题目1

答案1
错误核心是没有对「科目」去重,导致统计的是「科目出现的次数」,而非题目要求的「科目种类的数量」。
错误原因拆解
题目中Teacher表的主键是(subject_id, dept_id)------这意味着:同一个教师(teacher_id)可能在不同部门(dept_id),教授同一个科目(subject_id)。
比如测试用例中teacher_id=1的记录:
| teacher_id | subject_id | dept_id |
|---|---|---|
| 1 | 2 | 3 |
| 1 | 3 | 4 |
| 1 | 2 | 3 |
此时subject_id是2、3、2,你的count(subject_id)会统计为3,但实际科目种类只有2、3这2种 ------所以需要用count(distinct subject_id)来统计「唯一的科目数量」。
正确的SQL语句
sql
SELECT
teacher_id,
COUNT(DISTINCT subject_id) AS cnt -- 用DISTINCT对科目去重,统计种类数
FROM Teacher
GROUP BY teacher_id;验证示例(对应测试用例)
以teacher_id=1为例:
DISTINCT subject_id会把重复的2去重,得到唯一科目是2、3,共2个;COUNT(DISTINCT subject_id)结果为2,和题目预期结果一致。
总结
当题目要求统计「种类/唯一数量」时,必须用COUNT(DISTINCT 字段)------它会自动过滤字段的重复值,只统计不同值的数量;而普通的COUNT(字段)统计的是「字段出现的总次数」(包含重复)。
题目2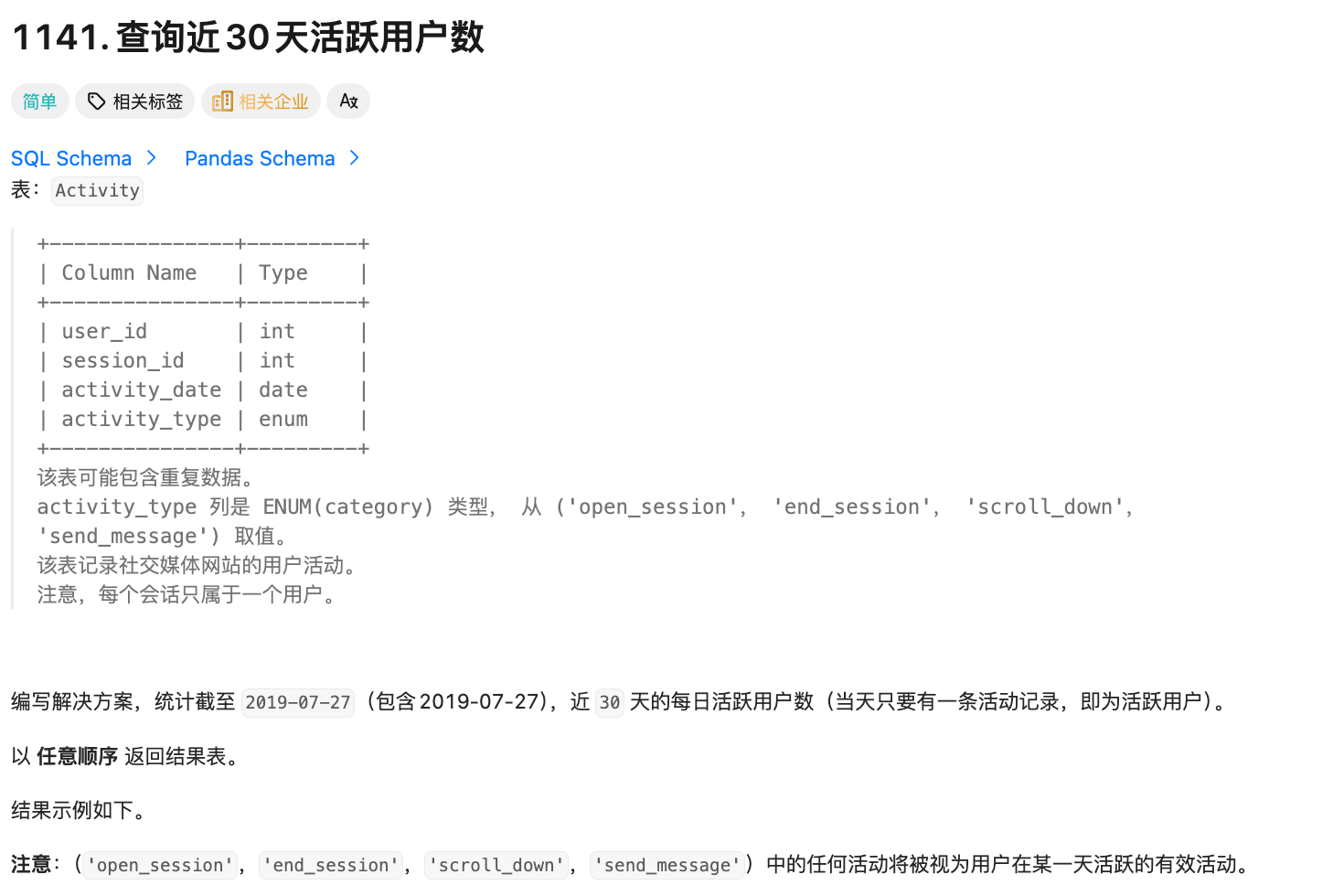

答案2
要解决这道题,核心是筛选时间范围+按日期分组+去重统计活跃用户
第一步:明确题目核心要求
需要统计 截至2019-07-27(包含当天)近30天 的每日活跃用户数:
- 「近30天」:时间范围是
2019-06-28 ~ 2019-07-27(因为包含27日,所以往前推29天)。 - 「活跃用户」:当天只要有活动记录,该用户算1个(即使当天有多个活动,也只算1次,所以需要对
user_id去重)。
第二步:count(activity_type is not null) as active_users 的问题:
- 没有去重:同一个用户当天可能有多个活动(比如多次scroll_down),会被重复计数;
- 没有时间筛选:会统计所有日期,而非近30天;
- 没有按日期分组:无法得到"每日"的活跃数。
第三步:正确的SQL语句
sql
SELECT
activity_date AS day, -- 日期列命名为day(匹配示例输出)
COUNT(DISTINCT user_id) AS active_users -- 对user_id去重,统计当日活跃用户数
FROM Activity
-- 筛选近30天的记录(截至2019-07-27,包含当天)
WHERE activity_date BETWEEN DATE_SUB('2019-07-27', INTERVAL 29 DAY) AND '2019-07-27'
GROUP BY activity_date; -- 按日期分组,统计每日数据逐句解释
-
时间筛选(WHERE子句):
DATE_SUB('2019-07-27', INTERVAL 29 DAY):计算出近30天的起始日期(2019-06-28);BETWEEN ... AND ...:限定活动日期在近30天内。
-
按日分组(GROUP BY):
- 按
activity_date分组,才能得到"每日"的统计结果。
- 按
-
去重计数(COUNT(DISTINCT)):
COUNT(DISTINCT user_id):同一个用户当天的多个活动只算1次,准确统计"活跃用户数"(而不是活动记录数)。
验证示例(假设数据)
比如某用户在2019-07-27有2条活动记录,COUNT(DISTINCT user_id)会把他算1个活跃用户,而普通的COUNT(activity_type)会算2次,这正是题目要求的"当天只要有一条活动记录,即为活跃用户"。
题目3
答案3
错误1:日期比较的语法不合法
MySQL不支持 2019-01-01<=sales.sale_date<=2019-03-31 这种连续比较写法 ,必须拆成 AND 连接的两个条件:
sql
-- 正确写法
sales.sale_date >= '2019-01-01' AND sales.sale_date <= '2019-03-31'错误2:未满足"仅在春季销售"的核心要求
题目要求是「仅在2019-01-01至2019-03-31之间出售 的商品」------ "2019-01-01<=sales.sale_date<=2019-03-31"只筛选了"春季有销售"的商品,但没排除「春季外也有销售」的商品。
比如测试数据中的 product_id=3(iPhone):
它在 2019-05-15(春季外)有销售记录,但你的SQL只查了春季的销售,没检查它是否在其他时间段也有销售,所以错误地把它包含进了结果。
正确的SQL逻辑(两步筛选)
要找到「仅在春季销售」的商品,需要先排除「在春季外有销售」的商品,再关联商品表:
sql
SELECT
p.product_id,
p.product_name
FROM Product p
-- 关联"仅在春季有销售"的商品ID
JOIN (
-- 子查询:找出所有销售记录都在春季的商品ID
SELECT product_id
FROM Sales
GROUP BY product_id
-- 条件:该商品的所有销售日期都在春季范围内
HAVING MIN(sale_date) >= '2019-01-01'
AND MAX(sale_date) <= '2019-03-31'
) s ON p.product_id = s.product_id;HAVING 是专门配合 GROUP BY 使用的**「分组后过滤」关键字**,它的核心作用只有一个:
对「分组聚合后的结果」进行筛选,只保留符合条件的分组。
它的3个关键特性必须记住:
- 执行时机晚 :在
GROUP BY(分组)、聚合函数计算(如MIN/MAX/COUNT)之后执行; - 作用于分组:过滤的是「整个分组」,而不是单条原始数据;
- 支持聚合函数 :可以直接在条件里用
COUNT()、SUM()、MIN()、MAX()等聚合函数(这是和WHERE最大的区别)。
简单说:WHERE 管「原始行」,HAVING 管「分组结果」。
| 对比维度 | WHERE | HAVING |
|---|---|---|
| 执行时机 | 分组(GROUP BY)之前 | 分组(GROUP BY)之后 |
| 作用对象 | 单条原始数据行 | 分组后的聚合结果(整个分组) |
| 能否用聚合函数 | 绝对不能(会直接报错) | 可以(核心能力) |
| 使用场景 | 过滤不需要的原始行(如筛选日期、性别) | 过滤分组结果(如筛选"总销量>100"的分组) |
举个最直观的小例子:
统计「每个部门的员工数」,并筛选出「员工数>5的部门」:
sql
SELECT dept_id, COUNT(*) AS emp_count
FROM employee
WHERE salary > 5000 -- 第一步:WHERE先过滤原始行(只留月薪>5000的员工)
GROUP BY dept_id -- 第二步:按部门分组,统计每组人数
HAVING COUNT(*) > 5; -- 第三步:HAVING过滤分组(只留人数>5的部门)这里WHERE筛的是「单个员工」,HAVING筛的是「整个部门分组」,分工明确。
题目要求:找出「仅在2019年春季(1-3月)销售」的商品 。
翻译一下这个需求的核心逻辑:
对每个商品(分组),检查它的「所有销售记录」的最早日期和最晚日期,是否都在春季范围内。
1. 为什么WHERE做不到?
WHERE 是在分组前 过滤单条原始销售记录,它只能做到:
「筛选出春季的销售记录」,但无法判断这个商品「有没有春季外的销售记录」。
比如你用WHERE写:
sql
SELECT product_id
FROM Sales
WHERE sale_date BETWEEN '2019-01-01' AND '2019-03-31'
GROUP BY product_id;这个SQL只会保留「春季有销售」的记录,但如果一个商品(比如iPhone)在5月也有销售,WHERE只是把5月的记录删掉了,剩下的春季记录还会被分组,导致iPhone被错误保留------WHERE根本没机会看到这个商品的全部销售记录,更没法判断"是否仅春季销售"。
而且,WHERE里绝对不能写MIN(sale_date)或MAX(sale_date),因为聚合函数是分组后才计算的,WHERE执行时还没分组,用了直接报错。
2. 为什么HAVING可以做到?
HAVING 是在分组后 执行,此时已经按product_id分好组,且计算出了每个商品的MIN(sale_date)(最早销售日)和MAX(sale_date)(最晚销售日)。
这时候用HAVING判断:
sql
HAVING MIN(sale_date) >= '2019-01-01' AND MAX(sale_date) <= '2019-03-31'就是对「每个商品分组」做检查:
- 最早销售日不早于1月1日,最晚销售日不晚于3月31日 → 说明这个商品的所有销售都在春季,符合要求,保留分组;
- 否则(比如最晚销售日是5月),不符合要求,直接丢弃分组。
用这个写法,测试数据中的 product_id=3(iPhone)会被排除(因为它的MAX(sale_date)=2019-05-15>2019-03-31),最终结果只会保留"仅在春季销售"的商品,和预期一致。
题目4

答案4
sql
select class
from Courses
group by class
having count(student)>=5题目5
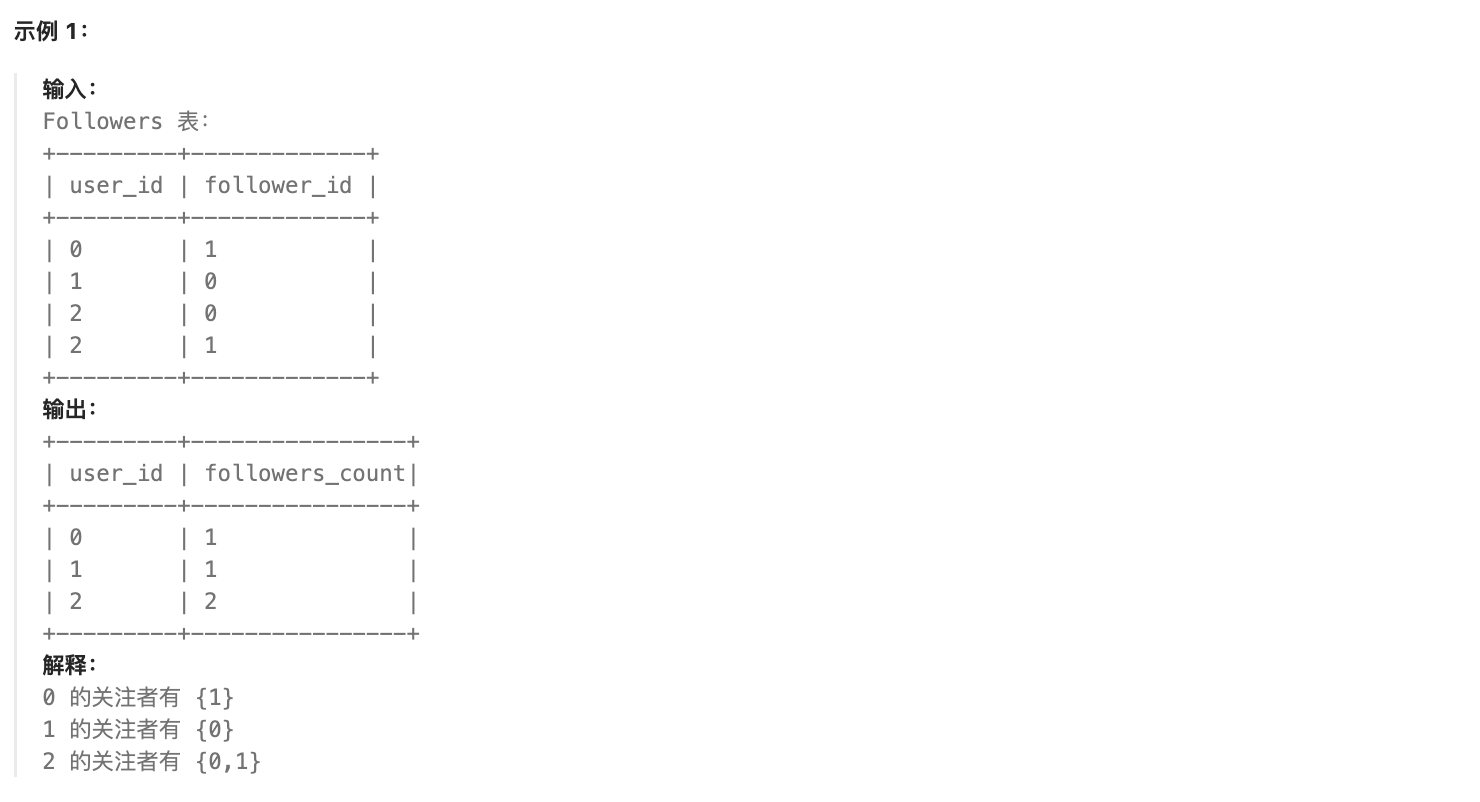
答案5
sql
SELECT user_id, COUNT(follower_id) AS followers_count -- SELECT后的聚合
FROM Followers
GROUP BY user_id
HAVING COUNT(follower_id) -- HAVING后的聚合先明确:分组(GROUP BY user_id)后,每个 user_id 是一个「分组」 (比如 user_id=0 是一个分组,user_id=1 是另一个分组)。
1. SELECT 后面的聚合函数:COUNT(follower_id) AS followers_count
它的作用是:对每个分组,计算聚合值(这里是统计该用户的粉丝数),并把这个值作为「结果列」展示出来。
对应你的例子:
- 分组
user_id=0:follower_id 有 1 个 →COUNT计算得 1 → 结果列followers_count显示 1; - 分组
user_id=1:follower_id 有 2 个 →COUNT计算得 2 → 结果列followers_count显示 2;
简单说:SELECT 后的聚合是「给分组算个结果,然后把结果展示出来」。
2. HAVING 后面的聚合函数:COUNT(follower_id)
它的作用是:对分组的聚合结果做「条件判断」,决定这个分组要不要保留(只有符合条件的分组,才会出现在最终结果里)。
但上述的写法里 HAVING COUNT(follower_id) 是不完整的 (缺了判断条件,比如 >1),所以相当于"没有筛选条件",所有分组都会保留(这也是你的 SQL 能通过的原因,但 HAVING 在这里是多余的)。
如果补全条件(比如筛选「粉丝数>1的用户」),HAVING 的作用就明显了:
sql
SELECT user_id, COUNT(follower_id) AS followers_count
FROM Followers
GROUP BY user_id
HAVING COUNT(follower_id) > 1 -- 只保留粉丝数>1的分组此时:
user_id=0的分组:粉丝数=1 → 不满足>1→ 被丢弃;user_id=1的分组:粉丝数=2 → 满足条件 → 保留;
简单说:HAVING 后的聚合是「给分组的结果设个门槛,不符合的分组直接扔掉」。
二、核心区别总结(一句话分清)
| 位置 | 作用 | 执行时机 | 例子(筛选粉丝数>1的用户) |
|---|---|---|---|
| SELECT 后 | 计算分组的聚合值,展示结果 | 分组+聚合后,最终展示时 | COUNT(follower_id) AS followers_count(展示每个用户的粉丝数) |
| HAVING 后 | 用聚合值判断,筛选分组 | 分组+聚合后,展示前筛选 | COUNT(follower_id) > 1(只留粉丝数>1的用户分组) |
三、补充:为什么上述写法 HAVING 写了但没影响?
因为上述写法没加「判断条件」(比如 >1/<3),所以 HAVING COUNT(follower_id) 等价于"所有分组都满足条件",自然不会过滤任何数据------但实际写 SQL 时,HAVING 必须搭配「条件判断」才有意义,否则可以删掉。
用例子再简化记忆:
- 想看每个用户有多少粉丝 → 用 SELECT 后的
COUNT计算并展示; - 想只看粉丝数超过1的用户 → 加 HAVING 后的
COUNT > 1筛选分组。
正确答案
sql
SELECT
user_id,
COUNT(follower_id) AS followers_count -- 统计每个用户的粉丝数
FROM Followers
GROUP BY user_id -- 按用户ID分组,确保每个用户一行结果
ORDER BY user_id ASC; -- 按用户ID升序排列(题目要求)题目6

答案6
正确思路拆解
题目要求:
- 先筛选出「只出现1次的数字」(即分组后
COUNT(num)=1的num); - 再从这些数字中找「最大值」;
- 若没有符合条件的数字,返回
null。
正确SQL语句
sql
SELECT MAX(num) AS num
FROM (
-- 子查询:筛选出只出现1次的数字
SELECT num
FROM MyNumbers
GROUP BY num
HAVING COUNT(num) = 1 -- 只保留出现次数=1的分组
) AS single_nums;错误大赏
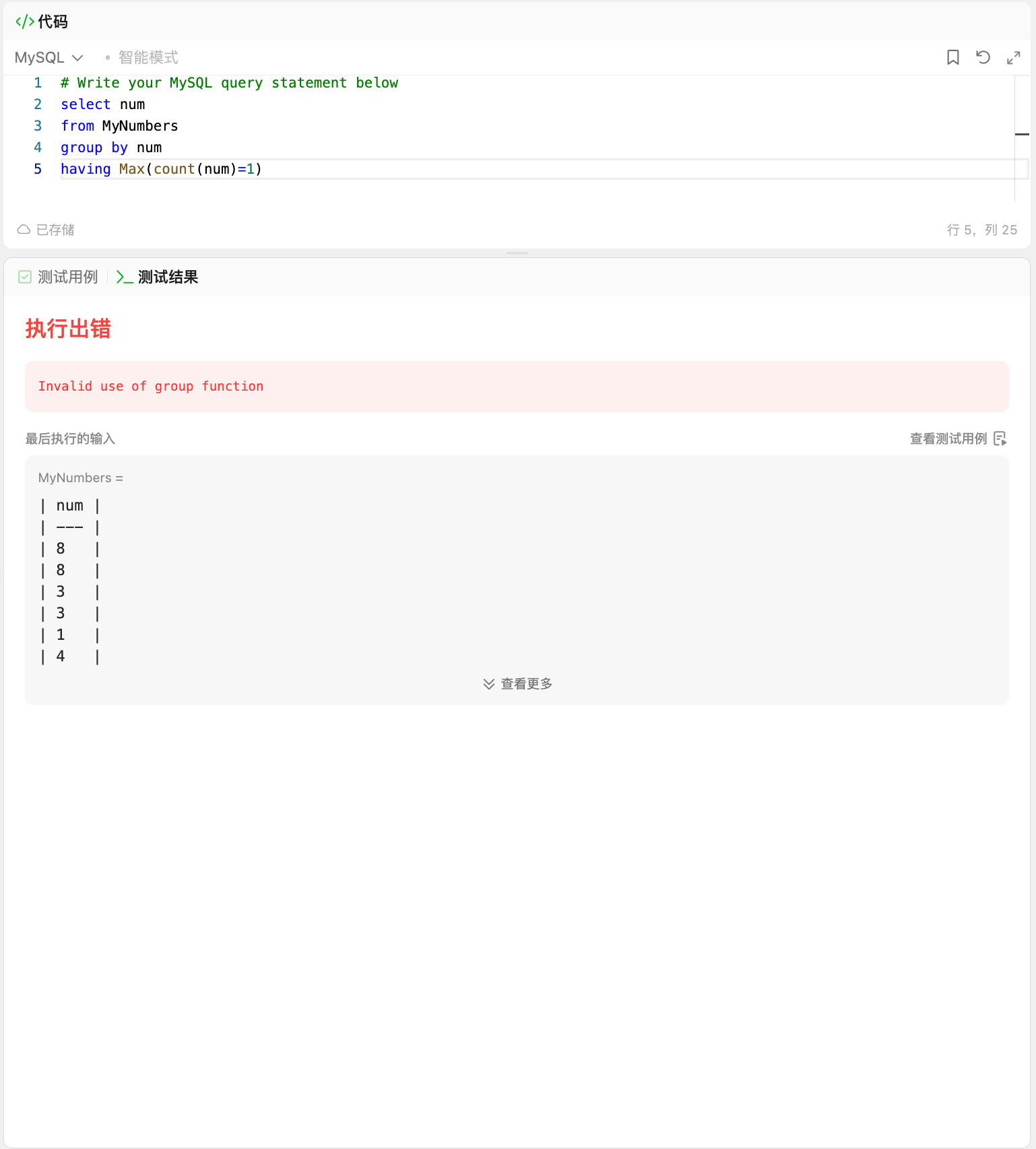
规则1:写在 SELECT 后面 → 为了「展示结果」
需要把「分组后的聚合值」当成一列数据,显示在最终查询结果里 ,就放 SELECT 后。
简单说:想看到这个聚合数,就放SELECT。
规则2:写在 HAVING 后面 → 为了「筛选分组」
需要用「分组后的聚合值」当条件,只保留符合条件的分组 ,就放 HAVING 后。
简单说:想用这个聚合数挑分组,就放HAVING。
例子1:统计每个用户的粉丝数
需求:展示每个用户的粉丝数,按用户ID排序(没有筛选需求)。
- 只需要「展示粉丝数」→ 聚合放
SELECT后; - 不需要「筛选分组」→ 不用写
HAVING。
sql
SELECT
user_id,
COUNT(follower_id) AS followers_count -- 规则1:展示粉丝数,放SELECT
FROM Followers
GROUP BY user_id
ORDER BY user_id;例子2:筛选「粉丝数>1」的用户(加筛选需求)
需求:只展示粉丝数超过1的用户,同时显示他们的粉丝数。
- 既要「展示粉丝数」→ 聚合放
SELECT后; - 又要「用粉丝数筛选分组」→ 同一个聚合再放
HAVING后。
sql
SELECT
user_id,
COUNT(follower_id) AS followers_count -- 规则1:展示粉丝数
FROM Followers
GROUP BY user_id
HAVING COUNT(follower_id) > 1; -- 规则2:用粉丝数筛选分组(只留>1的)例子3:找「只出现1次的最大数字」(上一题)
需求:① 先筛选「出现次数=1」的数字;② 再展示这些数字的最大值。
- 第一步:用「出现次数」筛选分组 → 聚合
COUNT(num)放HAVING后; - 第二步:用「最大值」展示结果 → 聚合
MAX(num)放SELECT后。
sql
SELECT MAX(num) AS num -- 规则1:展示最大数,放SELECT
FROM (
SELECT num
FROM MyNumbers
GROUP BY num
HAVING COUNT(num) = 1 -- 规则2:用出现次数筛选分组(只留=1的)
) AS single_nums;例子4:找「仅春季销售的商品」(之前的题)
需求:① 筛选「所有销售都在春季」的商品分组;② 展示商品ID和名称。
- 用「最早/最晚销售日期」筛选分组 → 聚合
MIN/MAX(sale_date)放HAVING后; - 不需要展示聚合值 →
SELECT后不放聚合。
sql
SELECT p.product_id, p.product_name -- 只展示商品信息,不放聚合
FROM Product p
JOIN Sales s ON p.product_id = s.product_id
GROUP BY p.product_id, p.product_name
HAVING MIN(sale_date) >= '2019-01-01'
AND MAX(sale_date) <= '2019-03-31'; -- 规则2:用销售日期范围筛选分组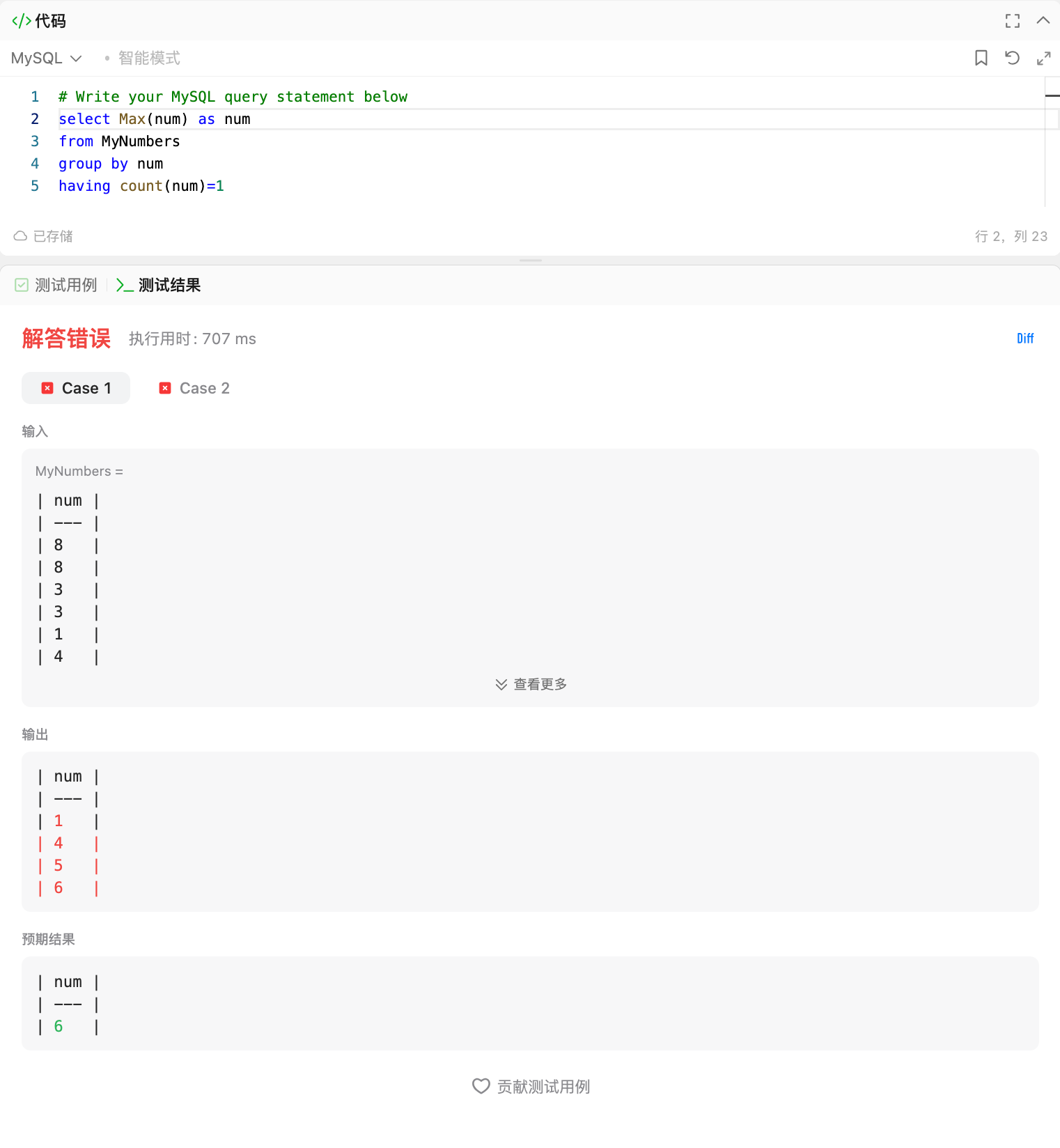
错误核心是:GROUP BY num 后直接用 MAX(num),得到的是「每个符合条件分组的自身值」,而不是「所有符合条件分组的最大值」。
错误逻辑拆解
当前的SQL执行流程是:
GROUP BY num→ 按num分组(比如输入中的num=8是一个分组、num=3是一个分组、num=1是一个分组......);HAVING COUNT(num)=1→ 筛选出「出现次数=1」的分组(比如num=1、num=4、num=6这些分组);SELECT MAX(num)→ 对每个分组 取MAX(num)(但每个分组只有一个num,所以MAX(num)就是分组自己的num)。
最终结果会输出所有出现次数=1的num(比如测试用例中会输出1、4、6),但题目要求的是「这些数中的最大值」(即6),所以你的写法没实现"取最大值"的逻辑。
正确逻辑:用子查询先筛选,再取最大值
需要先把「出现次数=1的所有num」放到一个临时表,再对这个临时表取MAX(),才能得到这些数的最大值:
sql
SELECT MAX(num) AS num
FROM (
-- 子查询:先筛选出所有出现次数=1的num
SELECT num
FROM MyNumbers
GROUP BY num
HAVING COUNT(num) = 1
) AS single_nums; -- 临时表:存储所有"只出现1次的num"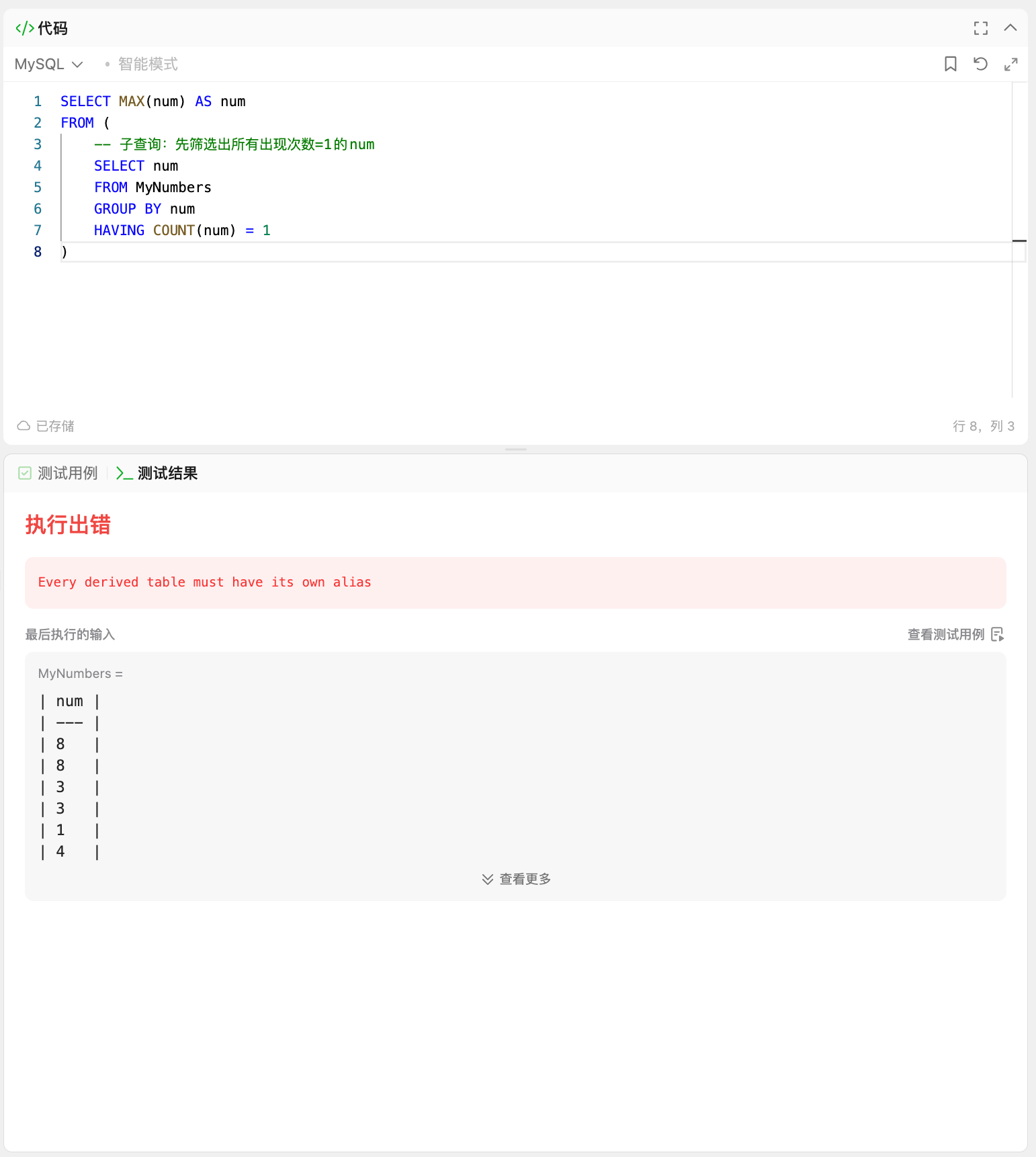
一、必须加 AS 别名的唯一场景:子查询放在 FROM 后面(派生表)
当子查询作为数据源 ,放在 FROM 关键字后面时,这个子查询会生成一个「临时结果表」,SQL 语法要求必须给这个临时表起一个别名(用 AS 或直接写别名都可以),否则会直接报错。
这就是你这道题必须加 AS single_nums 的原因!
正确(必须加别名)
sql
SELECT MAX(num) AS num
FROM (
SELECT num FROM MyNumbers GROUP BY num HAVING COUNT(num)=1
) AS single_nums; -- FROM后的子查询,必须加别名错误(去掉别名,语法报错)
sql
SELECT MAX(num) AS num
FROM (
SELECT num FROM MyNumbers GROUP BY num HAVING COUNT(num)=1
); -- 报错:Every derived table must have its own alias(每个派生表必须有别名)二、90%的场景:子查询不需要加 AS 别名
除了 FROM 后面的子查询,其他所有位置的子查询(SELECT、WHERE、HAVING 里),都不需要加别名,加了反而多余。
场景1:WHERE 里的子查询(IN/EXISTS/标量子查询)
最常用的场景,直接写子查询即可,无需别名:
sql
-- 例:筛选出有销售记录的商品(子查询在WHERE里,无别名)
SELECT product_name FROM Product
WHERE product_id IN (
SELECT product_id FROM Sales -- 子查询无别名,完全正确
);场景2:SELECT 里的标量子查询(返回单个值)
sql
-- 例:查询每个用户的粉丝数,同时显示总用户数(子查询在SELECT里,无别名)
SELECT
user_id,
COUNT(follower_id) AS followers_count,
(SELECT COUNT(DISTINCT user_id) FROM Followers) AS total_users -- 子查询无别名
FROM Followers
GROUP BY user_id;场景3:HAVING 里的子查询
sql
-- 例:筛选粉丝数超过平均粉丝数的用户(子查询在HAVING里,无别名)
SELECT user_id, COUNT(follower_id) AS followers_count
FROM Followers
GROUP BY user_id
HAVING COUNT(follower_id) > (
SELECT AVG(followers_count) FROM (
SELECT COUNT(follower_id) AS followers_count FROM Followers GROUP BY user_id
) AS t -- 只有这个FROM后的子查询需要别名,外层HAVING里的子查询不需要
);三、一句话总结(记这个就够了)
- 子查询在
FROM后面 → 必须加AS 别名(因为它是临时表,需要名字); - 子查询在
SELECT/WHERE/HAVING后面 → 绝对不需要加别名(加了也没用,语法不要求)。