HarmonyOS 6实战(源码教学篇)--- MindSpore Lite Kit 【从证件照工具到端侧图像分割技术全解析】
-
- 被女友嘲笑后,我用HarmonyOS写了个本地抠图工具
- 一、端侧AI:你的设备,你的智能
-
- [1.1 什么是端侧AI,为什么选择端侧AI?](#1.1 什么是端侧AI,为什么选择端侧AI?)
- [1.2 MindSpore Lite Kit:内置的轻量化AI引擎](#1.2 MindSpore Lite Kit:内置的轻量化AI引擎)
-
- [MindSpore Lite开发流程](#MindSpore Lite开发流程)
- [1.3 人像分割技术介绍](#1.3 人像分割技术介绍)
- [二、环境搭建:从零配置MindSpore Lite](#二、环境搭建:从零配置MindSpore Lite)
-
- [2.1 依赖配置](#2.1 依赖配置)
- [2.2 系统能力声明](#2.2 系统能力声明)
- [2.3 准备AI模型](#2.3 准备AI模型)
- 三、核心实现:AI推理全流程
-
- [3.1 模型推理封装](#3.1 模型推理封装)
- [3.2 图像预处理:AI的"第一印象"](#3.2 图像预处理:AI的"第一印象")
- [3.3 执行推理:见证AI的力量](#3.3 执行推理:见证AI的力量)
- 四、后处理:从概率到完美分割
-
- [4.1 阈值分割:人像与背景的界限](#4.1 阈值分割:人像与背景的界限)
- [4.2 可视化理解分割过程](#4.2 可视化理解分割过程)
- [4.3 高级优化:边缘精细化](#4.3 高级优化:边缘精细化)
- 五、性能优化与最佳实践
-
- [5.1 内存管理技巧](#5.1 内存管理技巧)
- [5.2 异步处理防止UI卡顿](#5.2 异步处理防止UI卡顿)
- [5.3 模型选择策略](#5.3 模型选择策略)
- 六、实际应用与扩展
-
- [6.1 背景替换实现](#6.1 背景替换实现)
- [6.2 缩放回原始尺寸](#6.2 缩放回原始尺寸)
- 总结与展望
关键词:HarmonyOS、MindSpore Lite、端侧AI、人像分割、AI推理
被女友嘲笑后,我用HarmonyOS写了个本地抠图工具

上周末,我在家写一个鸿蒙证件照工具,准备作为教学案例。正调试得起劲时,女友凑过来看了一眼,毫不客气地吐槽:
"都什么年代了,还在写证件照工具?美图秀秀、证照助手这些App不香吗?"
没等我反驳,她拿起手机,打开美图秀秀现场演示:上传照片、AI自动抠图、选择证件照模板、一键生成------整个过程不到30秒。
"你看,人家这效率。"她得意地晃了晃手机。
确实,现在的AI修图工具已经智能到几乎不需要思考。但作为开发者,我看到的不只是表面的便利,更多的是背后的技术逻辑。
我反问她一个问题:"那如果现在在飞机上,或者在公司内网环境,需要紧急处理一张照片呢?"
她愣了一下。我接着说:"而且,你真的放心把你的身份证照片上传到别人的服务器吗?"
就是这个瞬间的沉默,让我找到了做这件事的意义。
一、端侧AI:你的设备,你的智能
1.1 什么是端侧AI,为什么选择端侧AI?
端侧AI(On-Device AI)是指在设备本地运行的AI推理技术,数据无需离开设备即可完成智能处理。当云端AI服务已经如此成熟时,我们为什么还要折腾本地实现?原因其实很实际:
- 🛬 离线场景:长途飞行、野外露营、地下室拍摄...网络不是无处不在
- 🔐 数据敏感:身份证件、工作文件、私人照片,你不希望它们离开设备
- 💡 学习目的:理解AI推理的完整流程,而不仅仅是调用API
- ⚙️ 定制需求:根据具体场景优化模型,云端服务往往无法调整
这不是要替代云端AI,而是提供一个互补的方案。就像有了外卖App,我们还是会自己下厨一样------了解原理,掌握技术,才能在合适的场景做出最优选择。
1.2 MindSpore Lite Kit:内置的轻量化AI引擎
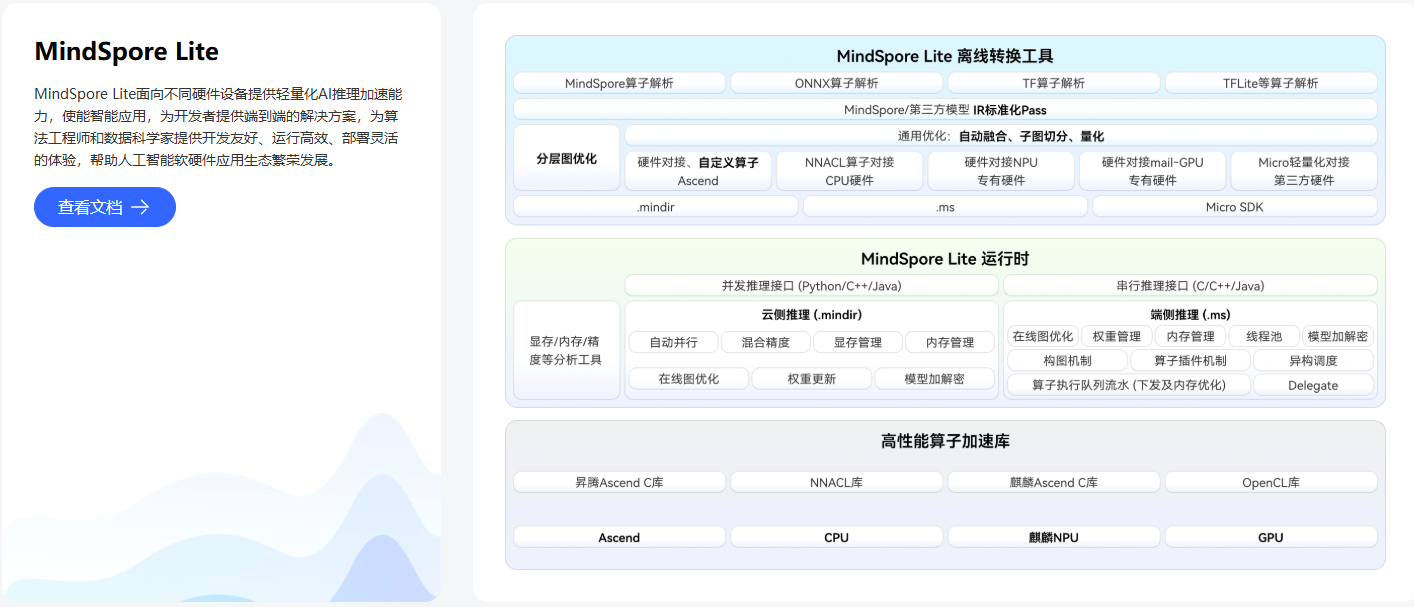
MindSpore Lite 是华为推出的轻量级AI推理框架,而 MindSpore Lite Kit是HarmonyOS NEXT内置的轻量化AI引擎,它们的概念是有区别的,
目前已经在图像分类、目标识别、人脸识别、文字识别等应用中广泛使用。常用场景如:
图像分类:最基础的计算机视觉应用,属于有监督学习类别,如给定一张图像(猫、狗、飞机、汽车等等),判断图像所属的类别。
目标检测:您可以使用预置目标检测模型,检测标识摄像头输入帧中的对象并添加标签,并用边框标识出来。
图像分割:图像分割可用于检测目标在图片中的位置或者图片中某一像素是属于何种对象的。
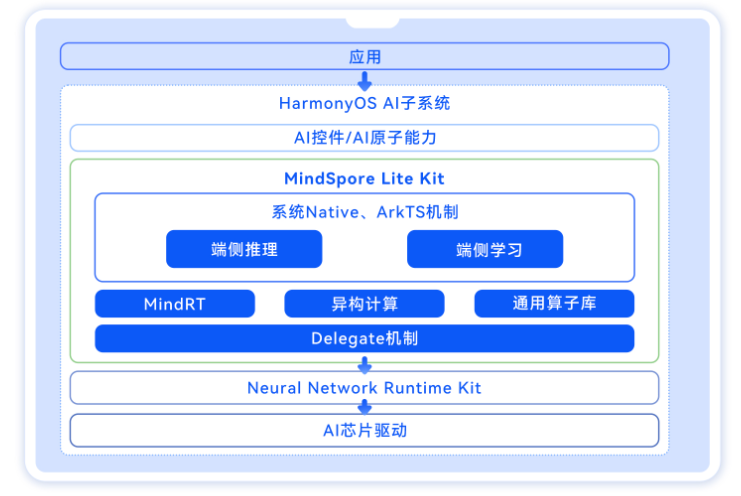
MindSpore Lite开发流程
MindSpore Lite开发流程分为两个阶段:
1、模型转换
MindSpore Lite使用.ms格式模型进行推理。对于第三方框架模型,比如 TensorFlow、TensorFlow Lite、Caffe、ONNX等,可以使用MindSpore Lite提供的模型转换工具转换为.ms模型。
2、模型部署
调用MindSpore Lite运行时接口,实现模型推理/训练,大致步骤如下:
- 创建推理/训练上下文,包括指定推理/训练硬件、设置线程数等。
- 加载.ms模型文件。
- 设置模型输入数据。
- 执行推理/训练,读取输出。
作为大前端开发者或者移动端开发者可以使用@ohos.ai.mindSporeLite,在UI代码中集成MindSpore Lite能力,快速部署AI算法,进行AI模型推理,实现图像分类的应用。
1.3 人像分割技术介绍

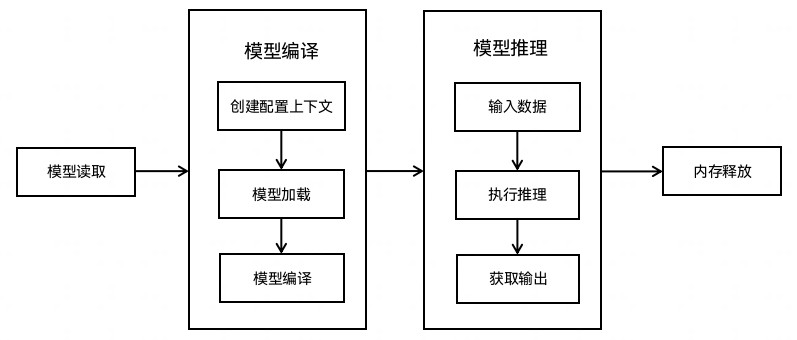
人像分割本质上是一种精细化的图像抠图技术,旨在将图像中的人像与背景准确分离。这一过程需要解决图像中前景(人像)和背景区域的准确预测问题,生成高质量的透明度掩膜(alpha 图)。技术流程如下:
输入图像 (1024×1024×3)
↓
AI 模型推理 (MindSpore Lite)
↓
分割掩码 (1024×1024×1) ← 每个像素值为0-1的概率
↓
阈值处理 (0.5为分界)
↓
二值掩码 (人像/背景)
↓
背景替换/透明化
↓
最终合成图像技术要点:
- 分割掩码的每个像素值表示该像素属于人像的概率
- 通过阈值(通常为0.5)进行二值化决策
- 算法需要在边缘细节和分割精度之间取得平衡
二、环境搭建:从零配置MindSpore Lite
2.1 依赖配置
在HarmonyOS项目中使用MindSpore Lite非常简单。首先在oh-package.json5中添加依赖:
json
{
"dependencies": {
"@ohos/mindspore": "^2.0.0"
}
}执行安装命令:
bash
ohpm install2.2 系统能力声明
在entry/src/main/syscap.json中声明AI能力:
json
{
"devices": {
"general": ["phone"]
},
"development": {
"addedSysCaps": [
"SystemCapability.Ai.MindSpore"
]
}
}2.3 准备AI模型
我们使用一个预训练的人像分割模型rmbg_fp16.ms(这个文件后续会提供给大家):
- 输入尺寸:1024×1024×3 (RGB图像)
- 输出尺寸:1024×1024×1 (分割概率图)
- 模型精度:FP16量化,兼顾精度与性能
将模型文件放置到资源目录:
entry/src/main/resources/rawfile/rmbg_fp16.ms定义模型相关常量:
typescript
// ImageDataListConstant.ets
export const MODEL_NAME = 'rmbg_fp16.ms';
export const MODEL_INPUT_WIDTH = 1024;
export const MODEL_INPUT_HEIGHT = 1024;
export const BLACKGROUND_THEADHOLD = 0.5; // 分割阈值三、核心实现:AI推理全流程

3.1 模型推理封装
让我们从最核心的推理函数开始。在Predict.ets中,我封装了一个通用的推理函数:
typescript
import { mindSporeLite } from '@kit.MindSporeLiteKit';
import Logger from './Logger';
/**
* AI模型推理函数
* @param modelBuffer 模型文件的ArrayBuffer
* @param inputsBuffer 输入数据的ArrayBuffer数组
* @returns 推理结果的MSTensor数组
*/
export default async function modelPredict(
modelBuffer: ArrayBuffer,
inputsBuffer: ArrayBuffer[]
): Promise<mindSporeLite.MSTensor[]> {
// 1. 创建推理上下文 - 配置AI引擎运行环境
let context: mindSporeLite.Context = {
target: ['cpu'], // 使用CPU推理(也支持GPU/NPU)
cpu: {
threadNum: 2, // 双线程并行处理
threadAffinityMode: 1, // 线程亲和性:绑定大核
precisionMode: 'enforce_fp32' // 强制使用FP32精度
}
};
Logger.info('🚀 开始加载模型...');
// 2. 从内存加载模型
let msLiteModel = await mindSporeLite.loadModelFromBuffer(modelBuffer, context);
Logger.info('✅ 模型加载完成');
// 3. 获取模型输入张量
let modelInputs = msLiteModel.getInputs();
Logger.info(`📊 模型输入数量: ${modelInputs.length}`);
// 4. 填充输入数据
for (let i = 0; i < inputsBuffer.length; i++) {
modelInputs[i].setData(inputsBuffer[i]);
}
// 5. 执行推理 - 最关键的步骤
Logger.info('⚡ 开始执行推理...');
let modelOutputs = await msLiteModel.predict(modelInputs);
Logger.info('🎉 推理完成');
return modelOutputs;
}配置说明:
threadNum: 根据设备性能调整,2-4线程通常最佳threadAffinityMode: 1表示绑定大核,获得更好性能precisionMode:enforce_fp32保证精度,enforce_fp16提升速度
3.2 图像预处理:AI的"第一印象"
AI模型对输入数据格式有严格要求,预处理至关重要:
typescript
// ImageGenerate.ets中的预处理逻辑
// 1. 加载原始图像
const imageUri = this.croppedImageUri || this.photoUri;
let file = fileIo.openSync(imageUri, fileIo.OpenMode.READ_ONLY);
let imageSource = image.createImageSource(file.fd);
let pixelMap = imageSource.createPixelMapSync();
// 保存原始尺寸(后处理时需要)
const { width: originalWidth, height: originalHeight } = pixelMap.getImageInfoSync();
Logger.info(`📐 原始图像尺寸: ${originalWidth}x${originalHeight}`);
// 2. 缩放到模型输入尺寸
const scaleX = MODEL_INPUT_WIDTH / originalWidth;
const scaleY = MODEL_INPUT_HEIGHT / originalHeight;
pixelMap.scaleSync(scaleX, scaleY);
Logger.info(`🔍 缩放后尺寸: ${MODEL_INPUT_WIDTH}x${MODEL_INPUT_HEIGHT}`);
// 3. 读取像素数据(RGBA格式)
let readBuffer = new ArrayBuffer(MODEL_INPUT_HEIGHT * MODEL_INPUT_WIDTH * 4);
await pixelMap.readPixelsToBuffer(readBuffer);
const imageArr = new Uint8Array(readBuffer);
// 4. 归一化处理 - AI模型的标准输入格式
let float32View = new Float32Array(MODEL_INPUT_HEIGHT * MODEL_INPUT_WIDTH * 3);
// 归一化参数:减去均值,除以标准差
let means = [0.5, 0.5, 0.5]; // RGB三通道均值
let stds = [1.0, 1.0, 1.0]; // RGB三通道标准差
let index = 0;
for (let i = 0; i < imageArr.length; i++) {
if ((i + 1) % 4 === 0) { // 每4个字节是一个像素(RGBA)
// R通道归一化
float32View[index] = (imageArr[i - 3] / 255.0 - means[0]) / stds[0];
// G通道归一化
float32View[index + 1] = (imageArr[i - 2] / 255.0 - means[1]) / stds[1];
// B通道归一化
float32View[index + 2] = (imageArr[i - 1] / 255.0 - means[2]) / stds[2];
index += 3;
}
}
Logger.info(`🎯 归一化完成,数据长度: ${float32View.length}`);归一化公式详解:
normalized_value = (pixel_value / 255.0 - mean) / std这个步骤将像素值从0,255转换到模型期望的分布范围,是确保AI准确识别的关键。
3.3 执行推理:见证AI的力量

typescript
// 1. 加载模型文件
let resMgr = this.getUIContext().getHostContext()?.getApplicationContext().resourceManager;
const modelBuffer = resMgr.getRawFileContentSync(MODEL_NAME);
// 2. 准备输入数据
let inputs: ArrayBuffer[] = [float32View.buffer];
Logger.info(`📤 准备输入数据,数量: ${inputs.length}`);
// 3. 调用推理函数
let outputs = await modelPredict(modelBuffer.buffer.slice(0), inputs);
Logger.info('🤖 AI 推理成功');
// 4. 解析输出结果
let output: Float32Array = new Float32Array(outputs[0].getData());
Logger.info(`📥 获取到输出数据,长度: ${output.length}`);四、后处理:从概率到完美分割
4.1 阈值分割:人像与背景的界限
推理得到的是概率图,我们需要将其转换为实际的掩码:
typescript
const BLACKGROUND_THEADHOLD = 0.5;
// 创建结果数组
let resultArr = new Uint8Array(MODEL_INPUT_HEIGHT * MODEL_INPUT_WIDTH * 4);
let isHumanMask = new Array<boolean>(MODEL_INPUT_HEIGHT * MODEL_INPUT_WIDTH);
for (let i = 0; i < resultArr.length; i++) {
if ((i + 1) % 4 === 0) {
// 获取当前像素的分割概率
let segmentValue = output[(i + 1) / 4 - 1];
// 阈值判断:是否为人像区域
let isHuman = segmentValue > BLACKGROUND_THEADHOLD;
isHumanMask[(i + 1) / 4] = isHuman;
if (isHuman) {
// 人像区域:保留原始颜色,完全不透明
resultArr[i - 3] = imageArr[i - 3]; // R
resultArr[i - 2] = imageArr[i - 2]; // G
resultArr[i - 1] = imageArr[i - 1]; // B
resultArr[i] = 255; // A (255 = 不透明)
} else {
// 背景区域:设置为完全透明
resultArr[i - 3] = 0; // R
resultArr[i - 2] = 0; // G
resultArr[i - 1] = 0; // B
resultArr[i] = 0; // A (0 = 透明)
}
}
}
Logger.info('🎭 分割结果处理完成');4.2 可视化理解分割过程
原始图像 分割掩码 最终结果
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 🧑 │ │ 1 1 1 │ │ 🧑 │
│ │ ───> │ 1 1 1 │ ───> │ │
│ 🌳 │ │ 0 0 0 │ │ 透明 │
└─────────┘ └─────────┘ └─────────┘
实际图像 概率值矩阵 透明背景4.3 高级优化:边缘精细化

基础分割可能产生锯齿状边缘,我们可以通过图像处理技术进行优化:
typescript
/**
* 边缘羽化 - 创建平滑的过渡效果
*/
function featherEdge(
mask: Uint8Array,
width: number,
height: number,
featherRadius: number = 3
): Uint8Array {
const result = new Uint8Array(mask.length);
for (let y = 0; y < height; y++) {
for (let x = 0; x < width; x++) {
const idx = (y * width + x) * 4;
const isForeground = mask[idx + 3] > 128; // Alpha值判断
// 检查feather半径内的像素
let foregroundCount = 0;
let totalCount = 0;
for (let dy = -featherRadius; dy <= featherRadius; dy++) {
for (let dx = -featherRadius; dx <= featherRadius; dx++) {
const nx = x + dx;
const ny = y + dy;
if (nx >= 0 && nx < width && ny >= 0 && ny < height) {
const nIdx = (ny * width + nx) * 4;
if (mask[nIdx + 3] > 128) {
foregroundCount++;
}
totalCount++;
}
}
}
// 计算边缘过渡的Alpha值
const alphaRatio = foregroundCount / totalCount;
const originalAlpha = mask[idx + 3];
const smoothedAlpha = Math.min(255, originalAlpha * alphaRatio);
// 保留RGB,调整Alpha
result[idx] = mask[idx];
result[idx + 1] = mask[idx + 1];
result[idx + 2] = mask[idx + 2];
result[idx + 3] = smoothedAlpha;
}
}
return result;
}
// 应用边缘优化
const optimizedResult = featherEdge(resultArr, MODEL_INPUT_WIDTH, MODEL_INPUT_HEIGHT);五、性能优化与最佳实践
5.1 内存管理技巧
typescript
// 及时释放不再需要的内存
pixelMap.release();
imageSource.release();
fileIo.closeSync(file.fd);
// 大数组使用后设为null,帮助GC回收
imageArr = null;
float32View = null;5.2 异步处理防止UI卡顿
typescript
async processImageInBackground(): Promise<void> {
// 显示加载指示器
this.isProcessing = true;
try {
// 在后台线程执行耗时操作
await this.performAIPrediction();
// 回到UI线程更新结果
this.updateUIWithResult();
} catch (error) {
Logger.error(`处理失败: ${error.message}`);
} finally {
this.isProcessing = false;
}
}5.3 模型选择策略
| 模型类型 | 精度 | 速度 | 适用场景 |
|---|---|---|---|
| FP32模型 | 高 | 慢 | 专业图像处理 |
| FP16模型 | 中 | 中 | 移动端推荐 |
| INT8量化 | 较低 | 快 | 实时视频处理 |
六、实际应用与扩展
6.1 背景替换实现
typescript
function replaceBackground(
foreground: Uint8Array,
background: Uint8Array,
mask: Uint8Array,
width: number,
height: number
): Uint8Array {
const result = new Uint8Array(width * height * 4);
for (let i = 0; i < result.length; i += 4) {
const pixelIndex = i / 4;
const maskAlpha = mask[i + 3] / 255.0;
// 混合前景和背景
result[i] = foreground[i] * maskAlpha + background[i] * (1 - maskAlpha);
result[i + 1] = foreground[i + 1] * maskAlpha + background[i + 1] * (1 - maskAlpha);
result[i + 2] = foreground[i + 2] * maskAlpha + background[i + 2] * (1 - maskAlpha);
result[i + 3] = 255; // 完全不透明
}
return result;
}6.2 缩放回原始尺寸
typescript
// 将1024x1024的分割结果缩放回原始图像尺寸
function resizeToOriginal(
processedImage: Uint8Array,
originalWidth: number,
originalHeight: number
): Uint8Array {
// 创建临时PixelMap
let tempPixelMap = image.createPixelMapFromData(processedImage, {
size: {
width: MODEL_INPUT_WIDTH,
height: MODEL_INPUT_HEIGHT
}
});
// 缩放回原始尺寸
tempPixelMap.scaleSync(
originalWidth / MODEL_INPUT_WIDTH,
originalHeight / MODEL_INPUT_HEIGHT
);
// 读取缩放后的数据
let resultBuffer = new ArrayBuffer(originalWidth * originalHeight * 4);
await tempPixelMap.readPixelsToBuffer(resultBuffer);
return new Uint8Array(resultBuffer);
}总结与展望
通过本文的实践,我们成功在HarmonyOS应用中实现了端侧人像分割功能。整个流程包括:
- 环境配置:添加MindSpore Lite依赖,配置系统能力
- 模型准备:使用预训练的FP16量化模型
- 图像预处理:缩放、归一化,满足模型输入要求
- AI推理:调用MindSpore Lite执行模型推理
- 后处理:阈值分割、边缘优化,提升视觉效果
未来优化方向:
- 使用NPU硬件加速进一步提升性能
- 集成更多AI模型(手势识别、物体检测等)
- 实现实时视频流人像分割
- 添加用户自定义背景功能
端侧AI正在成为移动开发的新范式。随着硬件性能的提升和AI框架的优化,我们有理由相信,未来更多的AI能力将直接运行在用户的设备上,带来更智能、更安全、更便捷的移动体验。
相关资源:
互动话题:你在移动端AI开发中遇到过哪些挑战?欢迎在评论区分享你的经验和想法!