度的订单数量
orders_in_tier = min(remaining_orders, threshold)
# 如果是第一个梯度,直接用全部数量
if threshold == 5: # 梯度1
orders_in_tier = min(remaining_orders, 5)
else:
# 其他梯度需要减去前一个梯度的阈值
orders_in_tier = min(remaining_orders, threshold) - sum(
t for t, _ in fee_rates[:fee_rates.index((threshold, rate))]
)
# 确保订单数为非负数
orders_in_tier = max(0, orders_in_tier)
total_fee += orders_in_tier * rate
# 更新剩余订单数
remaining_orders -= orders_in_tier
return round(total_fee, 2)
# 测试用例
def test_calculate_fee():
"""测试函数"""
test_cases = [
(0, 0.0), # 无订单
(3, 90.0), # 只梯度1
(5, 150.0), # 梯度1满额
(6, 165.0), # 梯度1+梯度2
(20, 150 + 15*15), # 梯度1+梯度2满额
(21, 150 + 15*15 + 10*1), # 进入梯度3
(50, 150 + 15*15 + 10*30), # 梯度3满额
(51, 150 + 15*15 + 10*30 + 1*1), # 进入梯度4
(100, 150 + 15*15 + 10*30 + 1*50), # 大量订单
]
for orders, expected in test_cases:
result = calculate_fee(orders)
status = "✓" if abs(result - expected) < 0.01 else "✗"
print(f"{status} 订单数:{orders:3d} 预期:{expected:7.2f} 实际:{result:7.2f}")
if __name__ == "__main__":
test_calculate_fee()```4、假设给定两个int类型的有序数组A和有序数组B,并且每个数组中都可能存在重复的数字,现在要求给出一个算法判断A是否为B的子集(给出思路即可,不用写代码)
例如:
若A为【1, 1, 2, 3】,B为【1, 1, 1, 2, 2, 3】,则A为B的子集
若A为【1, 2, 2, 3】,B为【1, 1,2, 3, 3】,则A不为B的子集
选择双指针方案
初始化两个指针:
i = 0 指向数组A
j = 0 指向数组B
遍历A中每个元素:
- 对于Ai,统计它在A中的连续出现次数 countA 在B中从当前位置j开始,
- 统计相同元素的出现次数 countB 比较:
- 如果countA > countB,则A不是B的子集
如果 countA ≤ countB,继续处理A中的下一个元素
5、假设现在需要让你实现一个限频的需求,限制任意一个登录用户任意5分钟内不能发帖超过10次,
请给出详细的技术方案。
6.在进行商城购物车架构并发测试过程中常见的性能问题,进行性能测试的基础配置(衍生相关的解决方案及架构)
一、测试环境配置:
二、解决方案:全量数据库读写 &缓冲池缓冲 &分布式架构
test:
environment:
# 硬件配置
server:
cpu: 8核心
memory: 32GB
disk: SSD 500GB
# 中间件配置
middleware:
redis:
mode: cluster # 集群模式
nodes: 3主3从 # 6节点
memory: 8GB/node # 每节点内存
maxmemory-policy: volatile-lru
mysql:
version: 8.0
connection: 200 # 最大连接数
buffer-pool: 16GB # InnoDB缓冲池
kafka:
partitions: 12 # 分区数
replication: 2 # 副本数
# 压测工具配置
jmeter:
threads: 1000 # 并发线程数
ramp-up: 60 # 启动时间(秒)
duration: 300 # 压测时长(秒)
loop: forever # 循环次数
# 监控配置
monitoring:
prometheus:
scrape-interval: 5s # 采集间隔
grafana:
dashboards:
-
redis -performance
-
mysql-performance
-
application-metrics
拓展解决并发问题方案:
分布式架构
python
购物车服务实例(每个Pod):
├── Web容器层
│ ├── RESTful API端点
│ ├── GRPC接口
│ └── WebSocket连接
├── 业务逻辑层
│ ├── 购物车管理器
│ ├── 库存检查器
│ ├── 价格计算器
│ └── 促销应用器
├── 数据访问层
│ ├── 缓存客户端
│ ├── 数据库客户端
│ └── 消息生产者
└── 协调层
├── 配置客户端
├── 服务发现客户端
└── 分布式锁客户端数据存储架构
python
第一层:本地缓存(L1)
├── 存储:热点用户购物车数据
├── 技术:Caffeine/Guava Cache
├── 容量:每实例10,000用户
├── 过期:5分钟
└── 特点:极速读取,减少网络开销
第二层:分布式缓存(L2)
├── 存储:全量购物车数据
├── 技术:Redis Cluster
├── 分片:按用户ID hash分片
├── 结构:Hash存储购物车项
├── 容量:支持千万级用户
└── 特点:高可用,支持故障转移
第三层:持久化存储(L3)
├── 存储:购物车操作日志
├── 技术:MySQL分库分表
├── 分片:按用户ID range分片
├── 备份:实时同步到备库
└── 特点:数据持久化,支持审计库存扣减架构
python
库存管理策略:
1. 预扣库存
- 加入购物车时预扣
- 设置预扣超时时间(15分钟)
- 超时自动释放
2. 真实库存与可售库存分离
- 真实库存:物理库存
- 可售库存 = 真实库存 - 预扣库存
- 展示给用户可售库存
3. 库存分层次管理
- 总仓库存
- 区域仓库存
- 门店库存
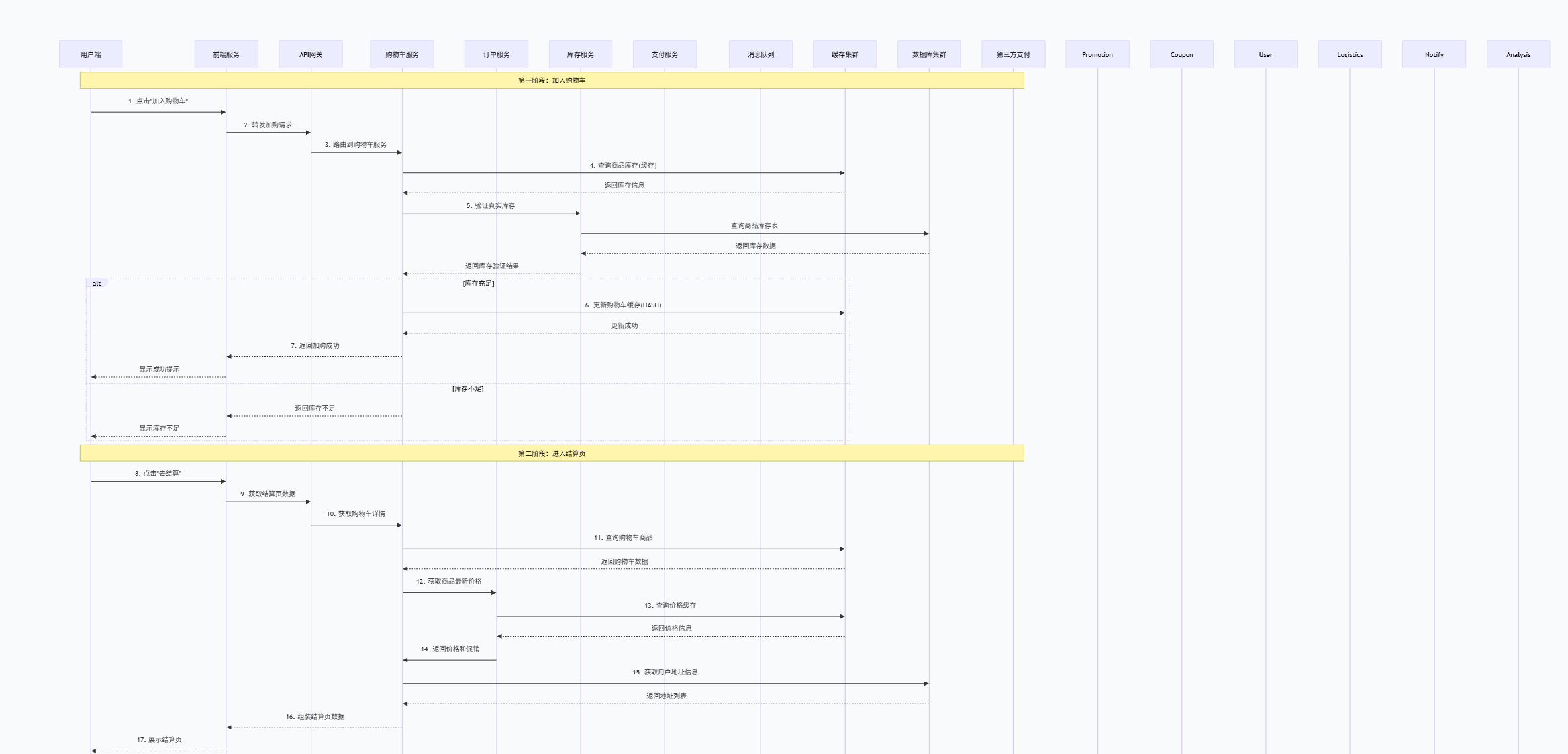
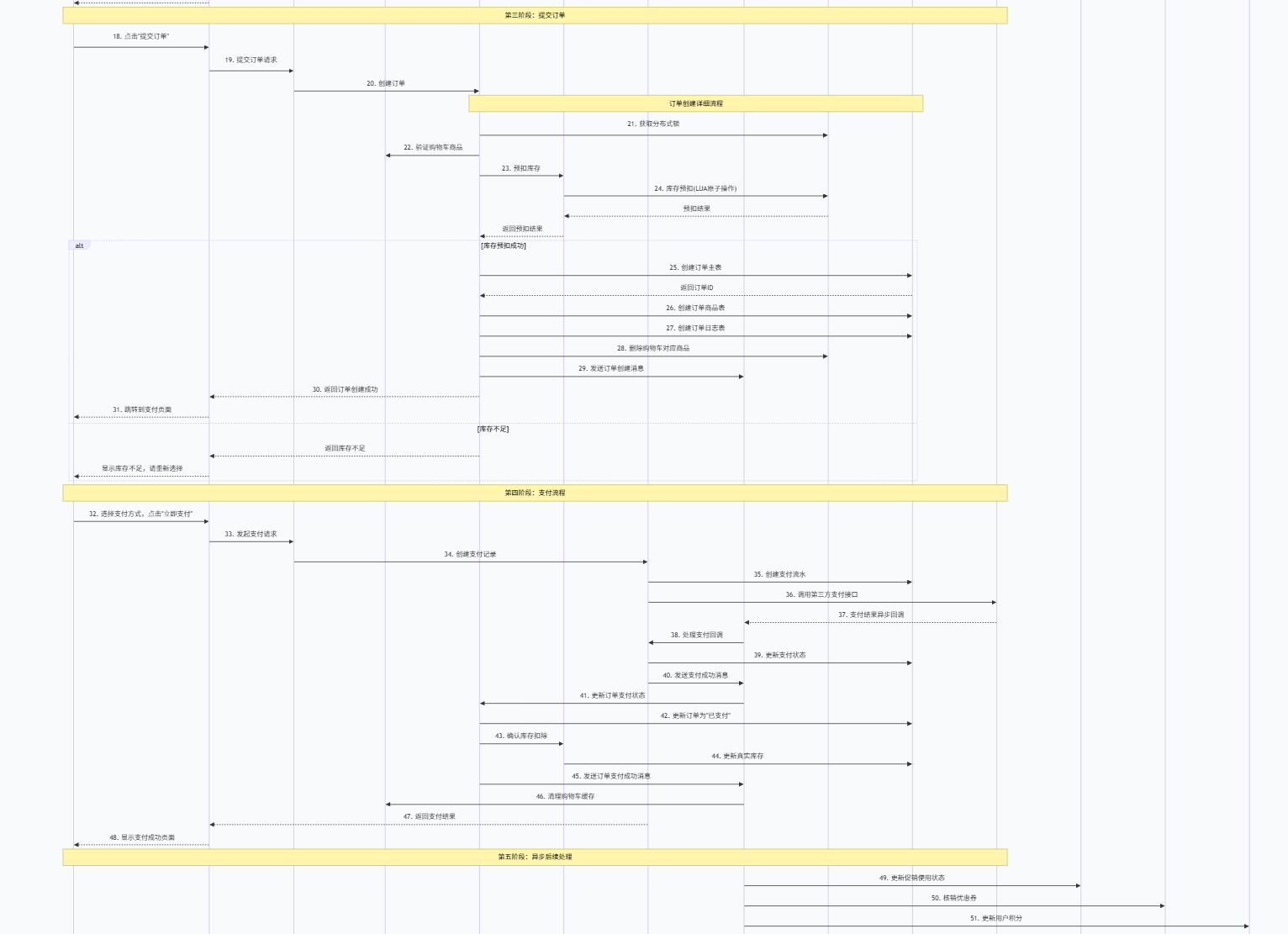
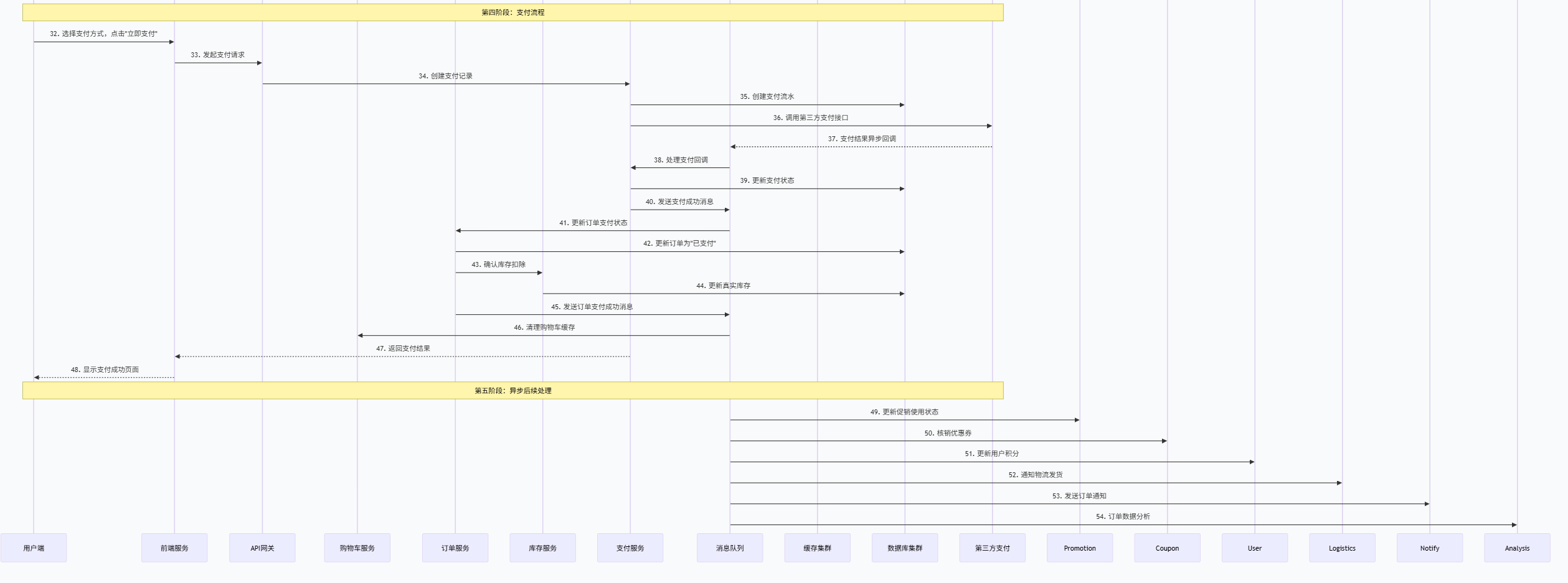
- 虚拟库存(预售)7.在进行第三方接口联通过程中,会遇到的联调问题,如何解决用户 → 商城下单 → 调用第三方支付 → 等待回调 → 状态不一致(超时/接口异常、数据不一致、重复处理等)情况
常见表现介绍:
调用超时:支付接口调用耗时过长,系统无法判断调用结果
回调丢失:第三方支付回调未到达或处理失败
数据不一致:商城状态与第三方支付状态存在差异
重复处理:因重试机制导致的重复支付或重复退款
通常 情况下使用的设置多个集群及对应设置多个节点

清晰总架构图方案(在进行第三方支付时,会进入支付回调服务):
解决方案及对应架构图展示:
业务核心逻辑层 :包含内容如下:
业务接入层 :接收用户支付请求,基础验证与参数处理
支付服务层:支付状态管理器:维护支付状态机,确保状态流转合法
幂等性检查器:防止重复支付的关键组件
分布式事务协调器:处理跨服务的原子性操作
渠道适配器:统一对接不同的第三方支付平台
数据存储层(多级存储策略) :
热点数据:Redis缓存,毫秒级响应
业务数据:MySQL分库分表,支持高并发写入
历史数据:归档存储,降低成本
审计日志:独立存储,满足合规要求
监控告警层 **(建立思维监控体系)**:
业务监控:支付成功率、转化率等
性能监控:接口响应时间、系统吞吐量
可用性监控:服务健康状态、依赖组件状态
一致性监控:数据一致性检查、异常告警
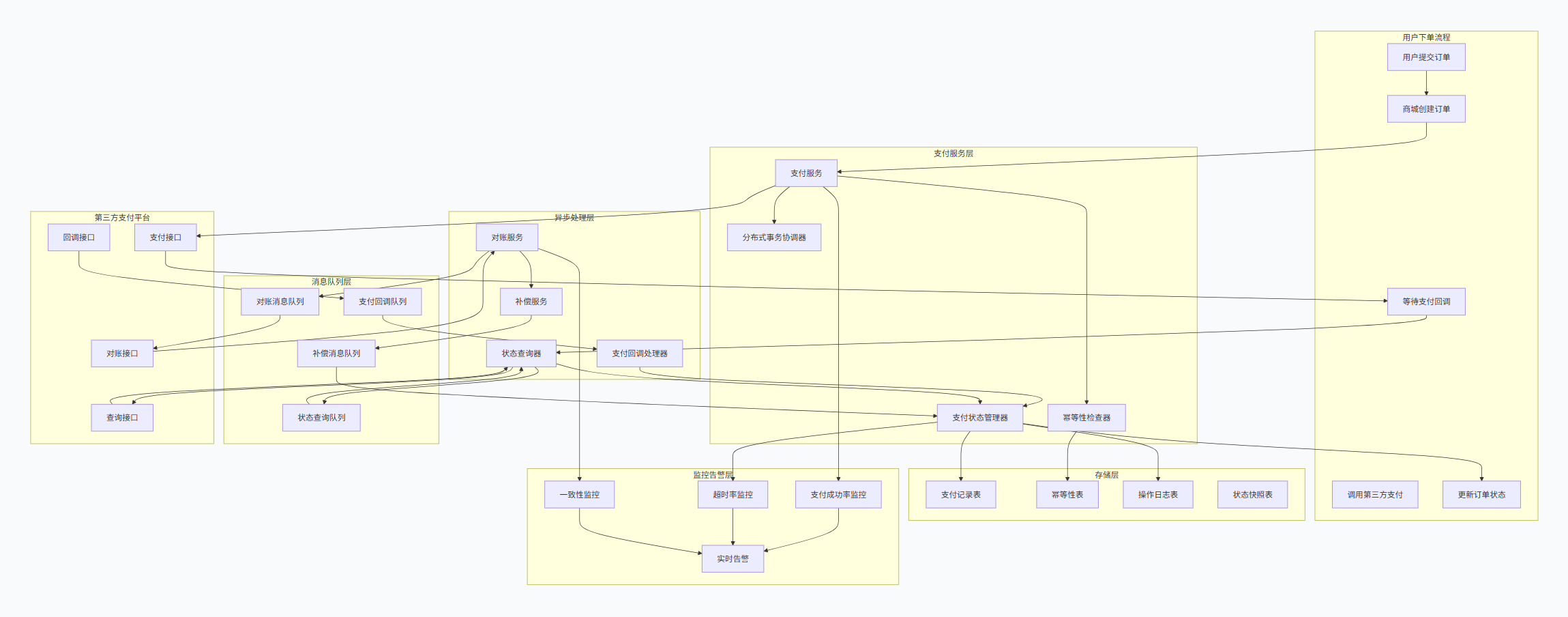
实际实施方案:
1.支付创建流程
请求接收---->幂等性检查----->参数验证---->状态流转--->调用第三方------>结果处理
2.支付回调处理
签证验证--->幂等性验证--->状态一致性检查--->业务处理--->异步确认
3.超时订单处理
对于长时间未收到回调的订单
定时扫描----->主动查询--->状态同步--->异步处理
预防措施:
1.分布式状态机
子状态细化:("支付中"为"调用接口中"、"等待回调中"、"主动查询中"),同一支付单状态变更获取分布式锁,防止并发更新
2.智能重试机制
设置重试时间机条件,在网络异常、超时异常需要重试**,智能重试平衡了成功率和响应时间,避免无效重试**
3.数据对账
数据准备(本地 vs 第三方)账单----->数据匹配(流水号、金额、时间多维度匹配)---->差异分析---->处理差异----》对账报告
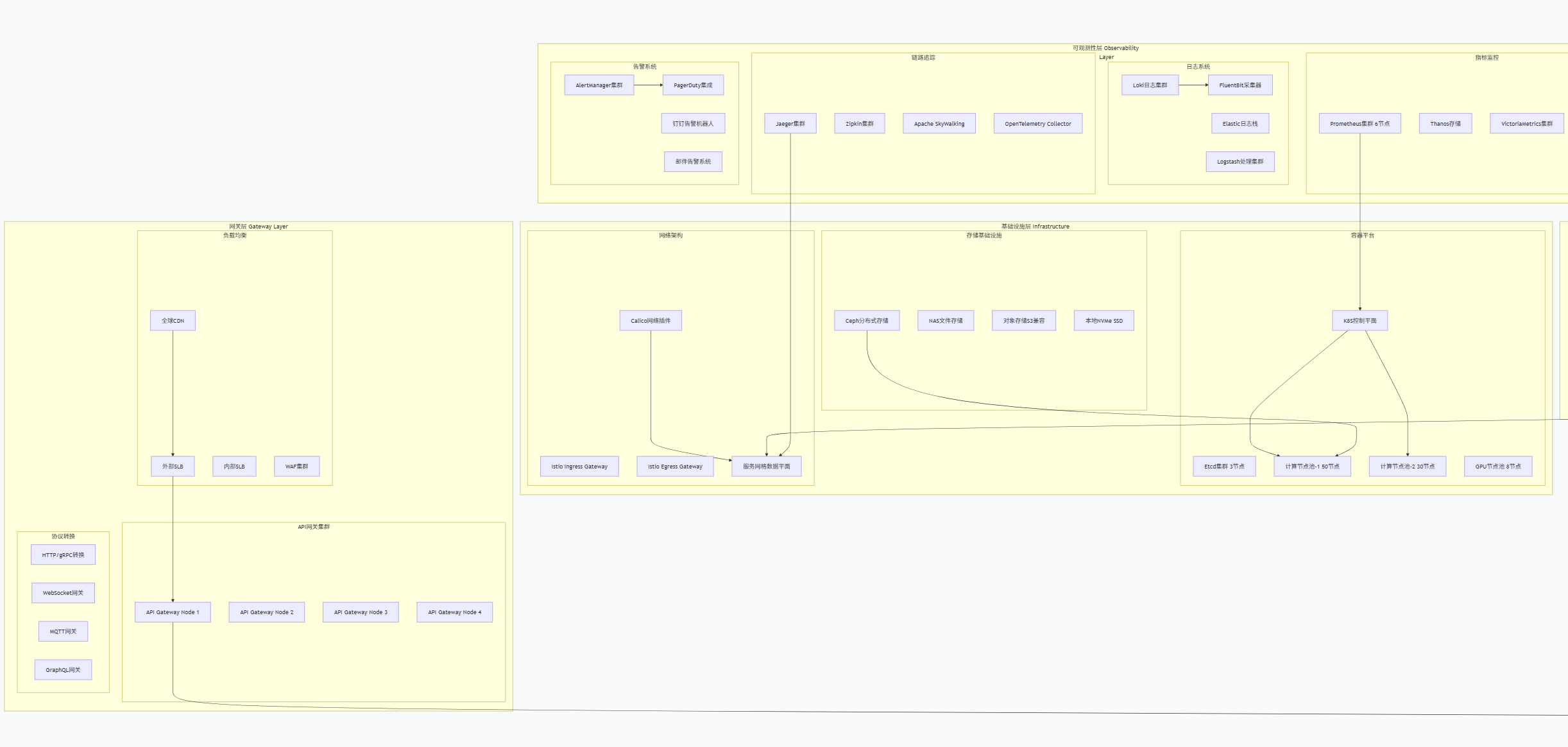
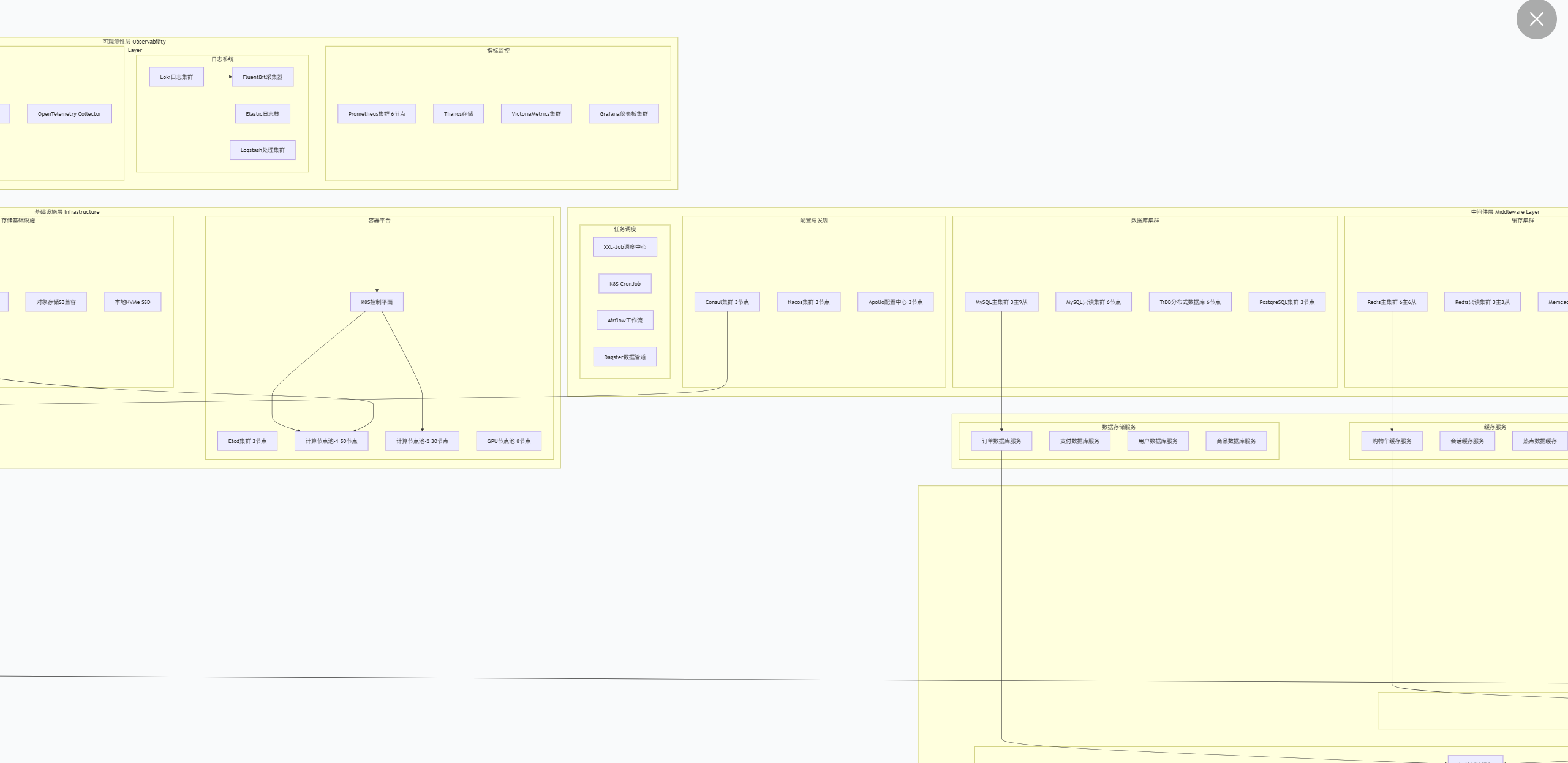
8.商品秒杀倒计时的数据存储方式,是否有做缓存,从商品架构到支付整个链路的数据流介绍,整个商城的架构情况
基本介绍缓存处理策略:
Redis集群配置
- 多级缓存:本地缓存(Caffeine) + 分布式缓存(Redis)
- 缓存穿透:布隆过滤器 + 空值缓存
- 缓存雪崩:随机过期时间 + 热点数据永不过期
- 缓存一致性:双写模式 + 失效模式 + 异步更新
适用场景介绍:
缓存击穿/雪崩:执行(大量缓存key)key失效,采取并发请求(大量请求集体)穿透数据库
并发缓存:分布式缓存、本地锁+标记位
Redis数据结构选择
- String: 简单缓存、计数器
- Hash: 对象存储、购物车
- List: 消息队列、最新列表
- Set: 标签、共同好友
- SortedSet: 排行榜、延迟队列
整个链路的数据流详情如下: