cann组织链接: https://atomgit.com/cann
ops-nn仓库链接: https://atomgit.com/cann/ops-nn在AIGC(人工智能生成内容)浪潮席卷全球的今天,从生成式对抗网络到大语言模型,其背后核心算子的性能直接决定了生成效率与质量。华为CANN(Compute Architecture for Neural Networks)生态中的ops-nn算子库,作为连接AI框架与昇腾NPU硬件的关键桥梁,正通过其高度优化的神经网络类算子,为AIGC应用提供硬核加速动力。本文将深入剖析ops-nn的设计哲学、技术实现及实战应用,带您领略从底层算子到上层应用的全栈优化之道。
🔍 CANN与ops-nn:异构计算架构的算子基石
华为CANN架构是专为神经网络计算优化的异构计算架构,旨在高效处理深度学习训练与推理任务。其核心设计包含三大模块:运行时引擎、编译器工具链和算子库,通过软硬件协同提升计算效率。而ops-nn是CANN提供的神经网络类计算算子库,专门实现网络在NPU上的加速计算。它支持Atlas A2/A3系列产品,于2025年9月首次上线开源,包含了大量经过深度优化的硬件亲和算子,能够充分发挥昇腾AI处理器的计算潜力。
1.1 CANN分层架构中的ops-nn定位
CANN采用分层架构设计,为不同层次的开发者提供了差异化的开发接口。ops-nn作为算子库的核心组成部分,其定位可从下图清晰看出:
CANN核心组件
AI框架
PyTorch/MindSpore
框架适配层
统一内部表示
运行时与调度层
任务分发与资源管理
驱动与固件层
硬件通信与控制
算子库
ops-nn/ops-audio等
异构编译器
图优化与算子融合
集合通信库
多设备协同优化
昇腾AI处理器
硬件计算单元
ops-nn在CANN架构中承担着核心计算引擎的角色,它提供的算子经过深度优化,能够直接映射到昇腾NPU的硬件指令,避免中间层的性能损耗。这种设计确保了无论是PyTorch、MindSpore还是其他AI框架的模型,都能通过CANN适配层无缝调用这些高性能算子,实现"一次开发,多端运行"的愿景。
1.2 ops-nn的技术特性与优势
ops-nn算子库具备以下几个关键特性,使其成为AIGC应用加速的理想选择:
- 硬件亲和优化:算子针对昇腾AI处理器的硬件特性进行深度优化,包括Vector Unit的SIMD能力、Cube计算单元的矩阵乘法加速以及片上内存(UB/L1)的高效利用。例如,矩阵乘法算子通过使能AtomicAdd选项,可以直接将结果矩阵与另一个矩阵进行累加,从而减少内存搬运次数,优化矩阵运算性能。
- 多精度支持:支持FP16、FP32、INT8等多种数据类型的混合精度计算,在保持模型精度的同时提升计算速度和能效比。在典型场景下,ResNet50的推理性能可达每秒数千张图像,时延控制在毫秒级。
- 算子融合能力:通过编译器工具链支持自动算子融合,将多个连续的操作(如激活函数、偏置添加)融合为一个任务,一次性执行,大幅降低延迟并减少内存访问开销。对于AIGC中常见的生成网络(如GAN、Diffusion Model),这种融合技术能显著提升推理速度。
- 动态形状支持:能够自动适应可变输入尺寸(如可变分辨率图像、可长度的文本序列),避免重复编译计算图,这对于处理生成任务中不确定长度的输出尤为重要。
🧠 核心算子解析:从数学原理到硬件实现
ops-nn提供了丰富的神经网络算子,其中卷积(Conv2d)和矩阵乘法(Matmul)是AIGC应用中最核心的计算原语。下面我们将深入解析这些算子的数学原理、硬件实现及优化技巧。
2.1 Conv2d算子:生成网络的视觉基础
卷积是计算机视觉任务和图像生成模型(如GAN、StyleGAN、VQ-VAE)的核心算子。ops-nn中的Conv2d算子通过以下优化策略实现了高性能:
2.1.1 数学定义与参数含义
二维卷积的数学表达式为:
Y m , n = ∑ c = 0 C i n − 1 ∑ i = 0 k h − 1 ∑ j = 0 k w − 1 X c , m ⋅ s h + i , n ⋅ s w + j ⋅ W m , c , i , j + b m Y_{m,n} = \sum_{c=0}^{C_{in}-1} \sum_{i=0}^{k_h-1} \sum_{j=0}^{k_w-1} X_{c, m \cdot s_h + i, n \cdot s_w + j} \cdot W_{m,c,i,j} + b_m Ym,n=c=0∑Cin−1i=0∑kh−1j=0∑kw−1Xc,m⋅sh+i,n⋅sw+j⋅Wm,c,i,j+bm
其中:
- ( X ) 是输入张量,形状为 (N, C_{in}, H_{in}, W_{in})
- ( W ) 是卷积核权重,形状为 (C_{out}, C_{in}, k_h, k_w)
- ( b ) 是偏置项,形状为 (C_{out})
- ( s_h, s_w ) 是步长(stride)
- 输出 ( Y ) 的形状为 (N, C_{out}, H_{out}, W_{out}),其中:
H o u t = ⌊ H i n + 2 p h − k h s h ⌋ + 1 H_{out} = \left\lfloor \frac{H_{in} + 2p_h - k_h}{s_h} \right\rfloor + 1 Hout=⌊shHin+2ph−kh⌋+1
W o u t = ⌊ W i n + 2 p w − k w s w ⌋ + 1 W_{out} = \left\lfloor \frac{W_{in} + 2p_w - k_w}{s_w} \right\rfloor + 1 Wout=⌊swWin+2pw−kw⌋+1
在PyTorch中,Conv2d的参数定义与上述数学表达式一一对应:
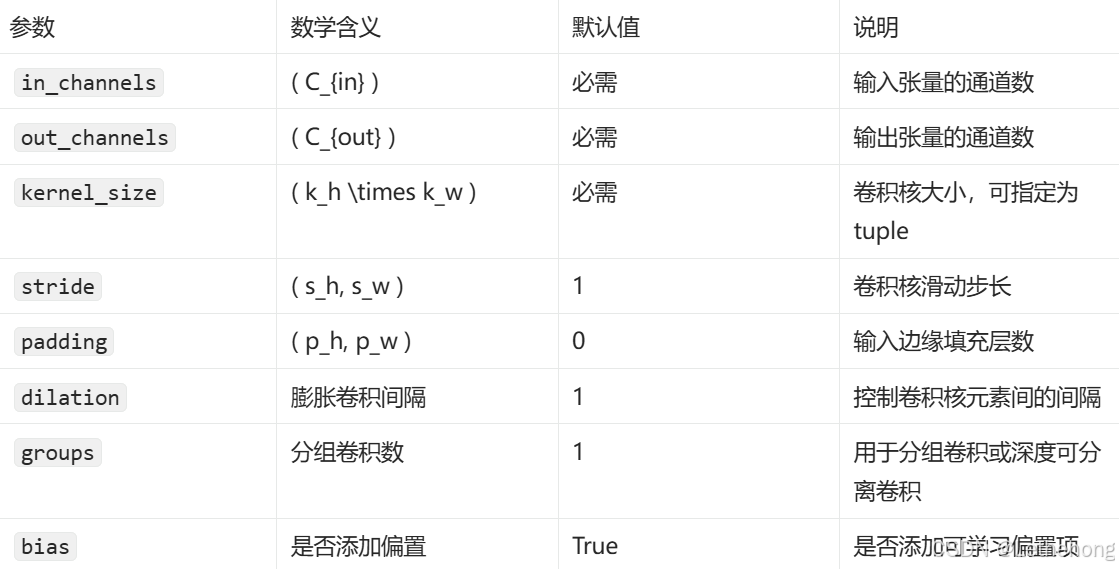
2.1.2 硬件实现与优化策略
ops-nn中的Conv2d算子并非简单移植,而是针对昇腾NPU的硬件特性进行了深度优化:
- 基于Winograd算法的卷积加速:对于小尺寸卷积核(如3x3、5x5),采用Winograd算法减少乘法运算次数,将部分乘法转换为加法,充分利用硬件的加法器资源。
- 内存访问优化:通过精心设计的数据重排策略和片上内存(UB)缓存机制,将卷积核的不规则内存访问转化为高效的连续访问,最大化内存带宽利用率。这类似于FFT中的Bit-reversal操作,将不连续的内存访问模式转换为连续访问。
- 多核并行与流水线:将输入特征图切分成多个Tile,分配给不同的AI Core并行计算。同时采用双缓冲流水线技术,在一个Tile计算的同时,为下一个Tile预取数据,隐藏内存延迟,提高计算单元的利用率。
- 支持分组卷积与深度可分离卷积 :通过高效的
groups参数实现,支持MobileNet等轻量化网络使用的深度可分离卷积,大幅减少计算量和参数量,在AIGC的移动端部署中尤为重要。
2.2 Matmul算子:生成网络的计算核心
矩阵乘法(Matmul)是几乎所有AIGC模型的核心计算原语,从GAN的判别器到Transformer的自注意力机制,都离不开密集的矩阵乘法运算。
2.2.1 数学定义与优化目标
矩阵乘法的标准定义为:
C m , n = ∑ k = 0 K − 1 A m , k ⋅ B k , n C_{m,n} = \sum_{k=0}^{K-1} A_{m,k} \cdot B_{k,n} Cm,n=k=0∑K−1Am,k⋅Bk,n
其中 ( A \in \mathbb{R}^{M \times K} ), ( B \in \mathbb{R}^{K \times N} ), ( C \in \mathbb{R}^{M \times N} )。
在AIGC应用中,矩阵乘法通常面临以下挑战:
- 大规模计算:生成模型(如Diffusion Model)中的矩阵维度往往很大,导致计算量巨大
- 频繁内存搬运:数据在片上内存与片外内存之间频繁搬运,成为性能瓶颈
- 累加操作:在Transformer等模型中,矩阵乘法结果需要与另一个矩阵累加,增加额外开销
2.2.2 硬件实现与AtomicAdd优化
ops-nn中的Matmul算子通过以下优化策略应对上述挑战:
-
Cube计算单元加速:利用昇腾AI处理器专用的Cube计算单元,进行大规模矩阵乘法加速。Cube单元专门为矩阵乘法设计,能够在一个周期内完成多个乘加操作,计算效率远超通用计算单元。
-
AtomicAdd累加优化 :这是ops-nn Matmul算子的一项关键优化技术。传统实现中,矩阵乘法后需要将结果从计算单元搬运到内存,再与另一个矩阵进行加法运算,这会引入多次内存搬运,导致额外的性能开销。ops-nn通过使能AtomicAdd选项,允许在进行矩阵乘法运算时,直接将结果矩阵C与矩阵D进行累加,从而减少内存搬运的次数,优化矩阵运算性能。
cpp// 伪代码示例:使能AtomicAdd的Matmul调用 MatmulWithAtomicAdd( &global_tensor_C, // 累加结果存储在C中 &global_tensor_A, &global_tensor_B, &global_tensor_D, // 累加矩阵 m, n, k, // 矩阵维度 enable_atomic_add // 使能AtomicAdd标志 );这种优化对于生成式模型尤为重要,因为在生成过程中,往往需要多次累加中间结果,AtomicAdd可以显著减少内存访问次数,提升整体性能。
-
分块与流水线计算:将大矩阵切分成多个适合Cube计算单元处理的小块,采用流水线方式计算。同时利用双缓冲技术,在计算一个Block的同时,为下一个Block预取数据,最大化计算单元的利用率。
-
混合精度计算:支持FP16和INT8等低精度计算,在保持模型精度的同时,大幅提升计算吞吐量,降低内存占用和功耗。在AIGC的大模型推理中,混合精度计算是平衡性能和精度的关键技术。
🛠️ 实战指南:基于ops-nn的AIGC算子开发
理解了核心算子的原理后,我们通过一个实例来演示如何基于ops-nn和Ascend C开发自定义算子,并集成到AIGC应用中。
3.1 开发环境搭建与工具链介绍
在开始开发之前,需要完成Ascend CANN的环境准备:
-
CANN软件安装:在开发机上安装CANN软件包,确保安装路径正确。具体安装步骤请参考官方《CANN软件安装指南》。
-
环境变量配置 :使用CANN运行用户登录环境,执行:
bashsource ${install_path}/set_env.sh其中
${install_path}为CANN的安装路径,例如/usr/local/Ascend/ascend-toolkit。该操作会将CANN相关的编译工具链和运行库加入环境变量。
Ascend C是CANN针对算子开发场景推出的编程语言,支持C和C++标准规范,最大化匹配用户开发习惯。它提供了一组高效的类库API,帮助开发者利用处理器的计算资源,进行高性能的AI运算。Ascend C API接口分为两大类:基础API 和高阶API。
- 基础API :实现了对硬件的抽象,是直接与芯片资源交互的工具。包括:
- 计算API:支持标量、向量和矩阵的运算,对应Scalar、Vector、Cube计算单元的调用。
- 数据搬运API:用于在Global Memory与Local Memory之间的数据搬运。
- 内存管理API:用于分配管理内存,例如AllocTensor、FreeTensor接口。
- 任务同步API:完成任务间的通信和同步,例如EnQue、DeQue接口。
- 高阶API:在基础API之上提供了更高层次的抽象,简化开发流程,适合快速开发常见算子。
3.2 自定义ReLU6算子开发实例
ReLU6是ReLU激活函数的一种变体,用于限制输出范围在0,6之间,常见于轻量化模型和量化感知训练场景。数学表达式为:
ReLU6 ( x ) = min ( max ( 0 , x ) , 6 ) \text{ReLU6}(x) = \min(\max(0, x), 6) ReLU6(x)=min(max(0,x),6)
3.2.1 算子分析与设计
首先对算子进行需求分析,明确输入输出、计算逻辑和核函数参数:
| 参数 | 类型 | 说明 |
|---|---|---|
x |
GlobalTensor | 输入张量 |
y |
GlobalTensor | 输出张量 |
totalLength |
uint32_t | 总数据长度 |
tileNum |
uint32_t | 每核数据块数量 |
| 计算逻辑如下: |
- 将输入数据从Global Memory搬运到Local Memory;
- 在Local Memory中进行逐元素ReLU6计算;
- 将计算结果搬运回Global Memory。
3.2.2 核函数实现
下面是使用Ascend C实现ReLU6算子的核函数示例:
cpp
#include "kernel_operator.h"
#include "kernel_printf.h"
using namespace AscendC;
// 核函数定义
extern "C" __global__ __aicore__ void relu6_custom(GM_ADDR x, GM_ADDR y,
uint32_t totalLength, uint32_t tileNum) {
KernelReLU6 op;
op.Init(x, y, totalLength, tileNum);
op.Process();
}
// 核心算子类
class KernelReLU6 {
public:
__aicore__ inline KernelReLU6() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t tileNum) {
// 获取输入输出GlobalTensor
x_global.GlobalTensor(x);
y_global.GlobalTensor(y);
// 计算每个核处理的数据量
uint32_t coreId = GetBlockIdx();
uint32_t perCoreLength = totalLength / GetBlockNum();
uint32_t length = (coreId == GetBlockNum() - 1) ?
(totalLength - perCoreLength * coreId) : perCoreLength;
// 分配LocalTensor
x_local = LocalTensor<float16>(AllocTensor<float16>(length * sizeof(float16)));
y_local = LocalTensor<float16>(AllocTensor<float16>(length * sizeof(float16)));
// 初始化数据搬运和计算参数
pipe.InitBuffer(x_que, BUFFER_NUM, length * sizeof(float16));
pipe.InitBuffer(y_que, BUFFER_NUM, length * sizeof(float16));
// 设置计算参数
this->length = length;
}
__aicore__ inline void Process() {
// 数据分块处理
uint32_t tileNum = (length + TILE_SIZE - 1) / TILE_SIZE;
for (uint32_t i = 0; i < tileNum; ++i) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(uint32_t progress) {
// 数据从GM搬运到UB
LocalTensor<float16> x_local_ub = pipe.PopBuffer(x_que);
DataCopy(x_local_ub, x_global[progress * TILE_SIZE],
progress == (tileNum - 1) ? (length - progress * TILE_SIZE) : TILE_SIZE);
pipe.PushBuffer(x_que, x_local_ub);
}
__aicore__ inline void Compute(uint32_t progress) {
// 从UB获取数据
LocalTensor<float16> x_local_ub = pipe.PopBuffer(x_que);
LocalTensor<float16> y_local_ub = pipe.PopBuffer(y_que);
// ReLU6计算: min(max(0, x), 6)
for (uint32_t i = 0; i < ((progress == (tileNum - 1)) ?
(length - progress * TILE_SIZE) : TILE_SIZE); ++i) {
// max(0, x)
if (x_local_ub[i] < 0) {
x_local_ub[i] = 0;
}
// min(x, 6)
if (x_local_ub[i] > 6) {
x_local_ub[i] = 6;
}
y_local_ub[i] = x_local_ub[i];
}
// 将计算结果放回队列
pipe.PushBuffer(x_que, x_local_ub);
pipe.PushBuffer(y_que, y_local_ub);
}
__aicore__ inline void CopyOut(uint32_t progress) {
// 数据从UB搬运回GM
LocalTensor<float16> y_local_ub = pipe.PopBuffer(y_que);
DataCopy(y_global[progress * TILE_SIZE], y_local_ub,
progress == (tileNum - 1) ? (length - progress * TILE_SIZE) : TILE_SIZE);
pipe.PushBuffer(y_que, y_local_ub);
}
private:
GlobalTensor<float16> x_global, y_global;
LocalTensor<float16> x_local, y_local;
TQue<TPosition::VECOUT, TPosition::VECIN> x_que, y_que;
uint32_t length;
uint32_t tileNum;
};3.2.3 Host端调用与验证
下面是Host端调用核函数的示例代码:
cpp
#include "acl/acl.h"
#include "kernel_operator.h"
int main() {
// 初始化ACL
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
printf("acl init failed, ret=%d\n", ret);
return -1;
}
// 设置设备
int32_t deviceId = 0;
ret = aclrtSetDevice(deviceId);
if (ret != ACL_SUCCESS) {
printf("aclrtSetDevice failed, ret=%d\n", ret);
return -1;
}
// 创建流
aclrtStream stream = nullptr;
ret = aclrtCreateStream(&stream);
if (ret != ACL_SUCCESS) {
printf("aclrtCreateStream failed, ret=%d\n", ret);
return -1;
}
// 准备输入输出数据
const uint32_t totalLength = 1024;
const uint32_t tileSize = 256;
const uint32_t tileSizeNum = 4;
// 分配并初始化输入输出内存
float16 *host_x = new float16[totalLength];
float16 *host_y = new float16[totalLength];
float16 *check_y = new float16[totalLength];
// 初始化输入数据(-10到10之间的随机数)
for (uint32_t i = 0; i < totalLength; ++i) {
host_x[i] = static_cast<float16>((rand() % 200 - 100) / 10.0f);
// CPU端计算预期结果
check_y[i] = (host_x[i] > 0) ? ((host_x[i] < 6) ? host_x[i] : 6) : 0;
}
// 分配设备内存
void *device_x = nullptr;
void *device_y = nullptr;
ret = aclrtMalloc(&device_x, totalLength * sizeof(float16), ACL_MEM_MALLOC_HUGE_FIRST);
ret = aclrtMalloc(&device_y, totalLength * sizeof(float16), ACL_MEM_MALLOC_HUGE_FIRST);
// 拷贝输入数据到设备
ret = aclrtMemcpy(device_x, totalLength * sizeof(float16), host_x,
totalLength * sizeof(float16), ACL_MEMCPY_HOST_TO_DEVICE);
// 调用核函数
constexpr uint32_t BLOCK_NUM = 8; // 假设使用8个AI Core
relu6_custom<<<BLOCK_NUM, nullptr, stream>>>(reinterpret_cast<GM_ADDR>(device_x),
reinterpret_cast<GM_ADDR>(device_y),
totalLength, tileSizeNum);
// 同步流
ret = aclrtSynchronizeStream(stream);
// 拷贝输出数据到主机
ret = aclrtMemcpy(host_y, totalLength * sizeof(float16), device_y,
totalLength * sizeof(float16), ACL_MEMCPY_DEVICE_TO_HOST);
// 验证结果
bool pass = true;
for (uint32_t i = 0; i < totalLength; ++i) {
if (fabs(host_y[i] - check_y[i]) > 1e-3f) {
printf("Mismatch at index %u: expected=%.3f, got=%.3f\n",
i, check_y[i], host_y[i]);
pass = false;
}
}
if (pass) {
printf("ReLU6 test passed!\n");
} else {
printf("ReLU6 test failed!\n");
}
// 清理资源
delete[] host_x;
delete[] host_y;
delete[] check_y;
aclrtFree(device_x);
aclrtFree(device_y);
aclrtDestroyStream(stream);
aclrtResetDevice(deviceId);
aclFinalize();
return pass ? 0 : -1;
}3.3 集成到AIGC应用
将自定义算子集成到AIGC应用(如PyTorch)需要通过CANN的框架适配层。基本流程如下:
- 算子适配:通过TBE(Tensor Boost Engine)或TIK(Tensor Iterator Kernel)将自定义算子适配到CANN框架,生成可由运行时调用的算子对象。
- 框架注册 :在PyTorch中注册自定义算子,使其能够被框架识别和调用。这通常需要实现
forward方法和backward方法(如果需要反向传播)。 - 调用验证 :在AIGC模型中替换原有算子,验证功能和性能是否符合预期。
对于AIGC应用,还可以考虑以下优化策略:
- 算子融合:将ReLU6与前后算子(如卷积、批归一化)融合,减少内存访问和启动开销。CANN的编译器支持自动算子融合,开发者也可以手动指定融合策略。
- 量化优化:使用INT8量化进一步提升推理速度,ops-nn提供了量化相关的算子和工具链支持。
- 流式推理:对于生成任务,支持流式推理模式,能够逐帧生成输出,确保极低的输出延迟。
🚀 性能优化与最佳实践
要充分发挥ops-nn算子的性能,需要遵循一些最佳实践和优化技巧。
4.1 内存层次利用策略
昇腾AI处理器的内存层次包括Global Memory(GM)、Unified Buffer(UB)、Local Memory(L1)等。优化内存访问是性能提升的关键:
内存层次优化策略
L1缓存优化
Double Buffer流水线
数据分块与复用
数据从GM搬运到UB
在UB中进行计算
结果从UB搬运回GM
- L1缓存优化:将频繁访问的数据加载到L1缓存中,减少对UB的访问次数。例如,在卷积计算中,可以将输入特征图和卷积核的部分数据预取到L1缓存。
- Double Buffer流水线:在计算一个Tile的同时,为下一个Tile预取数据,隐藏内存延迟。这需要精心设计数据分块策略和流水线调度。
- 数据分块与复用:合理划分数据块,使每个块的数据在计算过程中能够多次复用,减少数据搬运量。对于卷积操作,可以按照输出特征图和输入通道进行分块。
4.2 并行计算策略
昇腾AI处理器支持多核并行计算,如何有效利用多核资源是性能优化的另一个关键:
- 数据并行:将输入数据切分成多个部分,分配给不同的AI Core并行处理。适合数据量大且各部分计算独立的场景。
- 模型并行:将模型参数切分到不同的设备上,每个设备处理模型的一部分。适合大模型训练或推理场景。
- 流水线并行 :将模型的不同层分配到不同的设备上,形成流水线。适合深层模型推理,可以减少层间等待时间。
对于AIGC应用,数据并行和流水线并行是常用的策略。例如,在生成图像时,可以将不同批次的图像分配给不同的AI Core并行生成,或者将生成过程的不同阶段(如噪声预测、去噪)分配到不同的设备上形成流水线。
4.3 性能调优工具
CANN提供了丰富的性能调优工具,帮助开发者分析和优化算子性能:
- Profiling工具:用于采集算子执行过程中的各种性能指标,如计算时间、内存访问时间、流水线效率等。通过Profiling结果,可以识别性能瓶颈并针对性优化。
- 可视化分析:提供直观的图表和报告,帮助开发者理解算子的执行情况和资源利用情况。
- 自动调优:部分工具提供自动调优功能,可以根据硬件特性和输入特征自动选择最优的算法和参数组合。
💡 性能优化黄金法则:
- 减少内存访问:数据访问是主要瓶颈,尽量减少对Global Memory的访问次数。
- 提高计算密度:增加每个数据元素参与计算的次数,提高计算吞吐量。
- 利用流水线并行:将计算、数据搬运等操作重叠执行,隐藏延迟。
- 选择合适的数据类型:根据精度需求选择FP16或INT8,减少计算量和内存占用。
- 充分利用硬件特性:针对昇腾AI处理器的硬件特性进行优化,如Cube计算单元、Vector Unit等。
🌟 总结与展望
华为CANN的ops-nn算子库作为连接AI框架与昇腾硬件的桥梁,通过其深度优化的神经网络算子,为AIGC应用提供了强大的加速支持。从基础的Conv2d和Matmul算子到复杂的生成网络算子,ops-nn都展现了出色的性能和优化能力。
通过本文的深入解析,我们了解到:
- CANN架构:通过分层设计,实现了从AI框架到硬件的高效映射,ops-nn在其中扮演核心计算引擎的角色。
- 核心算子原理:Conv2d和Matmul等算子通过Winograd算法、AtomicAdd累加、多核并行等技术实现了高性能。
- 实战开发流程:通过ReLU6算子示例,演示了基于Ascend C的自定义算子开发流程,从核函数实现到Host端调用验证。
- 性能优化策略 :通过内存层次利用、并行计算和工具链调优,可以进一步提升算子性能,满足AIGC应用的严苛要求。
随着AIGC技术的不断发展,对算力需求将持续增长。CANN和ops-nn也在不断演进,支持更多的AI框架和模型架构。未来,我们期待看到: - 更广泛的算子支持:支持更多新兴的AIGC算子,如扩散模型中的特定算子、3D生成算子等。
- 更高层次的抽象:提供更高层次的API和工具,进一步简化算子开发流程,降低开发门槛。
- 更强的自动优化能力 :通过AI技术自动优化算子性能,根据硬件特性和输入特征选择最优实现。
对于开发者而言,掌握CANN和ops-nn的开发技术,将能够在AIGC浪潮中占据有利位置,构建出更加高效、强大的生成式AI应用。华为开源CANN生态,为开发者提供了共建、共用的平台,期待更多开发者加入这个生态,共同推动AI计算技术的发展。
参考资源:
- CANN官方文档与社区:https://atomgit.com/cann
- ops-nn算子库:https://atomgit.com/cann/ops-nn
- Ascend C编程指南:https://www.hiascend.com/cann/ascend-c
- CANN训练营与开发者活动:https://www.hiascend.com/developer/activities/cann20252
本文技术深度解析基于华为CANN开源生态,旨在为AIGC开发者提供底层算子优化的实战指导。随着CANN生态的不断开放和发展,开发者将有更多机会参与共建,共同推动AI计算技术的创新与进步。