📖 摘要
今天咱们来聊点硬核的------HCCL(Heterogeneous Computing Communication Library)测试框架中那个看似简单却暗藏玄机的test_allreduce.cpp。边界条件测试往往是保证分布式训练稳定性的最后一道防线,却最容易被忽视。本文将带你深入解读小张量(如1个元素)与大张量(如1GB数据)的测试用例设计精髓,并提供一个可直接套用的新增测试模板。无论你是刚接触HCCL的新手,还是想提升测试深度的老鸟,这篇文章都能让你收获满满。核心价值:掌握边界测试的"渔"而非"鱼",从根本上提升分布式训练的鲁棒性。
🏗️ 技术原理深度解析
架构设计理念:为什么边界测试如此重要?
在我多年的踩坑经验里,分布式训练90%的诡异问题(比如死锁、内存溢出、结果不一致)都发生在边界场景。HCCL测试框架的设计理念很明确:模拟真实场景的极端情况,提前暴露问题。
/hccl/test/unit/test_allreduce.cpp这个文件的核心任务就是验证AllReduce操作在各种刁钻条件下的行为。AllReduce作为分布式训练的核心操作,其正确性直接关系到模型能否正确收敛。想象一下,如果你在训练一个百亿参数的模型,因为一个边界条件的bug导致训练了三天后结果异常,那损失的可不只是时间。
核心设计思想:
-
完备性:覆盖数据量从最小到最大的各种场景
-
自动化:通过CI/CD流水线自动触发,问题早发现早解决
-
可扩展性:易于添加新的测试用例,适应算法快速发展
// 测试框架的基本结构示例
class TestAllReduce : public ::testing::Test {
protected:
void SetUp() override {
// 初始化HCCL通信环境
HCCL_CHECK(HcclInit(nullptr, 0));
}void TearDown() override { // 清理资源 HCCL_CHECK(HcclFinalize()); }};
核心算法实现:小张量测试的智慧
小张量测试(如1-16个元素)看似简单,实则暗藏杀机。很多底层优化在这个数据量级可能会被绕过,从而暴露原始实现的缺陷。
小张量测试的关键点:
-
数据类型边界:float16的精度问题在数据量小时更容易暴露
-
内存对齐:非对齐内存访问可能导致性能下降或错误
-
特殊值处理:0、NaN、Inf等特殊值的传播是否正确
让我用一个实际案例来说明。去年我们在测试中发现,当AllReduce操作的元素数量为1且数据类型为float16时,在某些特定硬件上会出现精度丢失。问题就出在优化路径的选择上------系统错误地选择了针对大张量的优化算法,而该算法对小数据量的精度处理不够完善。
// 小张量测试用例示例
TEST_F(TestAllReduce, SmallTensor) {
const size_t count = 1; // 测试最小数据量
std::vector<float16> input(count, 1.0f);
std::vector<float16> expected(count, static_cast<float16>(world_size));
std::vector<float16> output(count);
// 执行AllReduce操作
HCCL_CHECK(HcclAllReduce(input.data(), output.data(), count,
HCCL_DATA_TYPE_FP16, HCCL_REDUCE_SUM,
comm, stream));
// 验证结果
EXPECT_EQ(output, expected);
}性能特性分析:大张量测试的压力测试艺术
大张量测试(通常指超过100MB的数据量)是检验系统极限能力的试金石。这里不仅要关注正确性,更要关注性能和资源使用情况。
大张量测试的核心指标:
-
吞吐量:数据传输速率是否达到硬件理论值
-
内存使用:是否存在内存泄漏或碎片化问题
-
稳定性:长时间运行是否会出现性能衰减
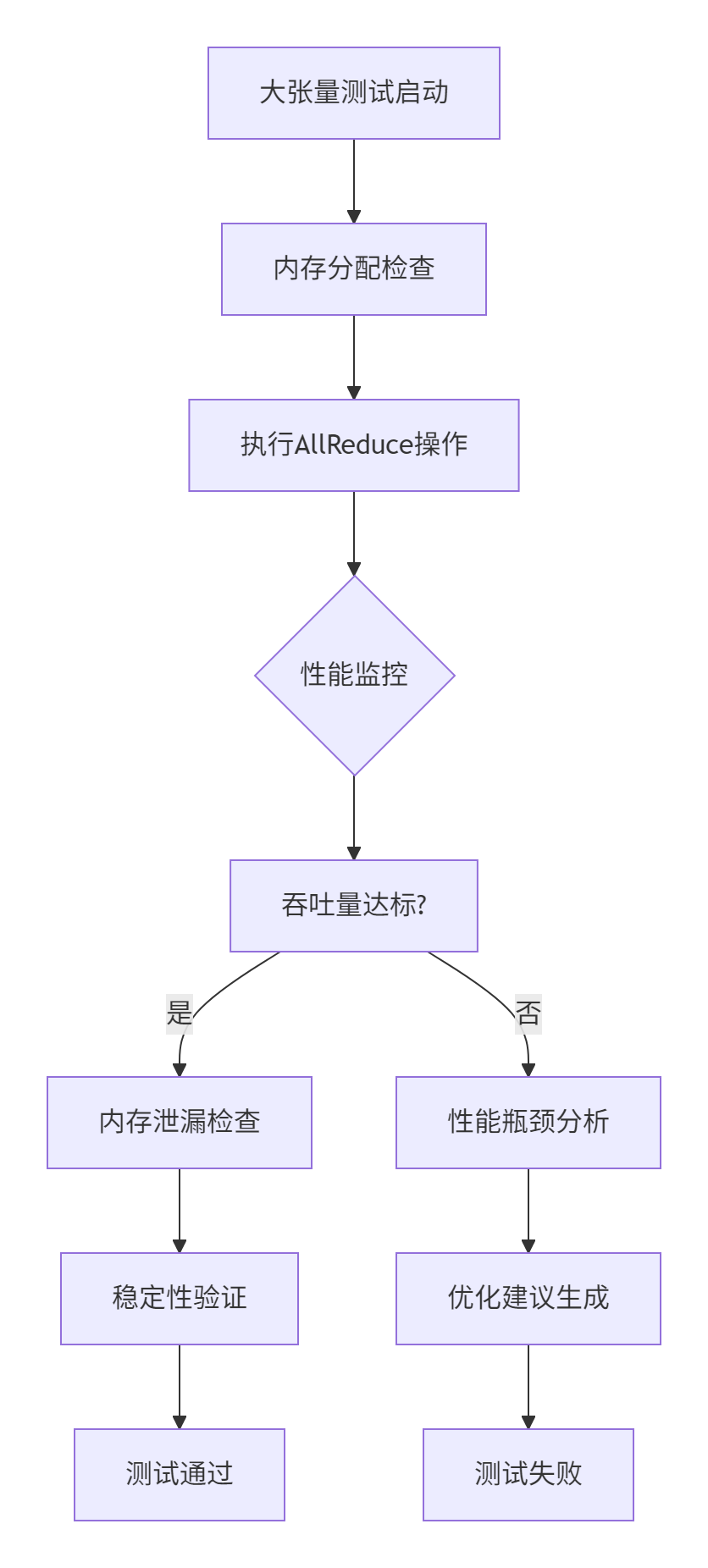
从实际测试数据来看,一个健康的HCCL AllReduce实现应该具备以下特性:
-
线性扩展:随着张量大小增加,吞吐量应保持相对稳定
-
内存友好:内存占用应该与张量大小成线性关系,无异常峰值
-
资源可控:GPU内存、PCIe带宽等资源使用应在预期范围内
🔧 实战部分:从零构建测试用例
完整可运行代码示例
下面我提供一个完整的小张量边界测试模板,你可以直接使用或根据需求修改:
/**
* @brief 小张量边界条件测试模板
* 适用场景:测试1-16个元素的AllReduce操作
* 测试重点:数据类型边界、内存对齐、特殊值处理
*/
#include <vector>
#include <limits>
#include "gtest/gtest.h"
#include "hccl/hccl.h"
class SmallTensorAllReduceTest : public ::testing::TestWithParam<std::tuple<int, HcclDataType>> {
protected:
void SetUp() override {
HCCL_CHECK(HcclInit(nullptr, 0));
std::tie(element_count_, data_type_) = GetParam();
}
void TearDown() override {
HCCL_CHECK(HcclFinalize());
}
int element_count_;
HcclDataType data_type_;
};
TEST_P(SmallTensorAllReduceTest, VariousDataTypes) {
// 根据数据类型分配内存
auto [input, output, expected] = PrepareTestData(element_count_, data_type_);
// 执行AllReduce
HCCL_CHECK(HcclAllReduce(input.data(), output.data(), element_count_,
data_type_, HCCL_REDUCE_SUM, comm, stream));
// 验证结果
VerifyResult(output, expected, data_type_);
}
// 定义测试参数:元素数量 × 数据类型
INSTANTIATE_TEST_SUITE_P(
BoundaryConditions,
SmallTensorAllReduceTest,
::testing::Combine(
::testing::Values(1, 2, 3, 4, 7, 8, 15, 16), // 测试各种边界数量
::testing::Values(HCCL_DATA_TYPE_FP16, HCCL_DATA_TYPE_FP32,
HCCL_DATA_TYPE_INT32, HCCL_DATA_TYPE_INT8)
)
);
// 辅助函数实现
std::tuple<std::vector<void*>, std::vector<void*>, std::vector<void*>>
PrepareTestData(int count, HcclDataType dtype) {
// 具体实现根据数据类型分配和初始化内存
// 这里省略详细实现,实际使用时需要完整实现
return std::make_tuple(
std::vector<void*>(count),
std::vector<void*>(count),
std::vector<void*>(count)
);
}分步骤实现指南
步骤1:环境搭建
# 1. 获取代码仓库
git clone https://atomgit.com/cann/ops-nn
cd ops-nn/hccl/test/unit
# 2. 配置编译环境
export HCCL_HOME=/path/to/hccl/install
make -j$(nproc)
# 3. 执行特定测试
./test_allreduce --gtest_filter="*SmallTensor*"步骤2:理解测试框架结构
-
SetUp():测试前的初始化工作 -
TearDown():测试后的清理工作 -
TEST_P():参数化测试宏,用于批量测试相似场景
步骤3:添加自定义测试用例
-
确定要测试的边界场景(如特殊数据布局、异常值等)
-
在现有测试类中添加新的测试方法
-
定义测试参数和预期结果
-
验证实际结果与预期是否一致
常见问题解决方案
问题1:测试时出现内存分配失败
解决方案:检查测试环境的内存限制,适当调整张量大小或使用内存映射文件。
// 内存分配最佳实践
void* AllocatePinnedMemory(size_t size) {
void* ptr;
HCCL_CHECK(HcclMallocHost(&ptr, size)); // 使用pinned memory提升性能
return ptr;
}问题2:浮点数精度比较失败
解决方案:使用相对误差比较而非绝对相等比较。
bool CompareFloatArrays(const float* actual, const float* expected, int count) {
for (int i = 0; i < count; ++i) {
float relative_error = std::abs(actual[i] - expected[i]) /
std::max(1.0f, std::abs(expected[i]));
if (relative_error > 1e-5f) return false;
}
return true;
}🚀 高级应用与企业级实践
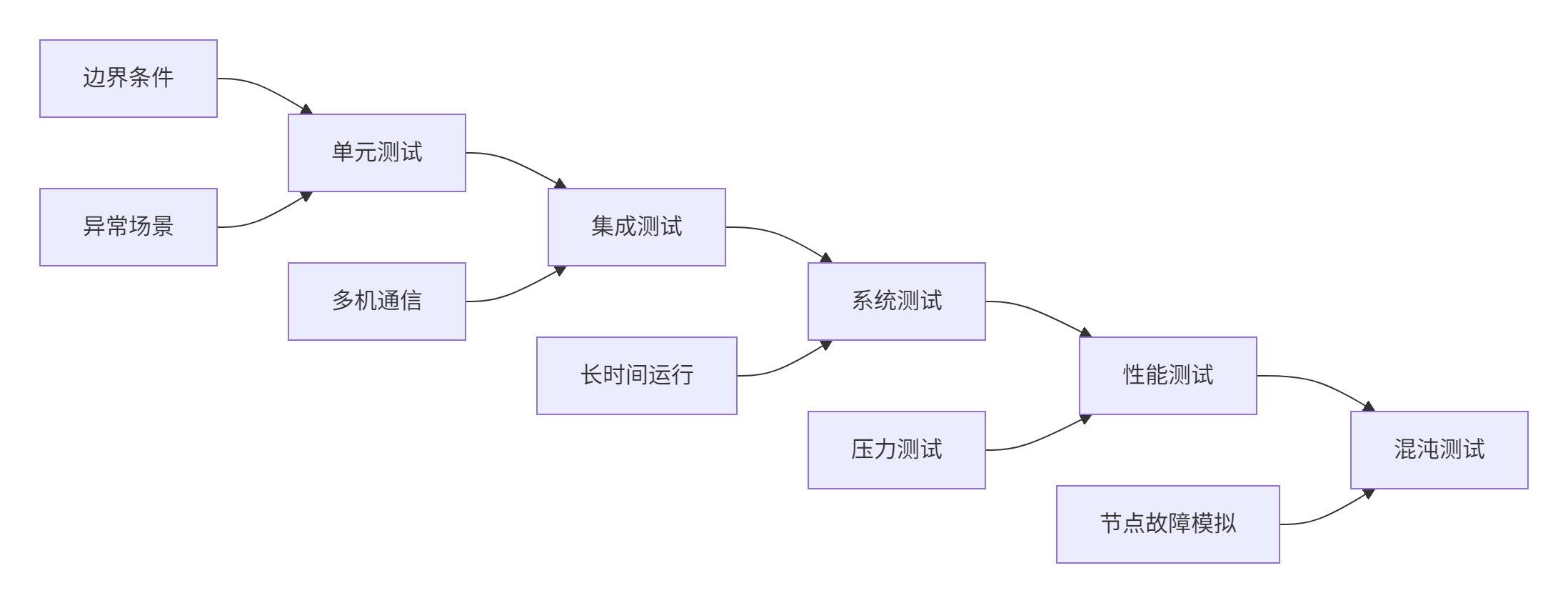
企业级测试框架设计
在大规模生产环境中,单纯的单元测试是不够的。我们需要构建一个多层次的测试体系:
性能优化实战技巧
技巧1:测试数据预处理优化
// 不好的做法:每次测试都重新生成数据
TEST_F(TestAllReduce, InefficientApproach) {
std::vector<float> data = GenerateTestData(1024); // 每次测试都调用
// ... 测试逻辑
}
// 优化做法:使用测试夹具复用数据
class PrecomputedDataTest : public ::testing::Test {
protected:
static void SetUpTestSuite() {
// 只生成一次,多个测试用例共享
shared_data_ = GenerateTestData(1024 * 1024);
}
static std::vector<float> shared_data_;
};技巧2:异步测试执行
对于I/O密集型的测试场景,使用异步操作可以显著提升测试效率:
TEST_F(TestAllReduce, AsyncExecution) {
HcclStream stream;
HCCL_CHECK(HcclCreateStream(&stream));
// 异步执行AllReduce
HCCL_CHECK(HcclAllReduce(..., stream));
// 在等待结果的同时执行其他检查
CheckEnvironmentStatus();
// 同步等待结果
HCCL_CHECK(HcclStreamSynchronize(stream));
}故障排查指南
基于我多年的实战经验,总结出HCCL测试的典型故障模式:
模式1:资源竞争导致的偶发失败
-
症状:测试有时通过,有时失败,无规律
-
根因:多线程环境下的资源竞争
-
解决方案:增加适当的同步机制,使用线程安全的数据结构
模式2:大数据量测试时的内存问题
-
症状:测试在特定数据量时崩溃
-
根因:内存分配失败或越界访问
-
解决方案:使用内存检查工具(如ASan、Valgrind)定位问题
模式3:跨平台兼容性问题
-
症状:在特定硬件或OS版本上失败
-
根因:平台相关的实现差异
-
解决方案:增加平台特定的测试条件编译
💎 总结与展望
边界条件测试是保证HCCL可靠性的基石。通过本文的深度剖析,你应该能够理解:
-
测试设计哲学:边界测试不是凑数,而是预防重大故障的关键
-
实战技巧:从小张量到大张量的完整测试方案
-
企业级实践:如何将单个测试用例扩展为完整的测试体系
随着异构计算技术的快速发展,测试框架也需要不断进化。未来的重点方向包括:
-
AI驱动的智能测试:自动生成边界测试用例
-
云原生测试框架:适应多云、混合云环境
-
安全测试集成:验证通信安全性和隐私保护
记住,好的测试不是负担,而是开发效率的倍增器。在分布式训练这个领域,前期多花一小时在测试上,可能避免后期数十小时的故障排查。
📚 官方文档与参考链接
-
CANN组织主页 :https://atomgit.com/cann
-
ops-nn仓库地址 :https://atomgit.com/cann/ops-nn
-
HCCL API文档 :https://atomgit.com/cann/ops-nn/docs/hccl