1、传统数仓的任务顺序
在一个传统数仓中,prd_src贴源层的表负责从外部系统接数,后续各个层(prd_dwd、prd_dws、prd_ads)的表负责从存储过程中被插入数据(一般都是一个存储过程,从若干来源表取数、加工,最终插入到一个结果表)。
而这些表的增量进数的过程,都是由"任务"控制的,比如Shell脚本,分别负责将外部数据插入prd_src层、执行存储过程(插入数据进结果表)。
一般来说,作为一个业务复杂、T+1时效、月增量达到3T的传统数仓,任务的数量或者说Shell脚本数可以达到600余个,且拥有复杂的先后关系,案例如下表所示。
各个任务中,SRC层的任务由于没有前置要求的节点,每天凌晨可以直接执行;后续作业在执行前,要先进入该表检索所有前置节点,然后代入任务执行日志表(略)检查执行是否完成,都完成才可开始执行该任务。
CREATE TABLE task_dependencies (
id SERIAL PRIMARY KEY,
predecessor_task_name VARCHAR(150) NOT NULL, -- 前置任务名称
successor_task_name VARCHAR(150) NOT NULL -- 后置任务名称
);
-- 插入任务依赖关系数据
INSERT INTO task_dependencies (predecessor_task_name, successor_task_name) VALUES
-- SRC层任务:数据接入,通常没有前置任务
('SRC_LOAD_ORDERS', 'DWD_PROCESS_SALES'),
('SRC_LOAD_CUSTOMERS', 'DWD_PROCESS_SALES'),
('SRC_LOAD_PRODUCTS', 'DWD_PROCESS_SALES'),
('SRC_LOAD_INVENTORY', 'DWD_PROCESS_INVENTORY'),
-- DWD层任务:依赖SRC层,进行数据清洗和关联
('DWD_PROCESS_SALES', 'DWS_AGG_SALES_DAILY'),
('DWD_PROCESS_SALES', 'DWS_AGG_CUSTOMER_BEHAVIOR'),
('DWD_PROCESS_INVENTORY', 'DWS_AGG_INVENTORY_STATUS'),
-- DWS层任务:依赖DWD层,进行指标汇总
('DWS_AGG_SALES_DAILY', 'DWS_AGG_SALES_MONTHLY'),
('DWS_AGG_CUSTOMER_BEHAVIOR', 'DWS_AGG_SALES_MONTHLY'),
-- 模拟更复杂的依赖:一个任务有多个前置任务
('SRC_LOAD_MARKETING_DATA', 'DWD_PROCESS_MARKETING'),
('DWD_PROCESS_MARKETING', 'DWS_AGG_SALES_MONTHLY'),
('DWS_AGG_INVENTORY_STATUS', 'DWS_FINAL_REPORT'),
('DWS_AGG_SALES_MONTHLY', 'DWS_FINAL_REPORT');
--查找一个任务的所有直接前置任务
SELECT predecessor_task_name
FROM task_dependencies
WHERE successor_task_name = 'DWD_PROCESS_SALES';
--查找一个任务的所有直接后置任务
SELECT successor_task_name
FROM task_dependencies
WHERE predecessor_task_name = 'DWD_PROCESS_SALES';2、任务执行异常的情况
一般而言,数仓的600余个任务的执行是顺利的,从凌晨0点开始,最迟9~10点结束,但往往会出现这样的情况------第二天早上上班查看时,一些任务已经跑完,一些任务再跑,还有一些任务没有跑。这显然是一个异常情况,此时我们必须排查这些任务节点的执行是否正常,到底卡在了哪一个任务节点?
这些问题的原因,一般有两类:
一是某个SRC层的任务没有跑或者延迟了(可能违法了某接数前的检查条件),导致后置的任务节点不能开始执行,最终导致延迟或者卡住。
二是某个任务所对应调度的存储过程在实际执行中耗费了太多资源,导致执行时间大大延长而使后续任务被延迟而不能开始;或者进一步因为耗费资源过多,导致数据库停止执行该存储过程,返回错误值,任务就执行失败了,最终该任务频繁地重启、执行失败、重启.........
归纳这两类错误的原因和特征,可以看出,要么是这些任务的"开始时间"出了问题,要么是"执行时长"出了问题,因此,我们得设计一个SQL来每天监控这些任务的执行情况,以便在任务异常或延迟执行的时候,快速找出出问题的任务节点。
3、对开始时间的监控
为了对开始时间进行监控,我推荐从各个数据链条的最后一个节点开始(本例仅展示一条数据链条),递归出上游的每一个节点,然后代入日志表中查出对应任务的开始时间。
--查找没有前置任务的所有后置节点,也就是数据链条上的最后一个任务
SELECT successor_task_name
FROM task_dependencies
WHERE successor_task_name not in (SELECT predecessor_task_name FROM task_dependencies );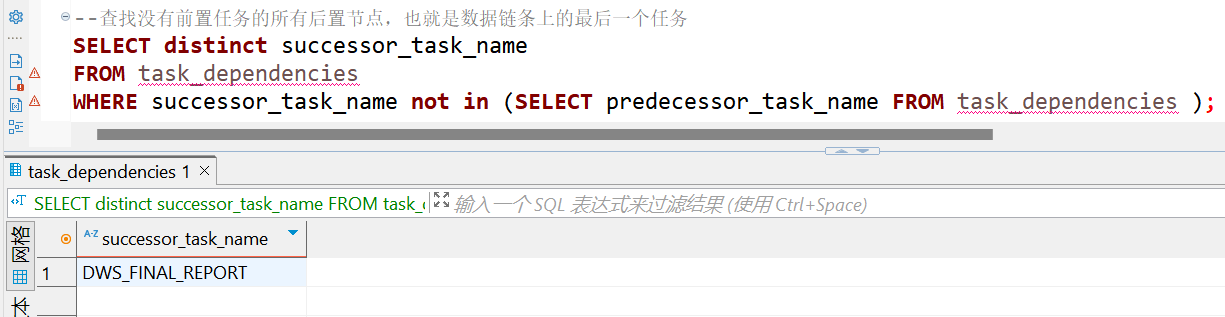
--从终末节点(叶子节点)出发,递归出上游每一个节点
with recursive t1 as (
SELECT distinct successor_task_name task_name
FROM task_dependencies
WHERE successor_task_name not in (SELECT predecessor_task_name FROM task_dependencies )
union distinct
SELECT distinct predecessor_task_name
FROM task_dependencies t0
right join t1 on t0.successor_task_name =t1.task_name
)
select task_name from t1
where task_name is not null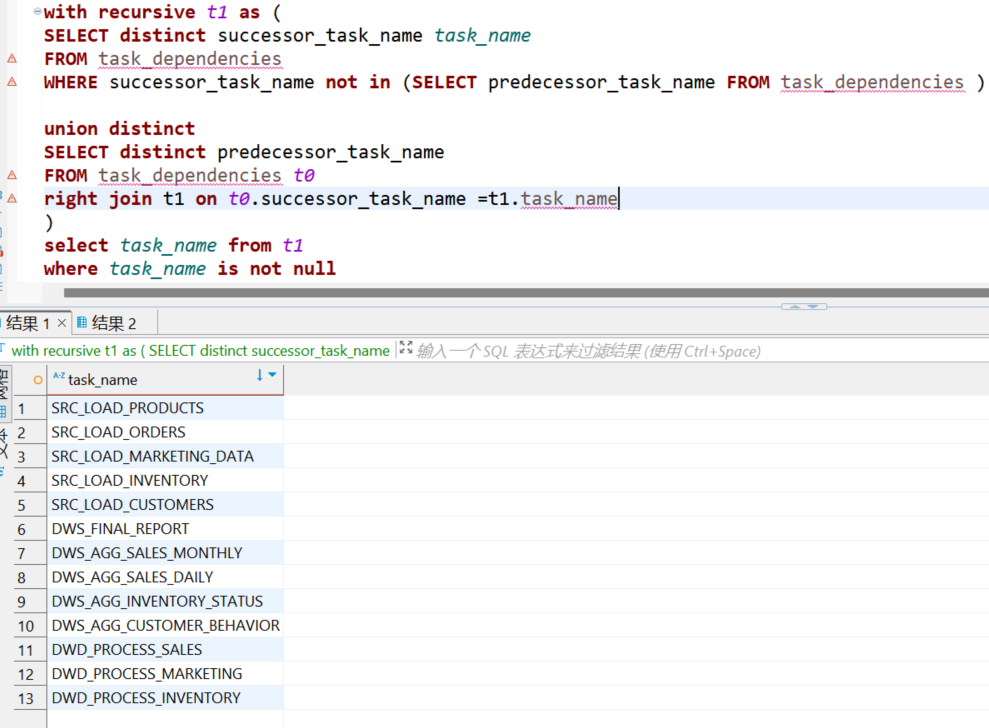
正常情况下,这些任务的开始时间在排列上,是从小到大的,是均匀的,不会有突增的情况;也就是说,如果某SRC的任务延迟接数了,该任务的开始时间会猛增,显得十分突出。
--正常情况
任务名称 分配的时间值 (HH:MM)
SRC_LOAD_PRODUCTS 2026-02-05 01:00:00
SRC_LOAD_ORDERS 2026-02-05 01:05:00
SRC_LOAD_MARKETING_DATA 2026-02-05 01:10:00
SRC_LOAD_INVENTORY 2026-02-05 01:15:00
SRC_LOAD_CUSTOMERS 2026-02-05 01:20:00
DWD_PROCESS_SALES 2026-02-05 01:25:00
DWD_PROCESS_MARKETING 2026-02-05 01:30:00
DWD_PROCESS_INVENTORY 2026-02-05 01:35:00
DWS_AGG_CUSTOMER_BEHAVIOR 2026-02-05 01:40:00
DWS_AGG_SALES_DAILY 2026-02-05 01:45:00
DWS_AGG_INVENTORY_STATUS 2026-02-05 01:50:00
DWS_AGG_SALES_MONTHLY 2026-02-05 01:55:00
DWS_FINAL_REPORT 2026-02-05 02:00:00
--异常情况
任务名称 分配的时间值 (HH:MM)
SRC_LOAD_PRODUCTS 2026-02-05 01:00:00
SRC_LOAD_ORDERS 2026-02-05 01:05:00
SRC_LOAD_MARKETING_DATA 2026-02-05 01:10:00
SRC_LOAD_CUSTOMERS 2026-02-05 01:20:00
DWD_PROCESS_SALES 2026-02-05 01:25:00
DWD_PROCESS_MARKETING 2026-02-05 01:30:00
DWS_AGG_CUSTOMER_BEHAVIOR 2026-02-05 01:40:00
DWS_AGG_SALES_DAILY 2026-02-05 01:45:00
DWS_AGG_SALES_MONTHLY 2026-02-05 01:55:00
SRC_LOAD_INVENTORY 2026-02-05 03:15:00 --一目了然,该任务的开始时间有异常
DWD_PROCESS_INVENTORY 2026-02-05 03:25:00
DWS_AGG_INVENTORY_STATUS 2026-02-05 03:35:00
DWS_FINAL_REPORT 2026-02-05 03:45:004、对执行时间的监控
传统数仓中,常常会发生某任务所对应的存储过程在执行中,因为耗费太多资源而被数据库终止,因此导致反复重试。而在数仓的存储过程的执行中,每执行提交一句SQL,都会往日志表插入一条日志记录的,因此,分析该日志表的记录,可以得出每日的所有存储过程的执行时长。
进一步地,将某一存储过程前99天的执行时间取平均值后,与当天的进行对比分析,就可以判断出来当天的执行时间是否属于超长,从而反应为异常情况。
另外,假设这100天的执行时长的数据中,前99天内,有90天的执行时间在25~30分钟之间(平均为27分钟),但是出现了9天异常执行数据为300分钟,而当天执行时长是45分钟。显然45分的执行时间,会导致最终延误15分钟,应该被记录为异常,要去看一下的,但是按照公式算:(27x90+300x9)/99=51.82>45,因此没有显示异常。
之所以这9天有异常数据,这可能是因为这9天内,生产上正常跑数的6小时后的,人工觉得有必要再一次跑数,导致日志表中取某天的某存储过程的最小、最大值去算执行时长时,得到了脏数据。
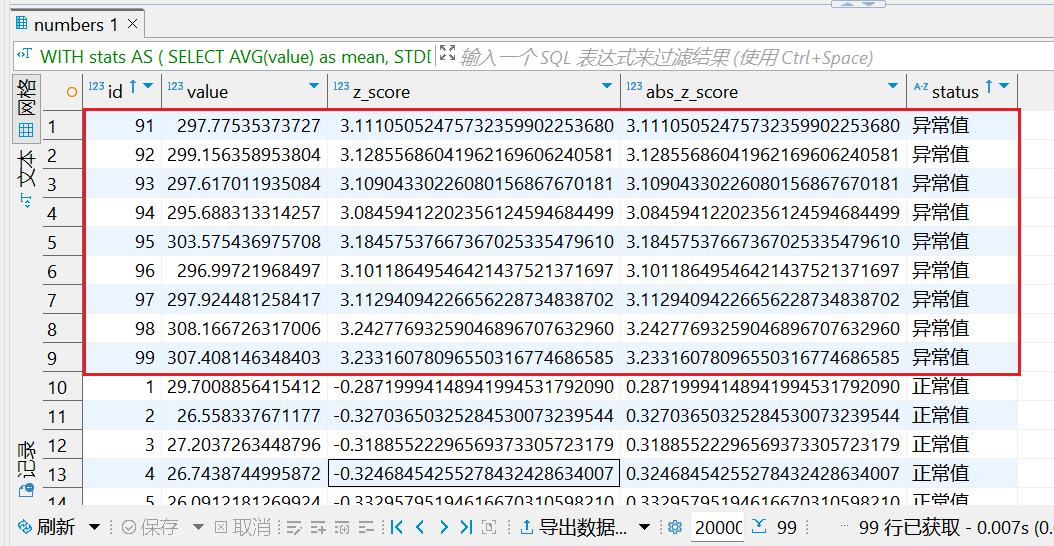
因此,我们再计算过去某个存储过程的正常的平均执行时长时,假设有99条数据,90条正常(在25~30之间),9条不正常(约300分钟),我们必须将后者排除掉后再进行计算平均值。我的方法是对这99条数据算出平均值、标准差,然后如果满足"(执行时长-平均值)/标准差>2",记为异常值,则排除出这9条数据,如下SQL演示。
当我们去除了9条异常数据,将过去90天的平均执行时长算出来为27,当天的执行时长为45,则执行时间显然有点超出,需要进一步被调查;像这样,就可以监控每天的数仓(数据库)中的所有存储过程的执行时长是否有问题,并被SQL即时查询出来。
-- 创建测试表
CREATE TABLE numbers (
id SERIAL PRIMARY KEY,
value NUMERIC NOT NULL
);
-- 插入90个正常数据(25~30之间)
INSERT INTO numbers (value)
SELECT 25 + random() * 5 -- 25~30之间的随机数
FROM generate_series(1, 90);
-- 插入9个异常数据(约300左右)
INSERT INTO numbers (value)
SELECT 290 + random() * 20 -- 290~310之间的随机数
FROM generate_series(1, 9);
-- 查看数据分布
SELECT
COUNT(*) as total_count,
MIN(value) as min_value,
MAX(value) as max_value,
AVG(value) as average,
STDDEV(value) as std_dev
FROM numbers;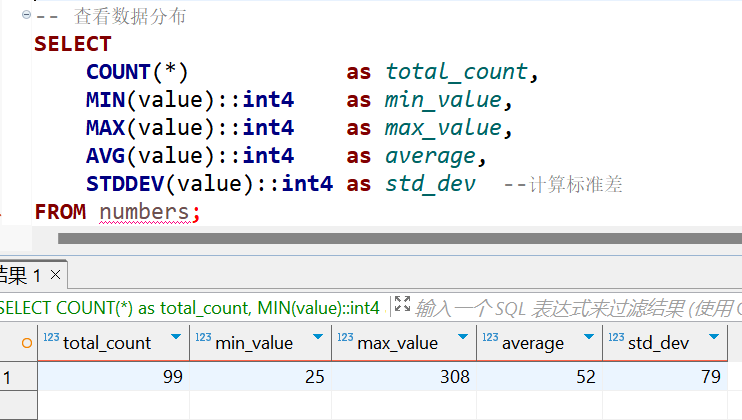
WITH stats AS (
SELECT
AVG(value) as mean,
STDDEV(value) as std_dev
FROM numbers
),
z_scores AS (
SELECT
id,
value,
(value - mean) / std_dev as z_score,
ABS((value - mean) / std_dev) as abs_z_score
FROM numbers, stats
)
-- 查找异常值(Z-score > 2 通常认为是异常值)
SELECT
*,
CASE
WHEN abs_z_score > 2 THEN '异常值'
ELSE '正常值'
END as status
FROM z_scores
ORDER BY abs_z_score DESC;