目录
[mode参数--创建文件的权限(仅 O_CREAT 时有效)](#mode参数--创建文件的权限(仅 O_CREAT 时有效))
[Linux dup2调度函数](#Linux dup2调度函数)
一、文件
从底层角度来看,文件是存储在磁盘中的电子信号,磁盘属于外设需要通过IO来完成文件的各项操作。从Linux操作系统角度来看一切皆文件,且对文件的操作都是通过进程来完成的。
文件可主要分为属性+内容两部分,我们对文件的管理也主要围绕这两部分。
打开文件,fopen函数

fopen函数的头文件是 stdio.h ,其能以指定模式(mod)打开指定文件(filename),filename需要提供文件的路径,mod则是确定文件的打开方式。FILE是一种特殊的类型,这个稍微后面讲。
常见的模式: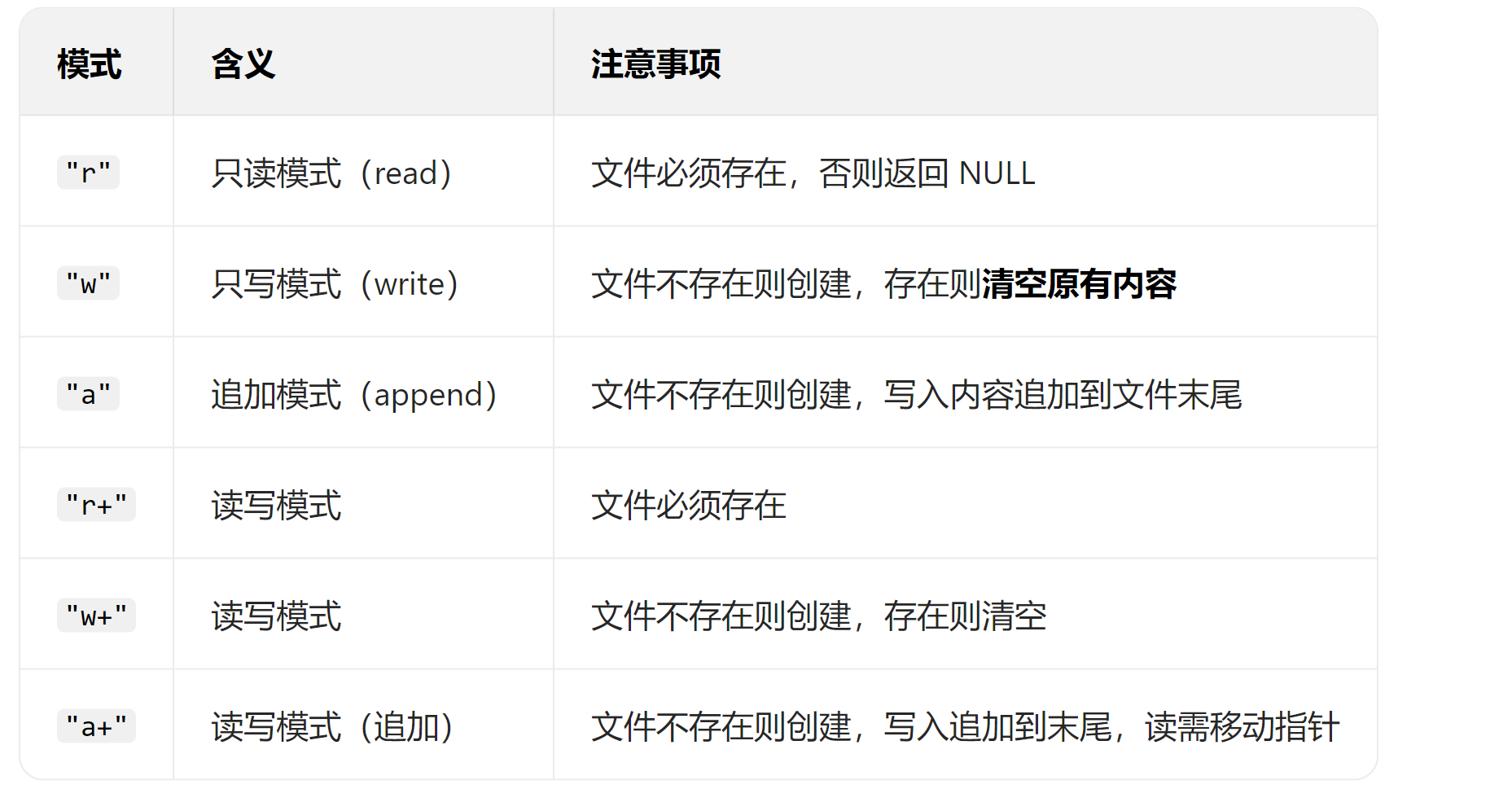
需要补充的是,上述模式都是权限声明+初始化。权限声明为向操作系统提前打好招呼说明该操作具备读/写的权限方便后续操作,也就是说具体的读/写还需要额外的操作来实现。初始化则为开始时对文件的各项初始化措施,例如清空文件或者是创建文件等等。
r模式
r,也就是read读的意思,该模式下开放文件r权限,在该模式下需要保证对应文件必须存在。
FILE* f=fopen("file.txt","r");
if(f==NULL)
{
exit(1);
}w模式
w模式下文件具备w权限,可被写入。须注意的是如果文件不存在就创建,如果存在则先清空再写入。
FILE* f=fopen("file.txt","w");
14 if(f==NULL)
15 {
16 exit(1);
17 }
18 else
19 {
20 const char* c="aabbc";
21 fputs(c,f);
22 fclose(f);
23 }a模式
a模式是追加模式,与w模式相比a模式下如果文件存在则不会清空文件内容而是在文件末尾追加数据。
一些疑问:
按照常识我们要操作一个文件就得先获得文件的路径,为什么上面的fopen函数只写文件名就可以呢,那是因为在没有用户提供路径的情况下会使用进程中保存的路径。
进程与文件的关系:
进程从不直接操作磁盘上的物理文件,所有文件操作都必须通过操作系统作为中介,且数据必须经过内存中转。
操作系统可以同时打开多个文件,进程。既然能同时打开多个,那必然意味着操作系统需管理好打开的文件。 Linux也确实安排有专门的数据结构来管理文件,那就是file结构体。C语言在系统级的file结构体基础上封装得到FILE C语言级的结构体用于专门管理文件。
这样一来C语言无法直接使用系统级的file,而需要通过文件标识符fd 来作为桥梁,体现了语言的跨平台性(上层不变,但能适配不同平台的系统接口)。
open函数
fopen是C语言封装的函数,而open则是Linux下的系统调用函数,头文件为<fcntl.h>。
#include <fcntl.h>
#include <unistd.h>
// 1. 仅打开已有文件(无需创建)
int open(const char *pathname, int flags);
// 2. 打开或创建文件(需指定新文件的权限)
int open(const char *pathname, int flags, mode_t mode);pathname支持绝对路径和相对路径(可从进程中获取当前路径),flags是打开标志,mode是创建文件的权限。
常见的打开标志
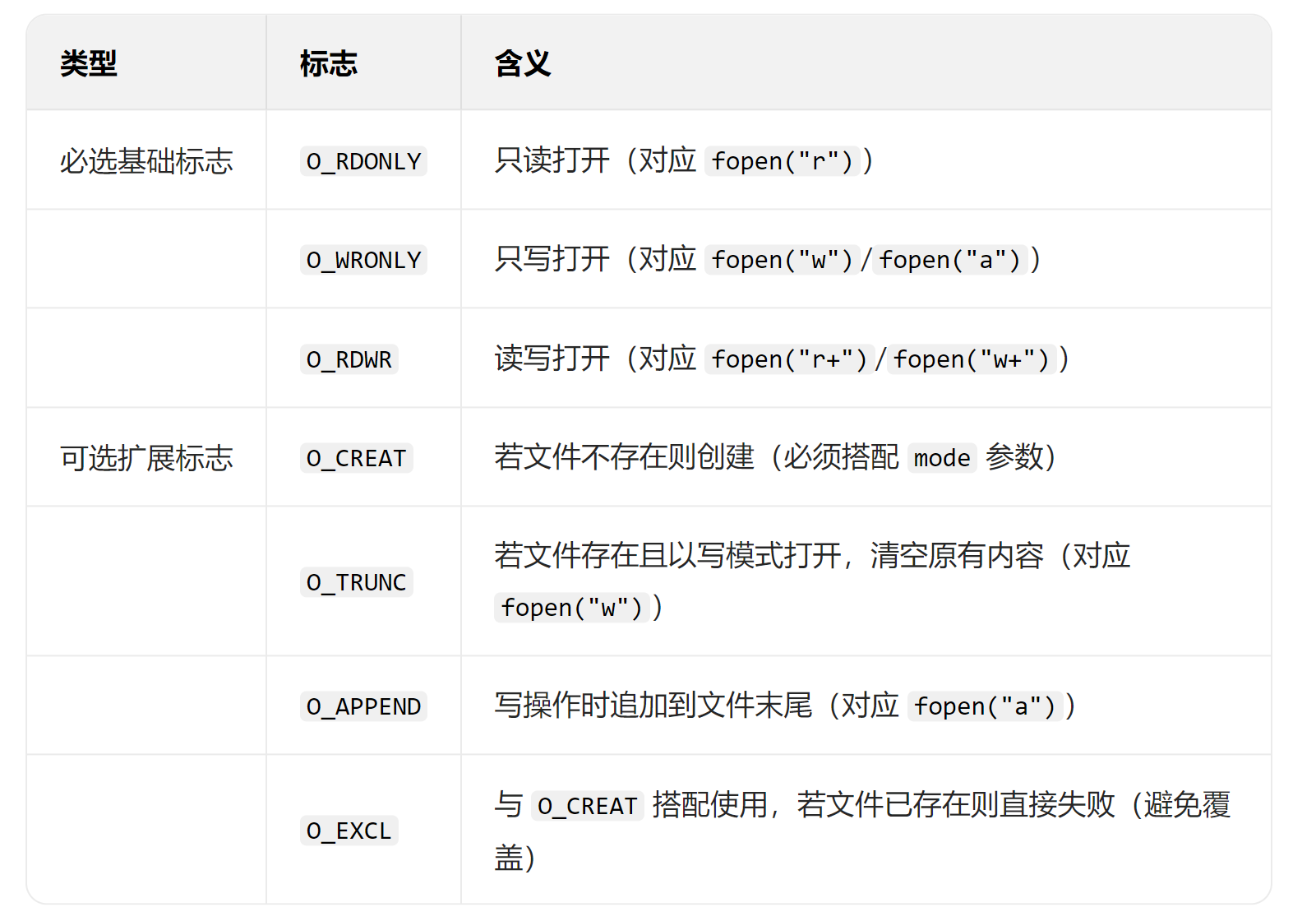
多个标志符是可以使用的,标识符之间以 | 为间隔符。
mode参数--创建文件的权限(仅 O_CREAT 时有效)
mode的参数为无符号整型,必须用八进制数(以0开头,如0664)
实际生效权限 = mode & (~umask):系统默认 umask(通常为 0022)会屏蔽部分权限,例如 0644 & ~0022 = 0644,0777 & ~0022 = 0755。这么干的原因是为了给系统层面的权限安全兜底,防止出现越权操作。
当掩码为0022时,打开的文件的组成员(g)和其它用户(o)的写(w)权限是一定不会出现的。
返回值
open函数成功执行时返回打开文件的文件标识符(fd),失败返回-1。
文件标识符fd
文件描述符(fd)是 Linux 内核分配给进程的非负整数 (本质是进程 "文件描述符表" 的下标),是进程访问内核中 file 结构体的唯一 "合法凭证"------ 进程无法直接操作内核的 file 结构体,只能通过这个整数 "编号",告诉内核 "我要操作哪个打开的文件"。
再准确点说,PCB--task_struct结构体中存在着file指针指向文件管理结构体,file指针指向files_sruct结构体,files_struct结构体中存放着fd_array结构体指针指向更具体的文件结构体,这个下标也就是fd。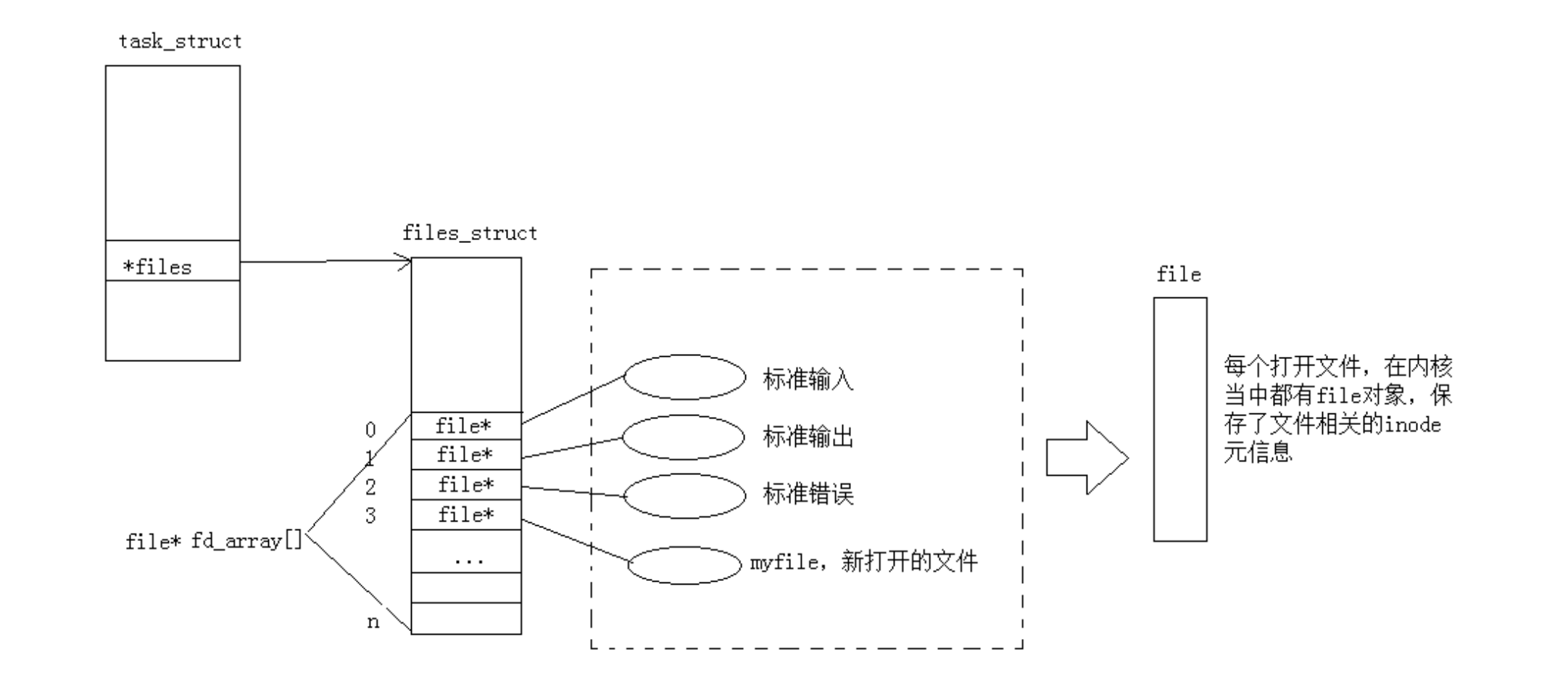
常见fd值
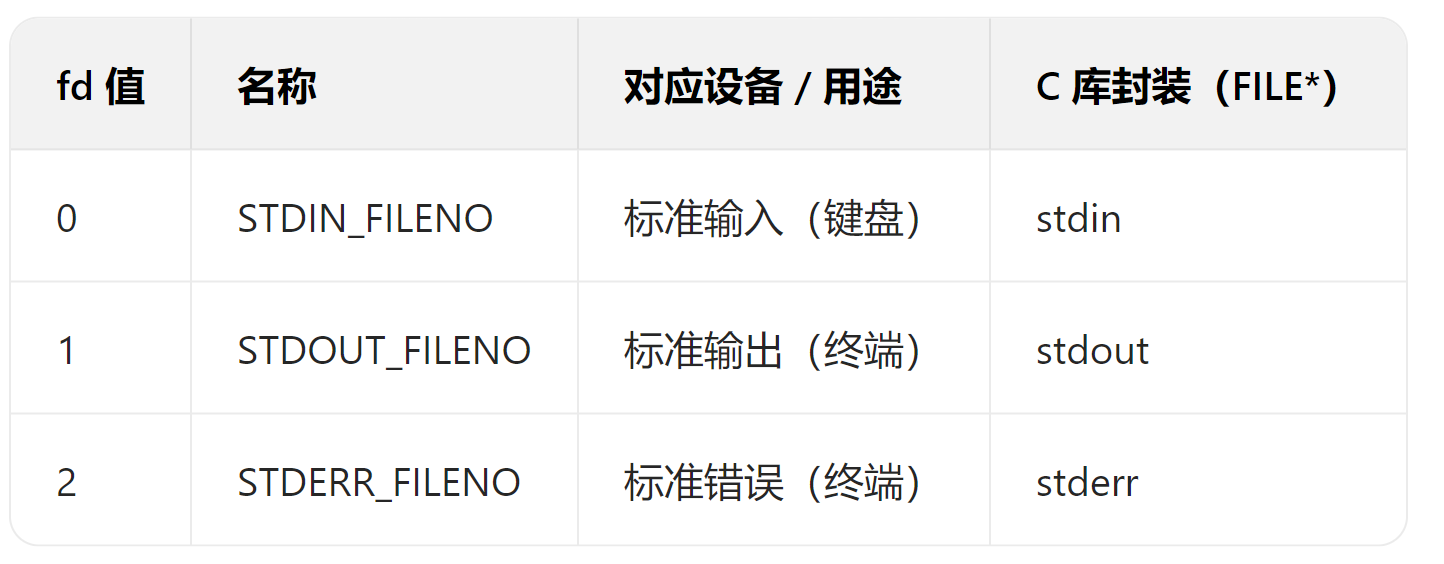
在进程创立的时候,0、1、2这三个fd值是默认被占用的:stdin(标准出入)、stdout(标准输出)、stderr(标准错误)
标准输入、输出、错误默认分别绑定终端键盘、终端屏幕、终端屏幕
fd的分配规则
新打开文件时,内核会给进程分配当前未使用的最小整数作为 fd。通常fd为0、1、2的通常被占用,此时如果fd为3的未被占用则新分配的文件。当然如果使用close函数关闭较小的fd指向,那么新文件的就会被分配到最小的fd。
二、重定向
假设我们关闭fd为0的呢?
close(0);
28 int fd=open("file.txt",O_RDWR|O_CREAT,00644);
29 char arr[100]="";
30 scanf("%s",arr);
31 fflush(stdin);//刷新缓冲区
32 int i=0;
33 for(;i<100;i++)
34 {
35 printf("%c",*(arr+i));
36 }
37 close(fd);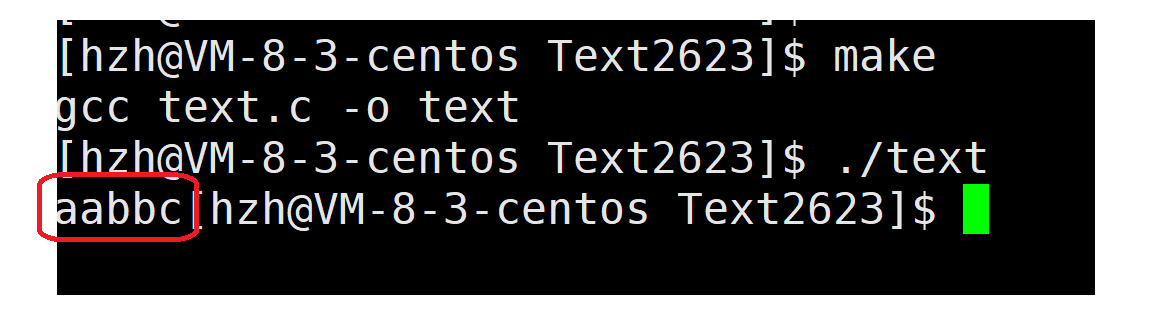
执行程序后发现虽然没有从键盘上读取数据,但file.txt文件中的内容已经被读取并顺利打印出来。代码中我们一开始就关闭了标准输入(fd=0),当使用open函数打开file.txt文件时在fd分配规则的要求下被分配到fd=0的位置,也就是标准输入的位置。
scanf函数从标准输入读取数据,此时fd=0位置是file.txt文件,scanf函数读取的也确实是file.txt文件内容。
这个过程就叫做标准输入重定向。
这一过程也说明了操作系统仅关注 "文件描述符 ↔ 内核文件对象" 的底层绑定关系,完全不感知上层的语义约定、程序意图和库函数逻辑。当fd=0标准输入被替换时操作系统是无法感知到的,其只认为fd=0代表的就是标准输入。
除了关闭fd=0,当然也可以关闭其它文件。当我关闭fd=1再打开新文件时可以构成标准输入重定向(数据输入到指定位置),关闭fd=2时可构成标准错误重定向(错误信息输入到指定位置)
close(1);
40 int fd=open("file.txt",O_RDWR|O_CREAT|O_APPEND,00644);
41 printf("hello!jei\n");;
42 fflush(stdout); //刷新缓冲区
43 close(fd);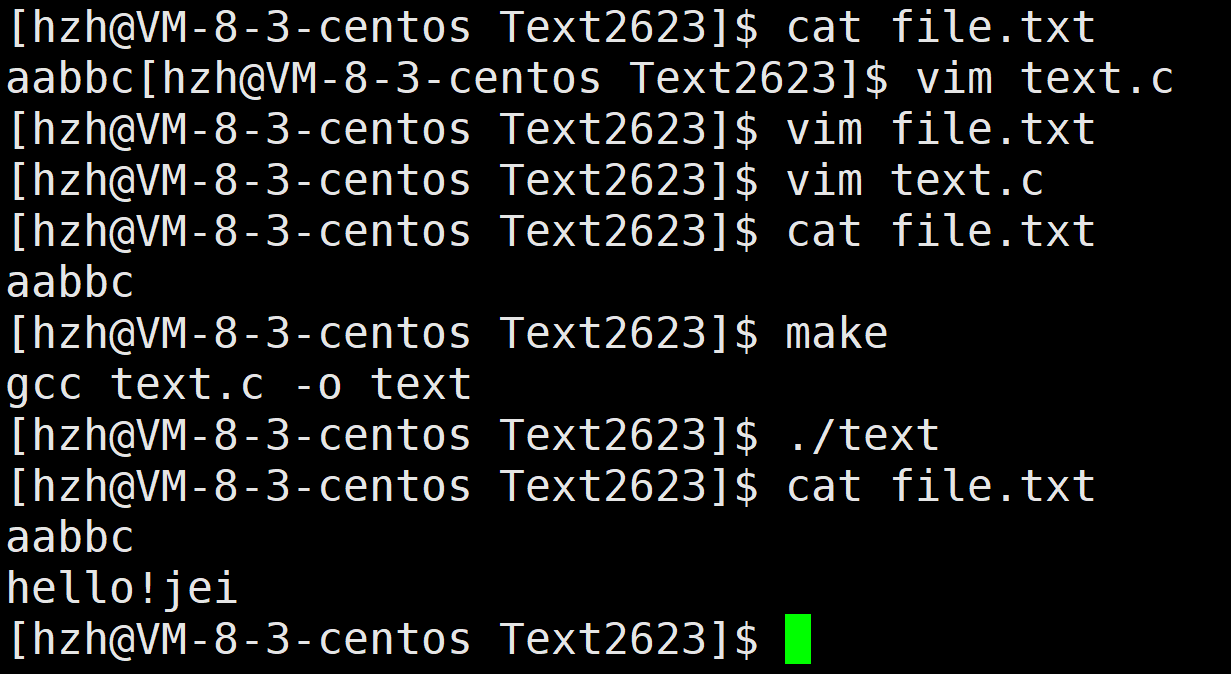
关闭标准输出再打开file.txt文件,当需要向标准输出打印内容时终端屏幕上什么都没有反而发现内容打印到了file.txt文件中,这就是标准输出重定向。
总结下上述例子,所谓重定向其实就是更改fd_array数组下标内容。
Linux dup2调度函数
Linux中的dup2函数能替代上述close+open 的功能,实现文件描述符重定向的标准、可靠且原子化。
#include<unistd.h>
int dup2(int oldfd, int newfd);dup2() 不是拷贝文件内容,而是复制文件描述符的内核绑定关系,使 newfd 与 oldfd 指向同一个内核文件对象(如文件、终端设备),最终让操作 newfd 等价于操作 oldfd(最终只剩下oldfd)。例如 dup2(1, fd) 表示让 fd 成为标准输出(fd=1)的别名(写 fd 等价于写屏幕);dup2(fd, 1) 则是标准输出重定向(写标准输出等价于写 fd 指向的文件)。
三、进一步了解文件
Linux下一切皆文件,对于每个硬件来说都会有对应的文件数据结构struct_file来管理。struct_file结构体中封装的方法在上层保持一致,即使在具体的底层实现虽然并不一样也能保持较高的不同硬件的统一调度。
其实就是基类和派生类的关系。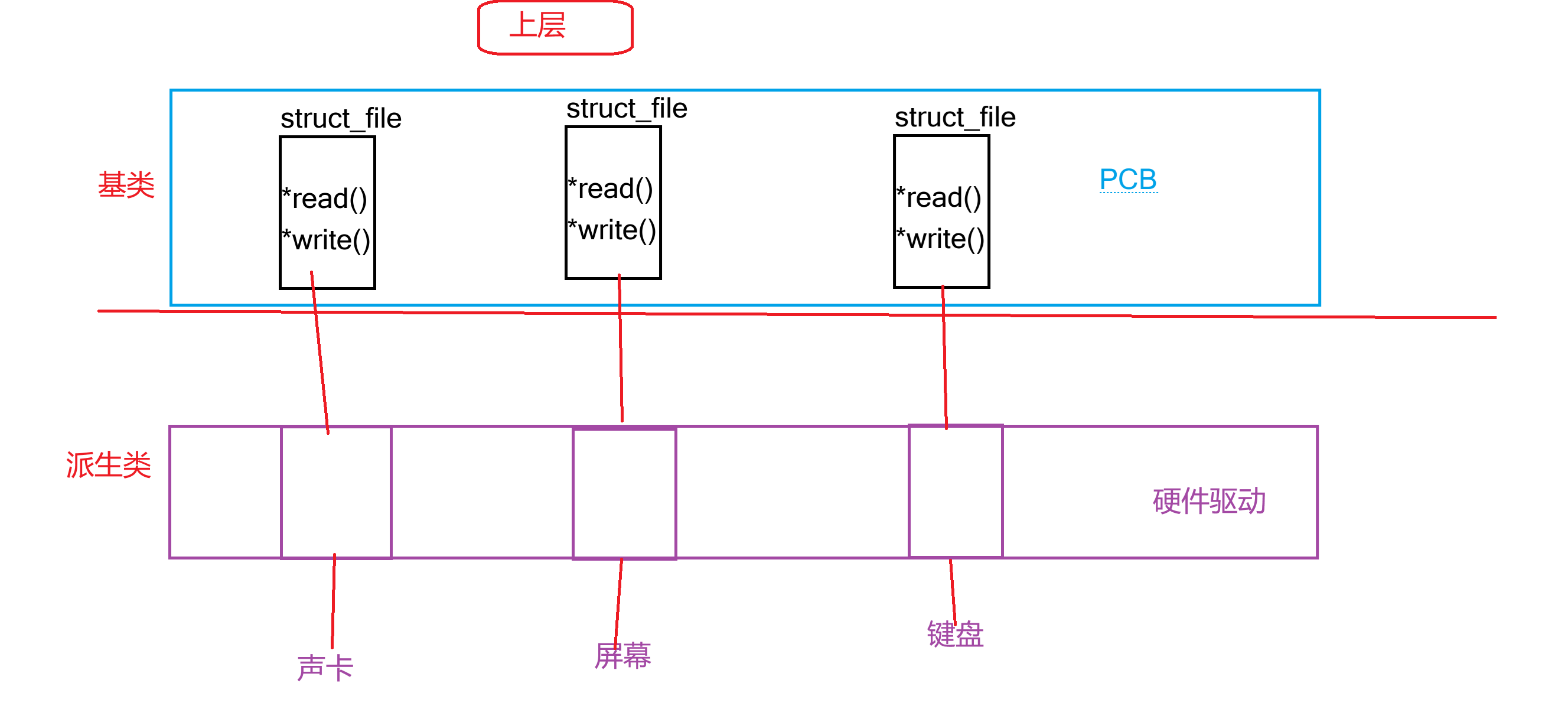
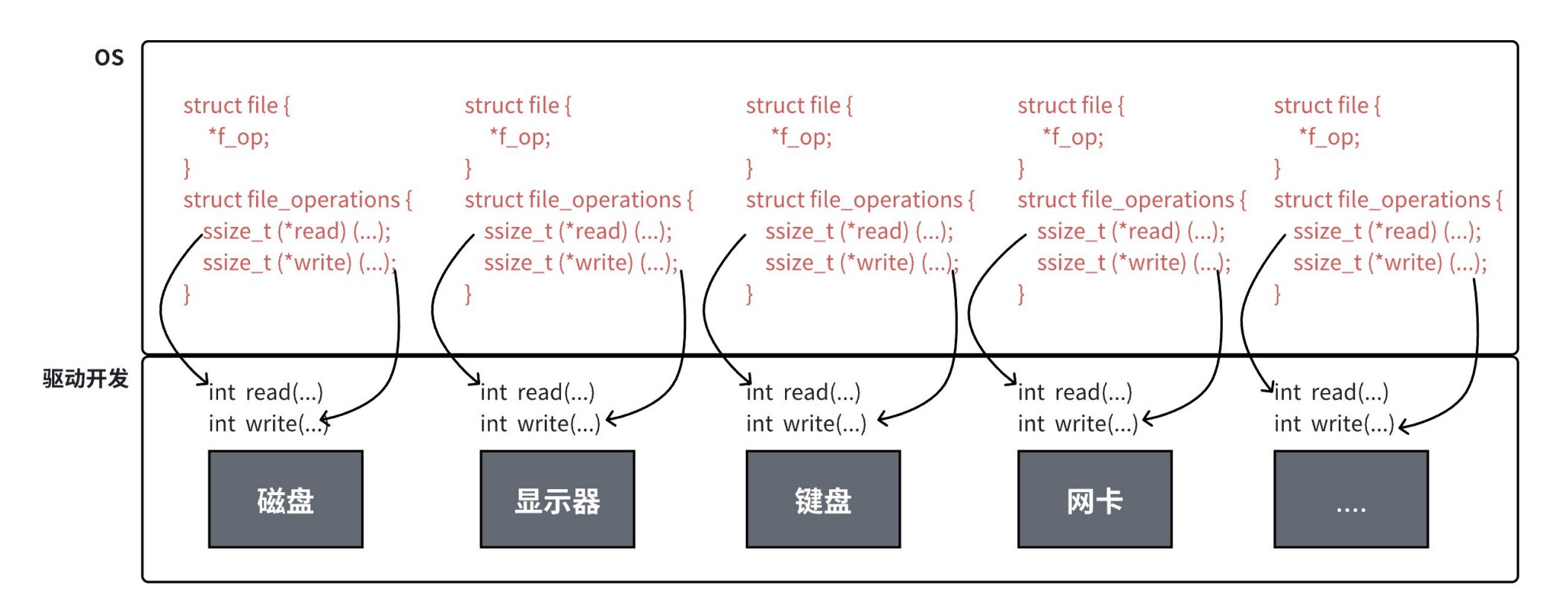
在进程角度来看,各硬件都是通过struct_file结构体管理的,而该结构体又是硬件驱动的封装。
四、缓冲区
什么是缓冲区
缓冲区(Buffer) 是内核分配的一块内存区域,核心作用是临时存储待写入硬件 / 从硬件读出的数据,解决进程 / 内核与硬件设备之间的速度不匹配问题,同时减少对硬件的直接频繁操作、实现数据异步传输。
首先要明白调用系统调用进行读写是有代价的--时间代价。在语言层面会对系统调用做封装,但如果仍然是发起一次请求就执行一次系统调用就会造成耗时过高的问题。为了解决这个问题,缓冲区就被设计出来。
缓冲区能展暂时存储部分读/写数据,等进程结束或缓冲区已满或其它特殊情况才会调用系统调用进行读写操作,将小而频繁的操作转化为大整体尽量一次读写操作就完成,减少时间消耗。
close(1);
40 int fd=open("file.txt",O_RDWR|O_CREAT|O_APPEND,00644);
41 printf("hello!jei\n");;
42 fflush(stdout); //刷新缓冲区
43 close(fd);对于上面代码而言,如果没有fflush函数手动刷新标准输出流,那么就会出现程序执行后文件没有成功写入的情况。这是因为printf向标准输出打印时一开始是将数据放在C语言级缓冲区中,可因为文件在进程结束前就已经被close关闭,导致无法正常写入。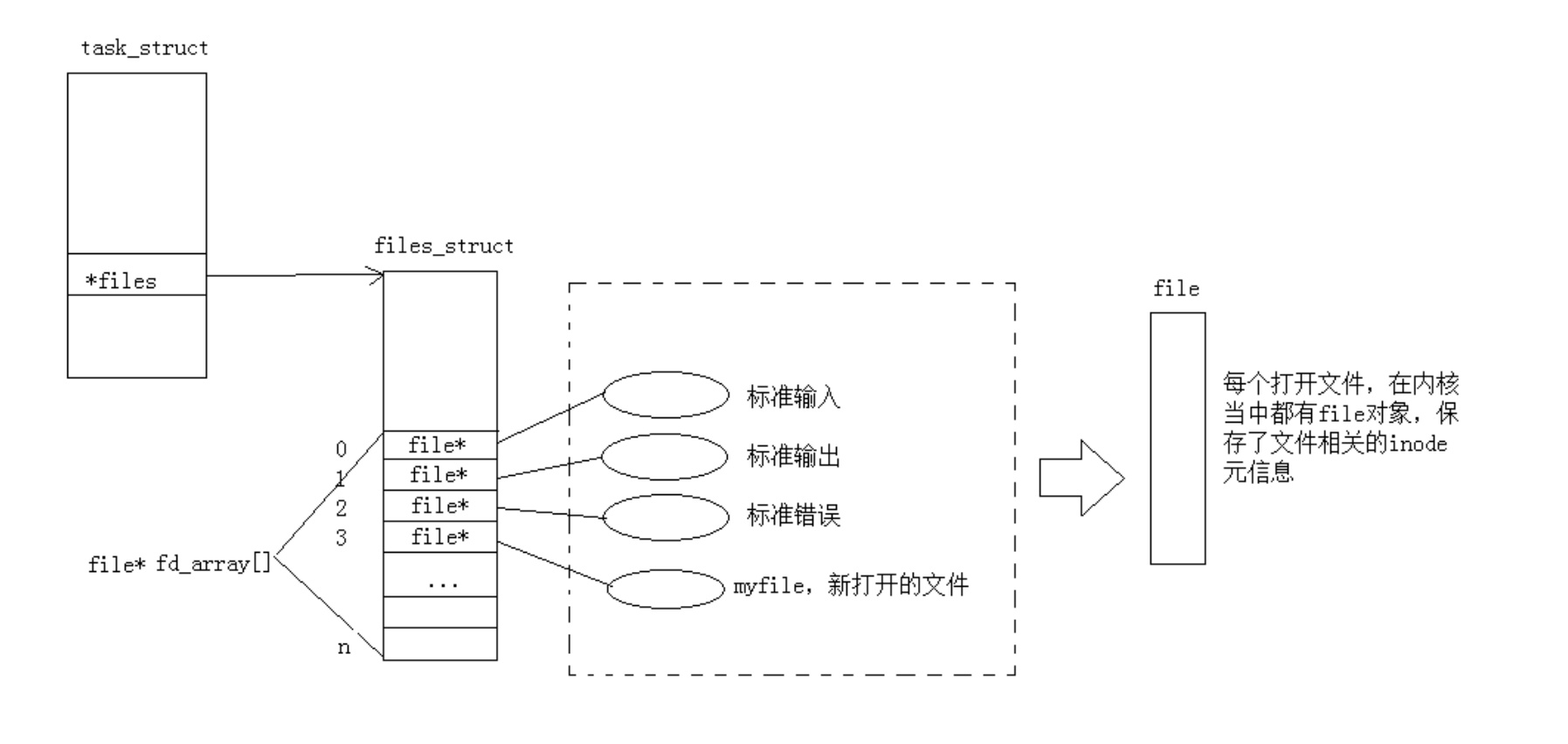
上图最右侧struct file 与进程私有的文件描述符(fd)一一绑定,其中记录着该 fd 操作文件的上下文信息(如读写偏移量、打开模式等)。struct file 通过 f_inode 指针指向全局唯一的 inode 结构体,而 inode 会关联到内核全局共享的系统级缓冲区(页缓存);因此,files_struct 中每个 fd 对应一个独立的 struct file 实例,多个 struct file 若指向同一个 inode,就会复用同一块全局页缓存,而非每个文件拥有专属的缓冲区。
缓冲区类型
全缓冲区
该缓冲方式要求填满整个缓冲区后,才会执行 I/O 系统调用操作;磁盘文件的操作通常采用全缓冲方式访问。
行缓冲区
行缓冲模式下,输入和输出中遇到换行符时,标准 I/O 库函数会执行 I/O 系统调用操作;操作的流涉及终端时(如标准输入、标准输出),使用行缓冲方式。标准 I/O 库的行缓冲区长度固定,若缓冲区被填满,即使未遇到换行符(\n),也会执行 I/O 系统调用操作,行缓冲区默认大小为 1024。
无缓冲区
无缓冲区指标准 I/O 库不对字符进行缓存,会直接调用系统调用;标准出错流 stderr 通常采用无缓冲方式,确保出错信息能尽快显示。
在语言和系统层面上来看又可以分为语言级缓冲区和系统级缓冲区。
缓冲区刷新
语言级缓冲区(用户态,标准 IO 库)
自动刷新:行缓冲遇\n或缓冲区满,全缓冲仅缓冲区满;二者均在进程正常退出、关闭流时刷新;
手动刷新:调用fflush()强制刷新(指定 / 所有流);
无缓冲:无缓存,写操作直接触发系统调用,无需刷新。
系统级缓冲区(内核态,页 / 块缓冲区等)
自动刷新:脏页达内存阈值 / 超时、系统内存不足、关闭文件描述符 / 进程退出、系统关机;
手动刷新:调用sync()(刷到内核层,不等待硬件)、fsync()(指定 fd 刷到硬件并等待)、fdatasync()(仅刷数据,更快)。
对于一般文件来说一般都是全缓冲。
进程与缓冲区
严谨点来看,进程是不具备缓存区这一说法的,但由于Linux下一切皆文件且文件struct_file结构体中的包含有缓冲区结构导致进程与缓冲区被绑定到一起。
系统级缓冲区是全局共有的,但进程打开文件 / 设备后,会通过以下链路绑定到对应的缓冲区区域:
进程 → 打开文件/设备 → 得到文件描述符(fd) → 内核映射到struct file → struct file关联inode → inode指向系统级缓冲区(页缓存)
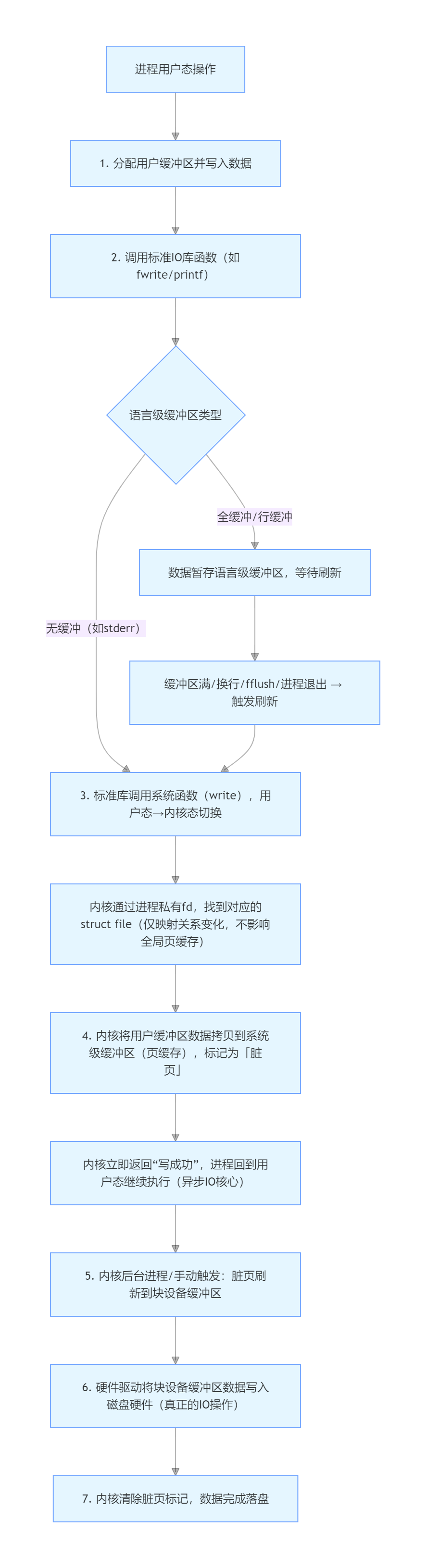
当用户写入数据需要记录到磁盘上的流程:
1.进程在用户级分配用户缓冲区(统一映射到struct file,更改进程私有fd只会改变映射关系)
2.进程通过函数调用系统函数,用户缓冲区中的数据被拷贝到系统级缓冲区中。
3.进行IO操作