同步调用
同步调用是一种请求 - 等待的交互模式:当服务 A 调用服务 B 时,A 会暂停自身执行,直到 B 返回结果后,A 才会继续处理后续逻辑。
就像你去餐厅点餐,需要等厨师做好菜、服务员把菜端到你面前,你才能开始吃饭,在这个过程中你需要一直等待。
优点
时效性强:调用方可以立即获取结果,适合对数据一致性和实时性要求高的场景(如余额支付场景,必须确保余额扣减成功后再进行后续操作)。
逻辑简单:调用流程线性、直观,代码编写和调试相对容易,无需处理异步回调或消息积压等复杂问题。
缺点
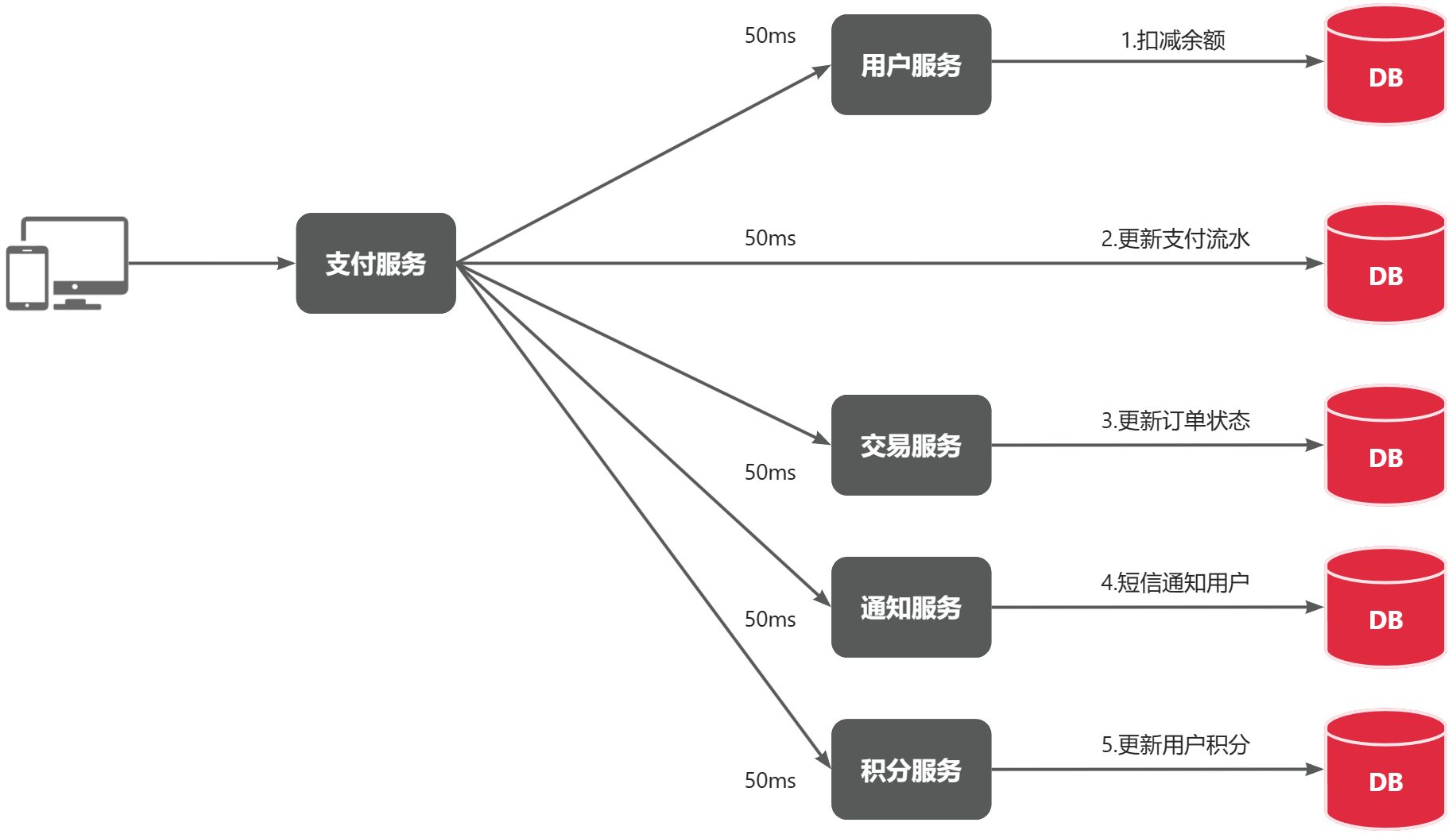
1、性能下降
支付服务需要依次调用用户服务、交易服务、通知服务等 5 个接口,每个接口耗时 50ms,总耗时会累积到约 250ms,再加上网络开销,最终可能达到 300ms,用户等待时间长。
2、拓展性差
每当新增业务环节(比如图里的 "还有个需求要加进去"),都需要在调用链中新增同步步骤,会进一步拉长响应时间,系统复杂度也会快速上升。
3、级联失败风险高
如果调用链中的任意一个服务(比如通知服务)出现故障,整个支付流程都会被阻塞甚至失败,可能导致用户余额已扣但订单状态未更新的不一致问题。
适用场景
同步调用适合对结果实时性、一致性要求高,且调用链路短的场景,
比如: 支付、转账等金融交易场景。 用户登录时的身份校验、权限查询。
异步调用
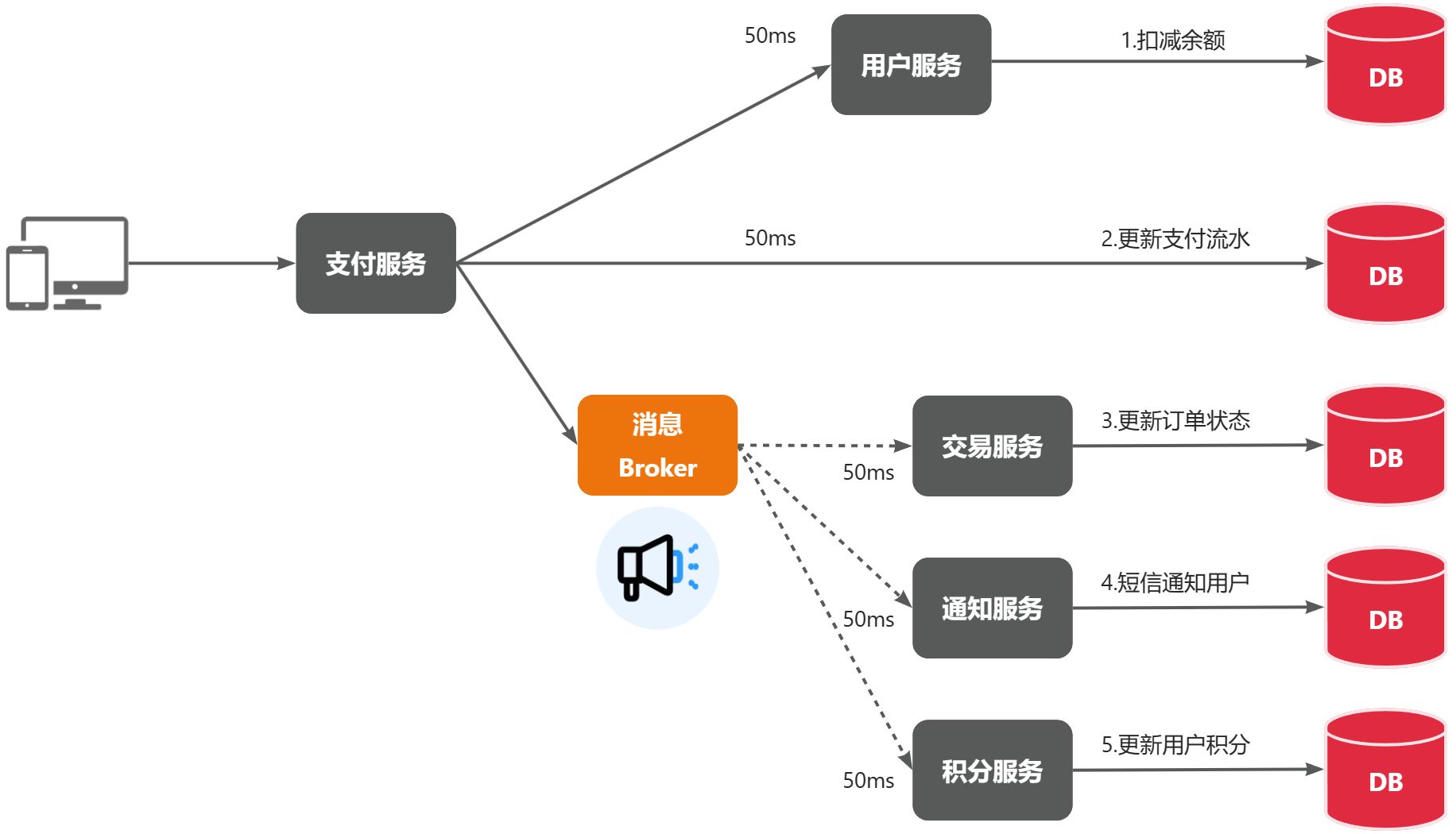
异步调用是一种基于消息通知的交互模式。调用方(消息发送者)只需把任务消息发送给消息代理(Broker),就可以立即返回,无需等待服务提供方(消息接收者)处理完成。
这就像你点了外卖,下单后不用一直等在门口,而是可以先去做别的事,外卖员(消息代理)会把餐送到你手上。
异步调用的核心角色
消息发送者:发起调用的一方,比如图中的支付服务。
消息代理(Broker):负责暂存、转发消息的中间件,类似微信服务器,保证消息可靠传递。
消息接收者:处理消息的服务,比如交易服务、通知服务、积分服务等。
优点:
1、耦合度低,拓展性强
支付服务只需发送一条 "支付完成" 的消息,新增的业务服务(如优惠券发放)只需订阅该消息即可,无需修改支付服务的代码。
2、无需等待,性能好
支付服务只需要处理扣减余额和发送消息这两个核心步骤,耗时从原来的 300ms 缩短到 100ms,用户体验明显提升。
3、故障隔离
即使通知服务或积分服务出现故障,也不会影响支付服务的核心流程,消息代理会缓存消息,等服务恢复后再重新投递。
4、流量削峰填谷
在大促等高并发场景下,消息代理可以缓存大量消息,然后匀速分发给下游服务,避免下游服务被瞬间流量冲垮。
缺点
1、不能立即得到调用结果,时效性差
2、不确定下游业务执行是否成功
3、业务安全依赖于broker的可靠性
适用场景
异步调用适合非核心流程、对实时性要求不高的场景,比如:
-
支付成功后的短信通知、积分发放。
-
电商订单创建后的物流同步、库存扣减。
-
系统日志上报、数据异步统计。
MQ(message queue)
MQ(消息队列)技术选型
MQ(Message Queue)就是异步调用里的 Broker,负责存储和转发消息,是实现异步通信的核心组件。目前常见的实现方案就是消息队列(MessageQueue),简称为MQ. 目比较常见的MQ实现:
-
ActiveMQ
-
RabbitMQ
-
RocketMQ
-
Kafka
下面给大家介绍几种常见MQ的对比;
| 特性 | RabbitMQ | ActiveMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 公司 / 社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP、XMPP、SMTP、STOMP | OpenWire、STOMP、REST、XMPP、AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
1、RabbitMQ
核心优势:基于 Erlang 开发,性能稳定,延迟低(微秒级),支持多种协议,社区成熟,运维工具完善。
适用场景:对可靠性和延迟敏感的场景,如金融支付、即时通信、订单确认等中小规模消息场景。 不足:单机吞吐量一般,不适合超大规模的高并发场景。
2、Kafka
核心优势:分布式、高吞吐、低延迟,专为大数据场景设计,支持海量消息的实时处理。
适用场景:日志收集、大数据实时计算、监控数据上报等超高吞吐量场景。
不足:消息可靠性一般,不适合对消息丢失零容忍的金融场景,功能相对单一(侧重消息转发而非复杂路由)。
据统计,目前国内消息队列使用最多的还是RabbitMQ,再加上其各方面都比较均衡,稳定性也好。
RabbitMQ架构框图
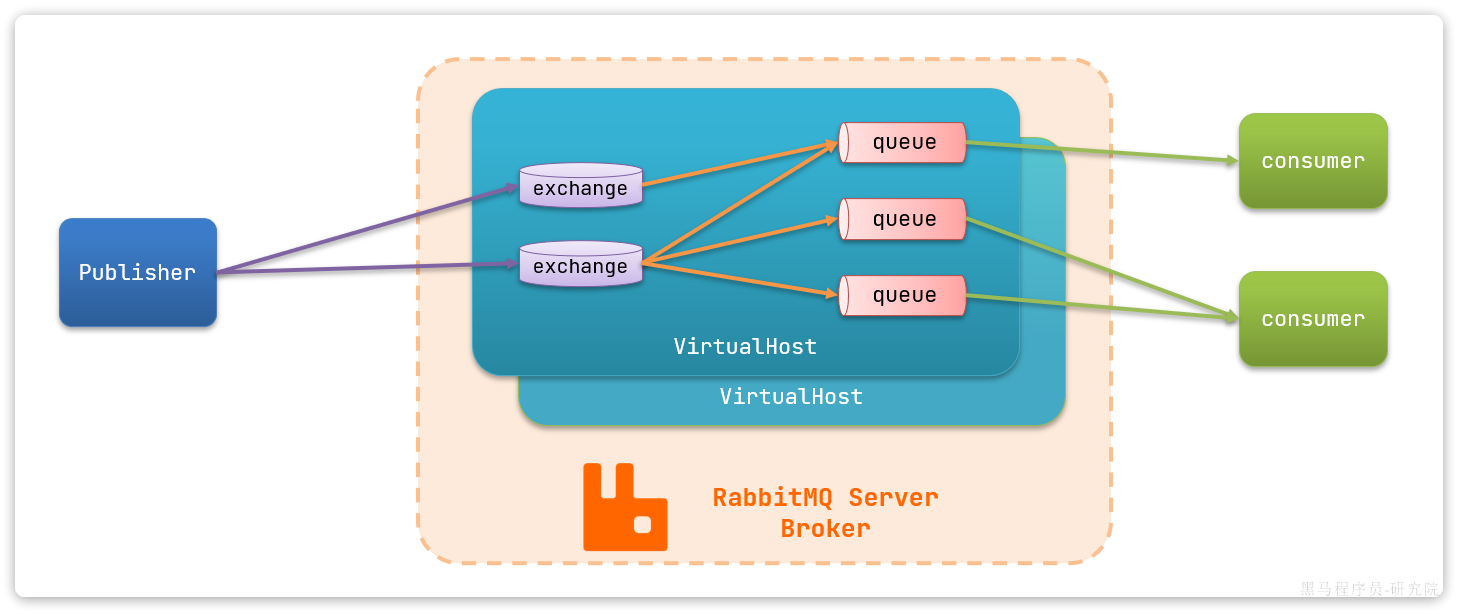
一、从外到内,整个架构分为三层:
-
消息生产者(Publisher):消息的发起方,负责生产并发送消息到 RabbitMQ Broker。
-
RabbitMQ Broker(服务端):核心的消息中间件服务,包含虚拟主机(VirtualHost)、交换机(Exchange)、队列(Queue)等核心组件,负责存储和转发消息。
-
消息消费者(Consumer):消息的接收方,从队列中获取并处理消息。
RabbitMQ Server (Broker)
RabbitMQ Server (Broker)是 RabbitMQ 的服务端进程,可以包含多个VirtualHost来实现资源隔离。
1、VirtualHost(虚拟主机)
相当于一个独立的 "小型 RabbitMQ 实例",用于实现不同业务 / 用户的资源隔离。 每个 VirtualHost 拥有独立的 Exchange、Queue、用户和权限,不同 VirtualHost 的资源完全隔离,适合多租户场景。
2、Exchange(交换机)
作用:接收来自 Publisher 的消息,并根据绑定规则(Binding Key)和路由策略(Routing Key)将消息路由到对应的 Queue。
常见类型:Direct(精准匹配)、Topic(模糊匹配)、Fanout(广播)、Headers(头信息匹配)。
3、Queue(队列)
作用:存储消息的容器,是消息的最终存储单元,Consumer 只能从 Queue 中获取消息。 核心特点:
- 消息持久化:可以配置为持久化队列,Broker 重启后消息不丢失。
- 先进先出(FIFO):默认按消息发送顺序存储和消费。
- 多消费者竞争:一个 Queue 可以被多个 Consumer 绑定,但一条消息只会被一个 Consumer 消费。
对于小型企业而言,出于成本考虑,我们通常只会搭建一套MQ集群,公司内的多个不同项目同时使用。这个时候为了避免互相干扰, 我们会利用
virtual host的隔离特性,将不同项目隔离。一般会做两件事情:
给每个项目创建独立的运维账号,将管理权限分离。
给每个项目创建不同的
virtual host,将每个项目的数据隔离。
举例
bash
docker run \
-e RABBITMQ_DEFAULT_USER=itheima \
-e RABBITMQ_DEFAULT_PASS=123321 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
--network hmall \
-d \
rabbitmq:3.8-management我们在此之前需要先创建一个网络: docker network create hmall .
如果后续启动其他微服务容器(如支付、订单服务),也加上 --network hmall 参数,这些容器就能直接通过 mq 这个容器名访问 RabbitMQ,无需写服务器 IP,避免网络配置问题。
2、创建完容器之后:
docker ps | grep mq 检查 MQ 容器状态,确保容器是Up运行状态 如果输出里有Up字样,说明容器正常;
如果没有,先重启容器:docker restart mq 访问http://服务器公网IP:15672
注意:如果是阿里云 / 腾讯云等云服务器,必须在控制台的安全组中开放 15672 端口,否则外网(本地浏览器、服务器内 wget/curl)都访问不了,这是云服务器的常见坑!
安全组规则:入方向,允许 TCP 协议,端口 15672,源地址 0.0.0.0/0(所有地址可访问)。
可以看到在安装命令中有两个映射的端口:
-
15672:RabbitMQ提供的管理控制台的端口
-
5672:RabbitMQ的消息发送处理接口
总结:本文介绍了同步调用,异步调用的定义,优缺点,适用场景;还介绍了MQ(消息队列)技术选型 ,RabbitMq和Kafka的核心优势,不足,使用场景;并介绍了RabbitMQ的架构框(VirtualHost,exchange,Queue);并实战创建一个docker来去拉取rabbitmq的镜像;访问其控制台;