文档搜索引擎搜索模块程序见下文:
本文介绍搜索模块的实现细节。
目录
[1. 关于分词库Ansj的大小写转换](#1. 关于分词库Ansj的大小写转换)
[2. 关于简单匹配与独立成词匹配](#2. 关于简单匹配与独立成词匹配)
[3. 关于使用正则表达式去JS标签](#3. 关于使用正则表达式去JS标签)
[3.1 统一处理所有HTML标签](#3.1 统一处理所有HTML标签)
[3.2 使用正则表达式匹配去除script标签](#3.2 使用正则表达式匹配去除script标签)
[3.3 使用正则表达式匹配处理空格](#3.3 使用正则表达式匹配处理空格)
[3.4 在DocSearcher类验证修改后的程序](#3.4 在DocSearcher类验证修改后的程序)
1. 关于分词库Ansj的大小写转换
java
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.List;
public class TestAnsj {
public static void main(String[] args) {
String str="The Quick Brown Fox Jumps Over The Lazy Dog";
List<Term> terms= ToAnalysis.parse(str).getTerms();
for(Term term: terms){
System.out.print(" \""+term.getName()+"\",");
}
}
}运行测试类:

可见分词库直接实现了大写转为小写,故而在查找时,也需要将正文统一处理为小写,才能在原文中保证命中关键词,否则可能因为大小写不同而导致查询无果,使用String提供的toLowerCase()方法即可:
java
firstPos = content.toLowerCase().indexOf(word);2. 关于简单匹配与独立成词匹配
java
public class TestIndexOf {
static String content = "applepie pineapple apple banana";
static String word = "apple";
public static void main(String[] args){
// 子串匹配
int pos1 = content.indexOf(word);
System.out.println("pos1: "+pos1);
// 独立单词匹配
int pos2 = content.indexOf(" "+word+" ");
System.out.println("pos2: "+pos2);
}
}运行测试类:
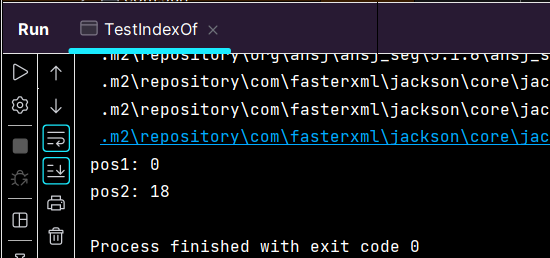
仅使用word作为参数进行定位进行的是子串匹配,可能匹配单词的一部分。
而使用" "+word+" "作为参数,即是通过空格作为单词边界实现一定程度上的独立单词匹配。
更严格的方式应使用正则表达式,此处使用" "可以保证绝大多数情况都定位成功,故不再复杂化。
3. 关于使用正则表达式去JS标签
3.1 统一处理所有HTML标签
在仅对HTML正文去HTML标签的情况下,在DocSearcher类实现main方法进行调用,以ArrayList作为查询词进行初步测试:
java
public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while(true){
System.out.print("请输入查询词->");
String query = scanner.next();
List<Result> results = docSearcher.search(query);
for(Result result:results){
System.out.println("----------------------------");
System.out.println(result);
}
}
}运行结果部分截图如下:
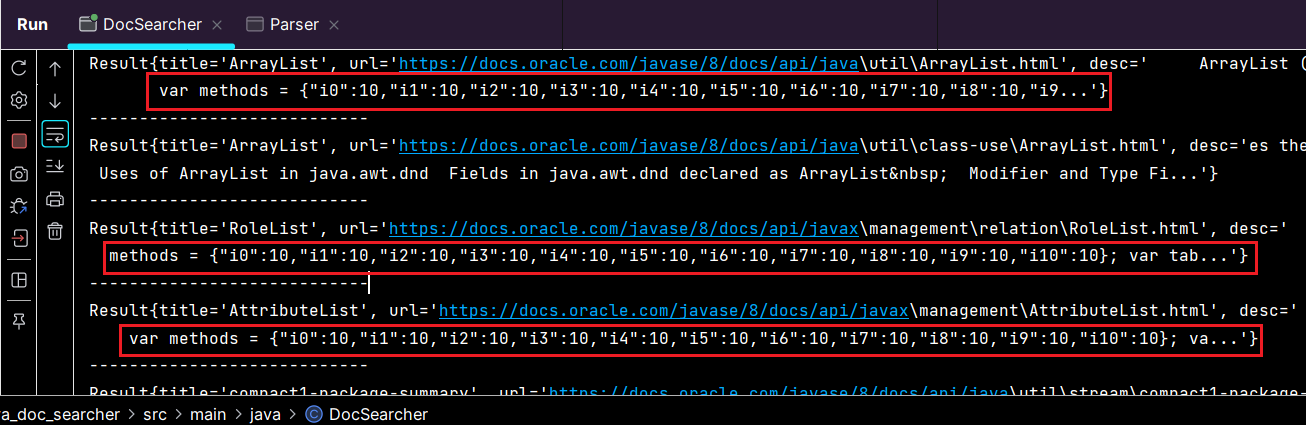
红框内部的是JavaScript的代码,有些HTML包含script标签,在对HTML正文去标签后,JS的代码也被整理到索引中了。
3.2 使用正则表达式匹配去除script标签
可以使用正则表达式来去JS标签。正则表达式使用了一些特殊的字符串描述了一些匹配规则,Java的String中的很多方法都支持正则,如indexOf,replace,replaceAll,spilt等等。
常用如下:
(1).表示匹配一个非换行字符(即非\n,非\r);
(2)*表示匹配若干个前面的那个字符;
(3).*即表示匹配非换行字符出现若干次(包括0次);
(4).+表示匹配非换行字符出现若干次(至少1次);
故而使用<.*?>即可匹配普通标签,使用<script.*?>(.*?)</script>即可匹配script标签,其中**?表示非贪婪匹配** ,表示匹配到一个符合条件的最短结果(若不带?则表示贪婪匹配,即表示匹配到一个符合条件的最长结果)
例如:<div>aaa</div><div>bbb</bbb>,若使用贪婪匹配<.*>,从第一个div始标签的<匹配到第二个div末标签的>,则包括aaa和bbb在内的整个正文都被匹配去除,这显然不是期望效果;若使用非贪婪匹配<.*?>,则表示分别匹配4个div标签,使得aaa和bbb不被匹配去除:
java
public String parseContentByRegex(File f){
// 将整个文件读取到String内
String content = readFile(f);
// 替换script标签
content = content.replaceAll("<script.*?>(.*?)</script>"," ");
// 替换普通标签
content = content.replaceAll("<.*?>"," ");
return content;
}注意应先处理script标签再处理通用标签,仍以ArrayList.html为例进行测试:
java
import java.io.File;
public class TestParseContent {
public static void main(String[] args) {
Parser parser=new Parser();
File file=new File("E:/SearchEngineProject/jdk-8u441-docs-all/docs/api/java/util/ArrayList.html");
String result = parser.parseContent(file);
String result2 = parser.parseContentByRegex(file);
System.out.println(result);
System.out.println(result2);
}
}运行结果如下:

3.3 使用正则表达式匹配处理空格
正则表达式中**\s匹配任何空白字符,包括空格、制表符、换页符等等**,但仅使用\s+并不能表示至少一个的若干个空格,涉及到转义问题:

故而应写为:
java
content = content.replaceAll("\\s+"," ");再次测试parseContentByRegex:

可见多个空格已被合并处理为一个空格。
3.4 在DocSearcher类验证修改后的程序
完成修改后,在Parser类中的parseHTML方法中的parseContentBy()方法修改为parseContentByRegex()方法:再次在DocSearcher中重启main方法查看生成的标题,URL以及描述:
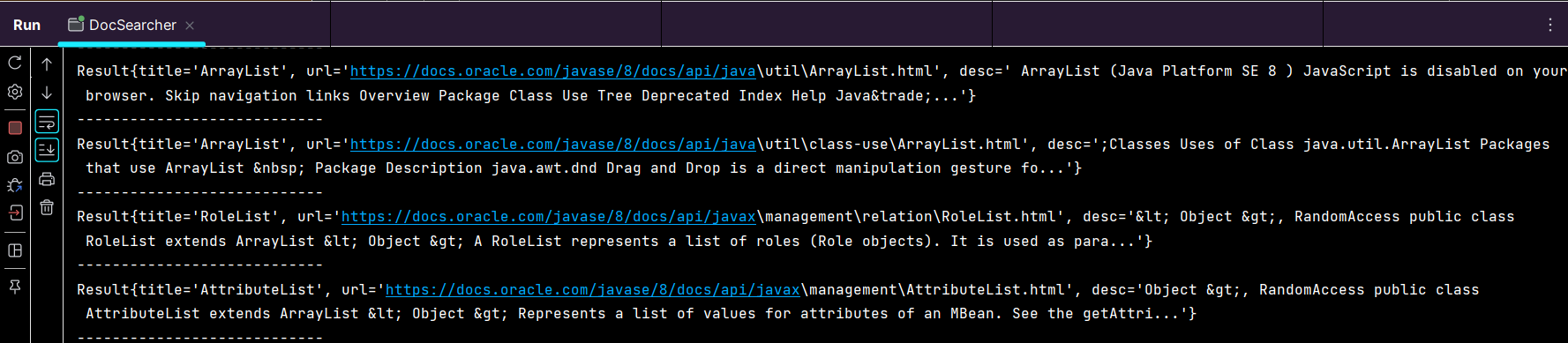
可见此时生成的描述已经没有了JS代码。