 项目介绍:github.com/mco-org/mco...
项目介绍:github.com/mco-org/mco...
你电脑上装了几个 AI 编程 Agent?
Claude Code、Codex、Gemini CLI、OpenCode、Qwen ------ 这些工具我都装了,但每次只用其中一个。用 Claude 写完一段代码,想让 Gemini或者Codex 再看看?得手动切过去,重新粘贴 prompt,等它跑完,再自己对比,审查的结果再粘贴回去,就非常麻烦。
为什么不让它们同时干活呢?
于是我做了 MCO(Multi-CLI Orchestrator)。一条命令,主Agent同时调度多个 AI 编程 Agent,并行执行,各自交付,结果汇总到一份输出里。
先看一个真实例子
我给 4 个 Agent 布置了同一个任务:「数一下这个仓库里有多少个 .py 文件」。
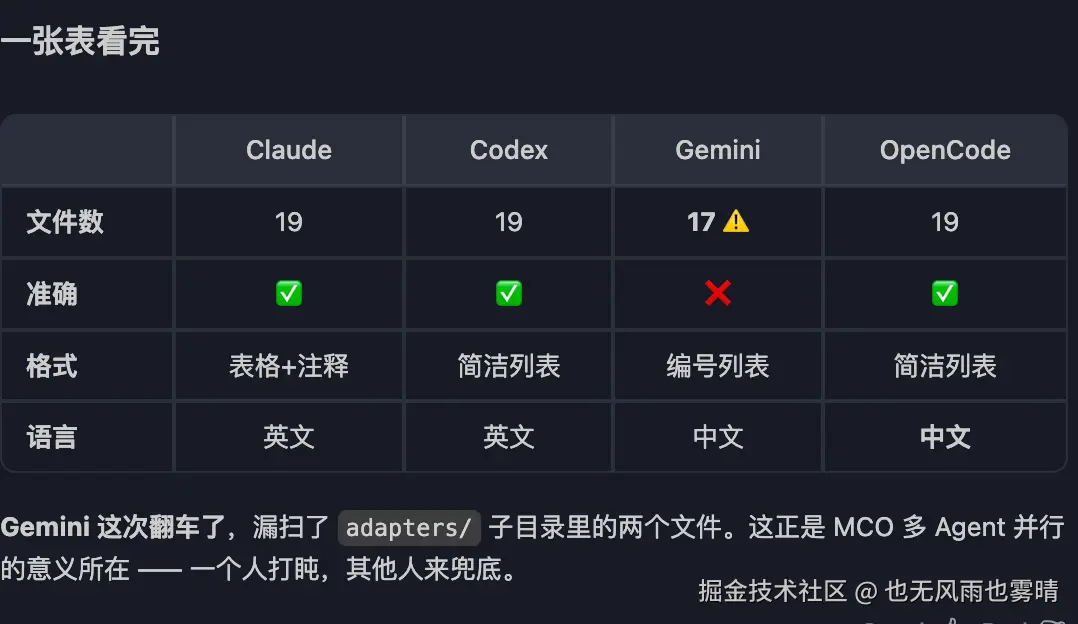
Claude、Codex、OpenCode 都数出了 19 个。Gemini 这次翻车了,只数出 17 个 ------ 漏掉了 adapters/ 子目录里的 parsing.py 和 shim.py 两个文件。
这只是一个数文件的简单任务,就已经出现了结果分歧。换成架构分析、代码总结、方案评估这类开放性任务,差异只会更大。
再来一个分析类任务:我把 5 个 Agent 全部拉进来,让它们同时分析 MCO 自己代码里的 retry.py,找出边界问题和潜在 Bug:

这次 5 家高度收敛,但各有侧重:
- 4/5 的 Agent 都发现了 :
retry_index <= 0无校验、延迟无上限可能指数爆炸 - 只有 Qwen 指出了 :
backoff_multiplier为负数时,会产生「正负交替延迟」这个奇特行为 - Claude 是唯一给出正向评价的 :主动说明
frozen=True的设计是对的,有来有往
一个 Agent 的输出,你只能选择信或不信。多个 Agent 的输出,你可以交叉验证。
MCO 是什么
MCO 是一个中立的 AI 编程 Agent 编排层。它不绑定任何厂商,不替代任何 Agent,只做一件事:
把你的任务并行分发给多个 Agent,收集结果,汇总输出。
你可以把它理解成一个 Tech Lead:
- 布置任务 ------ 你给 MCO 一个 prompt 和一组 Agent,就像给团队成员布置同一个任务
- 并行执行 ------ 所有 Agent 同时跑,总耗时 ≈ 最慢的那个,不是累加
- 收集结果 ------ 每个 Agent 独立交付自己的输出,MCO 汇总到一份结构化 JSON
- 你来判断 ------ 多份独立结果摆在面前,交叉对比,择优采纳
css
You (Tech Lead)
│
▼
mco run / mco review
│
├─→ Claude Code ──┐
├─→ Codex CLI │
├─→ Gemini CLI ├─→ 汇总 → 输出
├─→ OpenCode │
└─→ Qwen Code ───┘安装和上手
css
npm i -g @tt-a1i/mco或者从源码:
bash
git clone https://github.com/mco-org/mco.git
cd mco && python3 -m pip install -e .先用 mco doctor 检查一下你的环境:
mco doctor它会告诉你哪些 Agent 已安装、版本多少、认证是否正常。都 OK 之后,跑你的第一次多 Agent 任务:
css
mco run \
--repo . \
--prompt "分析这个项目的整体架构,列出模块职责和依赖关系" \
--providers claude,codex,gemini就这么简单。一条命令,3 个 Agent 同时分析,各自输出自己的理解。你拿到 3 份独立的架构报告,对比着看。
并行执行:核心能力
mco run 是 MCO 的核心模式。你给一个 prompt,选几个 Agent,它们同时跑,各自独立完成,你来对比验证。
关键点:额外开销几乎为零。 总耗时约等于最慢的那个 Agent,不是所有 Agent 的执行时间加起来。跑 1 个 Agent 要 30 秒,跑 5 个也大概 30 秒。
适合什么场景?
任何你想要多个独立视角的任务:
架构分析 ------ 3 个 Agent 各自分析同一个项目架构,你对比谁的理解更准确、谁漏了模块、谁的建议更实用:
css
mco run \
--repo . \
--prompt "分析这个项目的整体架构,列出核心模块、职责和依赖关系" \
--providers claude,gemini,qwen方案评估 ------ 让多个 Agent 独立评估同一个技术决策,收集不同立场的分析:
css
mco run \
--repo . \
--prompt "评估把这个项目从 Flask 迁移到 FastAPI 的可行性和风险" \
--providers claude,codex,gemini代码总结 ------ 多个 Agent 各自总结同一个模块,对比理解深度:
css
mco run \
--repo . \
--prompt "总结 runtime/ 目录下的核心逻辑和数据流" \
--providers claude,codex,opencode文档生成 ------ 多份草稿择优合并:
css
mco run \
--repo . \
--prompt "为这个项目的 API 模块生成开发者文档" \
--providers claude,gemini,qwen这就像给 3 个工程师布置同一个调研任务:你不需要他们协作,你需要的是多个独立视角,然后自己做判断。
为什么不只用一个 Agent?
这不是理论问题。从上面两次真实测试里就能看出来:
| 测试任务 | 翻车的 Agent | 翻车原因 | 独家发现 |
|---|---|---|---|
统计 .py 文件数 |
Gemini(17 vs 19) | 漏扫子目录 | --- |
| 分析 retry.py 边界问题 | 无明显失误 | --- | Qwen 发现负数乘数 Bug |
不同 Agent 确实擅长不同的事:
- Claude ------ 对代码结构和逻辑流的把握很强,会主动做正负两方面评价
- Codex ------ 执行指令精准,简洁干脆,不废话
- Gemini ------ 架构层面常有独到视角,但事实类任务偶尔漏扫(如数文件例子)
- OpenCode ------ 覆盖全面,系统性强,自动切换中文输出
- Qwen ------ 有时会发现其他 Agent 都没注意到的角落问题
如果你只用了其中某一个,Qwen 那条独家发现就永远不会出现在你面前;Gemini 漏掉的那两个文件你也永远不会知道。
3-5 个 Agent 并行跑同一个任务,你拿到的是视角的并集,不是某个 Agent 的单一判断。
延伸:结构化代码审查
并行执行的思路自然延伸到代码审查。mco review 是 MCO 的审查模式,在并行执行的基础上增加了:
- 结构化输出 ------ 每个 Agent 的发现被标准化为 findings(严重级别、分类、证据、建议)
- 跨 Agent 去重 ------ 多个 Agent 发现同一个 Bug 时自动合并,保留
detected_by来源追踪 - 共识总结 ------
--synthesize让一个 Agent 汇总所有结果:共识、分歧、下一步建议 - CI/CD 集成 ------
--format sarif对接 GitHub Code Scanning,--format markdown-pr生成 PR 评论
css
mco review \
--repo . \
--prompt "审查这个仓库的安全漏洞和高风险 Bug" \
--providers claude,codex,qwen \
--format markdown-pr审查场景下,多 Agent 的价值更明显 ------ 一个 Agent 发现竞态条件但漏掉 SQL 注入,另一个正好相反,第三个找到了前两个都没注意到的内存泄漏。MCO 把所有发现汇总去重,你拿到的是全覆盖的审查报告。
实际使用场景汇总
| 场景 | 命令 | 效果 |
|---|---|---|
| 架构分析 | mco run --providers claude,gemini,qwen |
3 份独立分析报告,对比择优 |
| 方案评估 | mco run --prompt "评估迁移到 FastAPI 的影响" |
多视角风险评估 |
| 代码总结 | mco run --prompt "总结核心模块逻辑" |
多份总结交叉验证 |
| 文档生成 | mco run --prompt "生成 API 文档" |
多份草稿择优合并 |
| PR 代码审查 | mco review --format markdown-pr |
多 Agent 并行审查,生成 PR 评论 |
| CI 安全扫描 | mco review --format sarif |
结果上传 GitHub Code Scanning |
| 共识决策 | mco review --synthesize |
汇总共识、标注分歧 |
| 环境健康检查 | mco doctor --json |
一键确认所有 Agent 就绪 |
跟 OpenClaw 等工具配合使用
如果你在用 OpenClaw,它可以直接调用 MCO 作为多 Agent 编排后端:
"用 mco 让 Claude、Codex 和 Gemini 同时分析这个项目的架构,汇总结果。"
OpenClaw 读 mco -h,自己学会 CLI 参数,自动编排整个流程。
同样适用于 Claude Code、Cursor、Trae、Copilot、Windsurf ------ 任何能跑 shell 命令的 Agent 都能调度 MCO。这意味着你可以让 Agent 调度 Agent:Claude Code 通过 MCO 分发任务给 Codex 和 Gemini,拿到结果后自己做总结。
核心特性一览
- 5 个内置 Provider ------ Claude Code、Codex、Gemini CLI、OpenCode、Qwen
- 并行扇出 ------ wait-all 语义,一个失败不阻塞其他
- 双模式 ------
mco run通用并行执行,mco review结构化代码审查 - 跨 Agent 发现去重 ------ 相同 Bug 多个 Agent 发现时自动合并,保留来源追踪
- LLM 共识总结 ------
--synthesize输出共识/分歧/建议 - 多格式输出 ------ JSON(默认)、SARIF(CI)、Markdown-PR(PR 评论)
- 环境健康检查 ------
mco doctor一键诊断 - Token 用量追踪 ------
--include-token-usage可选查看各 Agent 消耗 - 进度驱动超时 ------ 不设死超时,只在 Agent 长时间无输出时才取消
- 可扩展适配器 ------ 添加新 Agent 只需实现 3 个钩子
- 零配置 ------ 装完直接跑,所有参数都有合理默认值
MCO 不试图替代任何 Agent,它只是让你能同时用上所有 Agent。就像开会的时候,你不会只听一个人的意见 ------ 你让所有人都发言,然后做综合判断。
mco run 分配工作,mco review 审查工作 ------ 你是 Tech Lead,Agent 是你的团队。
项目开源,MIT 协议:github.com/mco-org/mco
css
npm i -g @tt-a1i/mco && mco doctor如果觉得有用,欢迎 Star 和反馈 issue。也欢迎贡献新的 Agent 适配器 ------ 只要你的 Agent 有 CLI,就能接入 MCO。