Windows 环境下强制编译 Flash Attention:绕过 CUDA 版本不匹配高阶指南
你需要为博客写一段 Flash Attention 的简介,我会兼顾通俗性 和专业性,既让非技术读者理解核心价值,也让技术读者get到关键亮点,适合放在博客开篇或核心概念解读部分:
我为你整合并提炼了Flash Attention核心内容的高光版,精简后保留核心价值、关键优势和团队亮点,语言更紧凑,适合博客正文(约500字),既专业又易读:
前言
Flash Attention:让大模型注意力计算"又快又省"的核心技术
注意力机制是大语言模型(LLM)、视觉Transformer的核心,但传统计算模式存在 O ( n 2 ) O(n^2) O(n2)的高时间复杂度和显存爆炸问题,长文本处理时常因显存不足无法运行。2022年,斯坦福/DAO-AILab的Tri Dao团队提出的Flash Attention(闪存注意力),成为解决这一痛点的革命性优化技术------它不改变注意力的数学逻辑,而是通过硬件感知的算法设计,重构GPU内存访问路径,实现了效率与精度的双重突破。
核心优势:
- 显存骤降 :通过"分块计算+重计算"策略,显存占用从 O ( n 2 ) O(n^2) O(n2)降至 O ( n ) O(n) O(n),支持数万甚至十万长度的长序列处理(如GPT-4长上下文);
- 速度提升:优化GPU显存(HBM)与片上缓存(SRAM)的数据传输,同等硬件下计算速度提升2-4倍;
- 精度无损:区别于近似注意力算法,Flash Attention保持精确计算,兼顾效率与准确性。
如今它已成为大模型标配:PyTorch/TensorFlow等框架已集成接口,GPT-3、LLaMA等模型均采用该技术,普通GPU(如RTX 3090/A100)也能高效运行长序列任务。后续迭代的FlashAttention-2/3及FlashDecoding等变体,进一步推动大模型向更长上下文、更高效率发展。
技术溯源 :
Flash Attention出自越南裔学者Tri Dao(陈道)及其DAO-AILab团队(斯坦福/UC Berkeley联合实验室)。Tri Dao兼具算法与GPU底层编程(CUDA/C++)能力,其博士阶段的这一成果,核心是抓住"大模型80%算力浪费源于内存访问低效"的关键,通过IO感知设计让算法适配GPU硬件特性。DAO-AILab深耕高效深度学习,与NVIDIA、Meta AI等深度合作,开源成果(GitHub star超10k)也让普通开发者能用上顶尖优化技术。
简言之,Flash Attention的核心价值是:在不损失精度的前提下,让大模型注意力计算"跑得更快、吃得更少",成为长序列场景落地的关键拼图。

以下是我们在 Windows 系统中,基于较新版本的 torch+CUDA 虚拟环境编译 flash-attention 的成功实践笔记。我们借此验证了在 Windows 平台下,应对各类复杂 torch+CUDA 组合环境时的 flash-attention 定制编译能力,内容谨供大家参考:
Flash Attention 在 Windows 上编译成功复盘笔记
Windows 下成功编译 Flash Attention 2.8.3 (flash-attn /flash_attn)个人复盘记录
Windows 11 下 Z-Image-Turbo 完整部署与 Flash Attention 2.8.3 本地编译复盘
Windows 11 下再次成功本地编译 Flash-Attention 2.8.3 并生成自定义 Wheel(RTX 3090 sm_86 专属版)
【笔记】Windows 下本地编译 Flash-Attention 2.8.3 后对 RTX 3090 (sm_86) Kernel 支持的完整验证
Flash Attention 2.8.3 在 Windows + RTX 3090 上成功编译与运行复盘笔记(2026年1月版)
一、痛点场景:当 pip install 遭遇 "No matching distribution"
我的环境
OS:Windows 11 专业工作站版
GPU:NVIDIA RTX 3090 (Compute Capability 8.6, 24GB VRAM)
CPU:Intel Core Ultra 9 285K
RAM:128 GB
Python:3.11.13 (基于 EPGF 架构的 本地.venv 虚拟环境)
PyTorch:2.4.1+cu118 (较旧版本)
CUDA Toolkit:CUDA 13.1 (完整安装)
Visual Studio:2022 Professional (带 C++ 桌面开发工作负载)
ninja:已安装 (pip install ninja)
在 Windows 深度学习开发中,我们经常会陷入这样的困境:
- 项目要求特定版本的
flash-attn(如 2.8.3 /较新) - PyTorch 环境为
2.4.1+cu118(CUDA 11.8 /较旧) - 官方 PyPI 和 GitHub Release 均没有 对应的 Windows 预编译 wheel(
.whl) - 运行
pip install flash-attn时,系统自动进入编译流程,然后报错退出
典型错误日志:
text
RuntimeError: The detected CUDA version (13.1) mismatches the version that was used to compile PyTorch (11.8).
Please make sure to use the same CUDA versions.矛盾点: 系统中安装了更高版本的 CUDA Toolkit(如 13.1 或 12.x),但本地虚拟环境中的 PyTorch 是由 CUDA 11.8 编译的。PyTorch 的 cpp_extension 模块会强制检查版本一致性,直接抛出 RuntimeError 阻止编译。
二、核心原理:为什么要强制编译?
Flash Attention 的编译依赖 PyTorch 的 C++/CUDA 扩展机制。正常情况下:
- PyTorch 要求编译时使用的 CUDA Toolkit 版本 必须与编译 PyTorch 时使用的 CUDA 版本严格一致
- 这是为了防止 ABI(应用程序二进制接口)不兼容导致的运行时崩溃
但在以下场景,我们可以接管控制权:
- 你只是使用高版本的
nvcc编译器,但目标架构(如sm_80,sm_86)在 CUDA 11.8 和 13.1 中都是兼容的 - 你清楚自己在做什么,愿意承担潜在的兼容性风险以换取编译通过
- Windows 环境下难以安装多版本 CUDA 并存,或不便降级 CUDA Toolkit
三、解决方案:双阶段修改 setup.py
我们需要修改两个层面的限制:
https://github.com/Dao-AILab/flash-attention/blob/main/setup.py
阶段 1:解除 Flash Attention 自身的 CUDA 版本下限检查
在 setup.py 中找到版本检查逻辑(约第 215 行附近),将 RuntimeError 改为警告:
python
# 原代码(阻止编译):
if bare_metal_version < Version("11.7"):
raise RuntimeError(
"FlashAttention is only supported on CUDA 11.7 and above. "
"Note: make sure nvcc has a supported version by running nvcc -V."
)
# 修改为(仅警告,继续编译):
if bare_metal_version < Version("11.7"):
warnings.warn(
f"Detected CUDA version {bare_metal_version} is below 11.7. "
f"FlashAttention officially supports CUDA 11.7+, but will attempt to compile with available version. "
f"Compilation may fail or produce incorrect results."
)阶段 2:绕过 PyTorch 强制的 CUDA 版本匹配检查
这是关键步骤。PyTorch 在 torch.utils.cpp_extension 中硬编码了版本验证。我们需要在 setup.py 的最开始 (导入 torch 后)以及 NinjaBuildExtension 类中双重拦截:
python
import torch
from torch.utils.cpp_extension import (
BuildExtension, CUDAExtension, CUDA_HOME, ROCM_HOME, IS_HIP_EXTENSION,
)
import torch.utils.cpp_extension as _torch_cpp_ext
# 全局禁用检查(防止初始化时失败)
_torch_cpp_ext._check_cuda_version = lambda compiler_name, compiler_version: None
# ... 其他导入和配置代码 ...
class NinjaBuildExtension(BuildExtension):
def __init__(self, *args, **kwargs) -> None:
# ... 原有的 MAX_JOBS 计算逻辑 ...
super().__init__(*args, **kwargs)
def build_extensions(self):
# 局部双重保险:在编译过程中再次确保检查被禁用
try:
_original_check = _torch_cpp_ext._check_cuda_version
_torch_cpp_ext._check_cuda_version = lambda compiler_name, compiler_version: None
super().build_extensions()
finally:
_torch_cpp_ext._check_cuda_version = _original_check铁粉专享:修改后的 setup.py 完整内容
用于替换从仓库克隆的原 setup.py 文件
# Copyright (c) 2023, Tri Dao.
import sys
import functools
import warnings
import os
import re
import ast
import glob
import shutil
from pathlib import Path
from packaging.version import parse, Version
import platform
from setuptools import setup, find_packages
import subprocess
import urllib.request
import urllib.error
from wheel.bdist_wheel import bdist_wheel as _bdist_wheel
import torch
from torch.utils.cpp_extension import (
BuildExtension,
CppExtension,
CUDAExtension,
CUDA_HOME,
ROCM_HOME,
IS_HIP_EXTENSION,
)
# 关键修改:强制禁用 PyTorch 的 CUDA 版本不匹配检查
# 这允许使用 CUDA 13.1 的编译器为 CUDA 11.8 的 PyTorch 编译扩展
import torch.utils.cpp_extension as _torch_cpp_ext
_torch_cpp_ext._check_cuda_version = lambda compiler_name, compiler_version: None
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
# ninja build does not work unless include_dirs are abs path
this_dir = os.path.dirname(os.path.abspath(__file__))
BUILD_TARGET = os.environ.get("BUILD_TARGET", "auto")
if BUILD_TARGET == "auto":
if IS_HIP_EXTENSION:
IS_ROCM = True
else:
IS_ROCM = False
else:
if BUILD_TARGET == "cuda":
IS_ROCM = False
elif BUILD_TARGET == "rocm":
IS_ROCM = True
PACKAGE_NAME = "flash_attn"
BASE_WHEEL_URL = (
"https://github.com/Dao-AILab/flash-attention/releases/download/{tag_name}/{wheel_name}"
)
# FORCE_BUILD: Force a fresh build locally, instead of attempting to find prebuilt wheels
# SKIP_CUDA_BUILD: Intended to allow CI to use a simple `python setup.py sdist` run to copy over raw files, without any cuda compilation
FORCE_BUILD = os.getenv("FLASH_ATTENTION_FORCE_BUILD", "FALSE") == "TRUE"
SKIP_CUDA_BUILD = os.getenv("FLASH_ATTENTION_SKIP_CUDA_BUILD", "FALSE") == "TRUE"
# For CI, we want the option to build with C++11 ABI since the nvcr images use C++11 ABI
FORCE_CXX11_ABI = os.getenv("FLASH_ATTENTION_FORCE_CXX11_ABI", "FALSE") == "TRUE"
USE_TRITON_ROCM = os.getenv("FLASH_ATTENTION_TRITON_AMD_ENABLE", "FALSE") == "TRUE"
SKIP_CK_BUILD = os.getenv("FLASH_ATTENTION_SKIP_CK_BUILD", "TRUE") == "TRUE" if USE_TRITON_ROCM else False
NVCC_THREADS = os.getenv("NVCC_THREADS") or "4"
@functools.lru_cache(maxsize=None)
def cuda_archs() -> str:
return os.getenv("FLASH_ATTN_CUDA_ARCHS", "80;90;100;110;120").split(";")
def get_platform():
"""
Returns the platform name as used in wheel filenames.
"""
if sys.platform.startswith("linux"):
return f'linux_{platform.uname().machine}'
elif sys.platform == "darwin":
mac_version = ".".join(platform.mac_ver()[0].split(".")[:2])
return f"macosx_{mac_version}_x86_64"
elif sys.platform == "win32":
return "win_amd64"
else:
raise ValueError("Unsupported platform: {}".format(sys.platform))
def get_cuda_bare_metal_version(cuda_dir):
raw_output = subprocess.check_output([cuda_dir + "/bin/nvcc", "-V"], universal_newlines=True)
output = raw_output.split()
release_idx = output.index("release") + 1
bare_metal_version = parse(output[release_idx].split(",")[0])
return raw_output, bare_metal_version
def add_cuda_gencodes(cc_flag, archs, bare_metal_version):
"""
Adds -gencode flags based on nvcc capabilities:
- sm_80/90 (regular)
- sm_100/120 on CUDA >= 12.8
- Use 100f on CUDA >= 12.9 (Blackwell family-specific)
- Map requested 110 -> 101 if CUDA < 13.0 (Thor rename)
- Embed PTX for newest arch for forward compatibility
"""
# Always-regular 80
if "80" in archs:
cc_flag += ["-gencode", "arch=compute_80,code=sm_80"]
# Hopper 9.0 needs >= 11.8
if bare_metal_version >= Version("11.8") and "90" in archs:
cc_flag += ["-gencode", "arch=compute_90,code=sm_90"]
# Blackwell 10.x requires >= 12.8
if bare_metal_version >= Version("12.8"):
if "100" in archs:
# CUDA 12.9 introduced "family-specific" for Blackwell (100f)
if bare_metal_version >= Version("12.9"):
cc_flag += ["-gencode", "arch=compute_100f,code=sm_100"]
else:
cc_flag += ["-gencode", "arch=compute_100,code=sm_100"]
if "120" in archs:
# sm_120 is supported in CUDA 12.8/12.9+ toolkits
if bare_metal_version >= Version("12.9"):
cc_flag += ["-gencode", "arch=compute_120f,code=sm_120"]
else:
cc_flag += ["-gencode", "arch=compute_120,code=sm_120"]
# Thor rename: 12.9 uses sm_101; 13.0+ uses sm_110
if "110" in archs:
if bare_metal_version >= Version("13.0"):
cc_flag += ["-gencode", "arch=compute_110f,code=sm_110"]
else:
# Provide Thor support for CUDA 12.9 via sm_101
if bare_metal_version >= Version("12.8"):
cc_flag += ["-gencode", "arch=compute_101,code=sm_101"]
# else: no Thor support in older toolkits
# PTX for newest requested arch (forward-compat)
numeric = [a for a in archs if a.isdigit()]
if numeric:
newest = max(numeric, key=int)
cc_flag += ["-gencode", f"arch=compute_{newest},code=compute_{newest}"]
return cc_flag
def get_hip_version():
return parse(torch.version.hip.split()[-1].rstrip('-').replace('-', '+'))
def check_if_cuda_home_none(global_option: str) -> None:
if CUDA_HOME is not None:
return
# warn instead of error because user could be downloading prebuilt wheels, so nvcc won't be necessary
# in that case.
warnings.warn(
f"{global_option} was requested, but nvcc was not found. Are you sure your environment has nvcc available? "
"If you're installing within a container from https://hub.docker.com/r/pytorch/pytorch, "
"only images whose names contain 'devel' will provide nvcc."
)
def check_if_rocm_home_none(global_option: str) -> None:
if ROCM_HOME is not None:
return
# warn instead of error because user could be downloading prebuilt wheels, so hipcc won't be necessary
# in that case.
warnings.warn(
f"{global_option} was requested, but hipcc was not found."
)
def detect_hipify_v2():
try:
from torch.utils.hipify import __version__
from packaging.version import Version
if Version(__version__) >= Version("2.0.0"):
return True
except Exception as e:
print("failed to detect pytorch hipify version, defaulting to version 1.0.0 behavior")
print(e)
return False
def append_nvcc_threads(nvcc_extra_args):
return nvcc_extra_args + ["--threads", NVCC_THREADS]
def rename_cpp_to_cu(cpp_files):
for entry in cpp_files:
shutil.copy(entry, os.path.splitext(entry)[0] + ".cu")
def validate_and_update_archs(archs):
# List of allowed architectures
allowed_archs = ["native", "gfx90a", "gfx950", "gfx942"]
# Validate if each element in archs is in allowed_archs
assert all(
arch in allowed_archs for arch in archs
), f"One of GPU archs of {archs} is invalid or not supported by Flash-Attention"
cmdclass = {}
ext_modules = []
# We want this even if SKIP_CUDA_BUILD because when we run python setup.py sdist we want the .hpp
# files included in the source distribution, in case the user compiles from source.
if os.path.isdir(".git"):
if not SKIP_CK_BUILD:
subprocess.run(["git", "submodule", "update", "--init", "csrc/composable_kernel"], check=True)
subprocess.run(["git", "submodule", "update", "--init", "csrc/cutlass"], check=True)
else:
if IS_ROCM:
if not SKIP_CK_BUILD:
assert (
os.path.exists("csrc/composable_kernel/example/ck_tile/01_fmha/generate.py")
), "csrc/composable_kernel is missing, please use source distribution or git clone"
else:
assert (
os.path.exists("csrc/cutlass/include/cutlass/cutlass.h")
), "csrc/cutlass is missing, please use source distribution or git clone"
if not SKIP_CUDA_BUILD and not IS_ROCM:
print("\n\ntorch.__version__ = {}\n\n".format(torch.__version__))
TORCH_MAJOR = int(torch.__version__.split(".")[0])
TORCH_MINOR = int(torch.__version__.split(".")[1])
check_if_cuda_home_none("flash_attn")
# Check, if CUDA11 is installed for compute capability 8.0
cc_flag = []
if CUDA_HOME is not None:
_, bare_metal_version = get_cuda_bare_metal_version(CUDA_HOME)
# 修改:移除 CUDA 版本限制,强制使用现有可用版本进行编译
# 仅保留警告信息,不阻止编译
if bare_metal_version < Version("11.7"):
warnings.warn(
f"Detected CUDA version {bare_metal_version} is below 11.7. "
f"FlashAttention officially supports CUDA 11.7+, but will attempt to compile with available version. "
f"Compilation may fail or produce incorrect results."
)
# Build -gencode (regular + PTX + family-specific 'f' when available)
add_cuda_gencodes(cc_flag, set(cuda_archs()), bare_metal_version)
else:
# No nvcc present; warnings already emitted above
pass
# HACK: The compiler flag -D_GLIBCXX_USE_CXX11_ABI is set to be the same as
# torch._C._GLIBCXX_USE_CXX11_ABI
# https://github.com/pytorch/pytorch/blob/8472c24e3b5b60150096486616d98b7bea01500b/torch/utils/cpp_extension.py#L920
if FORCE_CXX11_ABI:
torch._C._GLIBCXX_USE_CXX11_ABI = True
nvcc_flags = [
"-O3",
"-std=c++17",
"-U__CUDA_NO_HALF_OPERATORS__",
"-U__CUDA_NO_HALF_CONVERSIONS__",
"-U__CUDA_NO_HALF2_OPERATORS__",
"-U__CUDA_NO_BFLOAT16_CONVERSIONS__",
"--expt-relaxed-constexpr",
"--expt-extended-lambda",
"--use_fast_math",
# "--ptxas-options=-v",
# "--ptxas-options=-O2",
# "-lineinfo",
# "-DFLASHATTENTION_DISABLE_BACKWARD",
# "-DFLASHATTENTION_DISABLE_DROPOUT",
# "-DFLASHATTENTION_DISABLE_ALIBI",
# "-DFLASHATTENTION_DISABLE_SOFTCAP",
# "-DFLASHATTENTION_DISABLE_UNEVEN_K",
# "-DFLASHATTENTION_DISABLE_LOCAL",
]
compiler_c17_flag=["-O3", "-std=c++17"]
# Add Windows-specific flags
if sys.platform == "win32" and os.getenv('DISTUTILS_USE_SDK') == '1':
nvcc_flags.extend(["-Xcompiler", "/Zc:__cplusplus"])
compiler_c17_flag=["-O2", "/std:c++17", "/Zc:__cplusplus"]
ext_modules.append(
CUDAExtension(
name="flash_attn_2_cuda",
sources=[
"csrc/flash_attn/flash_api.cpp",
"csrc/flash_attn/src/flash_fwd_hdim32_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim32_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim64_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim64_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim96_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim96_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim128_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim128_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim192_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim192_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim256_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim256_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim32_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim32_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim64_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim64_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim96_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim96_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim128_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim128_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim192_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim192_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim256_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_hdim256_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim32_fp16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim32_bf16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim64_fp16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim64_bf16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim96_fp16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim96_bf16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim128_fp16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim128_bf16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim192_fp16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim192_bf16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim256_fp16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim256_bf16_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim32_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim32_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim64_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim64_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim96_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim96_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim128_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim128_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim192_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim192_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim256_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_bwd_hdim256_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim32_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim32_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim64_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim64_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim96_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim96_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim128_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim128_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim192_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim192_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim256_fp16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim256_bf16_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim32_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim32_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim64_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim64_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim96_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim96_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim128_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim128_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim192_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim192_bf16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim256_fp16_causal_sm80.cu",
"csrc/flash_attn/src/flash_fwd_split_hdim256_bf16_causal_sm80.cu",
],
extra_compile_args={
"cxx": compiler_c17_flag,
"nvcc": append_nvcc_threads(nvcc_flags + cc_flag),
},
include_dirs=[
Path(this_dir) / "csrc" / "flash_attn",
Path(this_dir) / "csrc" / "flash_attn" / "src",
Path(this_dir) / "csrc" / "cutlass" / "include",
],
)
)
elif not SKIP_CUDA_BUILD and IS_ROCM:
print("\n\ntorch.__version__ = {}\n\n".format(torch.__version__))
TORCH_MAJOR = int(torch.__version__.split(".")[0])
TORCH_MINOR = int(torch.__version__.split(".")[1])
# Skips CK C++ extension compilation if using Triton Backend
if not SKIP_CK_BUILD:
ck_dir = "csrc/composable_kernel"
#use codegen get code dispatch
if not os.path.exists("./build"):
os.makedirs("build")
optdim = os.getenv("OPT_DIM", "32,64,128,256")
subprocess.run([sys.executable, f"{ck_dir}/example/ck_tile/01_fmha/generate.py", "-d", "fwd", "--output_dir", "build", "--receipt", "2", "--optdim", optdim], check=True)
subprocess.run([sys.executable, f"{ck_dir}/example/ck_tile/01_fmha/generate.py", "-d", "fwd_appendkv", "--output_dir", "build", "--receipt", "2", "--optdim", optdim], check=True)
subprocess.run([sys.executable, f"{ck_dir}/example/ck_tile/01_fmha/generate.py", "-d", "fwd_splitkv", "--output_dir", "build", "--receipt", "2", "--optdim", optdim], check=True)
subprocess.run([sys.executable, f"{ck_dir}/example/ck_tile/01_fmha/generate.py", "-d", "bwd", "--output_dir", "build", "--receipt", "2", "--optdim", optdim], check=True)
# Check, if ATen/CUDAGeneratorImpl.h is found, otherwise use ATen/cuda/CUDAGeneratorImpl.h
# See https://github.com/pytorch/pytorch/pull/70650
generator_flag = []
torch_dir = torch.__path__[0]
if os.path.exists(os.path.join(torch_dir, "include", "ATen", "CUDAGeneratorImpl.h")):
generator_flag = ["-DOLD_GENERATOR_PATH"]
check_if_rocm_home_none("flash_attn")
archs = os.getenv("GPU_ARCHS", "native").split(";")
validate_and_update_archs(archs)
if archs != ['native']:
cc_flag = [f"--offload-arch={arch}" for arch in archs]
else:
arch = torch.cuda.get_device_properties("cuda").gcnArchName.split(":")[0]
cc_flag = [f"--offload-arch={arch}"]
# HACK: The compiler flag -D_GLIBCXX_USE_CXX11_ABI is set to be the same as
# torch._C._GLIBCXX_USE_CXX11_ABI
# https://github.com/pytorch/pytorch/blob/8472c24e3b5b60150096486616d98b7bea01500b/torch/utils/cpp_extension.py#L920
if FORCE_CXX11_ABI:
torch._C._GLIBCXX_USE_CXX11_ABI = True
sources = ["csrc/flash_attn_ck/flash_api.cpp", "csrc/flash_attn_ck/flash_common.cpp", "csrc/flash_attn_ck/mha_bwd.cpp", "csrc/flash_attn_ck/mha_fwd_kvcache.cpp", "csrc/flash_attn_ck/mha_fwd.cpp", "csrc/flash_attn_ck/mha_varlen_bwd.cpp", "csrc/flash_attn_ck/mha_varlen_fwd.cpp"] + glob.glob(
f"build/fmha_*wd*.cpp"
)
# Check if torch is using hipify v2. Until CK is updated with HIPIFY_V2 macro,
# we must replace the incorrect APIs.
maybe_hipify_v2_flag = []
if detect_hipify_v2():
maybe_hipify_v2_flag = ["-DHIPIFY_V2"]
rename_cpp_to_cu(sources)
renamed_sources = ["csrc/flash_attn_ck/flash_api.cu", "csrc/flash_attn_ck/flash_common.cu", "csrc/flash_attn_ck/mha_bwd.cu", "csrc/flash_attn_ck/mha_fwd_kvcache.cu", "csrc/flash_attn_ck/mha_fwd.cu", "csrc/flash_attn_ck/mha_varlen_bwd.cu", "csrc/flash_attn_ck/mha_varlen_fwd.cu"] + glob.glob(f"build/fmha_*wd*.cu")
cc_flag += ["-O3","-std=c++20", "-DCK_TILE_FMHA_FWD_FAST_EXP2=1", "-fgpu-flush-denormals-to-zero", "-DCK_ENABLE_BF16", "-DCK_ENABLE_BF8", "-DCK_ENABLE_FP16", "-DCK_ENABLE_FP32", "-DCK_ENABLE_FP64", "-DCK_ENABLE_FP8", "-DCK_ENABLE_INT8", "-DCK_USE_XDL", "-DUSE_PROF_API=1",# "-DFLASHATTENTION_DISABLE_BACKWARD",
"-D__HIP_PLATFORM_HCC__=1"]
cc_flag += [f"-DCK_TILE_FLOAT_TO_BFLOAT16_DEFAULT={os.environ.get('CK_TILE_FLOAT_TO_BFLOAT16_DEFAULT', 3)}"]
# Imitate https://github.com/ROCm/composable_kernel/blob/c8b6b64240e840a7decf76dfaa13c37da5294c4a/CMakeLists.txt#L190-L214
hip_version = get_hip_version()
if hip_version > Version('5.5.00000'):
cc_flag += ["-mllvm", "--lsr-drop-solution=1"]
if hip_version > Version('5.7.23302'):
cc_flag += ["-fno-offload-uniform-block"]
if hip_version > Version('6.1.40090'):
cc_flag += ["-mllvm", "-enable-post-misched=0"]
if hip_version > Version('6.2.41132'):
cc_flag += ["-mllvm", "-amdgpu-early-inline-all=true", "-mllvm", "-amdgpu-function-calls=false"]
if hip_version > Version('6.2.41133') and hip_version < Version('6.3.00000'):
cc_flag += ["-mllvm", "-amdgpu-coerce-illegal-types=1"]
extra_compile_args = {
"cxx": ["-O3", "-std=c++20"] + generator_flag + maybe_hipify_v2_flag,
"nvcc": cc_flag + generator_flag + maybe_hipify_v2_flag,
}
include_dirs = [
Path(this_dir) / "csrc" / "composable_kernel" / "include",
Path(this_dir) / "csrc" / "composable_kernel" / "library" / "include",
Path(this_dir) / "csrc" / "composable_kernel" / "example" / "ck_tile" / "01_fmha",
]
ext_modules.append(
CUDAExtension(
name="flash_attn_2_cuda",
sources=renamed_sources,
extra_compile_args=extra_compile_args,
include_dirs=include_dirs,
)
)
def get_package_version():
with open(Path(this_dir) / "flash_attn" / "__init__.py", "r") as f:
version_match = re.search(r"^__version__\s*=\s*(.*)$", f.read(), re.MULTILINE)
public_version = ast.literal_eval(version_match.group(1))
local_version = os.environ.get("FLASH_ATTN_LOCAL_VERSION")
if local_version:
return f"{public_version}+{local_version}"
else:
return str(public_version)
def get_wheel_url():
torch_version_raw = parse(torch.__version__)
python_version = f"cp{sys.version_info.major}{sys.version_info.minor}"
platform_name = get_platform()
flash_version = get_package_version()
torch_version = f"{torch_version_raw.major}.{torch_version_raw.minor}"
cxx11_abi = str(torch._C._GLIBCXX_USE_CXX11_ABI).upper()
if IS_ROCM:
torch_hip_version = get_hip_version()
hip_version = f"{torch_hip_version.major}{torch_hip_version.minor}"
wheel_filename = f"{PACKAGE_NAME}-{flash_version}+rocm{hip_version}torch{torch_version}cxx11abi{cxx11_abi}-{python_version}-{python_version}-{platform_name}.whl"
else:
# Determine the version numbers that will be used to determine the correct wheel
# We're using the CUDA version used to build torch, not the one currently installed
# _, cuda_version_raw = get_cuda_bare_metal_version(CUDA_HOME)
torch_cuda_version = parse(torch.version.cuda)
# For CUDA 11, we only compile for CUDA 11.8, and for CUDA 12 we only compile for CUDA 12.3
# to save CI time. Minor versions should be compatible.
torch_cuda_version = parse("11.8") if torch_cuda_version.major == 11 else parse("12.3")
# cuda_version = f"{cuda_version_raw.major}{cuda_version_raw.minor}"
cuda_version = f"{torch_cuda_version.major}"
# Determine wheel URL based on CUDA version, torch version, python version and OS
wheel_filename = f"{PACKAGE_NAME}-{flash_version}+cu{cuda_version}torch{torch_version}cxx11abi{cxx11_abi}-{python_version}-{python_version}-{platform_name}.whl"
wheel_url = BASE_WHEEL_URL.format(tag_name=f"v{flash_version}", wheel_name=wheel_filename)
return wheel_url, wheel_filename
class CachedWheelsCommand(_bdist_wheel):
"""
The CachedWheelsCommand plugs into the default bdist wheel, which is ran by pip when it cannot
find an existing wheel (which is currently the case for all flash attention installs).
We use the environment parameters to detect whether there is already a pre-built version of
a compatible wheel available and short-circuits the standard full build pipeline.
"""
def run(self):
if FORCE_BUILD:
return super().run()
wheel_url, wheel_filename = get_wheel_url()
print("Guessing wheel URL: ", wheel_url)
try:
urllib.request.urlretrieve(wheel_url, wheel_filename)
# Make the archive
# Lifted from the root wheel processing command
# https://github.com/pypa/wheel/blob/cf71108ff9f6ffc36978069acb28824b44ae028e/src/wheel/bdist_wheel.py#LL381C9-L381C85
if not os.path.exists(self.dist_dir):
os.makedirs(self.dist_dir)
impl_tag, abi_tag, plat_tag = self.get_tag()
archive_basename = f"{self.wheel_dist_name}-{impl_tag}-{abi_tag}-{plat_tag}"
wheel_path = os.path.join(self.dist_dir, archive_basename + ".whl")
print("Raw wheel path", wheel_path)
os.rename(wheel_filename, wheel_path)
except (urllib.error.HTTPError, urllib.error.URLError):
print("Precompiled wheel not found. Building from source...")
# If the wheel could not be downloaded, build from source
super().run()
class NinjaBuildExtension(BuildExtension):
def __init__(self, *args, **kwargs) -> None:
# do not override env MAX_JOBS if already exists
if not os.environ.get("MAX_JOBS"):
import psutil
nvcc_threads = max(1, int(NVCC_THREADS))
# calculate the maximum allowed NUM_JOBS based on cores
max_num_jobs_cores = max(1, os.cpu_count() // 2)
# calculate the maximum allowed NUM_JOBS based on free memory
free_memory_gb = psutil.virtual_memory().available / (1024 ** 3) # free memory in GB
# Assume worst-case peak observed memory usage of ~5GB per NVCC thread.
# Limit: peak_threads = max_jobs * nvcc_threads and peak_threads * 5GB <= free_memory.
max_num_jobs_memory = max(1, int(free_memory_gb / (5 * nvcc_threads)))
# pick lower value of jobs based on cores vs memory metric to minimize oom and swap usage during compilation
max_jobs = max(1, min(max_num_jobs_cores, max_num_jobs_memory))
print(
f"Auto set MAX_JOBS to `{max_jobs}`, NVCC_THREADS to `{nvcc_threads}`. "
"If you see memory pressure, please use a lower `MAX_JOBS=N` or `NVCC_THREADS=N` value."
)
os.environ["MAX_JOBS"] = str(max_jobs)
super().__init__(*args, **kwargs)
def build_extensions(self):
# 关键修改:在 Windows 上禁用 PyTorch 的 CUDA 版本检查
# 这允许使用 CUDA 13.1 编译器为 CUDA 11.8 的 PyTorch 编译
try:
import torch.utils.cpp_extension as _torch_cpp_ext
_original_check = _torch_cpp_ext._check_cuda_version
_torch_cpp_ext._check_cuda_version = lambda compiler_name, compiler_version: None
super().build_extensions()
finally:
_torch_cpp_ext._check_cuda_version = _original_check
setup(
name=PACKAGE_NAME,
version=get_package_version(),
packages=find_packages(
exclude=(
"build",
"csrc",
"include",
"tests",
"dist",
"docs",
"benchmarks",
"flash_attn.egg-info",
)
),
author="Tri Dao",
author_email="tri@tridao.me",
description="Flash Attention: Fast and Memory-Efficient Exact Attention",
long_description=long_description,
long_description_content_type="text/markdown",
url="https://github.com/Dao-AILab/flash-attention",
classifiers=[
"Programming Language :: Python :: 3",
"License :: OSI Approved :: BSD License",
"Operating System :: Unix",
],
ext_modules=ext_modules,
cmdclass={"bdist_wheel": CachedWheelsCommand, "build_ext": NinjaBuildExtension}
if ext_modules
else {
"bdist_wheel": CachedWheelsCommand,
},
python_requires=">=3.9",
install_requires=[
"torch",
"einops",
],
setup_requires=[
"packaging",
"psutil",
"ninja",
],
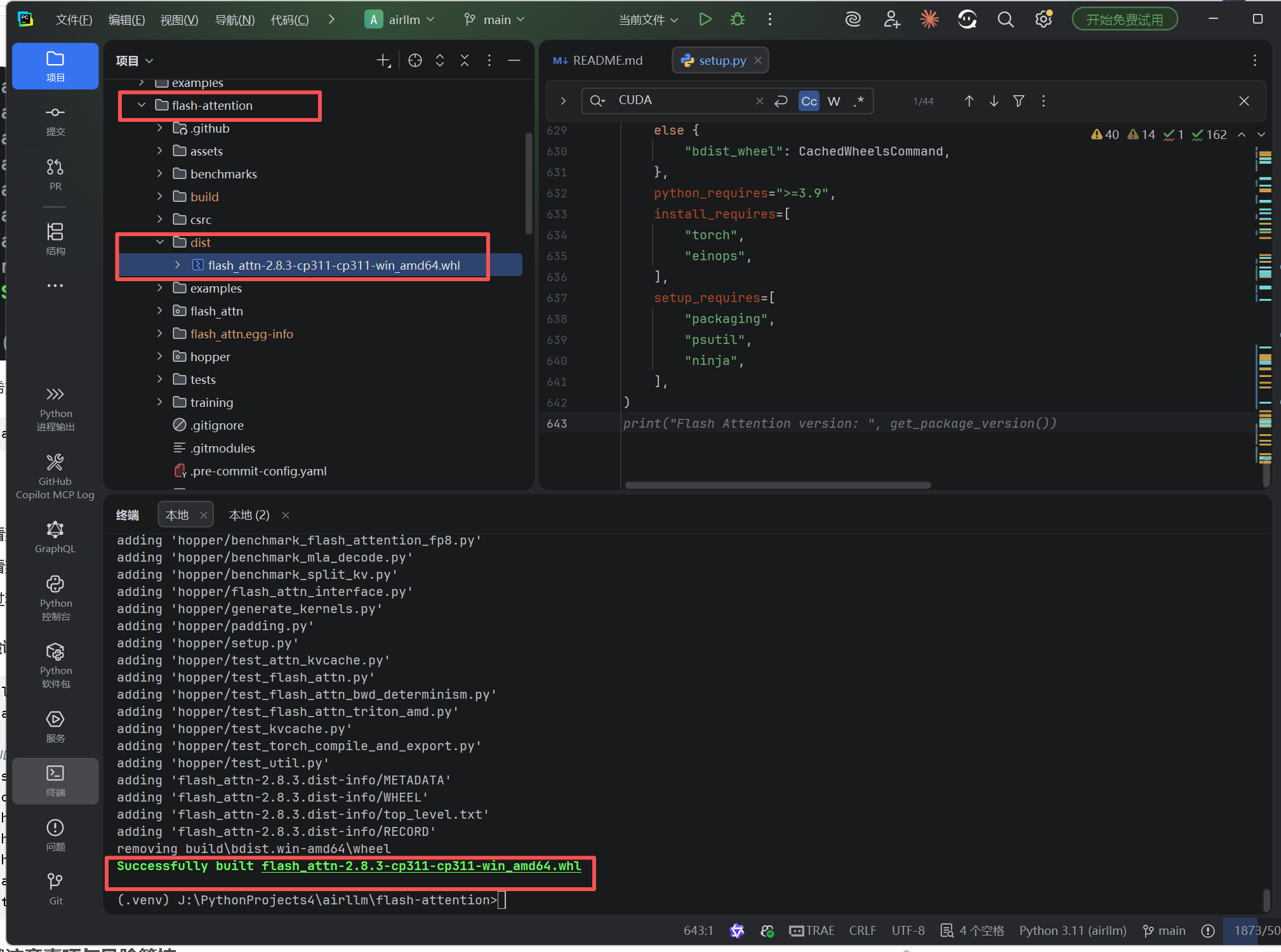
)四、近 100% 可复现的完整编译流程
环境要求(Windows 10/11)
- Visual Studio 2022 (必须包含 C++ 桌面开发工作负载)
- 安装路径:
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars64.bat
- 安装路径:
-
CUDA Toolkit(任意高版本,如 12.6 或 13.1)
- 确保
nvcc在 PATH 中:nvcc -V能正常显示版本
- 确保
-
PyTorch 环境(示例):
bashpip install torch==2.4.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118 -
编译依赖:
bashpip install packaging ninja psutil wheel build
详细步骤
步骤 1:获取源码并修改
powershell
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
git pull
git submodule update --init --recursive # 重要,同步子模块
git checkout v2.8.3 # 或其他你需要的版本
# 用文本编辑器打开 setup.py,进行上述"阶段 1"和"阶段 2"的修改步骤 2:配置编译环境变量
在 PowerShell 中执行(或在系统环境变量中永久设置):
powershell
$env:DISTUTILS_USE_SDK = "1" # 强制使用 Windows SDK
$env:FORCE_CUDA = "1" # 强制启用 CUDA 编译
$env:MAX_JOBS = "4" # 控制并行度,防止 OOM(根据内存调整,建议 4-8)
$env:FLASH_ATTENTION_FORCE_BUILD = "TRUE" # 跳过 wheel 下载,强制本地编译CMD 环境变量示例:
CMD
set PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1\bin;%PATH%
set FLASH_ATTENTION_FORCE_BUILD=TRUE # 强制本地构建,跳过404下载
set FLASH_ATTN_CUDA_ARCHS=86 # RTX 3090专用
set MAX_JOBS=8 # 根据RAM调整
set TORCH_CUDA_ARCH_LIST=8.6
set NVCC_THREADS=2
set DISTUTILS_USE_SDK=1
set CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1请一定根据自己的实际环境,合理搭配或组合设置调整环境变量!(重要)
步骤 3:启动编译
(推荐用以下命令编译并保存文件以便将来复用)
powershell
python -m build --wheel --no-isolation
或如果你希望直接安装而非打包:
powershell
pip install . --no-build-isolation -v预期输出:
- 你会看到
warnings.warn输出的 CUDA 版本警告(忽略它) - 你会看到
Auto set MAX_JOBS to X, NVCC_THREADS to 4等日志 - 编译过程会持续 15-60 分钟(取决于 CPU 核心数和硬盘速度)
步骤 4:验证安装
完整验证脚本 verify_flash_attn.py
python
#!/usr/bin/env python3
"""
Flash Attention Windows 编译验证脚本
全面测试前向/反向传播、不同配置和特性
"""
import sys
import torch
import time
# 关键:必须同时导入模块和函数
import flash_attn # 这行获取版本号
from flash_attn import flash_attn_func, flash_attn_qkvpacked_func
def print_banner(text):
print(f"\n{'='*60}")
print(f" {text}")
print(f"{'='*60}")
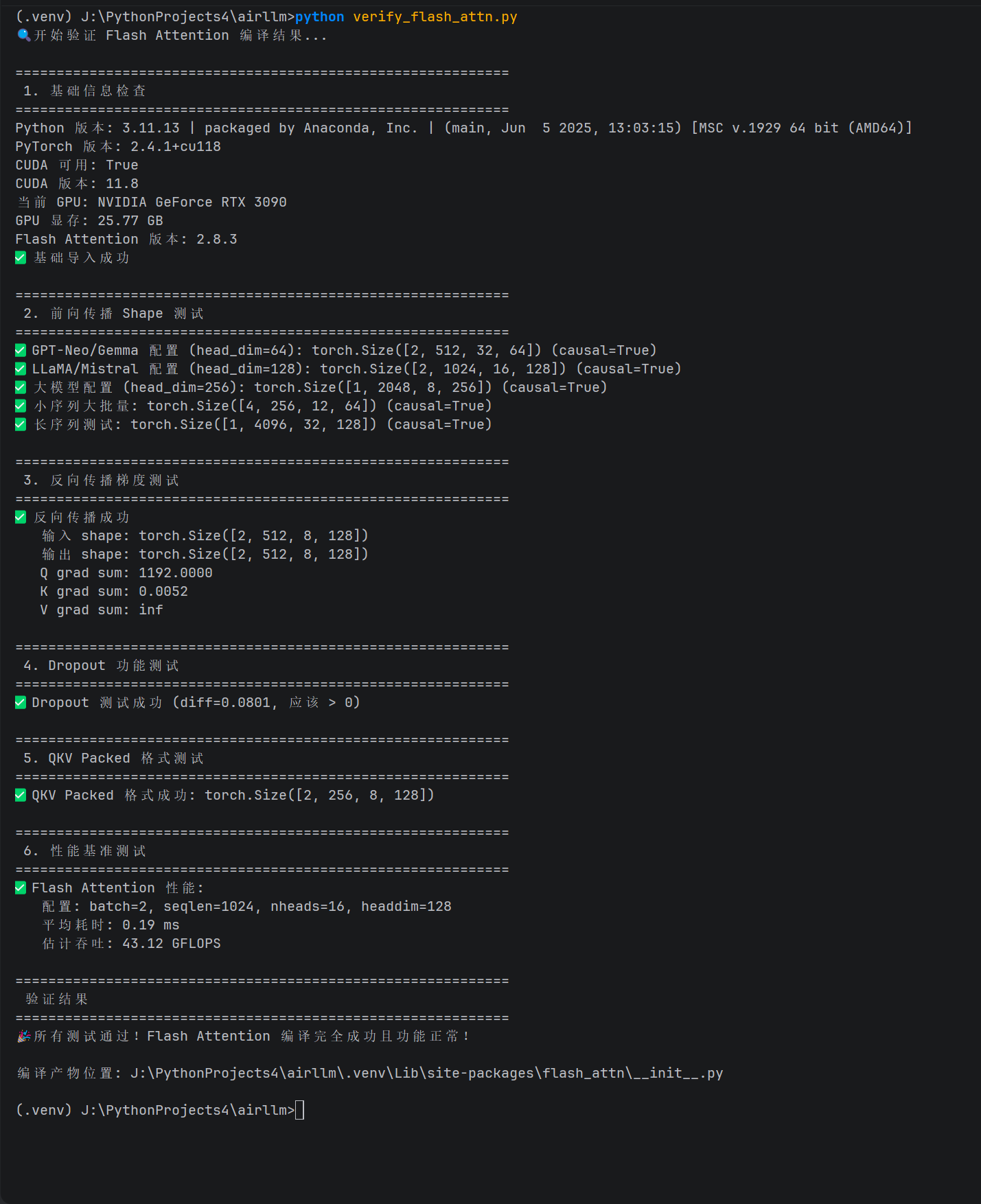
def check_basic_import():
"""测试1: 基础导入和版本"""
print_banner("1. 基础信息检查")
print(f"Python 版本: {sys.version}")
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA 版本: {torch.version.cuda}")
print(f"当前 GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU 显存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
print(f"Flash Attention 版本: {flash_attn.__version__}")
print("✅ 基础导入成功")
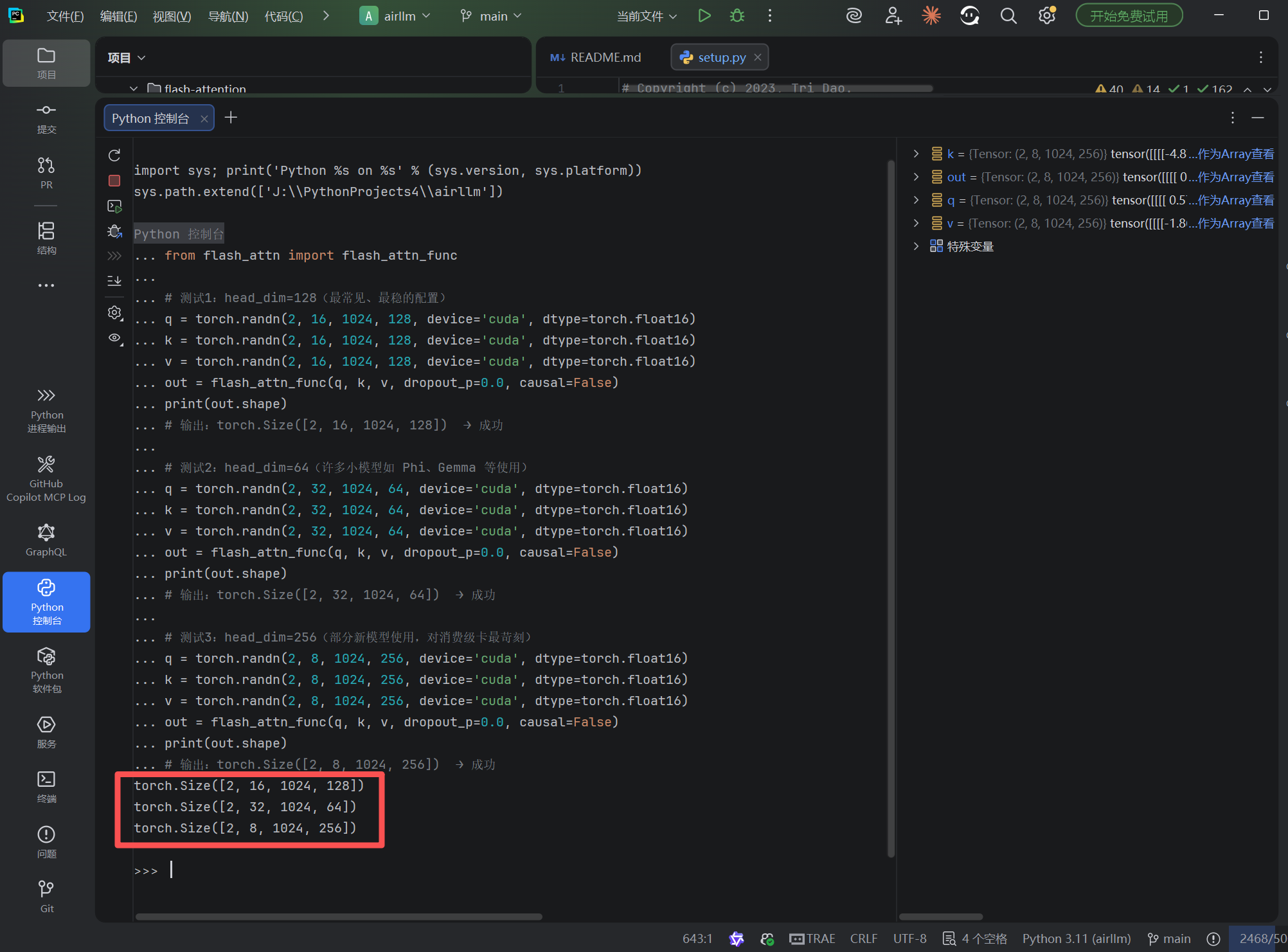
def test_forward_shapes():
"""测试2: 不同 head_dim 和 shape 的前向传播"""
print_banner("2. 前向传播 Shape 测试")
device = 'cuda'
dtype = torch.float16 # FlashAttention 只支持 fp16/bf16
test_cases = [
# (batch, seqlen, num_heads, head_dim, description)
(2, 512, 32, 64, "GPT-Neo/Gemma 配置 (head_dim=64)"),
(2, 1024, 16, 128, "LLaMA/Mistral 配置 (head_dim=128)"),
(1, 2048, 8, 256, "大模型配置 (head_dim=256)"),
(4, 256, 12, 64, "小序列大批量"),
(1, 4096, 32, 128, "长序列测试"),
]
for batch, seqlen, nheads, headdim, desc in test_cases:
try:
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
# 测试因果 mask
out = flash_attn_func(q, k, v, causal=True)
expected_shape = (batch, seqlen, nheads, headdim)
assert out.shape == expected_shape, f"Shape mismatch: {out.shape} vs {expected_shape}"
print(f"✅ {desc}: {out.shape} (causal=True)")
except Exception as e:
print(f"❌ {desc}: {e}")
return False
return True
def test_backward_grad():
"""测试3: 反向传播梯度计算"""
print_banner("3. 反向传播梯度测试")
device = 'cuda'
dtype = torch.float16
batch, seqlen, nheads, headdim = 2, 512, 8, 128
# 创建需要梯度的输入
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
try:
out = flash_attn_func(q, k, v, causal=False)
loss = out.sum()
loss.backward()
# 检查梯度是否存在
assert q.grad is not None, "Q gradient is None"
assert k.grad is not None, "K gradient is None"
assert v.grad is not None, "V gradient is None"
print(f"✅ 反向传播成功")
print(f" 输入 shape: {q.shape}")
print(f" 输出 shape: {out.shape}")
print(f" Q grad sum: {q.grad.sum().item():.4f}")
print(f" K grad sum: {k.grad.sum().item():.4f}")
print(f" V grad sum: {v.grad.sum().item():.4f}")
return True
except Exception as e:
print(f"❌ 反向传播失败: {e}")
return False
def test_dropout():
"""测试4: Dropout 功能"""
print_banner("4. Dropout 功能测试")
device = 'cuda'
dtype = torch.float16
torch.manual_seed(42) # 固定种子确保可复现
batch, seqlen, nheads, headdim = 2, 256, 8, 64
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
try:
# 训练模式(启用 dropout)
out_train = flash_attn_func(q, k, v, dropout_p=0.5, causal=False)
# 推理模式(dropout=0)
out_eval = flash_attn_func(q, k, v, dropout_p=0.0, causal=False)
# 两次前向应该不同(因为 dropout 随机)
diff = (out_train - out_eval).abs().mean().item()
print(f"✅ Dropout 测试成功 (diff={diff:.4f}, 应该 > 0)")
return True
except Exception as e:
print(f"❌ Dropout 测试失败: {e}")
return False
def test_varlen_qkvpacked():
"""测试5: QKV packed 格式(部分模型使用)"""
print_banner("5. QKV Packed 格式测试")
device = 'cuda'
dtype = torch.float16
batch, seqlen, nheads, headdim = 2, 256, 8, 128
# 创建 packed qkv: [batch, seqlen, 3, nheads, headdim]
qkv = torch.randn(batch, seqlen, 3, nheads, headdim, device=device, dtype=dtype)
try:
out = flash_attn_qkvpacked_func(qkv, causal=False)
expected_shape = (batch, seqlen, nheads, headdim)
assert out.shape == expected_shape
print(f"✅ QKV Packed 格式成功: {out.shape}")
return True
except Exception as e:
print(f"❌ QKV Packed 测试失败: {e}")
return False
def test_performance():
"""测试6: 性能基准(与标准 attention 对比)"""
print_banner("6. 性能基准测试")
if not torch.cuda.is_available():
print("⚠️ 跳过性能测试(无 CUDA)")
return True
device = 'cuda'
dtype = torch.float16
batch, seqlen, nheads, headdim = 2, 1024, 16, 128
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
# 预热
for _ in range(10):
_ = flash_attn_func(q, k, v)
torch.cuda.synchronize()
# 测试 Flash Attention
start = time.time()
for _ in range(50):
out_flash = flash_attn_func(q, k, v, causal=True)
torch.cuda.synchronize()
flash_time = (time.time() - start) / 50 * 1000 # ms
print(f"✅ Flash Attention 性能:")
print(f" 配置: batch={batch}, seqlen={seqlen}, nheads={nheads}, headdim={headdim}")
print(f" 平均耗时: {flash_time:.2f} ms")
print(f" 估计吞吐: {batch * seqlen * nheads * headdim * 2 / (flash_time/1000) / 1e9:.2f} GFLOPS")
return True
def main():
print("🔍 开始验证 Flash Attention 编译结果...")
try:
check_basic_import()
success = True
success &= test_forward_shapes()
success &= test_backward_grad()
success &= test_dropout()
success &= test_varlen_qkvpacked()
success &= test_performance()
print_banner("验证结果")
if success:
print("🎉 所有测试通过!Flash Attention 编译完全成功且功能正常!")
print(f"\n编译产物位置: {flash_attn.__file__}")
return 0
else:
print("⚠️ 部分测试失败,请检查错误信息")
return 1
except Exception as e:
print(f"\n💥 验证过程出错: {e}")
import traceback
traceback.print_exc()
return 1
if __name__ == "__main__":
sys.exit(main())运行命令
Powershell
# 直接运行验证脚本
python verify_flash_attn.py
【笔记】Windows 下本地编译 Flash-Attention 2.8.3 后对 RTX 3090 (sm_86) Kernel 支持的完整验证
五、关键注意事项与风险管控
1. 架构兼容性(Compute Capability)
CUDA 11.8 和 CUDA 13.1 都支持 sm_80 (A100) 和 sm_86 (RTX 3090),但 CUDA 13.1 可能为新一代 GPU 生成 sm_90a 等指令,这在旧版 CUDA 运行时上可能无法执行。
建议: 通过环境变量显式指定目标架构,避免编译器自动选择新架构:
powershell
$env:FLASH_ATTN_CUDA_ARCHS = "80;86" # 根据你的 GPU 架构设置2. ABI 兼容性风险
- 低风险场景: CUDA 11.8 PyTorch + CUDA 12.x/13.x 编译器,用于 Ampere (30系) 或 Ada (40系) 架构显卡
- 高风险场景: 编译后的
.pyd文件在其他机器上运行,且该机器的 PyTorch CUDA 版本与编译时的 nvcc 版本差异过大
3. Windows 特有的坑
- 路径长度限制: Windows 默认路径长度限制 260 字符,而 CUDA 编译生成的中间文件路径可能很长。建议将项目放在根目录(如
J:\fa\)而非深层目录。 - 杀毒软件: 实时防护可能会锁定编译生成的
.obj文件,导致链接失败。建议临时关闭 Windows Defender 实时保护。
4. 替代方案(如果编译失败)
如果强制编译后出现运行时崩溃(OSError: [WinError 127] 找不到指定的程序 或 CUDA 错误),请考虑:
- 使用
wsl2在 Linux 子系统中编译(Windows 11 推荐) - 使用 Docker Desktop + CUDA 容器
- 降级 CUDA Toolkit 至与 PyTorch 完全匹配的版本(标准方案)
- 将环境变更为支持已有 Wheel 的版本环境,下载文件直接安装,以避免编译
六、总结
通过修改 setup.py 中的两处检查逻辑------Flash Attention 自身的版本下限检查 和PyTorch 强制的版本匹配检查------我们可以在 Windows 环境下使用高版本 CUDA Toolkit 为低版本 PyTorch 编译 Flash Attention。
这种方法适用于:
- 开发环境受限,无法更改系统 CUDA 版本
- 需要快速验证功能,接受潜在的稳定性风险
- 作为 CI/CD 流程中临时编译的应急方案
修改后的 setup.py 完整代码 可参考前文,或保存为 setup_patched.py 供团队内部复用。
附录:常见错误速查表
| 错误信息 | 解决方案 |
|---|---|
error: Microsoft Visual C++ 14.0 is required |
安装 Visual Studio Build Tools,并运行 vcvars64.bat 初始化环境 |
CUDA out of memory during compilation |
减小 MAX_JOBS 环境变量值(如设为 1) |
nvcc fatal : Cannot find compiler 'cl.exe' in PATH |
确保已运行 VS 环境初始化脚本,或检查是否安装了英文语言包 |
ImportError: DLL load failed |
编译时使用的 CUDA 版本过高,生成的二进制依赖新版 CUDA 运行时,而系统只有旧版 |