HashMap
- 引言
- 一、HashMap的概念
- 二、HashMap的基本结构
-
- [1."数组 + 链表/红黑树"的复合结构](#1.“数组 + 链表/红黑树”的复合结构)
- 2.哈希值
-
- [1. 扰动函数(防止分布不均)](#1. 扰动函数(防止分布不均))
- [2. 取模运算(定位桶)](#2. 取模运算(定位桶))
- 哈希冲突
-
- 核心原因(鸽巢原理)
- [HashMap 的应对策略](#HashMap 的应对策略)
- 三、HashMap的put与get
-
- [1. 存储过程(put)](#1. 存储过程(put))
- 2.查找过程(get)
- 四、HashMap的扩容机制
- 五、HashMap的线程安全性
-
-
- [1. 致命缺陷:JDK 1.7 的"死循环" (CPU 100%)](#1. 致命缺陷:JDK 1.7 的“死循环” (CPU 100%))
- [2. 顽固通病:数据覆盖 (JDK 1.7 & 1.8)](#2. 顽固通病:数据覆盖 (JDK 1.7 & 1.8))
- [3. JDK 1.8 的改进与残留问题](#3. JDK 1.8 的改进与残留问题)
- [4. 替代方案:ConcurrentHashMap 的进化](#4. 替代方案:ConcurrentHashMap 的进化)
- 总结对比表
-
- 六、总结与最佳实践
引言
学Java的小伙伴们一定在学习的过程中都离不开集合框架吧~
临时提问:常见的集合框架有什么?
3
2
1
没错!你说的很对,常见的集合框架有 List ,Set,Map~
而今天我们要说的是Map当中的HashMap~
一、HashMap的概念
- 什么是HashMap:HashMap是Java集合框架中极为重要的一员,它以 "键-值对" 的形式存储数据,支持快速的插入、查找和删除操作,平均时间复杂度为O(1)。它基于哈希表实现,允许使用null键和多个null值,是开发中高频使用的数据结构之一。
- 应用场景:在实际编程中,HashMap广泛应用于缓存系统(如本地缓存)、配置项管理、统计频次(如词频统计)、去重处理以及数据库结果映射等场景,极大提升了程序的运行效率和可读性。
那么为什么HashMap的平均时间复杂度如此之低呢,竟然只要O(1),到底是怎么做到的,这也太匪夷所思了,别着急,我们从HashMap的基本结构说起
二、HashMap的基本结构
1."数组 + 链表/红黑树"的复合结构
- 数组+链表/红黑树:HashMap底层采用"数组 + 链表/红黑树"的复合结构。数组是哈希表的主干,每个数组元素称为一个"桶"(Bucket)。当发生哈希冲突时,多个元素会以链表形式挂在同一个桶上;当链表长度超过8且数组长度达到64时,链表自动转为红黑树,以提升查找性能。
说到这里你可能还是有些懵逼,我来给你画个图你就懂了:
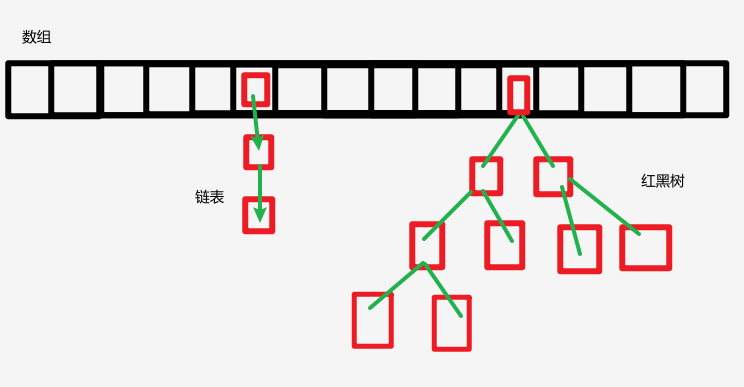
【小声叨叨:我猜有小伙伴不知道啥是红黑树,也不知道啥是平衡二叉树,这个你就当是一种很巧妙的构思,让人直呼妙哉妙哉,能够保证查找、插入和删除操作的最坏时间复杂度均为 O(logn),后续有时间再给大家讲】
其中,红色框框就相当于一个结点,里面有什么呢?
java
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 哈希值
final K key; // 键
V value; // 值
Node<K,V> next; // 指向下一个节点的指针(绿色箭头的实现原理)
// 构造函数...
}2.哈希值
那可能又会有小伙伴们看到上述代码里的 final int hash; 问:啥又是哈希值呢?
我们都知道 Java 的运行时环境(JVM)本身就是用 C++ 等语言编写的。在 Java 中,Object 类是所有类的祖宗,而 hashCode() 方法正是定义在 Object 类中。
这就好比:
每一个 Java 对象出生时,系统都会给它发一个"身份凭证"。虽然这个凭证在 Java 层面表现为一个方法,但在底层,它往往是由 JVM 用更高效的语言(如 C++)来实现的。这就像是由"户籍系统底层"直接生成的编号,我们直接拿过来用就行,不需要自己去编写生成逻辑。
在 HashMap 中的应用:
当你把一个字符串(比如 "name")作为 Key 存入 HashMap 时,HashMap 的第一反应就是:"我要检查你的指纹!"
它会立刻调用这个 Key 的 hashCode() 方法。这个"指纹"是后续一切操作的基础,HashMap 会拿着这个号码去进行扰动计算和取模运算,最终算出这个 Key 应该存放在数组的哪一个"桶"里。
PS:虽然所有对象都有这个方法,但默认情况下 (如果没有被重写),这个哈希码通常是根据对象的内存地址 通过某种算法映射得来的;而像 String、Integer 等包装类,它们都重写 了 hashCode() 方法,确保内容相同的字符串,算出来的哈希码是一模一样的。
那么我们再来讲讲扰动计算和取模运算~
首先,调用 Key 的 hashCode() 方法,得到一个原始的整数(哈希码)。
1. 扰动函数(防止分布不均)
拿到原始哈希码后,HashMap 不会直接使用它。
- 问题: 如果用户实现的
hashCode()不够好(比如产生的哈希码低比特位变化少,高比特位全是0),直接取模会导致所有数据都集中在数组的前半部分,造成严重的哈希冲突。 - 解决(扰动): Java 会对原始哈希码进行高地位异或运算 (
h ^ (h >>> 16))。 - 效果: 这样做是为了让哈希码的高位信息 也能参与到下标的计算中,让生成的哈希值更加"随机"和均匀分布,从而减少冲突。
2. 取模运算(定位桶)
最后,为了让哈希值能对应上数组的索引,会进行取模运算。
- 公式:
index = hash % 数组长度或者在源码中更高效的位运算index = (n - 1) & hash。 - 结果: 这一步决定了你的 Key-Value 对最终会落入哪一个**黑色的桶(数组槽位)**中。
所以:
哈希值就是通过算法算出的地址线索。它的质量直接决定了红黑树出现的频率,也决定了 HashMap 的读写性能。
哈希冲突
但是,这里有一个巨大的误区需要澄清:哈希值并不是绝对唯一的。
假设我们现在要往 HashMap 里存第一个数据:put("name", "Mic")。
- 算哈希 :HashMap 调用
"name".hashCode(),得到一个数字。 - 定位置 :经过扰动和取模,算出这个数据应该放在数组的第 1 号桶。
- 直接放:因为是第一个数据,1 号桶空空如也,直接放进去,大功告成!
这时候,HashMap 的内心独白是:"这工作太轻松了,我就是个简单的数组。"
但是,程序的世界哪有那么多"刚好"?
假设现在我们要存第二个数据:put("hobby", "swing")。
- 算哈希 :调用
"hobby".hashCode()。 - 定位置 :经过计算,尴尬的一幕发生了------它算出来的位置也是第 1 号桶!
这就是哈希冲突(Hash Collision)。
并且哈希冲突在数学上来说是不可避免的,那么为啥躲不掉呢?
核心原因(鸽巢原理)
想象一下,你可以存入的数据(输入空间)是无限的(任意长的字符串、文件),但哈希值(输出空间)是一个固定的数字范围(比如 int 类型只有 2^32 种可能)。这就像是有无数只鸽子(数据),但只有 42 亿个鸽巢(哈希值)。根据鸽巢原理,当鸽子数量超过鸽巢数量时,必然会有两只不同的鸽子挤进同一个巢里。这就是哈希碰撞。
如果 HashMap 还是死板地只用数组,那 "hobby" 就会把 "name" 挤走(覆盖),或者被 "name" 挡在外面。这显然是不行的。
HashMap 的应对策略
正因为哈希值不保真(不绝对唯一),所以 HashMap 在拿到哈希值定位到"桶"之后,还得进行二次确认:
第一步(看哈希值):快速定位到大致位置(桶)。
第二步(看 equals):在桶里遍历链表或红黑树,调用 equals() 方法逐个比对,确认到底是不是真的同一个 Key。
总结一句话:
哈希值是用来快速筛选的,equals() 是用来最终判决的。
哈希值不同,对象一定不同;哈希值相同,对象不一定相同。
三、HashMap的put与get
1. 存储过程(put)
- 首先调用键的hashCode()方法计算原始哈希值。
- 经过扰动处理(高地位异或)后,通过(n - 1) & hash的方式确定数组下标。
- 若该位置为空,则直接插入;否则遍历链表或红黑树,比较键的hash值和equals(),若已存在则更新值,否则添加新节点。
2.查找过程(get)
- 同样计算键的哈希值并定位到数组索引。
- 若该位置有元素,则逐个比较链表或红黑树中的节点,通过hash值和equals()判断是否匹配,找到则返回对应值,否则返回null。
四、HashMap的扩容机制
1.负载因子
负载因子(load factor)是衡量HashMap填充程度的指标,默认值为0.75。当元素数量 > 容量 × 负载因子时,触发扩容(一般都是翻一倍)。
2.扩容过程
扩容时创建一个原数组两倍大小的新数组,将所有元素重新计算索引并迁移过去。此过程较耗时,因此建议在初始化时预估数据量,设置合理的初始容量,避免频繁扩容。
五、HashMap的线程安全性
1. 致命缺陷:JDK 1.7 的"死循环" (CPU 100%)
这是 HashMap 线程不安全最恐怖的表现。在 JDK 1.7 中,多线程并发扩容(resize)时,极有可能导致链表形成环形结构 ,一旦形成,后续的 get() 操作就会陷入无限循环,导致 CPU 使用率瞬间飙升至 100%。
- 根源:头插法 (Head Insertion)
JDK 1.7 在扩容迁移数据时,使用的是头插法 。即:将原链表的节点拆下来,插入到新链表的头部。 - 场景复现(两个线程 A 和 B):
- 前提 :原数组某个桶里有一条链表
A -> B -> null。 - 并发:线程 A 和 线程 B 同时触发扩容,都要迁移这条链表。
- 过程 :
- 线程 A 执行到一半(假设刚拿到 A 节点,还没修改 A 的 next),被挂起。
- 线程 B 醒来,它完整地执行了迁移:它把 B 插到新链表头,再把 A 插到新链表头。此时新链表变成
A -> B -> null(注意顺序变了)。 - 线程 A 醒来,继续执行。此时线程 A 眼里的视图还是旧的(它认为 B 的 next 是 null)。
- 线程 A 开始操作:它把 B 插到新链表头(此时新链表是
B -> A -> B...),由于线程 A 眼里的 B.next 是 null,它会错误地把 A 接在 B 后面,而此时 A 的 next 又指向 B。
- 结果 :链表变成了
A -> B -> A的环形链表。 - 后果 :只要程序后续调用
get()去遍历这个桶,就会在这个环里无限转圈,直到栈溢出或程序卡死。
- 前提 :原数组某个桶里有一条链表
2. 顽固通病:数据覆盖 (JDK 1.7 & 1.8)
这个问题在所有版本的 HashMap 中都存在,它是由于 put 操作的非原子性导致的。
- 根源:检查与插入的分离
put操作的逻辑通常是:先检查位置是否为空(tab[i] == null),如果是空的,就新建节点放入。 - 场景复现(两个线程 A 和 B):
- 前提:线程 A 和 线程 B 准备往同一个桶(同一个索引)放入不同的键值对。
- 并发 :
- 线程 A 先执行,它检查发现
tab[i]是 null,准备执行插入。 - 此时线程 A 被挂起。
- 线程 B 开始执行,它也检查发现
tab[i]是 null(因为 A 还没来得及插入),于是线程 B 把自己的数据插进去了。 - 线程 A 恢复,它接着执行插入操作,由于它之前已经判断过位置为空,所以它会直接覆盖当前位置。
- 线程 A 先执行,它检查发现
- 结果 :线程 B 的数据被线程 A 无情覆盖,导致数据丢失。
3. JDK 1.8 的改进与残留问题
JDK 1.8 对 HashMap 做了重大优化,虽然解决了"死循环"这个大毒瘤,但并没有让它变得线程安全。
- 改进:尾插法 (Tail Insertion)
JDK 1.8 将扩容时的插入方式改为了尾插法 。在迁移链表时,保持原来的顺序插入到新链表的尾部。这样即使多线程并发,也不会导致指针错乱形成环,彻底解决了死循环问题。 - 残留问题:数据错乱与结构破坏
- 数据覆盖:上面提到的"检查-插入"分离导致的覆盖问题依然存在。
- 结构破坏:虽然用了尾插法,但在多线程同时进行扩容和插入时,由于缺乏同步锁,可能会导致链表中的节点丢失,或者红黑树的结构被破坏(虽然概率较低,但依然存在)。
4. 替代方案:ConcurrentHashMap 的进化
既然 HashMap 不行,我们就得用专业的工具:ConcurrentHashMap。
- JDK 1.7 的策略:分段锁 (Segment)
它把数据分成一段一段的存储,给每一段配一把锁(ReentrantLock)。当多个线程访问不同段的数据时,互不影响。这叫做锁分段技术,大大提高了并发度。 - JDK 1.8 的策略:CAS + synchronized
这一版的设计非常精妙:- CAS (无锁化操作):在插入数据时,如果没有发生哈希冲突(即桶是空的),它会使用 CAS 操作直接插入。CAS 是一种硬件级别的原子指令,比加锁效率高得多。
- synchronized (细粒度锁) :只有当发生冲突,需要在链表或红黑树上插入时,才会使用
synchronized锁住当前桶的头节点。 - 优势 :锁的粒度非常细,只有当两个线程操作同一个桶时才会互斥。不同桶之间完全并发,性能极高。
总结对比表
| 特性 | HashMap | Hashtable | ConcurrentHashMap (JDK 1.8) |
|---|---|---|---|
| 线程安全 | 否 | 是 (全表锁) | 是 (CAS + synchronized) |
| 并发性能 | 单线程极高,多线程崩坏 | 极低 (synchronized 锁全表) | 极高 (锁粒度极细) |
| 死循环风险 | JDK 1.7 有风险,1.8 无 | 无 | 无 |
| 推荐场景 | 单线程环境 | 已废弃,不推荐 | 高并发环境首选 |
一句话总结:
除非是单线程,否则永远不要在多线程环境下使用 HashMap。如果需要线程安全的 Map,ConcurrentHashMap 是唯一的正确选择。
六、总结与最佳实践
- 总结:HashMap凭借其高效的存取性能和灵活的结构设计,成为Java中最常用的Map实现。理解其底层原理有助于写出更高效、更稳定的代码。
- 最佳实践 :
- 在已知数据量时,显式指定初始容量,避免多次扩容带来的性能损耗。
- 自定义类作为键时,务必重写hashCode()和equals()方法,且保证其一致性与不变性。
- 在多线程环境下,优先选择ConcurrentHashMap而非HashMap,确保程序的健壮性与安全性。
- 避免使用可变对象作为键,防止其状态改变导致哈希值变化,从而无法正确访问值。
- 理解树化与退化条件,合理设计键的分布,减少极端情况下的性能波动。
本文参考了网上的各种文章以及学习视频以及AI助手综合整理而来,由浅入深,层层递进的带大家深入了解HashMap,希望对大家有所帮助
不得不说,我在整理的时候,真的是直呼妙哉妙哉,其实大部分知识都是为了解决问题而想出的办法,只有我们知其然,知其所以然才能更好的运用知识,服务于业务~~~
大家加油鸭!!!