提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
一、先看一下图
可以愉快的看到,上一期中奖概率还是挺高的,能讨论的也只有上一期。我这里预想是这样的,中奖率有一个区间,当我的号码落在这个区间里,就是说是一组老彩民认为可能会中奖的号码,如果不在,太高或者太低,也许就是不会中奖的,因为长期来说不符合自然规律。
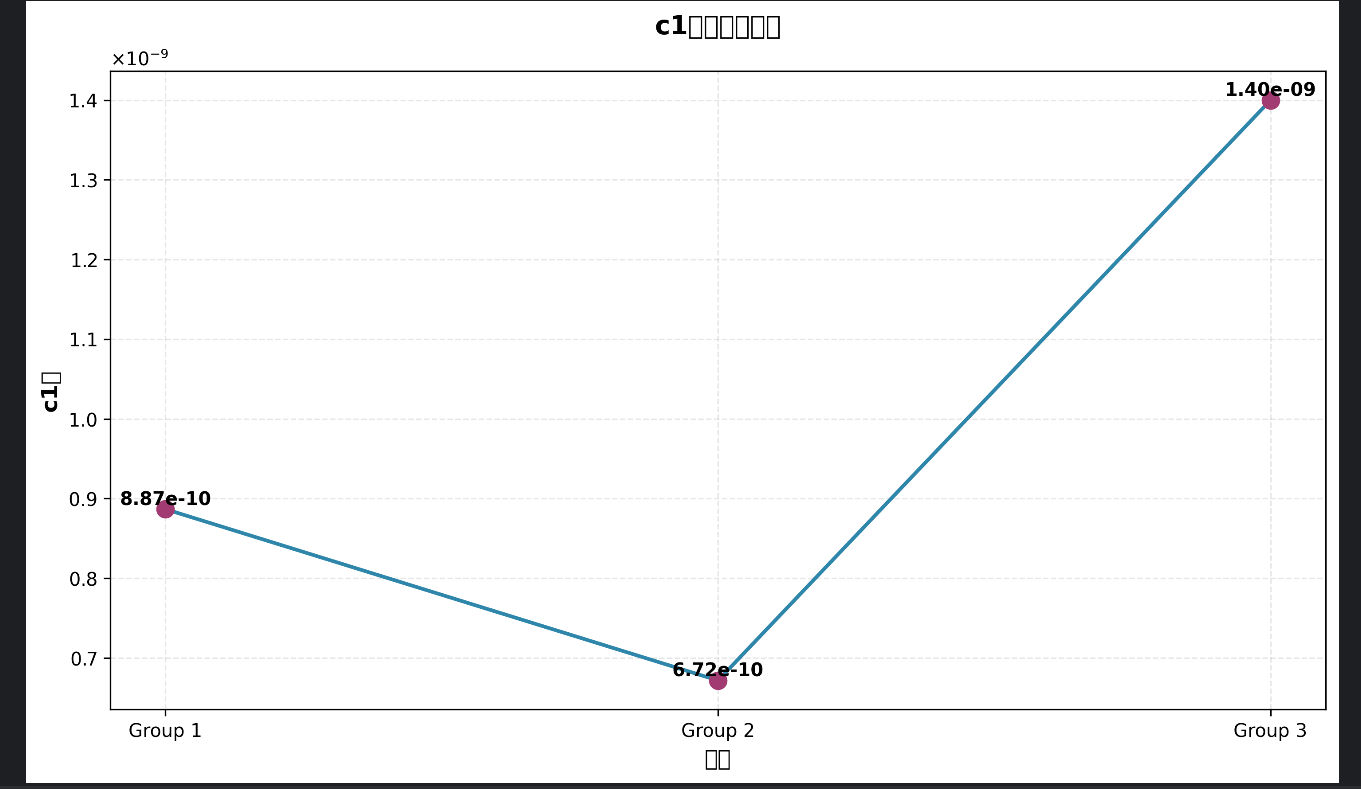
二、讲解计算方法
100期*6个数/33个号=18
18/18=1,所以这里用100期出现次数/18=1.。。。。。

每个数字中奖概率均等,1/33。然后相乘,得到概率,然后画图。
三、具体实现
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
# 检查文件是否存在
if os.path.exists('c1_trend.png'):
# 删除文件
os.remove('c1_trend.png')
print("已删除存在的 c1_trend.png 文件")
else:
print("c1_trend.png 文件不存在,无需删除")
# 读取CSV文件
df = pd.read_csv('data.csv')
print("从CSV文件读取的数据:")
print(df)
# 执行计算
def calculate_c1(row):
a1, a2, a3, a4, a5, a6 = row['a1'], row['a2'], row['a3'], row['a4'], row['a5'], row['a6']
# 标准化
a1 = a1 / (18 * 33)
a2 = a2 / (18 * 33)
a3 = a3 / (18 * 33)
a4 = a4 / (18 * 33)
a5 = a5 / (18 * 33)
a6 = a6 / (18 * 33)
# 计算b值
b1 = 6 * 100 / 33
b2 = (b1 ** 6) / (18 ** 6)
# 计算c1
c1 = (a1 * a2 * a3 * a4 * a5 * a6) / b2
return c1
# 应用计算
df['c1'] = df.apply(calculate_c1, axis=1)
print("\n计算结果(包含c1):")
print(df)
# 绘制c1变化趋势折线图
plt.figure(figsize=(10, 6))
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['Noto Sans CJK JP']
plt.rcParams['axes.unicode_minus'] = False
# 创建x轴标签(组名)
x_labels = df['Group']
# 绘制折线图
plt.plot(x_labels, df['c1'], marker='o', linewidth=2, markersize=8,
color='#2E86AB', markerfacecolor='#A23B72', markeredgecolor='#A23B72',
markeredgewidth=2)
# 添加数据标签
for i, (group, c1_value) in enumerate(zip(df['Group'], df['c1'])):
plt.text(i, c1_value, f'{c1_value:.2e}',
ha='center', va='bottom', fontsize=10, fontweight='bold')
# 设置图表属性
plt.xlabel('组别', fontsize=12, fontweight='bold')
plt.ylabel('c1值', fontsize=12, fontweight='bold')
plt.title('c1值变化趋势图', fontsize=14, fontweight='bold', pad=20)
# 添加网格
plt.grid(True, alpha=0.3, linestyle='--')
# 设置y轴为科学计数法显示
from matplotlib.ticker import ScalarFormatter
plt.gca().yaxis.set_major_formatter(ScalarFormatter(useMathText=True))
plt.gca().ticklabel_format(style='sci', axis='y', scilimits=(0, 0))
# 调整图表布局
plt.tight_layout()
# 保存图表
plt.savefig('c1_trend.png', dpi=300, bbox_inches='tight')
print("\nc1值变化趋势:")
for i, row in df.iterrows():
print(f"{row['Group']}: c1 = {row['c1']:.6e}")
# 计算变化率
if len(df) > 1:
print("\n变化率分析:")
for i in range(1, len(df)):
prev_c1 = df.loc[i - 1, 'c1']
curr_c1 = df.loc[i, 'c1']
change_rate = ((curr_c1 - prev_c1) / prev_c1) * 100
change_type = "增长" if change_rate > 0 else "下降"
print(f"从 {df.loc[i - 1, 'Group']} 到 {df.loc[i, 'Group']}: "
f"{change_rate:.2f}% {change_type}")
else:
print("\n只有一组数据,无法计算变化率。")
print(f"\n图表已保存为 c1_trend.png 和 c1_trend.svg")总结
目标是通过去掉最大值最小值等方法,压缩到8-13%区间,这样也许可以去掉新手选的绝对不会中的号码,可能是像布隆过滤器一样。