文章目录
- [一 GPTQ量化实现思路](#一 GPTQ量化实现思路)
- [二 量化校准数据集处理](#二 量化校准数据集处理)
- [三 核心量化脚本](#三 核心量化脚本)
- [四 量化模型效果综合评估](#四 量化模型效果综合评估)
-
- [4.1 all-MiniLM-L6-v2模型](#4.1 all-MiniLM-L6-v2模型)
- [4.2 分层评估架构](#4.2 分层评估架构)
- [4.3 评估代码模版](#4.3 评估代码模版)
- [五 量化模型部署](#五 量化模型部署)
一 GPTQ量化实现思路
-
数据准备 → 模型量化 → 效果评估 → 性能测试 → 部署测试。
-
校准数据的处理思路:多数据源融合,针对不同业务场景进行数据配比优化。
-
模型量化:使用GPTQ量化框架进行INT 4,量化。
-
使用三维评估框架设计:
| 维度 | 指标 | 方法 | 标准/阈值 |
|---|---|---|---|
| 输出一致性 (Consistency) | 原始模型与量化模型输出的语义相似度 (Cosine Similarity) | 使用 Sentence-Transformers 编码句子级语义向量 | >0.85 为优秀 >0.8 为可接受 |
| 稳定性 (Stability) | 同一输入多次生成的自一致性分数 | 对同一 Prompt 采样 10 次,计算响应间平均相似度 | 量化模型稳定性保持率 > 80% |
| 性能增益 (Performance) | 推理延迟 (Latency) 吞吐量 (Tokens/sec) 显存占用 | GPU 预热后精确计时,对比原始与量化模型 | INT4 量化通常实现 2-4 倍加速 |
- 使用分布式部署方式进行性能测试和使用测试。
二 量化校准数据集处理
- 基本依赖包安装:
bash
pip install gptqmodel[all] -i https://pypi.tuna.tsinghua.edu.cn/simple- 校准数据融合处理思路:
SFT
GRPO
Unknown
所有文件处理完成
开始
初始化
设置随机种子
接收输入参数
文件列表/目标样本数/比例
比例归一化
确保总和为1.0
遍历每个
输入文件
文件类型检测
内容特征识别 > 文件名识别
SFT或GRPO?
提取SFT文本
-
instruction+input → prompt
-
output → response
过滤长度<20的文本
提取GRPO文本
prompt字段
过滤长度<20的文本
跳过文件
按比例采样
随机抽取目标数量
累积到总数据集
记录来源标记
随机打乱数据集
截断至目标样本数
防止超量
保存为JSONL格式
每行一个JSON对象
包含text/source/file字段
结束
- 一个实现的通用脚本。
python
"""
量化校准数据融合工具 - 模板化使用示例
支持程序化调用和命令行使用
"""
import json
import random
import argparse
from pathlib import Path
from typing import List, Dict, Optional, Tuple
from dataclasses import dataclass
@dataclass
class FusionConfig:
"""数据融合配置类"""
input_files: List[str]
output_file: str
total_samples: int = 512
ratios: Optional[List[float]] = None
random_seed: int = 42
min_text_length: int = 20 # 最小文本长度阈值
class CalibrationDataFusion:
"""
校准数据融合核心类
支持SFT和GRPO格式数据的自动识别与融合
"""
def __init__(self, config: FusionConfig):
self.config = config
self.random_seed = config.random_seed
random.seed(self.random_seed)
def extract_sft_texts(self, file_path: str) -> List[Dict]:
"""提取SFT格式数据(instruction/input/output)"""
texts = []
with open(file_path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
try:
data = json.loads(line.strip())
# 提取prompt部分(instruction + input)
instruction = data.get('instruction', '').strip()
input_text = data.get('input', '').strip()
if instruction and input_text:
prompt = f"{instruction}\n{input_text}"
if len(prompt) > self.config.min_text_length:
texts.append({
"text": prompt,
"source": "sft_prompt",
"file": Path(file_path).name,
"line": line_num
})
# 提取response部分(output)
output = data.get('output', '').strip()
if output and len(output) > self.config.min_text_length:
texts.append({
"text": output,
"source": "sft_response",
"file": Path(file_path).name,
"line": line_num
})
except json.JSONDecodeError:
continue
except Exception as e:
print(f"警告: 处理第{line_num}行时出错: {e}")
continue
return texts
def extract_grpo_texts(self, file_path: str) -> List[Dict]:
"""提取GRPO格式数据(prompt字段)"""
texts = []
with open(file_path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
try:
data = json.loads(line.strip())
prompt = data.get('prompt', '').strip()
if prompt and len(prompt) > self.config.min_text_length:
texts.append({
"text": prompt,
"source": "grpo_prompt",
"file": Path(file_path).name,
"line": line_num
})
except json.JSONDecodeError:
continue
except Exception as e:
print(f"警告: 处理第{line_num}行时出错: {e}")
continue
return texts
def detect_file_type(self, file_path: str) -> str:
"""
智能文件类型检测
优先级:内容特征 > 文件名特征
"""
# 基于内容的检测
try:
with open(file_path, 'r', encoding='utf-8') as f:
for _ in range(10): # 检查前10行
line = f.readline()
if not line:
break
try:
data = json.loads(line.strip())
if 'instruction' in data and 'output' in data:
return 'sft'
elif 'prompt' in data and 'instruction' not in data:
return 'grpo'
except:
continue
except Exception as e:
print(f"错误: 无法读取文件 {file_path}: {e}")
return 'unknown'
# 基于文件名的检测(兜底)
file_name = Path(file_path).name.lower()
if 'sft' in file_name:
return 'sft'
elif 'grpo' in file_name or 'rl' in file_name:
return 'grpo'
return 'unknown'
def calculate_ratios(self, file_count: int) -> List[float]:
"""自动计算默认比例"""
if self.config.ratios is not None:
return self.config.ratios
if file_count == 2:
return [0.7, 0.3] # 双文件默认7:3
else:
ratio = 1.0 / file_count
return [ratio] * file_count
def normalize_ratios(self, ratios: List[float]) -> List[float]:
"""归一化比例,确保总和严格为1.0"""
total = sum(ratios)
if abs(total - 1.0) > 0.001:
return [r / total for r in ratios]
return ratios
def fuse(self) -> Dict[str, any]:
"""
执行数据融合主流程
Returns:
统计信息字典,包含各类样本数量等
"""
print(f"🚀 开始数据融合...")
print(f" 输入文件数: {len(self.config.input_files)}")
print(f" 目标样本数: {self.config.total_samples}")
print(f" 随机种子: {self.random_seed}")
# 准备比例
ratios = self.calculate_ratios(len(self.config.input_files))
ratios = self.normalize_ratios(ratios)
print(f" 采样比例: {ratios}")
all_texts = []
stats = {
"total_input_files": len(self.config.input_files),
"processed_files": 0,
"skipped_files": [],
"samples_by_source": {},
"total_extracted": 0
}
# 处理每个文件
for idx, file_path in enumerate(self.config.input_files):
file_name = Path(file_path).name
print(f"\n📄 处理文件 [{idx+1}/{len(self.config.input_files)}]: {file_name}")
# 检测类型
file_type = self.detect_file_type(file_path)
if file_type == 'unknown':
print(f" ⚠️ 跳过: 无法识别文件格式")
stats["skipped_files"].append(file_path)
continue
print(f" 检测到格式: {file_type.upper()}")
# 提取数据
if file_type == 'sft':
texts = self.extract_sft_texts(file_path)
else:
texts = self.extract_grpo_texts(file_path)
print(f" 提取样本数: {len(texts)}")
# 按比例采样
target_count = int(self.config.total_samples * ratios[idx])
if len(texts) > target_count:
selected = random.sample(texts, target_count)
print(f" 采样后: {len(selected)} (目标: {target_count})")
else:
selected = texts
if len(texts) < target_count:
print(f" ⚠️ 样本不足: 实际{len(texts)} < 目标{target_count}")
# 统计来源
for item in selected:
source = item["source"]
stats["samples_by_source"][source] = stats["samples_by_source"].get(source, 0) + 1
all_texts.extend(selected)
stats["processed_files"] += 1
# 后处理
stats["total_extracted"] = len(all_texts)
print(f"\n🔄 融合与打乱数据...")
random.shuffle(all_texts)
# 截断到目标数量
if len(all_texts) > self.config.total_samples:
all_texts = all_texts[:self.config.total_samples]
print(f" 截断至目标数量: {self.config.total_samples}")
# 保存
output_path = Path(self.config.output_file)
output_path.parent.mkdir(parents=True, exist_ok=True)
with open(output_path, 'w', encoding='utf-8') as f:
for item in all_texts:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
# 最终统计
stats["final_samples"] = len(all_texts)
stats["output_file"] = str(output_path)
print(f"\n✅ 融合完成!")
print(f" 最终样本数: {stats['final_samples']}")
print(f" 输出文件: {output_path}")
print(f"\n📊 数据来源分布:")
for source, count in stats["samples_by_source"].items():
percentage = (count / stats['final_samples']) * 100
print(f" - {source}: {count} ({percentage:.1f}%)")
return stats
def create_sample_data():
"""生成示例数据文件(用于测试)"""
# SFT格式示例
sft_data = [
{"instruction": "请解释量子计算", "input": "用简单语言说明", "output": "<think>量子计算利用量子叠加...</think>\n量子计算是一种利用量子力学原理进行计算的技术。"},
{"instruction": "翻译句子", "input": "Hello World", "output": "你好,世界"},
]
# GRPO格式示例
grpo_data = [
{"prompt": "设计一个Python函数来计算斐波那契数列", "reward": 0.9},
{"prompt": "解释为什么天空是蓝色的", "reward": 0.85},
]
# 保存示例
with open('sample_sft.jsonl', 'w', encoding='utf-8') as f:
for item in sft_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
with open('sample_grpo.jsonl', 'w', encoding='utf-8') as f:
for item in grpo_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print("已生成示例数据文件: sample_sft.jsonl, sample_grpo.jsonl")
# ==================== 使用示例 ====================
def example_basic_usage():
"""基础使用示例"""
config = FusionConfig(
input_files=["sample_sft.jsonl", "sample_grpo.jsonl"],
output_file="output/calibration_data.jsonl",
total_samples=100,
ratios=[0.6, 0.4], # 60% SFT, 40% GRPO
random_seed=42
)
fusion = CalibrationDataFusion(config)
stats = fusion.fuse()
return stats
def example_advanced_usage():
"""高级使用示例:批量处理多文件"""
# 自动比例(平均分配)
config = FusionConfig(
input_files=[
"data/train_sft_part1.jsonl",
"data/train_sft_part2.jsonl",
"data/train_grpo.jsonl"
],
output_file="output/fused_calibration.jsonl",
total_samples=1024,
ratios=None, # 自动计算为 1/3, 1/3, 1/3
random_seed=2024,
min_text_length=50 # 提高长度阈值,过滤短文本
)
fusion = CalibrationDataFusion(config)
return fusion.fuse()
def example_programmatic_access():
"""程序化调用示例:自定义处理流程"""
# 步骤1: 创建配置
config = FusionConfig(
input_files=["data/training_data.jsonl"],
output_file="output/calibration.jsonl",
total_samples=512
)
# 步骤2: 初始化融合器
fusion = CalibrationDataFusion(config)
# 步骤3: 单独使用提取功能(如需预处理)
file_type = fusion.detect_file_type("data/training_data.jsonl")
print(f"检测到类型: {file_type}")
# 步骤4: 执行完整融合
stats = fusion.fuse()
# 步骤5: 根据统计结果做后续处理
if stats["final_samples"] < config.total_samples * 0.9:
print("警告: 样本数量不足,建议检查数据源")
return stats
def main():
"""命令行入口"""
parser = argparse.ArgumentParser(
description='量化校准数据融合工具 - 支持SFT/GRPO格式',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
使用示例:
# 基础融合(自动比例7:3)
python script.py -i sft_data.jsonl grpo_data.jsonl -o output.jsonl -n 512
# 指定比例
python script.py -i data1.jsonl data2.jsonl -o out.jsonl -n 1024 -r 0.6 0.4
# 多文件平均分配
python script.py -i file1.jsonl file2.jsonl file3.jsonl -o out.jsonl -n 512
# 生成测试数据
python script.py --create-sample
"""
)
parser.add_argument('-i', '--input', nargs='+', required=True,
help='输入文件列表')
parser.add_argument('-o', '--output', required=True,
help='输出文件路径')
parser.add_argument('-n', '--samples', type=int, default=512,
help='目标样本数 (默认: 512)')
parser.add_argument('-r', '--ratios', nargs='+', type=float,
help='采样比例列表 (如: 0.7 0.3)')
parser.add_argument('-s', '--seed', type=int, default=42,
help='随机种子 (默认: 42)')
parser.add_argument('--min-length', type=int, default=20,
help='最小文本长度阈值 (默认: 20)')
parser.add_argument('--create-sample', action='store_true',
help='生成示例数据文件并退出')
args = parser.parse_args()
if args.create_sample:
create_sample_data()
return
# 验证比例数量
if args.ratios and len(args.ratios) != len(args.input):
print(f"错误: 比例数量({len(args.ratios)})必须与输入文件数量({len(args.input)})一致")
return
# 执行融合
config = FusionConfig(
input_files=args.input,
output_file=args.output,
total_samples=args.samples,
ratios=args.ratios,
random_seed=args.seed,
min_text_length=args.min_length
)
fusion = CalibrationDataFusion(config)
fusion.fuse()
if __name__ == "__main__":
# 如果没有命令行参数,运行示例
import sys
if len(sys.argv) == 1:
print("运行示例模式...")
create_sample_data()
print("\n" + "="*50)
example_basic_usage()
else:
main()三 核心量化脚本
- 核心量化处理思路
否
是
是
否
开始量化流程
初始化Quantizer
设置模型路径/校准数据路径
检查路径
是否存在?
报错并退出
量化完成
加载校准数据
解析JSONL格式
过滤短文本<10字符
校准数据
是否为空?
报错: 无有效校准数据
配置量化参数
bits=4, group_size=128
damp_percent=0.01
desc_act=false
加载AutoTokenizer
from_pretrained
加载原始模型
FP16精度
device_map=auto
trust_remote_code=True
执行GPTQ量化
model.quantize
使用校准数据统计
激活分布并转换权重
FP16→INT4
保存量化模型
mkdir创建目录
save_quantized
save_pretrained
模型大小对比
计算bin/safetensors
压缩比/节省空间
- 核心量化脚本通用代码
python
#!/usr/bin/env python3
"""
通用GPTQ模型量化工具 - 模板化实现
支持多配置预设、命令行接口、详细日志记录
"""
import torch
import json
import logging
import argparse
import time
from pathlib import Path
from dataclasses import dataclass, field
from typing import List, Optional, Dict, Tuple
from transformers import AutoTokenizer
from gptqmodel import GPTQModel, QuantizeConfig
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
@dataclass
class QuantizationConfig:
"""量化配置数据类"""
# 路径配置
model_path: str
calibration_data_path: str
output_path: str
# 量化参数
bits: int = 4 # 量化位数 (2/3/4/8)
group_size: int = 128 # 分组大小 (-1 表示 per-channel)
damp_percent: float = 0.01 # 阻尼系数 (0.01-0.1)
desc_act: bool = False # 是否启用描述符激活
static_groups: bool = False # 是否静态分组
sym: bool = True # 是否对称量化
true_sequential: bool = True # 是否顺序量化
# 数据配置
min_text_length: int = 10 # 校准数据最小长度
max_text_length: int = 2048 # 校准数据最大长度
max_calib_samples: int = 512 # 最大校准样本数
# 模型加载配置
torch_dtype: torch.dtype = field(default_factory=lambda: torch.float16)
device_map: str = "auto"
trust_remote_code: bool = True
# 预设配置名称
preset: Optional[str] = None
class GPTQQuantizer:
"""
通用GPTQ量化器
支持灵活的量化配置和完整的生命周期管理
"""
# 预设配置库
PRESETS = {
"int4_fast": {
"bits": 4,
"group_size": 128,
"desc_act": False,
"sym": True,
"damp_percent": 0.01
},
"int4_quality": {
"bits": 4,
"group_size": 64,
"desc_act": True,
"sym": False,
"damp_percent": 0.01
},
"int3_aggressive": {
"bits": 3,
"group_size": 128,
"desc_act": False,
"sym": True,
"damp_percent": 0.01
},
"int8_safe": {
"bits": 8,
"group_size": 128,
"desc_act": False,
"sym": True,
"damp_percent": 0.01
}
}
def __init__(self, config: QuantizationConfig):
self.config = self._apply_preset(config)
self.tokenizer = None
self.model = None
self.calibration_data = []
self.stats = {
"start_time": None,
"end_time": None,
"original_size_gb": 0,
"quantized_size_gb": 0,
"compression_ratio": 0
}
def _apply_preset(self, config: QuantizationConfig) -> QuantizationConfig:
"""应用预设配置"""
if config.preset and config.preset in self.PRESETS:
preset = self.PRESETS[config.preset]
for key, value in preset.items():
setattr(config, key, value)
logger.info(f"已应用预设配置: {config.preset}")
return config
def validate_paths(self) -> bool:
"""验证输入路径有效性"""
model_path = Path(self.config.model_path)
calib_path = Path(self.config.calibration_data_path)
if not model_path.exists():
logger.error(f"模型路径不存在: {model_path}")
return False
if not calib_path.exists():
logger.error(f"校准数据路径不存在: {calib_path}")
return False
return True
def load_calibration_data(self) -> List[str]:
"""
加载并预处理校准数据
支持JSON/JSONL格式自动识别
"""
logger.info(f"正在加载校准数据: {self.config.calibration_data_path}")
calib_path = Path(self.config.calibration_data_path)
texts = []
try:
with open(calib_path, 'r', encoding='utf-8') as f:
# 自动检测JSON或JSONL格式
first_line = f.readline().strip()
f.seek(0)
if first_line.startswith('['):
# JSON数组格式
data = json.load(f)
for item in data:
text = self._extract_text(item)
if text:
texts.append(text)
else:
# JSONL格式
for line_num, line in enumerate(f, 1):
try:
data = json.loads(line.strip())
text = self._extract_text(data)
if text:
texts.append(text)
except json.JSONDecodeError:
logger.warning(f"第{line_num}行JSON解析失败,已跳过")
continue
except Exception as e:
logger.error(f"加载校准数据失败: {e}")
raise
# 限制样本数量
if len(texts) > self.config.max_calib_samples:
logger.info(f"校准数据过多,随机采样至{self.config.max_calib_samples}条")
import random
random.seed(self.config.bits) # 固定位数作为种子,保证可复现
texts = random.sample(texts, self.config.max_calib_samples)
if not texts:
raise ValueError("没有加载到有效的校准数据")
self.calibration_data = texts
logger.info(f"成功加载 {len(texts)} 条校准数据")
return texts
def _extract_text(self, data: dict) -> Optional[str]:
"""从数据字典中提取有效文本"""
# 支持多种常见字段名
text_fields = ['text', 'content', 'input', 'prompt', 'instruction']
text = None
for field in text_fields:
if field in data:
text = data[field]
if isinstance(text, str):
break
if not isinstance(text, str):
return None
text = text.strip()
min_len = self.config.min_text_length
max_len = self.config.max_text_length
if len(text) < min_len:
return None
if len(text) > max_len:
text = text[:max_len]
return text
def setup_quantize_config(self) -> QuantizeConfig:
"""创建量化配置对象"""
logger.info("配置量化参数...")
logger.info(f" 量化位数: {self.config.bits}-bit")
logger.info(f" 分组大小: {self.config.group_size}")
logger.info(f" 阻尼系数: {self.config.damp_percent}")
logger.info(f" 描述符激活: {self.config.desc_act}")
return QuantizeConfig(
bits=self.config.bits,
group_size=self.config.group_size,
damp_percent=self.config.damp_percent,
desc_act=self.config.desc_act,
static_groups=self.config.static_groups,
sym=self.config.sym,
true_sequential=self.config.true_sequential,
)
def load_model(self, quantize_config: QuantizeConfig):
"""加载模型和分词器"""
logger.info(f"加载模型: {self.config.model_path}")
# 加载分词器
self.tokenizer = AutoTokenizer.from_pretrained(
self.config.model_path,
trust_remote_code=self.config.trust_remote_code
)
# 设置padding token(如果不存在)
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
# 加载模型
self.model = GPTQModel.from_pretrained(
self.config.model_path,
quantize_config=quantize_config,
torch_dtype=self.config.torch_dtype,
device_map=self.config.device_map,
trust_remote_code=self.config.trust_remote_code,
)
logger.info("模型加载完成")
def quantize(self):
"""执行量化"""
logger.info("开始量化计算...")
self.stats["start_time"] = time.time()
try:
self.model.quantize(self.calibration_data)
self.stats["end_time"] = time.time()
duration = self.stats["end_time"] - self.stats["start_time"]
logger.info(f"量化完成,耗时: {duration:.2f}秒")
except Exception as e:
logger.error(f"量化过程出错: {e}")
raise
def save_model(self):
"""保存量化后的模型"""
output_path = Path(self.config.output_path)
output_path.mkdir(parents=True, exist_ok=True)
logger.info(f"保存量化模型至: {output_path}")
# 保存模型权重
self.model.save_quantized(str(output_path))
# 保存分词器
self.tokenizer.save_pretrained(str(output_path))
# 保存量化配置信息(便于后续追踪)
config_info = {
"quantization_config": {
"bits": self.config.bits,
"group_size": self.config.group_size,
"desc_act": self.config.desc_act,
"sym": self.config.sym,
"damp_percent": self.config.damp_percent,
},
"calibration_samples": len(self.calibration_data),
"original_model_path": str(self.config.model_path),
"quantization_time_sec": self.stats["end_time"] - self.stats["start_time"]
if self.stats["end_time"] else None
}
with open(output_path / "quant_config.json", "w", encoding="utf-8") as f:
json.dump(config_info, f, indent=2, ensure_ascii=False)
logger.info("模型保存完成")
def analyze_compression(self):
"""分析模型压缩效果"""
def get_dir_size(path: Path) -> Tuple[int, int, int]:
"""返回总字节数、bin文件数、safetensors文件数"""
total = 0
bin_count = 0
st_count = 0
for f in path.rglob("*"):
if f.is_file():
if f.suffix == ".bin":
bin_count += 1
total += f.stat().st_size
elif f.suffix == ".safetensors":
st_count += 1
total += f.stat().st_size
return total, bin_count, st_count
try:
orig_path = Path(self.config.model_path)
quant_path = Path(self.config.output_path)
orig_size, orig_bins, orig_st = get_dir_size(orig_path)
quant_size, quant_bins, quant_st = get_dir_size(quant_path)
if orig_size == 0 or quant_size == 0:
logger.warning("无法计算模型大小(可能文件格式不支持)")
return
orig_gb = orig_size / (1024**3)
quant_gb = quant_size / (1024**3)
ratio = orig_size / quant_size
saved = orig_gb - quant_gb
self.stats["original_size_gb"] = orig_gb
self.stats["quantized_size_gb"] = quant_gb
self.stats["compression_ratio"] = ratio
logger.info("=" * 50)
logger.info("模型压缩分析:")
logger.info(f" 原始模型: {orig_gb:.2f} GB ({orig_bins} .bin, {orig_st} .safetensors)")
logger.info(f" 量化模型: {quant_gb:.2f} GB ({quant_bins} .bin, {quant_st} .safetensors)")
logger.info(f" 压缩比率: {ratio:.2f}x")
logger.info(f" 节省空间: {saved:.2f} GB ({(saved/orig_gb)*100:.1f}%)")
logger.info("=" * 50)
except Exception as e:
logger.error(f"分析模型大小时出错: {e}")
def run(self):
"""执行完整的量化流程"""
logger.info("🚀 启动模型量化流程")
# 1. 验证路径
if not self.validate_paths():
return False
try:
# 2. 加载校准数据
self.load_calibration_data()
# 3. 设置量化配置
quant_config = self.setup_quantize_config()
# 4. 加载模型
self.load_model(quant_config)
# 5. 执行量化
self.quantize()
# 6. 保存模型
self.save_model()
# 7. 分析压缩效果
self.analyze_compression()
logger.info("✅ 量化流程全部完成")
return True
except Exception as e:
logger.error(f"❌ 量化流程失败: {e}")
return False
def create_sample_calibration_data(output_path: str = "calibration_data.jsonl"):
"""生成示例校准数据"""
samples = [
{"text": "人工智能在金融领域的应用包括风险评估、算法交易和客户服务自动化。"},
{"text": "深度学习模型通过多层神经网络提取数据特征,广泛应用于图像识别和自然语言处理。"},
{"text": "量化交易利用数学模型和计算机程序自动执行交易策略,提高交易效率。"},
{"text": "机器学习算法可以从历史数据中学习模式,用于预测股票价格和信用评分。"},
{"text": "自然语言处理技术使计算机能够理解和生成人类语言,应用于聊天机器人和文本分析。"}
]
with open(output_path, 'w', encoding='utf-8') as f:
for item in samples:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
logger.info(f"已生成示例校准数据: {output_path}")
def main():
"""命令行入口"""
parser = argparse.ArgumentParser(
description="GPTQ模型量化工具",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
使用示例:
# 使用预设配置快速量化
python quantize.py -m /path/to/model -c calib.jsonl -o output/ --preset int4_fast
# 自定义量化参数
python quantize.py -m /path/to/model -c calib.jsonl -o output/ --bits 4 --group-size 64
# 生成示例校准数据
python quantize.py --create-sample
"""
)
# 路径参数
parser.add_argument("-m", "--model", help="原始模型路径")
parser.add_argument("-c", "--calibration", help="校准数据路径(JSONL格式)")
parser.add_argument("-o", "--output", help="输出路径")
# 预设配置
parser.add_argument("--preset", choices=list(GPTQQuantizer.PRESETS.keys()),
help="使用预设配置")
# 量化参数
parser.add_argument("--bits", type=int, choices=[2, 3, 4, 8], default=4,
help="量化位数(默认: 4)")
parser.add_argument("--group-size", type=int, default=128,
help="分组大小(默认: 128, -1表示per-channel)")
parser.add_argument("--desc-act", action="store_true",
help="启用描述符激活(提高精度,降低速度)")
parser.add_argument("--no-sym", action="store_true",
help="使用非对称量化")
# 数据参数
parser.add_argument("--max-calib-samples", type=int, default=512,
help="最大校准样本数(默认: 512)")
parser.add_argument("--min-text-length", type=int, default=10,
help="最小文本长度(默认: 10)")
# 其他
parser.add_argument("--create-sample", action="store_true",
help="生成示例校准数据并退出")
args = parser.parse_args()
if args.create_sample:
create_sample_calibration_data()
return
if not all([args.model, args.calibration, args.output]):
parser.error("必须提供 --model, --calibration 和 --output 参数")
# 构建配置
config = QuantizationConfig(
model_path=args.model,
calibration_data_path=args.calibration,
output_path=args.output,
preset=args.preset,
bits=args.bits,
group_size=args.group_size,
desc_act=args.desc_act,
sym=not args.no_sym,
max_calib_samples=args.max_calib_samples,
min_text_length=args.min_text_length
)
# 执行量化
quantizer = GPTQQuantizer(config)
success = quantizer.run()
exit(0 if success else 1)
if __name__ == "__main__":
main()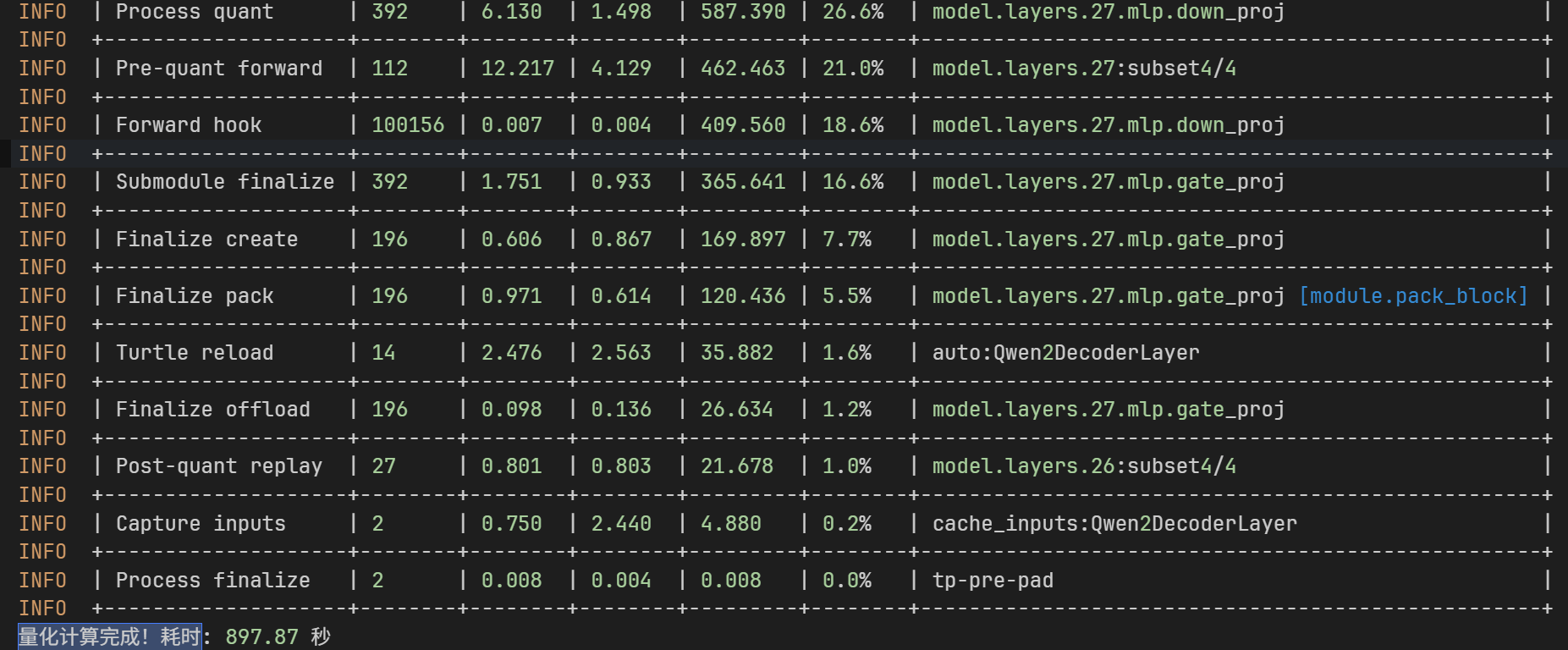
- 日志字段含义
| layer | module | loss | samples | damp | time |
|---|---|---|---|---|---|
| 0 | self_attn.v_proj | 0.0000001123 | 0.01000 | - | 3.466 |
| 0 | self_attn.k_proj | 0.0000005868 | 0.01000 | - | 3.497 |
| 0 | self_attn.q_proj | 0.0000025209 | 0.01000 | - | 3.531 |
| 0 | self_attn.o_proj | 0.0000029000 | 0.01000 | - | 0.894 |
| 0 | mlp.gate_proj | 0.0000060188 | 0.01000 | - | 2.130 |
| 0 | mlp.up_proj | 0.0000036735 | 0.01000 | - | 2.162 |
| 0 | mlp.down_proj | 0.0000025184 | 0.01000 | - | 5.998 |
- module 字段详细分类
| module 值 | 所属组件 | 功能描述 |
|---|---|---|
self_attn.k_proj |
Attention | Key 投影层(将隐藏状态映射为 Key 向量) |
self_attn.v_proj |
Attention | Value 投影层(将隐藏状态映射为 Value 向量) |
self_attn.q_proj |
Attention | Query 投影层(将隐藏状态映射为 Query 向量) |
self_attn.o_proj |
Attention | Output 投影层(注意力输出线性变换) |
mlp.up_proj |
MLP | 上投影层(升维扩展) |
mlp.gate_proj |
MLP | 门控投影层(Gated MLP 的门控控制) |
mlp.down_proj |
MLP | 下投影层(降维压缩) |
- 层级结构
bash
layer (0-27)
├── self_attn (自注意力层)
│ ├── q_proj (Query 投影)
│ ├── k_proj (Key 投影)
│ ├── v_proj (Value 投影)
│ └── o_proj (输出投影)
└── mlp (前馈网络层)
├── gate_proj (门控)
├── up_proj (上采样)
└── down_proj (下采样)四 量化模型效果综合评估
- 主要从三个维度评估模型:语义相似度评估(比较量化模型答案与原始模型答案的相似度)、输出稳定性评估(多次同一问题的回答输出相似度)、推理性能评估(原始模型与量化模型的回答耗时比较)。
4.1 all-MiniLM-L6-v2模型
all-MiniLM-L6-v2是由 sentence-transformers 开发的轻量级句子嵌入模型,基于微软的 MiniLM 架构,通过知识蒸馏从更大的模型(如 BERT)压缩而来,专为高效语义理解和快速推理设计。sentence-transformers库的默认推荐模型,在保持较小体积的同时提供了优秀的语义理解能力,特别适合资源受限的生产环境 。
| 属性 | 详细信息 |
|---|---|
| 模型全称 | sentence-transformers/all-MiniLM-L6-v2 |
| 基础架构 | MiniLM (Mini Language Model) |
| Transformer 层数 | 6 层 (L6 = Layers 6) |
| 隐藏层维度 | 384 (H384) |
| 输出维度 | 384 维密集向量 |
| 参数量 | 22.7M (约 2270 万) |
| 模型大小 | 约 80-90 MB |
| 最大序列长度 | 256 word pieces |
| 许可证 | Apache 2.0 |
| 训练数据 | 超过 10 亿句子对 (S2ORC、MS MARCO、StackExchange、WikiAnswers 等 21+ 数据集) |
| 训练目标 | 对比学习 (Contrastive Learning) |
| 支持语言 | 英语为主,支持 50+ 种语言(多语言版本另有 paraphrase-multilingual-MiniLM-L12-v2) |
| 支持的框架 | PyTorch、TensorFlow、ONNX、Rust |
- 性能特点
| 特性 | 表现 |
|---|---|
| 推理速度 | CPU 上约 14,000 句子/秒 (批处理) |
| 语义相似度 (STS-B) | 84-85% |
| 内存占用 | 低 (适合边缘设备) |
| GPU 显存需求 | 约 2GB |
- 适用场景:语义搜索与信息检索
- 文本聚类与分类
- 重复数据检测
- RAG (检索增强生成) 系统的嵌入层
- 实时推荐系统
4.2 分层评估架构
📈 结果层
🔍 三维评估引擎
📊 数据层
🤖 模型层
📋 配置层
初始化
load_models
load_models
init
load_test_data
evaluate_output_consistency
evaluate_stability
evaluate_performance
统计聚合
统计聚合
统计聚合
_generate_report
_save_results
决策逻辑
一致性>0.85
稳定性>0.8
加速>1.5x
任一指标不足
EvaluationConfig
模型路径/评估参数
随机种子/硬件配置
原始模型加载
AutoModelForCausalLM
bfloat16精度
device_map自动分配
量化模型加载
GPTQModel.from_quantized
Int4权重量化
显存优化
语义编码器
SentenceTransformer
all-MiniLM-L6-v2
相似度计算
测试数据加载
JSONL格式过滤
随机采样
质量校验
输出一致性评估
语义相似度对比
原始vs量化输出
余弦相似度矩阵
稳定性评估
自一致性测试
多次生成方差
稳定性保持率计算
性能评估
GPU精确计时
torch.cuda.synchronize
预热-测试-清理
加速比分析
统计分析
均值/分位数/标准差
置信度计算
评估报告
一致性/稳定性/性能
综合评分
部署建议
持久化存储
JSON详细结果
Markdown报告
FinancialModelEvaluator
主控调度器
量化质量
是否达标?
✅ 建议生产部署
⚠️ 建议参数调优
4.3 评估代码模版
bash
pip install sentence-transformers scikit-learn gptqmodel -i https://pypi.tuna.tsinghua.edu.cn/simple
python
#!/usr/bin/env python3
"""
模型量化效果评估模板 (Model Quantization Evaluation Template)
使用方法:
1. 配置模型路径和评估参数
2. 继承基础类或直接使用FinancialModelEvaluator
3. 运行run_complete_evaluation()获取完整报告
"""
import json
import time
import random
from dataclasses import dataclass
from pathlib import Path
from typing import List, Dict, Optional
import logging
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# 根据实际量化方式选择导入
# from gptqmodel import GPTQModel # GPTQ方案
# from awq import AutoAWQForCausalLM # AWQ方案
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
@dataclass
class QuantizationEvalConfig:
"""量化评估配置模板"""
# 模型配置
original_model_path: str = "path/to/original/model"
quantized_model_path: str = "path/to/quantized/model"
# 数据配置
test_data_path: str = "path/to/test/data.jsonl"
output_dir: str = "./eval_results"
# 评估参数
num_test_samples: int = 20 # 一致性测试样本数
num_consistency_trials: int = 5 # 稳定性测试重复次数
max_new_tokens: int = 512
temperature: float = 0.7
random_seed: int = 42
# 硬件参数
device_map: str = "auto"
torch_dtype: torch.dtype = torch.bfloat16
class ModelQuantizationEvaluator:
"""
通用量化模型评估器
支持评估维度:
1. Output Consistency: 输出语义一致性 (余弦相似度)
2. Stability: 生成稳定性 (多次采样方差)
3. Performance: 推理性能对比 (延迟与吞吐量)
"""
def __init__(self, config: QuantizationEvalConfig):
self.config = config
self.device = "cuda" if torch.cuda.is_available() else "cpu"
# 初始化语义模型
self.similarity_model = SentenceTransformer('all-MiniLM-L6-v2')
# 模型占位符
self.orig_model = None
self.quant_model = None
self.orig_tokenizer = None
self.quant_tokenizer = None
# 设置随机种子
self._set_seed(config.random_seed)
# 创建输出目录
Path(config.output_dir).mkdir(parents=True, exist_ok=True)
def _set_seed(self, seed: int):
"""设置全局随机种子保证可复现"""
random.seed(seed)
torch.manual_seed(seed)
np.random.seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
def load_models(self):
"""加载原始模型和量化模型 - 需根据实际量化框架调整"""
logger.info("Loading models...")
# 加载原始模型 (FP16/BF16)
logger.info(f"Loading original model from {self.config.original_model_path}")
self.orig_tokenizer = AutoTokenizer.from_pretrained(
self.config.original_model_path,
trust_remote_code=True
)
self.orig_model = AutoModelForCausalLM.from_pretrained(
self.config.original_model_path,
device_map=self.config.device_map,
torch_dtype=self.config.torch_dtype,
trust_remote_code=True
)
# 清理显存
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 加载量化模型 (示例为GPTQ,可按需替换为AWQ/BitsAndBytes等)
logger.info(f"Loading quantized model from {self.config.quantized_model_path}")
self.quant_tokenizer = AutoTokenizer.from_pretrained(
self.config.quantized_model_path,
trust_remote_code=True
)
# TODO: 根据实际量化方案替换此处
# self.quant_model = GPTQModel.from_quantized(...)
# 或者通用加载方式:
self.quant_model = AutoModelForCausalLM.from_pretrained(
self.config.quantized_model_path,
device_map=self.config.device_map,
trust_remote_code=True
)
logger.info("Models loaded successfully")
def generate(self, model, tokenizer, prompt: str) -> str:
"""标准化生成方法"""
inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=2048)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=self.config.max_new_tokens,
temperature=self.config.temperature,
do_sample=True,
top_p=0.9,
repetition_penalty=1.1,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response[len(prompt):].strip()
def calc_similarity(self, text1: str, text2: str) -> float:
"""计算语义相似度"""
try:
emb1 = self.similarity_model.encode([text1])
emb2 = self.similarity_model.encode([text2])
return float(cosine_similarity(emb1, emb2)[0][0])
except Exception as e:
logger.warning(f"Similarity calculation failed: {e}")
return 0.0
def evaluate_consistency(self, prompts: List[str]) -> Dict:
"""
评估输出一致性
Returns:
Dict包含: mean_similarity, std_similarity, min_similarity, 详细对比结果
"""
logger.info("=== Evaluating Output Consistency ===")
similarities = []
details = []
for i, prompt in enumerate(prompts):
logger.info(f"Processing sample {i+1}/{len(prompts)}")
try:
# 双模型推理
orig_out = self.generate(self.orig_model, self.orig_tokenizer, prompt)
quant_out = self.generate(self.quant_model, self.quant_tokenizer, prompt)
# 计算相似度
sim = self.calc_similarity(orig_out, quant_out)
similarities.append(sim)
details.append({
"prompt": prompt[:100] + "...",
"original": orig_out[:200] + "...",
"quantized": quant_out[:200] + "...",
"similarity": sim
})
except Exception as e:
logger.error(f"Error processing sample {i+1}: {e}")
continue
return {
"mean_similarity": np.mean(similarities),
"std_similarity": np.std(similarities),
"min_similarity": np.min(similarities),
"max_similarity": np.max(similarities),
"percentiles": {
"p25": np.percentile(similarities, 25),
"p50": np.percentile(similarities, 50),
"p90": np.percentile(similarities, 90)
},
"samples": len(similarities),
"details": details
}
def evaluate_stability(self, prompts: List[str]) -> Dict:
"""
评估生成稳定性 (自一致性)
通过多次采样同一prompt,计算生成结果的内部一致性
"""
logger.info("=== Evaluating Stability ===")
test_prompts = random.sample(prompts, min(5, len(prompts)))
orig_stability = []
quant_stability = []
for prompt in test_prompts:
# 原始模型稳定性
orig_responses = [self.generate(self.orig_model, self.orig_tokenizer, prompt)
for _ in range(self.config.num_consistency_trials)]
orig_stability.append(self._self_consistency_score(orig_responses))
# 量化模型稳定性
quant_responses = [self.generate(self.quant_model, self.quant_tokenizer, prompt)
for _ in range(self.config.num_consistency_trials)]
quant_stability.append(self._self_consistency_score(quant_responses))
return {
"original_stability": {
"mean": np.mean(orig_stability),
"std": np.std(orig_stability)
},
"quantized_stability": {
"mean": np.mean(quant_stability),
"std": np.std(quant_stability)
},
"stability_retention": np.mean(quant_stability) / np.mean(orig_stability)
}
def _self_consistency_score(self, responses: List[str]) -> float:
"""计算一组响应的自一致性 (两两相似度均值)"""
if len(responses) < 2:
return 1.0
sims = []
for i in range(len(responses)):
for j in range(i+1, len(responses)):
sims.append(self.calc_similarity(responses[i], responses[j]))
return np.mean(sims)
def evaluate_performance(self, prompts: List[str], warmup: int = 3) -> Dict:
"""
评估推理性能
使用GPU同步确保计时准确,包含预热阶段
"""
logger.info("=== Evaluating Performance ===")
test_prompts = random.sample(prompts, min(10, len(prompts)))
def benchmark(model, tokenizer, name):
times = []
for i, prompt in enumerate(test_prompts):
# 预热
if i == 0:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
for _ in range(warmup):
with torch.no_grad():
model.generate(**inputs, max_new_tokens=50)
if torch.cuda.is_available():
torch.cuda.synchronize()
# 正式计时
start = time.time()
self.generate(model, tokenizer, prompt)
if torch.cuda.is_available():
torch.cuda.synchronize()
times.append(time.time() - start)
return {
"mean_latency": np.mean(times),
"std_latency": np.std(times),
"p90_latency": np.percentile(times, 90),
"throughput": len(test_prompts) / sum(times) # samples/sec
}
orig_perf = benchmark(self.orig_model, self.orig_tokenizer, "Original")
if torch.cuda.is_available():
torch.cuda.empty_cache()
quant_perf = benchmark(self.quant_model, self.quant_tokenizer, "Quantized")
return {
"original": orig_perf,
"quantized": quant_perf,
"speedup": orig_perf["mean_latency"] / quant_perf["mean_latency"],
"latency_reduction": (1 - quant_perf["mean_latency"]/orig_perf["mean_latency"]) * 100
}
def generate_report(self, consistency: Dict, stability: Dict, performance: Dict) -> str:
"""生成人类可读的评估报告"""
report = f"""
=== Model Quantization Evaluation Report ===
1. OUTPUT CONSISTENCY
- Mean Similarity: {consistency['mean_similarity']:.3f}
- Std Deviation: {consistency['std_similarity']:.3f}
- 90th Percentile: {consistency['percentiles']['p90']:.3f}
- Status: {"✅ PASS" if consistency['mean_similarity'] > 0.85 else "⚠️ NEEDS IMPROVEMENT"}
2. STABILITY RETENTION
- Original Model: {stability['original_stability']['mean']:.3f}
- Quantized Model: {stability['quantized_stability']['mean']:.3f}
- Retention Rate: {stability['stability_retention']:.2%}
- Status: {"✅ PASS" if stability['stability_retention'] > 0.8 else "⚠️ NEEDS IMPROVEMENT"}
3. PERFORMANCE GAIN
- Speedup: {performance['speedup']:.2f}x
- Latency Reduction: {performance['latency_reduction']:.1f}%
- Status: {"✅ EXCELLENT" if performance['speedup'] > 2 else "✅ GOOD" if performance['speedup'] > 1.5 else "⚠️ MARGINAL"}
4. DEPLOYMENT RECOMMENDATION
"""
# 综合决策逻辑
checks = [
consistency['mean_similarity'] > 0.85,
stability['stability_retention'] > 0.8,
performance['speedup'] > 1.5
]
if all(checks):
report += " 🟢 RECOMMENDED: Quantization quality meets production standards.\n"
elif sum(checks) >= 2:
report += " 🟡 CONDITIONAL: Acceptable for deployment with monitoring.\n"
else:
report += " 🔴 NOT RECOMMENDED: Consider adjusting quantization parameters.\n"
return report
def run_evaluation(self) -> Dict:
"""执行完整评估流程"""
# 1. 加载资源
self.load_models()
# 加载测试数据 (简单示例,实际应从文件加载)
test_prompts = [
"Explain the concept of machine learning in simple terms.",
"What are the benefits of quantization in deep learning?",
"Write a short poem about artificial intelligence.",
# 添加更多测试样本...
][:self.config.num_test_samples]
# 2. 执行三项评估
consistency = self.evaluate_consistency(test_prompts)
stability = self.evaluate_stability(test_prompts)
performance = self.evaluate_performance(test_prompts)
# 3. 生成报告
report = self.generate_report(consistency, stability, performance)
print(report)
# 4. 保存结果
results = {
"config": {
"original_model": self.config.original_model_path,
"quantized_model": self.config.quantized_model_path,
"num_samples": len(test_prompts)
},
"consistency": consistency,
"stability": stability,
"performance": performance,
"report": report
}
output_file = Path(self.config.output_dir) / "quantization_eval_results.json"
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
logger.info(f"Results saved to {output_file}")
return results
def main():
"""使用示例"""
config = QuantizationEvalConfig(
original_model_path="/path/to/your/original/model",
quantized_model_path="/path/to/your/quantized/model",
test_data_path="/path/to/test/data.jsonl",
num_test_samples=10,
output_dir="./evaluation_results"
)
evaluator = ModelQuantizationEvaluator(config)
results = evaluator.run_evaluation()
# 程序性决策示例
if (results['consistency']['mean_similarity'] > 0.85 and
results['performance']['speedup'] > 1.5):
print("🎉 Quantization validation successful! Ready for deployment.")
else:
print("⚠️ Quantization did not meet criteria. Please review parameters.")
if __name__ == "__main__":
main()五 量化模型部署
bash
pip install vllm ray[default,serve] -i https://pypi.tuna.tsinghua.edu.cn/simple
bash
#!/bin/bash
# 基本配置参数
HEAD_NODE="xxx"
MODEL_PATH="xxx"
PORT=8000
# 激活conda环境
source ~/miniconda3/etc/profile.d/conda.sh
conda activate [env_name]
# 设置分布式训练环境变量
export MASTER_ADDR=$HEAD_NODE
export MASTER_PORT=29500
export GLOO_SOCKET_IFNAME=eth0
export NCCL_SOCKET_IFNAME=eth0
# 停止现有的Ray进程
ray stop --force 2>/dev/null || true # --force强制停止,2>/dev/null忽略错误输出
# 启动Ray头节点
ray start --head \
--port=6379 \
--dashboard-host=0.0.0.0 \
--dashboard-port=8265 \
--num-gpus=1 \
--num-cpus=24
echo "启动vLLM单机服务器..."
# 启动vLLM API服务器
python -m vllm.entrypoints.openai.api_server \
--model $MODEL_PATH \
--host 0.0.0.0 \
--port $PORT \
--tensor-parallel-size 1 \
--dtype bfloat16 \
--max-model-len 8192 \
--gpu-memory-utilization 0.95 \
--disable-log-requests \
--api-key gptq-model-key \
--distributed-executor-backend ray