适用系统 :Windows 10/11、macOS 12+、Linux(Ubuntu/CentOS)
目标模型 :Qwen3 系列(含 1.8B / 7B / 32B 等版本)
前置要求 :8GB+ 内存(推荐 16GB+),无需 GPU 也可运行小模型
更新日期:2026 年 2 月
一、为什么选择 Ollama + Qwen?
| 优势 | 说明 |
|---|---|
| ✅ 一键部署 | 无需配置 Python 环境、CUDA、依赖库 |
| ✅ 自动量化 | 自动下载 GGUF 4-bit 量化模型,节省显存 |
| ✅ 跨平台支持 | Windows/macOS/Linux 全支持 |
| ✅ OpenAI 兼容 API | 可直接替换 GPT 调用 |
| ✅ 中文优化 | Qwen 对中文理解远超 Llama 系列 |
💡 2026 年现状 :Ollama 已原生支持 Qwen3 全系列模型,并启用 思考模式 (
/think)。
二、安装 Ollama
▶️ Windows
- 访问 ollama.com/download/Ol...
- 双击安装(默认安装到
C:\Users<user>\AppData\Local\Programs\Ollama) - 安装完成后自动启动服务(系统托盘出现 🐫 图标)
▶️ macOS
shell
# 方法 1:官网下载 dmg
# https://ollama.com/download/Ollama-darwin.zip
# 方法 2:使用 Homebrew(推荐)
brew install ollama
brew services start ollama▶️ Linux(Ubuntu/Debian)
bash
curl -fsSL https://ollama.com/install.sh | sh
sudo systemctl enable ollama
sudo systemctl start ollama🔍 验证安装:
bashollama --version # 输出示例:ollama version is 0.4.5
三、下载 Qwen 模型(关键步骤)
Ollama 支持多种 Qwen 版本,命名规则为:qwen3:<size>-<quant>。
📦 可用模型列表(2026 年 2 月)
| 模型名称 | 参数量 | 量化方式 | 内存需求 | 下载命令 |
|---|---|---|---|---|
qwen3:1.8b |
1.8B | Q4_K_M | ~2 GB | ollama pull qwen3:1.8b |
qwen3:7b |
7B | Q4_K_M | ~6 GB | ollama pull qwen3:7b |
qwen3:32b |
32B | Q4_K_M | ~20 GB | ollama pull qwen3:32b |
qwen3:1.8b-q8_0 |
1.8B | Q8(高精度) | ~3 GB | ollama pull qwen3:1.8b-q8_0 |
⚠️ 注意:
- 默认不加后缀 = Q4_K_M 量化(最佳性价比)
- 首次下载需 5~30 分钟(取决于网速和模型大小)
▶️ 下载示例(以 7B 为例)
bash
# 查看可用标签
ollama list
# 下载 Qwen3-7B(自动量化)
ollama pull qwen3:7b
# 输出示例:
# pulling manifest
# pulling 8d9a4e3c... 100% ▕████████████████████████████████████████▏ 4.2 GB
# verifying sha256 digest
# writing manifest
# success💡 提示:模型文件默认保存在:
- Windows:
C:\Users<user>.ollama\models- macOS:
~/.ollama/models- Linux:
~/.ollama/models
四、命令行使用 Qwen
▶️ 基础对话
arduino
ollama run qwen3:7b
>>> 你好!介绍一下你自己。▶️ 特殊指令(Qwen3 独有)
| 指令 | 功能 |
|---|---|
/think |
开启深度思考模式(慢但准确) |
/nothink |
关闭思考,快速响应 |
/clear |
清空上下文 |
/set parameter num_ctx 4096 |
设置上下文长度 |
🌰 示例:
shell>>> /think Thinking mode enabled. >>> 解释量子纠缠的原理,并举例说明。 (模型将分步推理,输出更严谨)
▶️ 多轮对话
Ollama 自动维护会话上下文,直到输入 /clear 或退出。
五、API 调用(OpenAI 兼容)
Ollama 启动后自动监听 http://localhost:11434,提供 OpenAI 兼容 API。
▶️ 请求示例(Python)
vbscript
import requests
response = requests.post(
"http://localhost:11434/api/chat",
json={
"model": "qwen3:7b",
"messages": [
{"role": "user", "content": "写一个 Python 快速排序函数"}
],
"stream": False
}
)
print(response.json()["message"]["content"])▶️ OpenAI SDK 兼容(推荐)
ini
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # 任意值均可
)
completion = client.chat.completions.create(
model="qwen3:7b",
messages=[{"role": "user", "content": "Hello!"}],
temperature=0.7
)
print(completion.choices[0].message.content)✅ 优势:现有 GPT 代码只需改两行即可切换到 Qwen!
六、可视化界面推荐
方案 1:ChatWise(免费,跨平台)
- 下载:chatwise.app
- 安装后打开 → 选择 Ollama 作为后端
- 在模型列表中选择已下载的
qwen3:7b - 享受 Markdown 渲染、代码高亮、对话管理
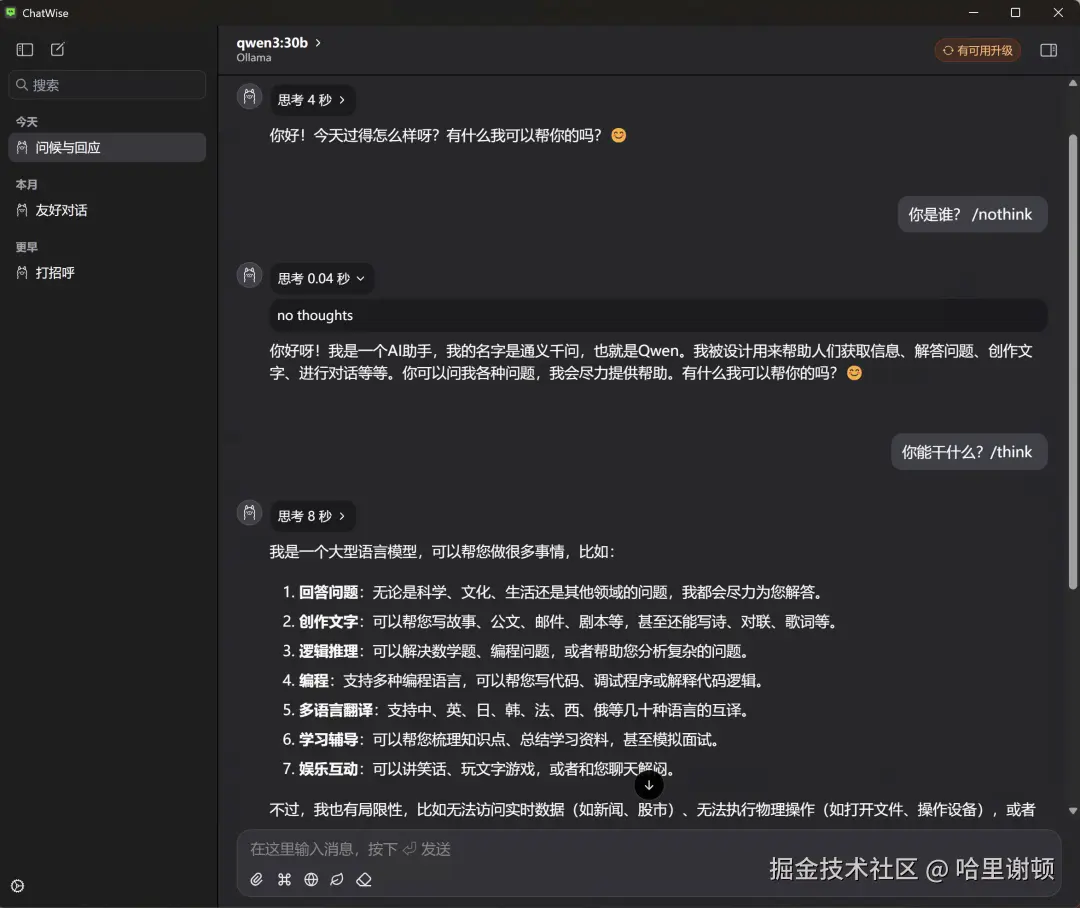
方案 2:LM Studio(macOS/Windows)
- 支持本地模型管理
- 内置性能监控
- 下载地址:lmstudio.ai
七、远程访问:让团队共享你的 Qwen
使用 Cloudflare Tunnel(免费内网穿透)
bash
# 1. 下载 cloudflared
# https://developers.cloudflare.com/cloudflare-one/connections/connect-apps/install-and-setup/installation
# 2. 启动隧道(Ollama 默认端口 11434)
cloudflared tunnel --url http://localhost:11434输出示例:
arduinoYour tunnel is ready! Visit: https://abc123.trycloudflare.com
在 ChatWise 中配置远程地址:
- 设置 → 模型服务 → Ollama
- API 地址填写:
https://abc123.trycloudflare.com - 团队成员即可通过公网使用你的 Qwen!
🔒 安全提示:生产环境建议添加 API Key 验证(需反向代理)。
八、性能调优技巧
1. 强制 CPU 模式(无 GPU 时)
ini
# Windows
set OLLAMA_NUM_GPU=0
ollama run qwen3:1.8b
# Linux/macOS
OLLAMA_NUM_GPU=0 ollama run qwen3:1.8b2. 调整上下文长度
bash
# 创建自定义 Modelfile
echo "FROM qwen3:7b" > Modelfile
echo "PARAMETER num_ctx 8192" >> Modelfile
# 构建新模型
ollama create qwen3-7b-long -f Modelfile
# 使用
ollama run qwen3-7b-long3. 查看资源占用
bash
# 实时监控
ollama ps
# 输出示例:
# NAME ID SIZE PROCESSOR UNTIL
# qwen3:7b 8d9a4e3c... 4.2 GB 100% CPU 5m九、常见问题解答(FAQ)
❓ Q1:下载速度慢怎么办?
✅ 解决方案:
-
使用国内镜像(需手动配置):
bash# 临时设置代理(如你有代理) export http_proxy=http://your-proxy:port export https_proxy=http://your-proxy:port ollama pull qwen3:7b -
或从 ModelScope 手动下载 GGUF 文件,再导入 Ollama(高级操作)
❓ Q2:如何删除模型释放空间?
bash
ollama rm qwen3:7b❓ Q3:支持函数调用(Function Calling)吗?
✅ 部分支持:
- Qwen3 原生支持 MCP 协议(非 OpenAI Function Calling)
- 需配合 MCP Server 使用(见 Qwen 官方文档)
❓ Q4:能否微调模型?
❌ Ollama 不支持微调 !
✅ 替代方案:
- 使用 Qwen-Agent 框架进行 LoRA 微调
- 微调后导出 GGUF 格式,再通过 Ollama 加载
十、学习资源
- Ollama 官方文档 :ollama.com/docs
- Qwen GitHub :github.com/QwenLM/Qwen
- 模型下载页 :Ollama Library - Qwen
- 社区论坛 :Ollama Discord
十一、总结:最佳实践路径
| 目标 | 推荐配置 |
|---|---|
| 个人体验 | qwen3:1.8b + ChatWise |
| 开发测试 | qwen3:7b + OpenAI SDK |
| 高性能推理 | qwen3:32b + vLLM(非 Ollama) |
| 团队共享 | Ollama + Cloudflare Tunnel |
💬 记住 :
"Ollama 让大模型本地化变得像安装 App 一样简单。"今天,你已拥有属于自己的中文 AI 助手!
作者 :AI 工程师
版权声明 :本文可自由转载,但请保留出处。
GitHub 示例代码 :github.com/yourname/ol...(虚构)