最近因TDSQL存放物联感知数据量增长较快,因此为提升性能,使用分区表。
建表
sql
DROP TABLE `data_iot2`;
CREATE TABLE `data_iot2` (
`id` bigint(20) NOT NULL COMMENT '分布式ID',
`device_id` varchar(64) NOT NULL COMMENT '设备唯一标识',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '数据创建时间',
`metric_name` varchar(128) NOT NULL,
`metric_value` decimal(18,4) NOT NULL,
`unit` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`, `device_id`, `create_time`),
KEY `idx_data_iot2_device_id_create_time` (`device_id`, `create_time`),
KEY `idx_data_iot2_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
PARTITION BY RANGE (TO_DAYS(`create_time`)) (
PARTITION p202601 VALUES LESS THAN (TO_DAYS('2026-02-01')),
PARTITION p202602 VALUES LESS THAN (TO_DAYS('2026-03-01')),
PARTITION p202603 VALUES LESS THAN (TO_DAYS('2026-04-01')),
PARTITION p_max VALUES LESS THAN MAXVALUE
);为何如此设计?
1、满足分区规则:分区键是 TO_DAYS(create_time),所以 create_time必须在主键中。
2、保证全局唯一性:id本身是分布式ID,理论上全局唯一。但MySQL的分区逻辑无法感知这一点,它要求主键能唯一标识整个表的每一行。通过将 id设为主键的第一列,我们确保了主键的唯一性。
3、包含查询键:device_id是高频查询条件,将其加入主键,可以让某些查询(如 WHERE device_id = ? AND create_time = ?)直接通过主键定位,速度极快。
潜在缺点:
主键过长:InnoDB的主键是聚集索引,其叶子节点存储了整行数据。一个过长的主键会增加索引占用的空间,并可能降低基于主键的插入和更新性能。不过,对于您的字段类型,这个长度尚可接受。
注意点
重要警告:在分区表中,类似WHERE create_time > '2026-02-10 10:00:00'这种查询的性能是灾难性的!因为它会导致MySQL的查询优化器无法有效进行分区裁剪(Partition Pruning),可能会变成全分区扫描,即扫描 p202601, p202602, p202603, p_max所有分区,性能极低。强烈建议避免使用此类查询,或者在业务上保证此类查询必须带上 device_id或其他能缩小范围的条件。
插入测试数据
sql
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (1, '1', '2026-01-01 17:27:55', '1', 1.0000, '1');
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (2, '2', '2026-01-02 17:28:11', '2', 2.0000, '2');
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (3, '3', '2026-02-02 17:28:29', '3', 3.0000, '3');
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (4, '4', '2026-02-04 17:28:42', '4', 4.0000, '4');
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (5, '5', '2026-03-19 17:28:52', '5', 5.0000, '5');
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (6, '6', '2026-05-30 17:29:03', '6', 6.0000, '6');
INSERT INTO `test`.`data_iot2` (`id`, `device_id`, `create_time`, `metric_name`, `metric_value`, `unit`) VALUES (7, '7', '2026-06-09 18:02:44', '7', 7.0000, '7');验证
1、执行以下查询计划
sql
EXPLAIN SELECT * FROM `data_iot2` WHERE create_time > '2026-01-01' and create_time < '2026-02-01'
可以看到定位到了分区p202601上
2、执行以下查询计划
sql
EXPLAIN SELECT * FROM `data_iot2` WHERE create_time = '2026-06-09 18:02:44'
由于没有p202606分区,因此定位了p_max分区,注意这里即使重新创建p202601分区,原有已经入库的数据也不会自动挪到新建的分区上
3、执行以下查询计划
sql
EXPLAIN SELECT * FROM `data_iot2` WHERE create_time > '2026-06-09 18:02:44'
从查询计划看,可以看到查询了多个分区
其他
增加分区
sql
ALTER TABLE `data_iot2`
REORGANIZE PARTITION p_max INTO (
-- 1. 定义新的2026年4月分区
PARTITION p202606 VALUES LESS THAN (TO_DAYS('2026-07-01')),
-- 2. 重新定义p_max,作为新的"未来"分区
PARTITION p_max VALUES LESS THAN MAXVALUE
);查询表的所有分区
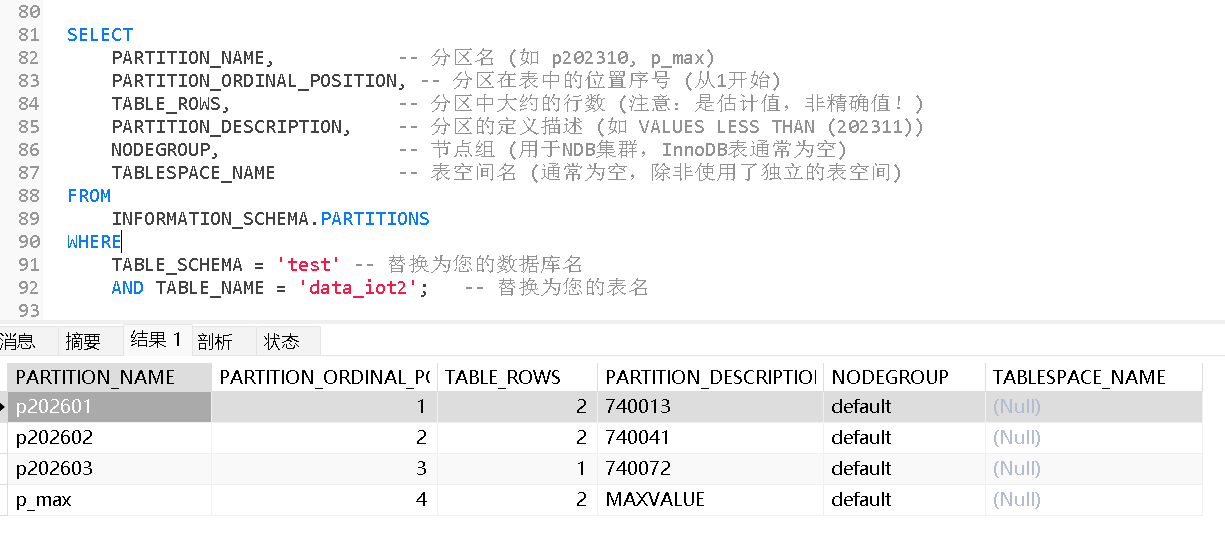
sql
SELECT
PARTITION_NAME, -- 分区名 (如 p202310, p_max)
PARTITION_ORDINAL_POSITION, -- 分区在表中的位置序号 (从1开始)
TABLE_ROWS, -- 分区中大约的行数 (注意:是估计值,非精确值!)
PARTITION_DESCRIPTION, -- 分区的定义描述 (如 VALUES LESS THAN (202311))
NODEGROUP, -- 节点组 (用于NDB集群,InnoDB表通常为空)
TABLESPACE_NAME -- 表空间名 (通常为空,除非使用了独立的表空间)
FROM
INFORMATION_SCHEMA.PARTITIONS
WHERE
TABLE_SCHEMA = 'test' -- 替换为您的数据库名
AND TABLE_NAME = 'data_iot2'; -- 替换为您的表名