交叉验证是一种用于评估深度学习模型性能的统计方法 。交叉验证是一种重采样方法,用于在有限的数据样本上评估深度学习模型,可用于分类、回归等任务。交叉验证可以减少过拟合、提供稳健的性能评估、高效利用数据(尤其是在数据量有限的情况下)。
K-Fold Cross-Validation:K折交叉验证,K表示给定数据样本随机要分成的大小相等的组数(折) 。训练K次,将模型在所有K次迭代中的性能取平均值,从而得到模型泛化能力的估计。如下图所示:原图来自于: https://www.kaggle.com

一般步骤 :数据集中的每个样本有且仅一次用于测试,每个样本均K-1次用于训练
-
随机打乱数据集,将数据集分成K折。
-
训练及测试:对于每个折,使用K-1个折来训练模型,使用剩余的折作为测试集来评估模型。
-
汇总结果:计算每个折的性能指标,并取平均值。
K值的选择会影响偏差和方差之间的权衡,K的选择通常为5或10,没有硬性规定。小数据集适合较大的K值,中数据集适合较小的K值。大数据集不建议使用K-Fold。
-
较小的K值,使计算速度更快,但性能估计的方差更大。
-
较大的K值,使方差更小,但计算成本更高。
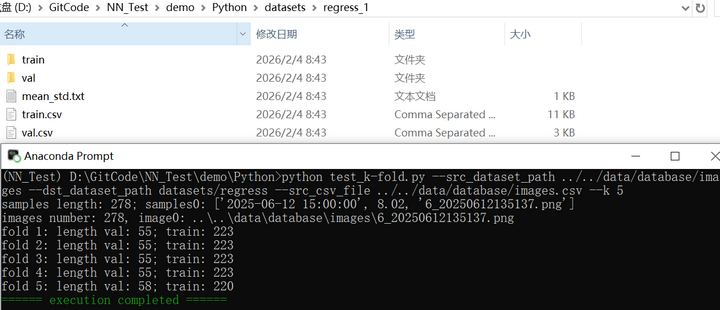
以下测试代码为将数据集按照K折交叉验证拆分,并计算mean和std,用于回归训练中,csv文件中为每幅图像对应一个float值
python
def parse_args():
parser = argparse.ArgumentParser(description="K-Fold Cross-Validation")
parser.add_argument("--src_dataset_path", required=True, type=str, help="source dataset path")
parser.add_argument("--src_csv_file", required=True, type=str, help="source csv file")
parser.add_argument("--dst_dataset_path", required=True, type=str, help="the path of the destination dataset after split")
parser.add_argument("--k", type=int, default=5, help="number fo groups, K-Fold cross validataion")
args = parser.parse_args()
return args
def split_k_fold(src_dataset_path, dst_dataset_path, src_csv_file, k):
if src_dataset_path is None or not src_dataset_path or not Path(src_dataset_path).is_dir():
raise ValueError(colorama.Fore.RED + f"{src_dataset_path} is not a directory")
if src_csv_file is None or not src_csv_file or not Path(src_csv_file).is_file():
raise ValueError(colorama.Fore.RED + f"{src_csv_file} is not a file")
for i in range(1, k+1):
path_name = dst_dataset_path + "_" + str(i)
if Path(path_name).exists():
raise FileExistsError(colorama.Fore.RED + f"specified directory already exists: {path_name}")
Path(path_name).mkdir(parents=True)
Path(path_name + "/train").mkdir(parents=True)
Path(path_name + "/val").mkdir(parents=True)
dataframe = pd.read_csv(src_csv_file, header=None)
samples = dataframe.values.tolist()
if len(samples) == 0:
raise FileNotFoundError(colorama.Fore.RED + f"there is no data in the file: {src_csv_file}")
print(f"samples length: {len(samples)}; samples0: {samples[0]}")
images = [img for img in Path(src_dataset_path).glob("*") if img.is_file()]
if len(images) == 0:
raise FileNotFoundError(colorama.Fore.RED + f"there are no matching images in this directory: {src_dataset_path}")
print(f"images number: {len(images)}, image0: {images[0]}")
if len(samples) != len(images):
raise ValueError(colorama.Fore.RED + f"length mismatch: samples:{len(samples)}; images:{len(images)}")
for i in range(0, len(samples)):
if samples[i][2] != images[i].name:
raise ValueError(colorama.Fore.RED + f"name mismatch: samples{i}:{samples[i][2]}; images{i}:{images[i].name}")
total = len(samples)
numbers = list(range(total))
random.shuffle(numbers)
fold_size = total // k
def write_and_copy(index_list, folder, csv_file):
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
write = csv.writer(file)
for idx in index_list:
write.writerow(samples[idx])
shutil.copy(images[idx], folder)
def calculate_mean_std(train_list, txt_file):
mean_sum = np.zeros(3, dtype=np.float64)
std_sum = np.zeros(3, dtype=np.float64)
for idx in train_list:
img = cv2.imread(str(images[idx]))
if img is None:
raise FileNotFoundError(colorama.Fore.RED + f"image file does not exist: {images[idx]}")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float64) / 255.0
mean_sum += img.mean(axis=(0, 1))
std_sum += img.std(axis=(0, 1))
mean = mean_sum / len(train_list)
std = std_sum / len(train_list)
with open(txt_file, mode="w", encoding="utf-8") as file:
file.write(f'--mean "{tuple(mean.tolist())}" --std "{tuple(std.tolist())}"')
for fold in range(k):
val_idx = numbers[fold * fold_size : (fold + 1) * fold_size] if fold < k - 1 else numbers[fold * fold_size :]
train_idx = [i for i in numbers if i not in val_idx]
print(f"fold {fold + 1}: length val: {len(val_idx)}; train: {len(train_idx)}")
write_and_copy(train_idx, dst_dataset_path + "_" + str(fold+1) + "/train", dst_dataset_path + "_" + str(fold+1) + "/train.csv")
write_and_copy(val_idx, dst_dataset_path + "_" + str(fold+1) + "/val", dst_dataset_path + "_" + str(fold+1) + "/val.csv")
calculate_mean_std(train_idx, dst_dataset_path + "_" + str(fold+1) + "/mean_std.txt")
if __name__ == "__main__":
colorama.init(autoreset=True)
args = parse_args()
split_k_fold(args.src_dataset_path, args.dst_dataset_path, args.src_csv_file, args.k)
print(colorama.Fore.GREEN + "====== execution completed ======")执行结果如下图所示: