书接上回,上一部分我们学习了逻辑回归基础,将信用卡数据集构建了逻辑回归模型,但是,我们构建的模型还有非常多的地方可以优化,这一篇就来介绍如何提高逻辑回归模型的准确率。
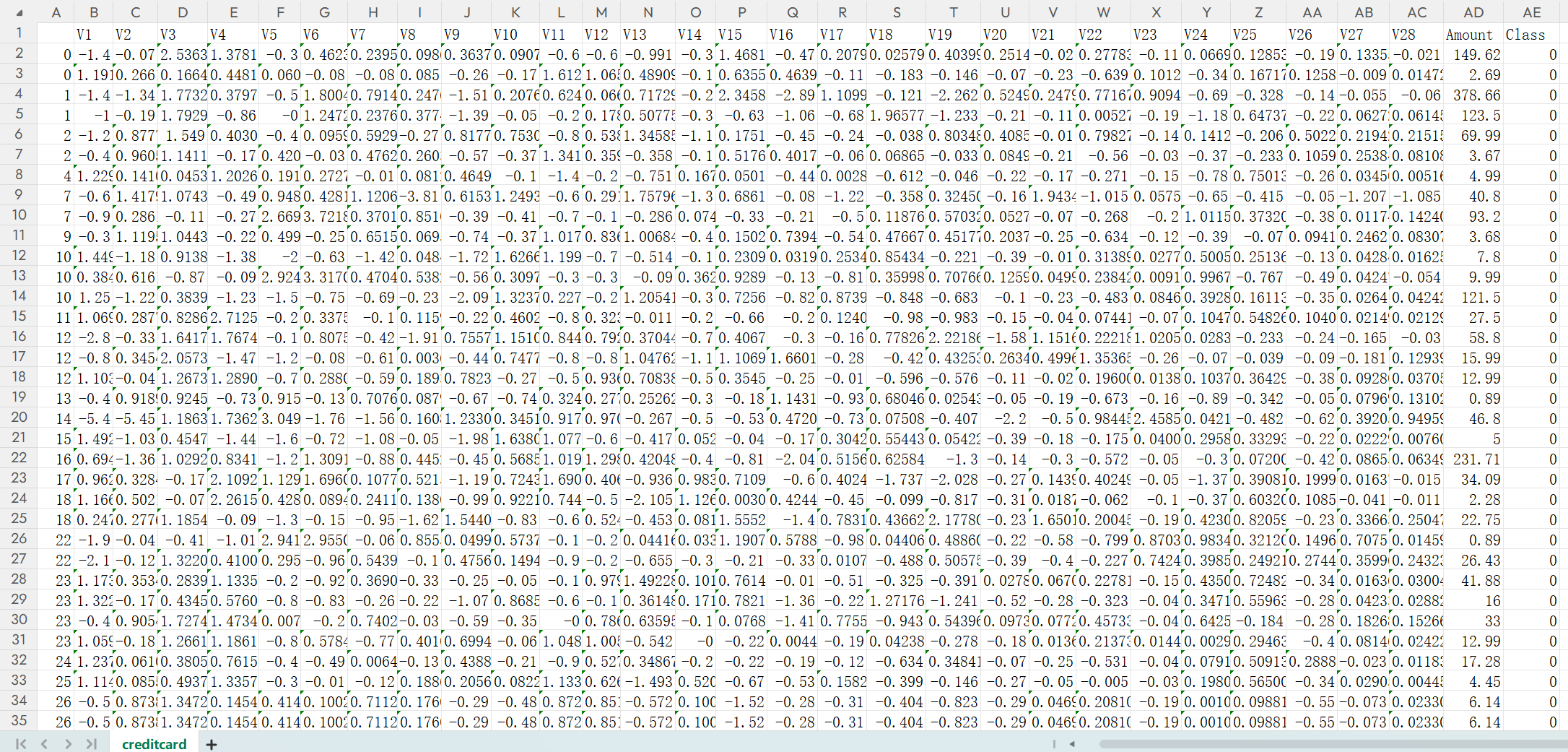
这是之前的银行信用卡数据集,下面是构建最基础的模型代码,接下来我们就需要在这之上进行优化。
import pandas as pd
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from pylab import mpl
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
data = pd.read_csv("creditcard.csv")
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'], axis=1)
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
labels_count = data['Class'].value_counts()
print("正负例样本数量:")
print(labels_count)
plt.title("正负例样本数")
plt.xlabel("类别")
plt.ylabel("频数")
ax = labels_count.plot(kind='bar')
for bar in ax.patches:
count = int(bar.get_height())
x = bar.get_x() + bar.get_width() / 2
y = bar.get_height() + 500
ax.text(x, y, str(count), ha='center', va='bottom', fontsize=10, fontweight='bold')
plt.tight_layout()
plt.show()
X_whole = data.drop('Class', axis=1)
y_whole = data['Class']
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(
X_whole, y_whole, test_size=0.3, random_state=1000
)
lr = LogisticRegression(C=0.01, max_iter=1000)
lr.fit(x_train_w, y_train_w)
test_predicted = lr.predict(x_test_w)
train_predicted = lr.predict(x_train_w)
print("\n测试集准确率:", lr.score(x_test_w, y_test_w))
print("\n训练集分类报告:")
print(metrics.classification_report(y_train_w, train_predicted))
print("\n测试集分类报告:")
print(metrics.classification_report(y_test_w, test_predicted))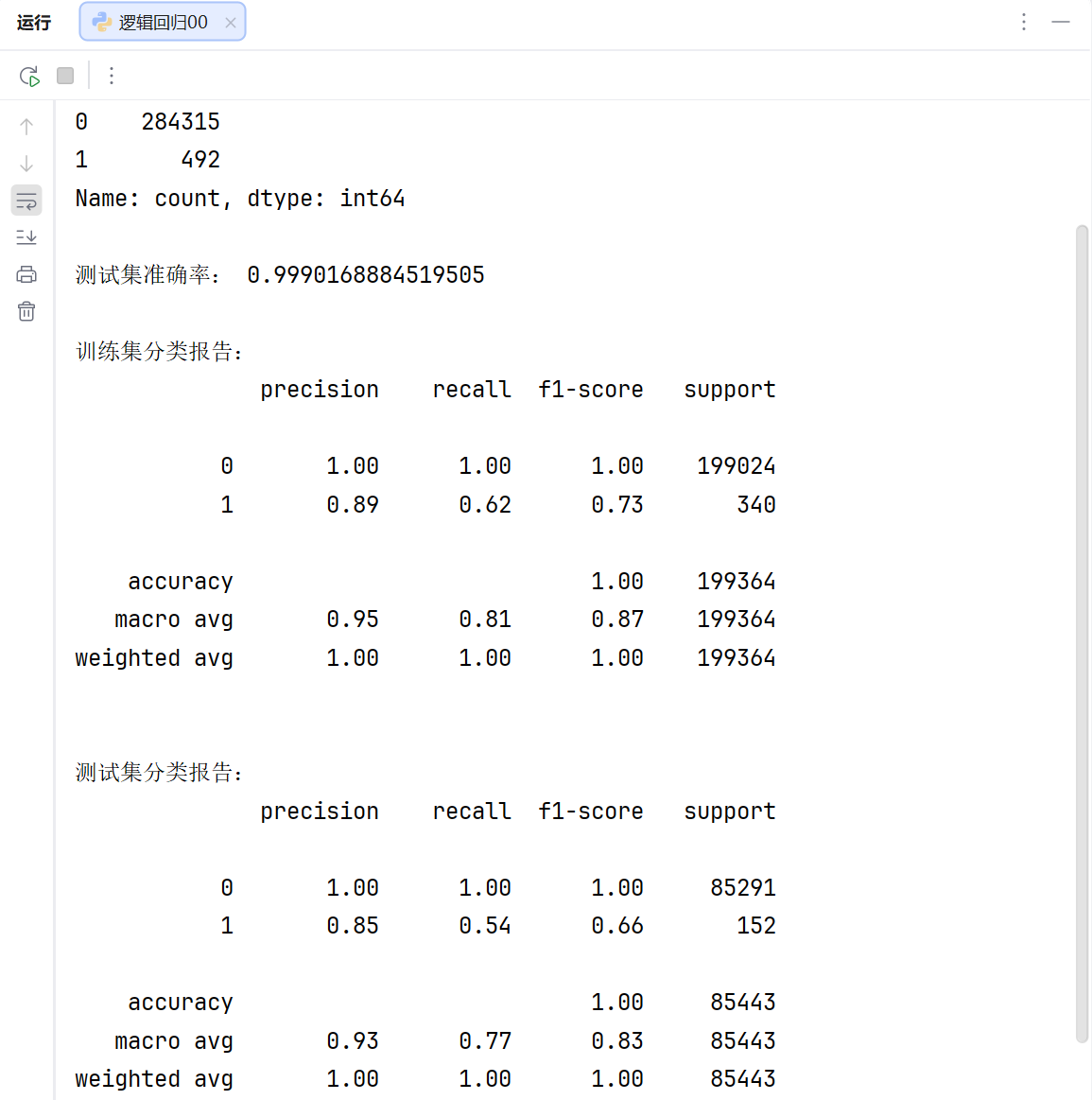
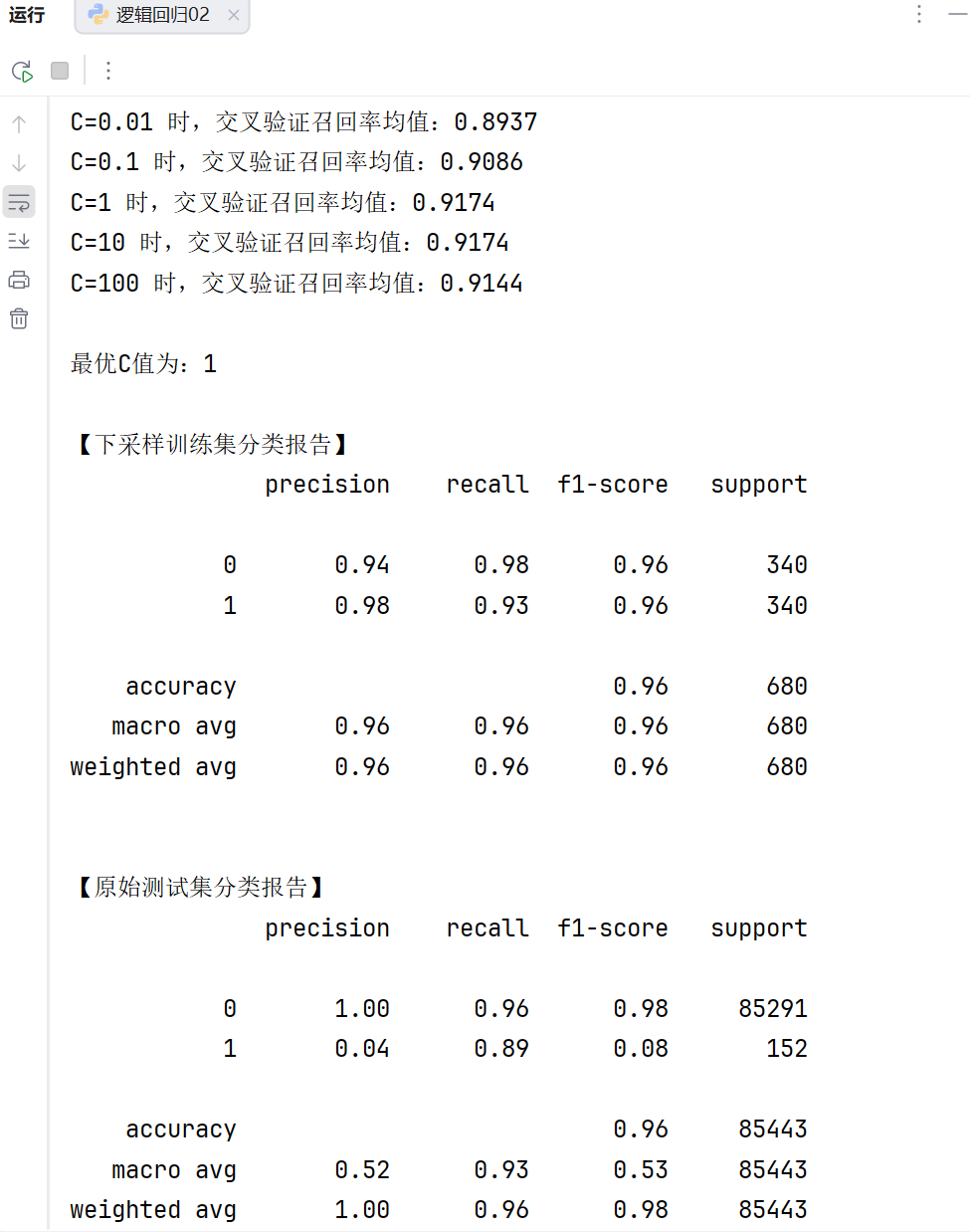
1.调整参数C
我们注意到了测试集准确率已经达到了99.9016%了,但是模型的召回率(recall)非常的低,训练集只有0.62,测试集只有0.54,那么我们模型第一步就可以调整模型的参数c,设置不同的参数进行训练,最后找到最合适的参数。
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:
lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000)
score = cross_val_score(lr, x_train_w, y_train_w, cv=8, scoring='recall')
score_mean = sum(score) / len(score)
scores.append(score_mean)
print(f"C={i} 时,交叉验证召回率均值:{score_mean:.4f}")
best_c = c_param_range[scores.index(max(scores))]
print(f"\n最优C值为:{best_c}")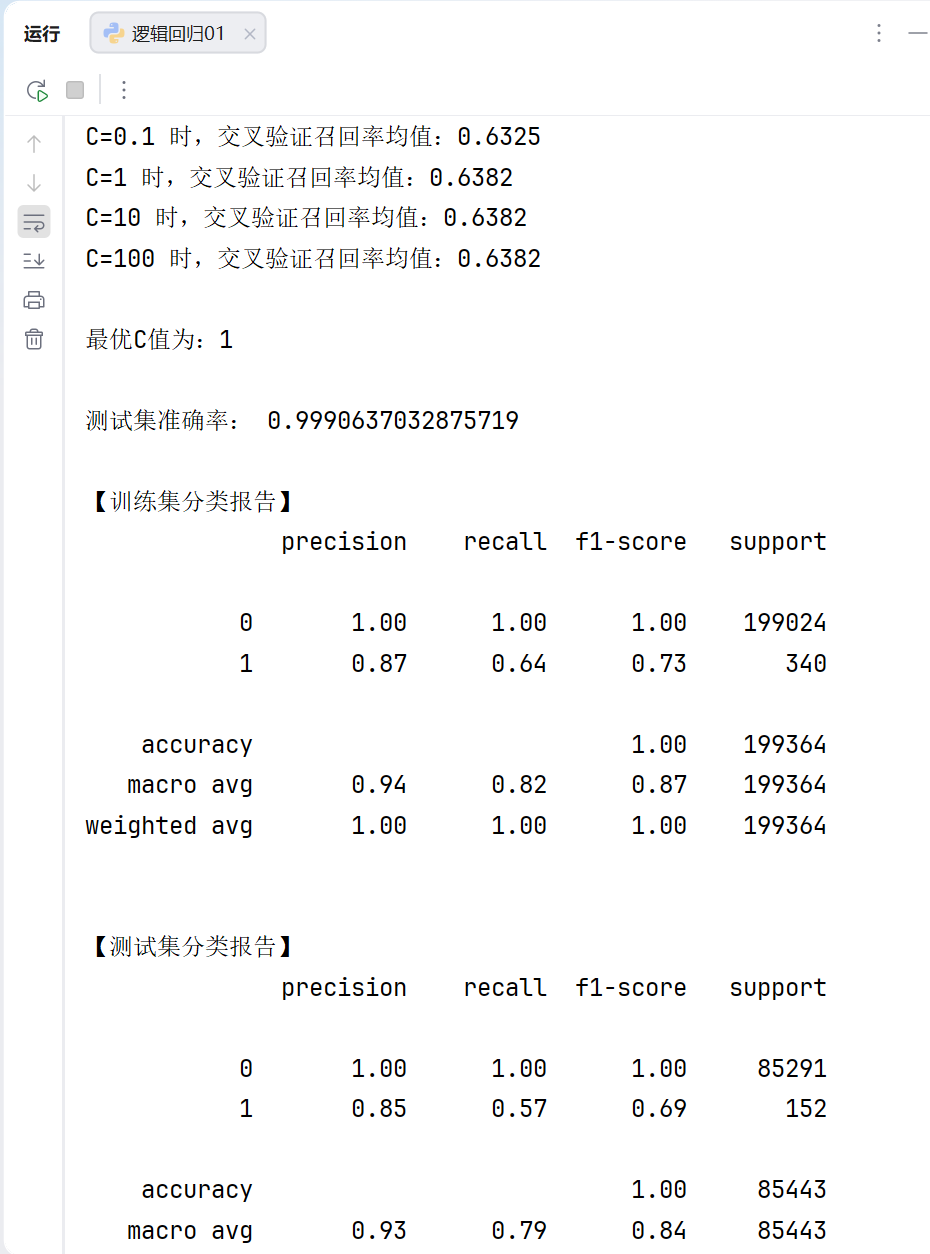
这里我们可以看到,当参数C为1时,我们模型的召回率最高,但是这个模型的召回率还是非常低。那么我们下一步怎么办?
2.调整数据不平衡
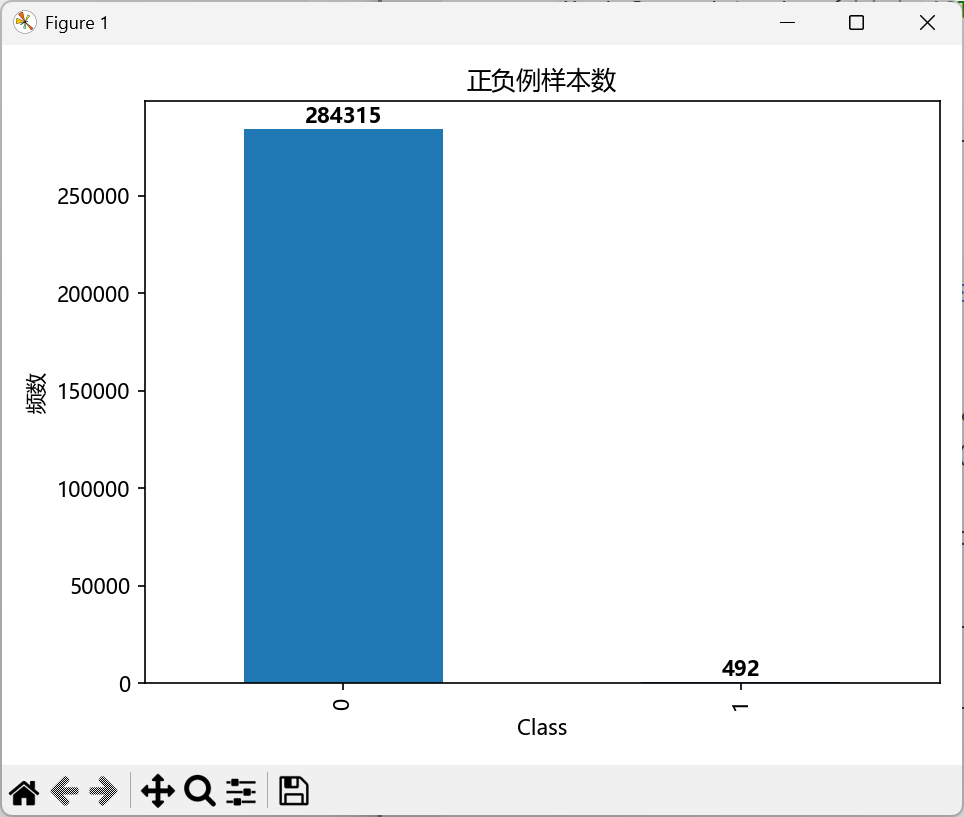
由上图我们可以直观的看出,这个数据非常的不平衡,标签为0的样本有28万条,而标签为1的只有492条,如此悬殊的差距导致我们模型的召回率非常的不理想。
所以我们可以通过下采样法将数据平衡
由此可以看出模型通过下采样将数据平衡以后,模型的召回率一下子从0.6提高到0.9,如此所构建的模型才算是构建的比较成功。
日记
2月6日,星期五
我可真是天才
今天下午有人问我:电脑上面下载的MP3音频到u盘上,在音响里面就放不出来了

那肯定要去问万能的豆包了。

然后我看了一下音频属性,果然格式不对。
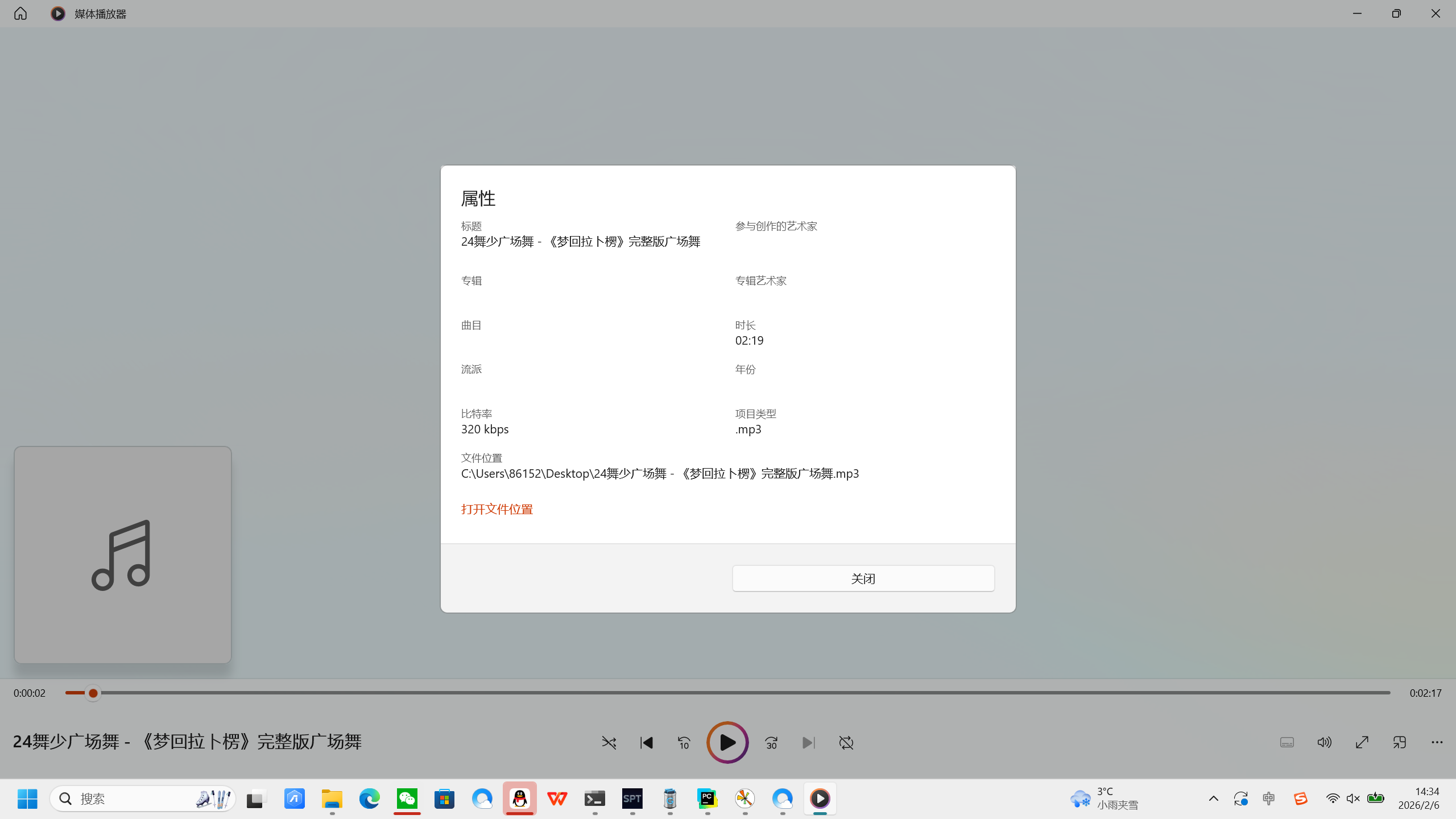
然后就是将音频格式更改过来
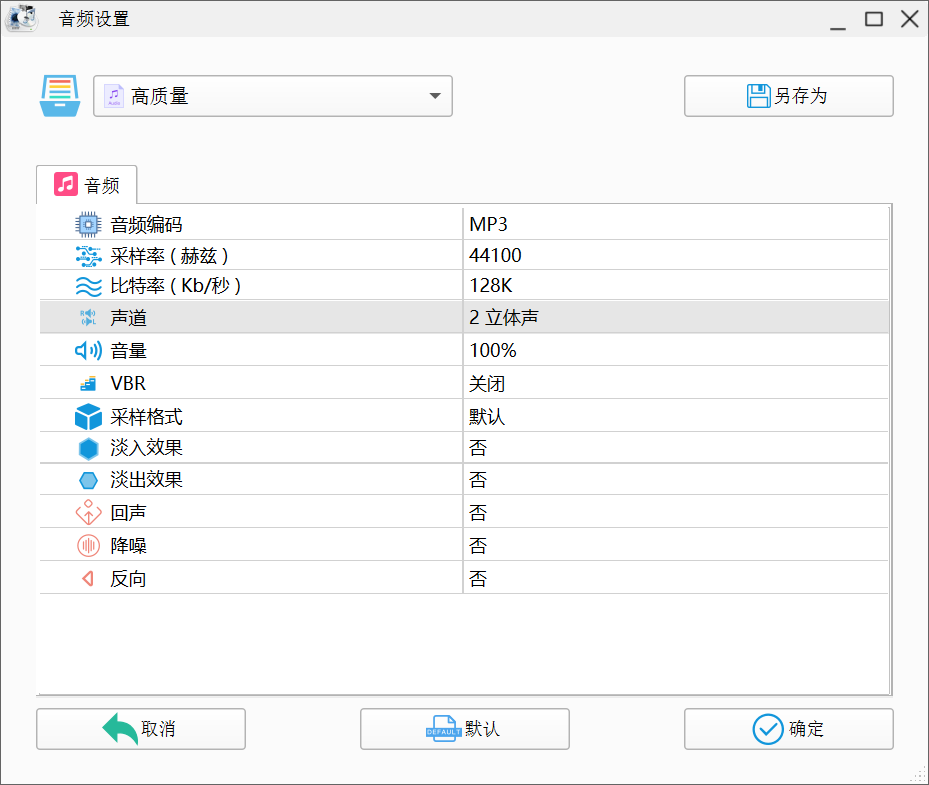
果然,改完格式以后马上就能在放广场舞的音响上面放了。
我果然是天才。
顺带一提,下载的格式工厂这个就是个流氓,我突然桌面莫名其妙的多了一个桌面优化大师,但是我是什么人,直接给你注册表都删的干干净净,骨灰都不剩。