第一模块:索引与存储引擎(内核级深度)
1. 为什么 MySQL InnoDB 选择 B+ 树作为索引结构?(不仅要对比,还要说出量化指标)
普通回答:因为 B+ 树层高低,I/O 次数少。
深度回答:
你需要从硬件特性和数据结构对比两个维度阐述:
磁盘 I/O 的代价:
数据库的瓶颈在于磁盘 I/O。机械硬盘随机读写只有 100 IOPS 左右。
B+ 树的"矮胖"特性:InnoDB 页默认 16KB。假设主键是 bigint (8字节),指针 (6字节)。非叶子节点能存 16384 / (8+6) ≈ 1170 个指针。
量化计算:3 层 B+ 树能存 1170 * 1170 * 16(假设叶子节点存16条数据)≈ 2000万行数据。
结论:查询 2000 万行表,只需要 3次 I/O(且根节点常驻内存,实际可能仅 1-2 次)。
为什么不用 B 树?
B 树的非叶子节点也存 Data。这导致单页能存的索引变少,树变高(瘦高),I/O 增加。
B 树不支持范围查询的高效遍历(需要中序遍历),而 B+ 树叶子节点有双向链表,范围查询(BETWEEN, >)直接扫链表即可,极其适合数据库场景。
为什么不用 Hash?
Hash 是 O(1),但无法处理范围查询和排序,仅适用于精确匹配(如 Redis)。
为什么不用跳表(Skip List)?(Redis 用了,为什么 MySQL 不用?)
跳表是链表结构,数据分散在不同内存页。MySQL 是基于Page(页)管理的,B+ 树相邻数据在同一页,能利用局部性原理和预读机制,缓存命中率远高于跳表。
2. 聚簇索引与二级索引的本质区别?以及"覆盖索引"的底层原理?
深度回答:
聚簇索引 (Clustered Index):
本质:数据文件本身就是索引文件。叶子节点存储了完整的行数据(Row Data)。
代价:因为数据都在叶子上,插入新数据如果主键无序(如 UUID),会导致页分裂 (Page Split),产生大量磁盘碎片和随机 I/O。所以推荐用自增 ID。
二级索引 (Secondary Index):
本质:叶子节点存的是 索引列值 + 主键 ID。
回表:先查二级索引拿到主键 ID,再回聚簇索引查完整数据。多一次 B+ 树扫描。
覆盖索引 (Covering Index) 的深度理解:
SQL:SELECT id, age FROM user WHERE age = 20;
如果 age 建了索引,叶子节点里已经有了 age 和 id。
核心优势:直接从辅助索引树返回数据,无需回表,甚至无需读取数据页(物理 I/O 降为 0,仅逻辑 I/O)。
3. 联合索引的底层存储结构与"最左前缀"的本质?
深度回答:
存储结构:假设索引是 (a, b)。B+ 树是先按 a 排序;在 a 相同的情况下,再按 b 排序。全局看 a 是有序的,但 b 是无序的。
最左前缀本质:
WHERE a=1 AND b=2:先找 a=1,再在 a=1 的区间里找 b=2(利用了局部有序性)。
WHERE b=2:跳过 a 直接找 b,因为 b 全局无序,无法利用二分查找,只能全表扫描。
索引下推 (ICP, Index Condition Pushdown):
MySQL 5.6 优化。对于 WHERE name like 'Li%' AND age = 20(索引 name, age)。
老版本:查出所有 'Li' 开头的主键,回表,再判断 age。
ICP:在二级索引遍历时,直接判断 age=20,不符合的直接跳过,减少回表次数。
第二模块:事务与并发控制(MVCC 与 锁的细节)
4. 彻底讲透 MVCC(多版本并发控制)的实现原理?
普通回答:通过 Undo Log 实现版本链。
深度回答:
必须讲出 Read View 的 4 个核心字段 和 可见性算法。
三个隐式字段:
DB_TRX_ID:最后修改该行的事务 ID。
DB_ROLL_PTR:回滚指针,指向 Undo Log 中的上一个版本。
DB_ROW_ID:隐藏主键。
Read View (读视图) 结构:
m_ids:生成 Read View 时,当前系统中**活跃(未提交)**的事务 ID 列表。
min_trx_id:活跃列表中最小的 ID。
max_trx_id:生成 Read View 时,系统分配给下一个事务的 ID。
creator_trx_id:当前事务自己的 ID。
可见性判断算法(核心):
拿着数据的 trx_id 跟 Read View 比:
落在绿色区间 (trx_id < min_trx_id):说明是以前提交的,可见。
落在红色区间 (trx_id >= max_trx_id):说明是未来生成的,不可见。
落在黄色区间 (中间):
如果 trx_id 在 m_ids 列表里:说明还没提交,不可见(除非是自己改的)。
如果不在列表里:说明已经提交了,可见。
RC 与 RR 的区别:
RC:每次 SELECT 都重新生成 Read View(能看到新提交的)。
RR:第一次 SELECT 生成 Read View,之后复用(保证可重复读)。
5. 幻读(Phantom Read)到底解决了没有?
深度回答:
InnoDB 在 RR 级别下,**"部分"**解决了幻读,但不是 100%。
快照读 (Snapshot Read):SELECT * FROM table。
解决方式:MVCC。通过 Read View,新插入的数据 trx_id 很大,我看不到,所以没幻读。
当前读 (Current Read):SELECT ... FOR UPDATE / UPDATE。
解决方式:Next-Key Lock。锁住记录 + 间隙。比如 SELECT * FROM user WHERE id > 10 FOR UPDATE,它会锁住 (10, +∞) 这个范围,别的事务想插入 id=11 会被阻塞。
特殊场景(幻读依然存在):
如果你先用快照读(没幻读),然后自己手贱去 UPDATE 了一条别人刚插入的数据(因为 UPDATE 是当前读,不看版本),更新成功后,你的 Read View 里的 trx_id 变成了你自己的,下次再 SELECT 就能看到这条数据了------幻读产生。
第三模块:日志与一致性(WAL 与 2PC)
6. Redo Log 和 Binlog 的区别?为什么需要两份日志?
深度回答:
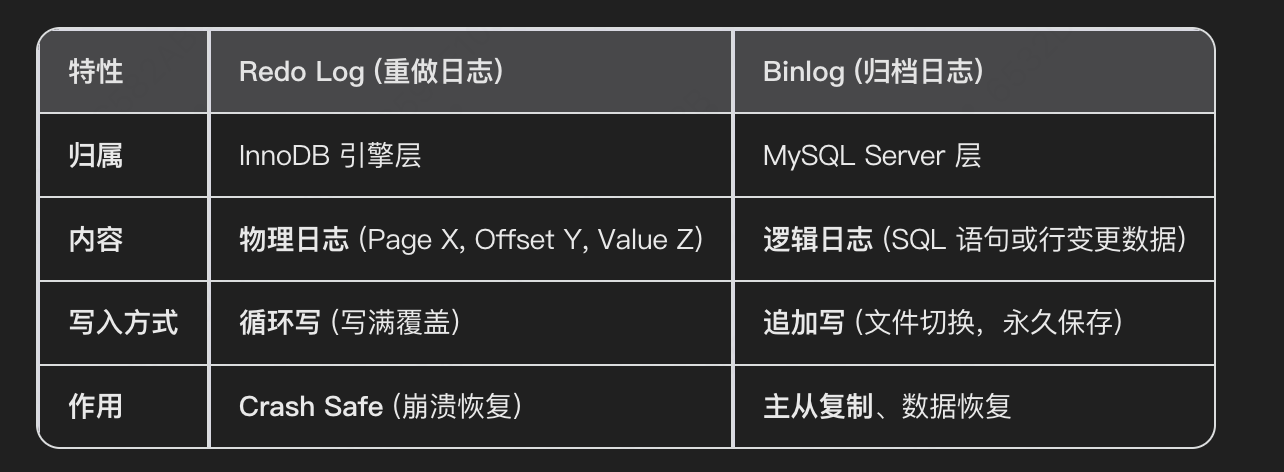
为什么不能只要一个?
把问题拆解开,一点点把这个逻辑盘清楚。
问题一:为什么 Binlog 不能用来做崩溃恢复?
核心痛点:Binlog 不知道"物理状态"。
想象这样一个场景:
你有一本书(数据库文件),你要把第 10 页的第 5 行字,从"A"改成"B"。
Binlog (老板的记账本):
它记录的是:"把第 10 页第 5 行改成 B"。
它是逻辑的,它只管**"你要做什么",不管"你做完了没"**。
崩溃场景:
你刚在内存里把"A"改成了"B",还没来得及把这一页纸写回书架(磁盘)上,突然停电了。
重启后:
MySQL 拿着 Binlog 一看:"哦,这里有一条记录说要改成 B"。
关键问题来了:MySQL 不知道这条修改到底有没有写进磁盘。
也许磁盘上已经是 B 了(不用再改),也许磁盘上还是 A(需要重做)。
Binlog 没有记录 "CheckPoint(检查点)",它不知道磁盘上的数据页到底是旧的还是新的。如果盲目地重做一遍,可能会覆盖掉其他并发事务的修改,或者导致数据错乱。
对比 Redo Log (工人的施工日志):
Redo Log 记录的是物理修改:"在第 10 页,偏移量 500 的位置,写入数据 B"。
更重要的是,InnoDB 引擎通过 LSN (Log Sequence Number,日志序列号) 机制,精确地知道磁盘上的数据页处于什么版本。
重启时,InnoDB 只要看一眼磁盘页上的 LSN,就知道这个页是不是旧的。如果是旧的,就用 Redo Log 覆盖一下;如果是新的,就跳过。Binlog 做不到这一点。
问题二:为什么 Redo Log 不能用来做全量备份/主从复制?
核心痛点:Redo Log 是"循环写"的,存不住历史。
Redo Log 的物理结构:
它不是无限增长的文件,它通常是固定大小的(比如 4 个文件,每个 1GB)。
它像一个 "圆环"。写满了一圈,就会回到开头,把最旧的日志覆盖掉。
为什么不能做全量备份?
假设你要恢复到 1 年前的数据。
Redo Log 早就被覆盖了 10000 圈了,1 年前的记录早就灰飞烟灭了。
所以你没法用 Redo Log 找回很久以前的历史数据。
为什么不能做主从复制?
生态兼容性:MySQL 的生态圈(主从复制、Canal 数据同步、数据迁移)都是基于 Binlog 的。
引擎绑定:Redo Log 是 InnoDB 特有的。如果你的从库用的是 MyISAM 引擎,或者你想把数据同步到 Elasticsearch/Hadoop,它们根本看不懂 InnoDB 的物理 Redo Log(那是二进制的页结构),但它们能看懂 Binlog(标准的 SQL 或行数据)。
总结:为什么必须是"双剑合璧"?
Redo Log (物理日志):
特长:快(顺序写)、准(物理定位)。
职责:专门负责**"保命"(Crash Safe)。只要断电重启,我就能把内存里没来得及刷盘的脏页恢复出来。
缺陷:空间有限,记不住历史。
Binlog (逻辑日志):
特长:全(无限追加)、通(通用格式)。
职责:专门负责 "传承"**(主从复制、历史归档)。只要有 Binlog,我就能把数据库还原到过去任意一秒的状态。
缺陷:不懂底层物理页,救不了急(无法用于崩溃恢复)。
一句话总结:
Redo Log 保证了"当下"不死,Binlog 保证了"过去"不丢。 缺一不可。
7. 详细描述两阶段提交 (2PC) 及其优化 (Group Commit)?
深度回答:
2PC 流程:
Prepare 阶段:写 Redo Log,标记为 prepare。
Binlog 阶段:写 Binlog。
Commit 阶段:写 Redo Log,标记为 commit。
目的:保证 Redo 和 Binlog 的逻辑一致性。如果中间断电,重启时检查 Binlog 是否完整,完整则提交,不完整则回滚。
性能瓶颈与优化 (Group Commit):
问题:每次提交都要刷两次盘(Redo一次,Binlog一次),TPS 极低。
组提交 (Group Commit):
MySQL 不会来一个事务刷一次盘。
它会把多个并发事务的 Redo Log 攒在一起刷盘。
也会把多个事务的 Binlog 攒在一起刷盘。
效果:大幅降低磁盘 IOPS 消耗,提升吞吐量。
第四模块:实战与调优(面试加分项)
8. count(*)、count(1)、count(id)、count(字段) 哪个快?
深度回答:
原理:count() 是聚合函数,需要遍历索引树。
count(字段):最慢。如果字段允许 NULL,还需要把值取出来判断是否为 NULL。
count(id):引擎遍历整张表,把 ID 取出来给 Server 层,Server 层判断不为空加 1。
count(1):引擎遍历整张表,但不取值。Server 层对于每一行放个数字"1"进去,判断不为空加 1。
count():最快(MySQL 专门优化)。
它不取值。
InnoDB 会自动选择最小的那棵二级索引树进行遍历(成本最低)。
结论:直接写 count(),别搞花里胡哨的。
9. 深分页优化:LIMIT 1000000, 10 为什么慢?怎么解?
深度回答:
慢的原因:
MySQL 需要查出 1000010 条记录。
如果用 SELECT ,这 100 万条数据都要回表读取数据页,产生海量随机 I/O,最后丢弃前 100 万条。
解法 1:延迟关联 (Deferred Join)
SELECT t1. FROM table t1 JOIN (SELECT id FROM table LIMIT 1M, 10) t2 ON t1.id = t2.id;
原理:子查询只查 ID(覆盖索引,不回表),拿到 10 个 ID 后,再去主表查 10 条完整数据。
解法 2:游标法 (Seek Method)
SELECT * FROM table WHERE id > 1000000 LIMIT 10;
原理:利用 B+ 树索引直接定位到 ID=1000000 的位置,向后扫 10 条。效率 O(1)。
10. 线上 CPU 飙高 100%,如何排查?
深度回答(SRE 视角):
定位进程:top -c 确认是 mysqld 占用。
定位线程:top -H -p 找到消耗 CPU 最高的线程 ID。
定位 SQL:
查询 performance_schema.threads 表,根据线程 ID 找到对应的 SQL 语句。
或者直接看 SHOW PROCESSLIST 里的 State(是否在 Sending data 或 Sorting)。
分析原因:
慢查询:全表扫描、索引失效(EXPLAIN 分析)。
QPS 暴增:缓存穿透。
死锁:大量锁等待消耗 CPU。