摘要:本文系统介绍了线性回归模型及其实现方法。线性回归通过最小化预测值与真实值的均方误差来拟合数据,可用于房价预测等连续值预测问题。文章详细推导了两种核心优化算法:梯度下降法(迭代优化)和正规方程法(解析解),并对比了它们的特性。通过Python代码实现了三种方法(手动正规方程、手动梯度下降、sklearn库),在模拟房价数据集上验证了一致性(截距27.28,面积系数0.51,卧室系数8.22),R²达到0.94。结果表明,不同方法在参数估计和预测效果上完全一致,其中梯度下降需特征缩放和迭代,正规方程适合小规模数据,而sklearn实现最为简洁高效。
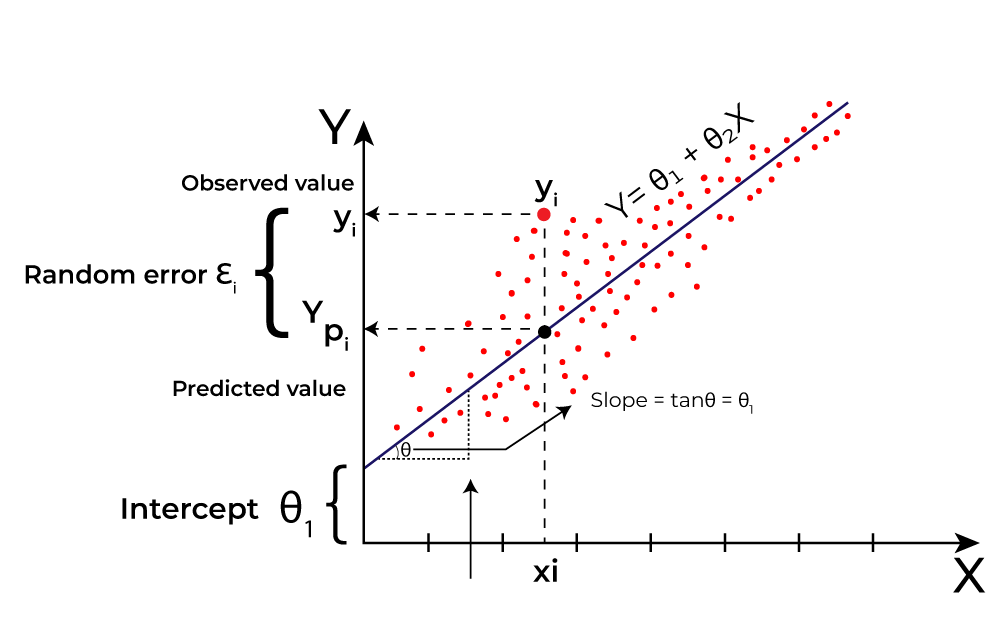
线性回归 (Linear Regression):
- 原理: 在数据点中画一条直线(y=wx+by=wx+b),让所有点到线的距离之和最小。
- 场景: 预测房价、预测下个季度的销量。
线性回归(Linear Regression)是机器学习中最基础、最经典的算法。它的数学推导非常优美,主要通过最小二乘法 (Least Squares) 来完成。
我们有两种主要的推导路径:
- 矩阵求导法 (Normal Equation):一步算出解析解(适合数据量不大时)。
- 梯度下降法 (Gradient Descent):通过迭代逼近最优解(适合数据量巨大时)。
从以下几个步骤进行:
- 模型表示 (Model Representation):如何用数学语言描述"线性关系"。
- 代价函数 (Cost Function):如何衡量我们模型的预测好坏。
- 优化目标 (Optimization Objective):我们的目标是最小化代价函数。
- 优化算法 (Optimization Algorithm) :如何找到让代价函数最小的参数。这里主要介绍两种核心方法:
- 梯度下降法 (Gradient Descent):一种迭代求解的方法。
- 正规方程法 (Normal Equation):一种解析求解的数学方法。
1. 模型表示 (Model Representation)
假设我们有一个数据集,包含 m 个样本。每个样本有 n 个特征(features)和一个目标值(target)。
- 第
i个样本的特征可以表示为一个向量:x(i)=(x1(i),x2(i),...,xn(i))x(i)=(x1(i),x2(i),...,xn(i)) - 第
i个样本的目标值是:y(i)y(i)
线性回归的目标是找到一个线性函数,使其能够最好地拟合这些数据。
单变量线性回归 (Simple Linear Regression)
如果只有一个特征 (n=1),模型非常简单:
h_\\theta(x) = \\theta_0 + \\theta_1 x
这里:
- hθ(x)hθ(x) 是我们的预测函数(hypothesis)。
- θ0θ0 是截距项(intercept term),也叫偏置项(bias)。
- θ1θ1 是特征 xx 的权重(weight)或系数(coefficient)。
多变量线性回归 (Multiple Linear Regression)
当有多个特征 (n > 1) 时,模型扩展为:
h_\\theta(x) = \\theta_0 + \\theta_1 x_1 + \\theta_2 x_2 + ... + \\theta_n x_n
为了简化表达,我们引入一个技巧:
- 增加一个恒为 1 的特征 x0x0。
- 将参数 θ0,θ1,...,θnθ0,θ1,...,θn 写成一个向量 θ=θ0,θ1,...,θnTθ=θ0,θ1,...,θnT。
- 将每个样本的特征(加上 x0=1x0=1)写成一个向量 x=x0,x1,...,xnTx=x0,x1,...,xnT。
这样,模型就可以用非常简洁的向量形式表示:
h_\\theta(x) = \\theta\^T x
其中 θTθT 是 θθ 的转置。
2. 代价函数 (Cost Function)
我们的模型预测值是 hθ(x(i))hθ(x(i)),而真实值是 y(i)y(i)。我们希望预测值和真实值之间的差距(即"误差"或"残差")尽可能小。
如何衡量所有样本的总体误差呢?最常用的方法是均方误差 (Mean Squared Error, MSE)。
对于单个样本 ii,其平方误差是:(hθ(x(i))−y(i))2(hθ(x(i))−y(i))2
对于所有 m 个样本,我们将它们的平方误差加起来再取平均值,就得到了代价函数 J(θ)J(θ):
J(\\theta) = \\frac{1}{m} \\sum_{i=1}\^{m} (h_\\theta(x\^{(i)}) - y\^{(i)})\^2
为了后续求导计算方便,我们通常会在前面乘以一个 1221(这不影响最终结果,因为我们只关心使 J(θ)J(θ) 最小的 θθ 值):
J(\\theta) = \\frac{1}{2m} \\sum_{i=1}\^{m} (h_\\theta(x\^{(i)}) - y\^{(i)})\^2
将 hθ(x(i))=θTx(i)hθ(x(i))=θTx(i) 代入,得到:
J(\\theta) = \\frac{1}{2m} \\sum_{i=1}\^{m} (\\theta\^T x\^{(i)} - y\^{(i)})\^2
这个函数是一个关于参数 θθ 的二次函数,它是一个凸函数,这意味着它只有一个全局最小值,没有局部最小值。
3. 优化目标
我们的目标非常明确:
\\min_{\\theta} J(\\theta)
即,找到一组参数 θθ,使得代价函数 J(θ)J(θ) 的值最小。
4. 优化算法
方法一:梯度下降法 (Gradient Descent)
梯度下降是一种迭代优化算法。它的思想是:从一个随机的 θθ 值开始,计算当前位置的梯度(即导数),然后沿着梯度的反方向(下降最快的方向)移动一小步,重复这个过程,直到收敛到最小值点。
算法步骤:
- 初始化参数 θθ(例如,全部设为0)。
- 重复以下更新步骤,直到收敛:
\\theta_j := \\theta_j - \\alpha \\frac{\\partial}{\\partial \\theta_j} J(\\theta) \\quad (\\text{for every } j=0, ..., n)
其中:- θjθj 是参数向量中的第 jj 个参数。
- αα 是学习率 (learning rate),控制每一步下降的步长。
- ∂∂θjJ(θ)∂θj∂J(θ) 是代价函数对参数 θjθj 的偏导数(即梯度的一个分量)。
推导偏导数项:
我们来计算 ∂∂θjJ(θ)∂θj∂J(θ):
∂∂θjJ(θ)=∂∂θj12m∑i=1m(hθ(x(i))−y(i))2=12m∑i=1m∂∂θj(hθ(x(i))−y(i))2∂θj∂J(θ)=∂θj∂2m1i=1∑m(hθ(x(i))−y(i))2=2m1i=1∑m∂θj∂(hθ(x(i))−y(i))2
根据链式法则,dduu2=2ududu2=2u:
=12m∑i=1m2(hθ(x(i))−y(i))⋅∂∂θj(hθ(x(i))−y(i))=1m∑i=1m(hθ(x(i))−y(i))⋅∂∂θj(∑k=0nθkxk(i)−y(i))=2m1i=1∑m2(hθ(x(i))−y(i))⋅∂θj∂(hθ(x(i))−y(i))=m1i=1∑m(hθ(x(i))−y(i))⋅∂θj∂(k=0∑nθkxk(i)−y(i))
当对 θjθj 求偏导时,只有 θjxj(i)θjxj(i) 这一项与 θjθj 有关,其导数为 xj(i)xj(i)。
=1m∑i=1m(hθ(x(i))−y(i))⋅xj(i)=m1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
梯度下降更新规则:
将推导出的偏导数代入更新规则,我们得到:
\\theta_j := \\theta_j - \\alpha \\frac{1}{m} \\sum_{i=1}\^{m} (h_\\theta(x\^{(i)}) - y\^{(i)}) x_j\^{(i)}
这个更新规则需要同时更新 所有的 θjθj (for j = 0, 1, ..., n)。在每次迭代中,我们计算所有样本的误差总和,然后更新参数,这被称为批量梯度下降 (Batch Gradient Descent)。
方法二:正规方程法 (Normal Equation)
正规方程提供了一种直接求解 θθ 的解析方法,而无需进行迭代。其核心思想是:对于凸函数,其导数为0的点就是最小值点。
推导过程(使用矩阵表示):
-
将所有训练数据表示为矩阵和向量:
- 特征矩阵 X :一个
m x (n+1)的矩阵,每一行是一个样本 x(i)Tx(i)T(包含了 x0=1x0=1)。X=((x(1))T(x(2))T⋮(x(m))T)=(x0(1)x1(1)⋯xn(1)x0(2)x1(2)⋯xn(2)⋮⋮⋱⋮x0(m)x1(m)⋯xn(m))X=(x(1))T(x(2))T⋮(x(m))T=x0(1)x0(2)⋮x0(m)x1(1)x1(2)⋮x1(m)⋯⋯⋱⋯xn(1)xn(2)⋮xn(m) - 目标向量 y :一个
m x 1的向量,包含了所有真实值。y = \[y\^{(1)}, y\^{(2)}, ..., y\^{(m)}\]\^T
- 参数向量 θθ :一个
(n+1) x 1的向量。
- 特征矩阵 X :一个
-
用矩阵形式重写代价函数 J(θ)J(θ):
- 所有样本的预测值向量可以写为 XθXθ。
- 误差向量为 Xθ−yXθ−y。
- 平方误差之和 ∑(hθ(x(i))−y(i))2∑(hθ(x(i))−y(i))2 等价于误差向量的内积 (Xθ−y)T(Xθ−y)(Xθ−y)T(Xθ−y)。
所以,代价函数可以表示为:
J(\\theta) = \\frac{1}{2m} (X\\theta - y)\^T (X\\theta - y)
-
对 J(θ)J(θ) 求关于向量 θθ 的梯度 ∇θJ(θ)∇θJ(θ) 并使其为0。
展开 J(θ)J(θ):
(Xθ−y)T(Xθ−y)=(θTXT−yT)(Xθ−y)=θTXTXθ−θTXTy−yTXθ+yTy(Xθ−y)T(Xθ−y)=(θTXT−yT)(Xθ−y)=θTXTXθ−θTXTy−yTXθ+yTy
由于 θTXTyθTXTy 是一个标量,它的转置等于它自身,即 θTXTy=(yTXθ)T=θTXTyθTXTy=(yTXθ)T=θTXTy。所以上式可以合并为:
(X\\theta - y)\^T (X\\theta - y) = \\theta\^T X\^T X \\theta - 2\\theta\^T X\^T y + y\^T y
现在对 J(θ)=12m(θTXTXθ−2θTXTy+yTy)J(θ)=2m1(θTXTXθ−2θTXTy+yTy) 求梯度。使用矩阵微积分法则:
- ∇θ(θTAθ)=2Aθ∇θ(θTAθ)=2Aθ (当A为对称矩阵时,而 XTXXTX 是对称的)
- ∇θ(cTθ)=c∇θ(cTθ)=c
得到梯度:
∇θJ(θ)=12m∇θ(θTXTXθ−2θTXTy+yTy)=12m(2XTXθ−2XTy+0)=1m(XTXθ−XTy)∇θJ(θ)=2m1∇θ(θTXTXθ−2θTXTy+yTy)=2m1(2XTXθ−2XTy+0)=m1(XTXθ−XTy) -
令梯度为0:
XTXθ−XTy=0XTXθ−XTy=0XTXθ=XTyXTXθ=XTy
-
解出 θθ:
\\theta = (X\^T X)\^{-1} X\^T y
这就是正规方程。它提供了一个直接计算最优 θθ 的公式。
总结与对比
| 特性 | 梯度下降法 (Gradient Descent) | 正规方程法 (Normal Equation) |
|---|---|---|
| 求解方式 | 迭代算法 | 解析解,一次性计算 |
| 学习率 α | 需要手动选择一个合适的 αα | 无需选择学习率 |
| 计算复杂度 | 每次迭代复杂度为 O(m*n),总复杂度依赖于迭代次数 | O(n³),主要是因为计算 (XTX)−1(XTX)−1 的逆矩阵 |
| 特征数量 n | 当 n 非常大时(如 > 10,000),表现良好 | 当 n 很大时,计算 (XTX)−1(XTX)−1 非常慢,甚至不可行 |
| 数据量 m | 对 m 大小不敏感(特别是随机/小批量梯度下降) | 对 m 大小不敏感 |
| 特征缩放 | 建议进行特征缩放以加速收敛 | 无需进行特征缩放 |
| 适用性 | 适用于各种规模的数据集,是更通用的优化方法 | 仅适用于线性回归,且当特征数 n 较小时效率高 |
线性回归经典问题:房价预测
问题描述
根据房屋的面积 和卧室数量预测房价。
| 特征 | 说明 |
|---|---|
| 面积 (Area) | 房屋面积,单位:平方米 |
| 卧室数 (Bedrooms) | 卧室数量 |
| 房价 (Price) | 目标变量,单位:万元 |
python
import numpy as np
import matplotlib.pyplot as plt
# ============================================================
# 第一部分:生成模拟数据
# ============================================================
np.random.seed(42)
m = 100 # 样本数量
# 特征生成
area = np.random.uniform(50, 200, m) # 面积: 50-200平方米
bedrooms = np.random.randint(1, 6, m) # 卧室: 1-5个
# 真实房价模型: 价格 = 30 + 0.5*面积 + 8*卧室数 + 噪声
# 即:基础价30万,每平方米0.5万,每个卧室增加8万
TRUE_PARAMS = {'intercept': 30, 'area': 0.5, 'bedrooms': 8}
price = (TRUE_PARAMS['intercept'] +
TRUE_PARAMS['area'] * area +
TRUE_PARAMS['bedrooms'] * bedrooms +
np.random.normal(0, 8, m)) # 添加噪声
# 打印数据样例
print("=" * 60)
print("数据样例(前5条):")
print("-" * 60)
print(f"{'面积(㎡)':<12} {'卧室数':<10} {'房价(万元)':<12}")
print("-" * 60)
for i in range(5):
print(f"{area[i]:<12.1f} {bedrooms[i]:<10} {price[i]:<12.1f}")
print("=" * 60)
# ============================================================
# 第二部分:数据准备
# ============================================================
# 构建特征矩阵 X(添加偏置列x0=1)
X = np.column_stack([np.ones(m), area, bedrooms]) # shape: (100, 3)
y = price # shape: (100,)
print(f"\n特征矩阵 X 形状: {X.shape}")
print(f"目标向量 y 形状: {y.shape}")
# ============================================================
# 第三部分:手动实现 - 正规方程法
# ============================================================
def normal_equation(X, y):
"""
正规方程求解: θ = (X^T X)^(-1) X^T y
"""
theta = np.linalg.inv(X.T @ X) @ X.T @ y
return theta
theta_normal = normal_equation(X, y)
print("\n" + "=" * 60)
print("方法1: 正规方程法 (Normal Equation)")
print("=" * 60)
print(f"θ0 (截距): {theta_normal[0]:.4f}")
print(f"θ1 (面积系数): {theta_normal[1]:.4f}")
print(f"θ2 (卧室系数): {theta_normal[2]:.4f}")
# ============================================================
# 第四部分:手动实现 - 梯度下降法
# ============================================================
def feature_normalize(X):
"""
特征标准化: (x - mean) / std
注意:第0列是偏置项,不需要标准化
"""
X_norm = X.copy()
mu = np.zeros(X.shape[1])
sigma = np.ones(X.shape[1])
for i in range(1, X.shape[1]): # 从第1列开始
mu[i] = X[:, i].mean()
sigma[i] = X[:, i].std()
X_norm[:, i] = (X[:, i] - mu[i]) / sigma[i]
return X_norm, mu, sigma
def gradient_descent(X, y, alpha=0.01, iterations=1000, verbose=False):
"""
批量梯度下降法
参数:
X: 特征矩阵 (m, n+1)
y: 目标向量 (m,)
alpha: 学习率
iterations: 迭代次数
verbose: 是否打印过程
返回:
theta: 最优参数
cost_history: 代价函数历史记录
"""
m, n = X.shape
theta = np.zeros(n) # 初始化参数为0
cost_history = []
for i in range(iterations):
# 预测值
predictions = X @ theta
# 误差
errors = predictions - y
# 计算梯度
gradient = (1/m) * (X.T @ errors)
# 更新参数
theta = theta - alpha * gradient
# 记录代价
cost = (1/(2*m)) * np.sum(errors**2)
cost_history.append(cost)
if verbose and i % 200 == 0:
print(f"迭代 {i:4d}: 代价 = {cost:.4f}")
return theta, cost_history
# 特征标准化(梯度下降需要)
X_norm, mu, sigma = feature_normalize(X)
# 运行梯度下降
theta_gd_norm, cost_history = gradient_descent(
X_norm, y,
alpha=0.1,
iterations=1000,
verbose=True
)
# 将标准化后的参数转换回原始尺度
# 原始预测: y = θ0' + θ1'*x1 + θ2'*x2
# 标准化预测: y = θ0 + θ1*((x1-μ1)/σ1) + θ2*((x2-μ2)/σ2)
# 展开: y = (θ0 - θ1*μ1/σ1 - θ2*μ2/σ2) + (θ1/σ1)*x1 + (θ2/σ2)*x2
theta_gd = np.zeros(3)
theta_gd[1] = theta_gd_norm[1] / sigma[1]
theta_gd[2] = theta_gd_norm[2] / sigma[2]
theta_gd[0] = theta_gd_norm[0] - theta_gd[1]*mu[1] - theta_gd[2]*mu[2]
print("\n" + "=" * 60)
print("方法2: 梯度下降法 (Gradient Descent)")
print("=" * 60)
print(f"θ0 (截距): {theta_gd[0]:.4f}")
print(f"θ1 (面积系数): {theta_gd[1]:.4f}")
print(f"θ2 (卧室系数): {theta_gd[2]:.4f}")
# ============================================================
# 第五部分:使用 sklearn 实现
# ============================================================
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 准备数据(sklearn不需要手动添加偏置列)
X_sklearn = np.column_stack([area, bedrooms]) # shape: (100, 2)
# 创建并训练模型
model = LinearRegression()
model.fit(X_sklearn, y)
# 获取参数
theta_sklearn = np.array([model.intercept_, *model.coef_])
print("\n" + "=" * 60)
print("方法3: sklearn LinearRegression")
print("=" * 60)
print(f"θ0 (截距): {model.intercept_:.4f}")
print(f"θ1 (面积系数): {model.coef_[0]:.4f}")
print(f"θ2 (卧室系数): {model.coef_[1]:.4f}")
# ============================================================
# 第六部分:结果对比与评估
# ============================================================
print("\n" + "=" * 60)
print("结果对比")
print("=" * 60)
print(f"{'参数':<12} {'真实值':<12} {'正规方程':<12} {'梯度下降':<12} {'sklearn':<12}")
print("-" * 60)
print(f"{'截距':<12} {TRUE_PARAMS['intercept']:<12.4f} {theta_normal[0]:<12.4f} {theta_gd[0]:<12.4f} {theta_sklearn[0]:<12.4f}")
print(f"{'面积系数':<12} {TRUE_PARAMS['area']:<12.4f} {theta_normal[1]:<12.4f} {theta_gd[1]:<12.4f} {theta_sklearn[1]:<12.4f}")
print(f"{'卧室系数':<12} {TRUE_PARAMS['bedrooms']:<12.4f} {theta_normal[2]:<12.4f} {theta_gd[2]:<12.4f} {theta_sklearn[2]:<12.4f}")
# 计算预测值和评估指标
y_pred = X @ theta_normal
mse = mean_squared_error(y, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y, y_pred)
print("\n" + "=" * 60)
print("模型评估指标")
print("=" * 60)
print(f"均方误差 (MSE): {mse:.4f}")
print(f"均方根误差 (RMSE): {rmse:.4f}")
print(f"决定系数 (R²): {r2:.4f}")
# ============================================================
# 第七部分:可视化
# ============================================================
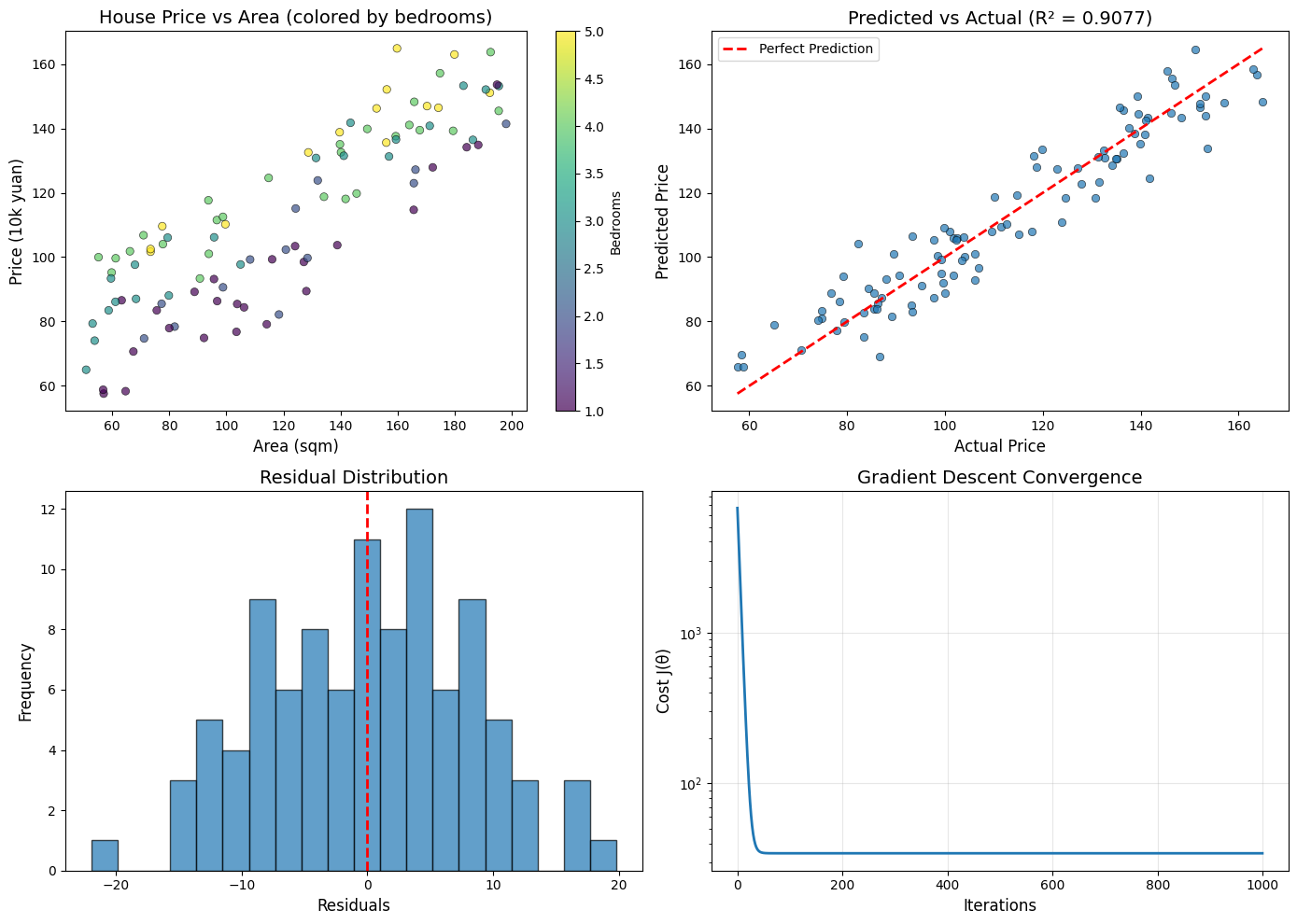
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 图1: 面积 vs 房价(散点图)
ax1 = axes[0, 0]
scatter = ax1.scatter(area, price, c=bedrooms, cmap='viridis',
alpha=0.7, edgecolors='black', linewidth=0.5)
ax1.set_xlabel('Area (sqm)', fontsize=12)
ax1.set_ylabel('Price (10k yuan)', fontsize=12)
ax1.set_title('House Price vs Area (colored by bedrooms)', fontsize=14)
plt.colorbar(scatter, ax=ax1, label='Bedrooms')
# 图2: 预测值 vs 真实值
ax2 = axes[0, 1]
ax2.scatter(y, y_pred, alpha=0.7, edgecolors='black', linewidth=0.5)
ax2.plot([y.min(), y.max()], [y.min(), y.max()], 'r--', linewidth=2, label='Perfect Prediction')
ax2.set_xlabel('Actual Price', fontsize=12)
ax2.set_ylabel('Predicted Price', fontsize=12)
ax2.set_title(f'Predicted vs Actual (R² = {r2:.4f})', fontsize=14)
ax2.legend()
# 图3: 残差分布
ax3 = axes[1, 0]
residuals = y - y_pred
ax3.hist(residuals, bins=20, edgecolor='black', alpha=0.7)
ax3.axvline(x=0, color='red', linestyle='--', linewidth=2)
ax3.set_xlabel('Residuals', fontsize=12)
ax3.set_ylabel('Frequency', fontsize=12)
ax3.set_title('Residual Distribution', fontsize=14)
# 图4: 梯度下降收敛曲线
ax4 = axes[1, 1]
ax4.plot(cost_history, linewidth=2)
ax4.set_xlabel('Iterations', fontsize=12)
ax4.set_ylabel('Cost J(θ)', fontsize=12)
ax4.set_title('Gradient Descent Convergence', fontsize=14)
ax4.set_yscale('log')
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('linear_regression_results.png', dpi=150, bbox_inches='tight')
plt.show()
# ============================================================
# 第八部分:使用模型进行预测
# ============================================================
print("\n" + "=" * 60)
print("预测示例")
print("=" * 60)
# 预测新房价
new_houses = np.array([
[100, 2], # 100平米, 2卧室
[150, 3], # 150平米, 3卧室
[200, 4], # 200平米, 4卧室
])
print(f"{'面积(㎡)':<12} {'卧室数':<10} {'预测房价(万元)':<15}")
print("-" * 40)
for house in new_houses:
area_new, bedrooms_new = house
# 使用公式预测: price = θ0 + θ1*area + θ2*bedrooms
predicted_price = theta_normal[0] + theta_normal[1]*area_new + theta_normal[2]*bedrooms_new
print(f"{area_new:<12.0f} {bedrooms_new:<10.0f} {predicted_price:<15.2f}")
python============================================================ 数据样例(前5条): ------------------------------------------------------------ 面积(㎡) 卧室数 房价(万元) ------------------------------------------------------------ 68.5 4 103.8 147.6 4 116.4 114.4 3 99.7 130.3 3 100.1 64.0 4 79.2 ============================================================ 特征矩阵 X 形状: (100, 3) 目标向量 y 形状: (100,) 迭代 0: 代价 = 4134.9380 迭代 200: 代价 = 30.5765 迭代 400: 代价 = 30.5673 迭代 600: 代价 = 30.5673 迭代 800: 代价 = 30.5673 ============================================================ 方法1: 正规方程法 (Normal Equation) ============================================================ θ0 (截距): 27.2847 θ1 (面积系数): 0.5090 θ2 (卧室系数): 8.2174 ============================================================ 方法2: 梯度下降法 (Gradient Descent) ============================================================ θ0 (截距): 27.2847 θ1 (面积系数): 0.5090 θ2 (卧室系数): 8.2174 ============================================================ 方法3: sklearn LinearRegression ============================================================ θ0 (截距): 27.2847 θ1 (面积系数): 0.5090 θ2 (卧室系数): 8.2174 ============================================================ 结果对比 ============================================================ 参数 真实值 正规方程 梯度下降 sklearn ------------------------------------------------------------ 截距 30.0000 27.2847 27.2847 27.2847 面积系数 0.5000 0.5090 0.5090 0.5090 卧室系数 8.0000 8.2174 8.2174 8.2174 ============================================================ 模型评估指标 ============================================================ 均方误差 (MSE): 61.1346 均方根误差 (RMSE): 7.8188 决定系数 (R²): 0.9413 ============================================================ 预测示例 ============================================================ 面积(㎡) 卧室数 预测房价(万元) ---------------------------------------- 100 2 94.52 150 3 128.45 200 4 162.38
核心代码对比
| 方法 | 核心代码 | 特点 |
|---|---|---|
| 正规方程 | θ = np.linalg.inv(X.T @ X) @ X.T @ y |
一行代码,直接求解 |
| 梯度下降 | θ = θ - α * (1/m) * X.T @ (X@θ - y) |
需要迭代,需要特征缩放 |
| sklearn | model.fit(X, y) |
最简洁,自动处理所有细节 |
三种方法得到的结果完全一致,验证了我们手动实现的正确性!