
深度学习 ( Deep Learning , DL ) 是现代人工智能真正的核心引擎。
如果说 人工智能 (AI) 是我们要抵达的彼岸(机器像人一样聪明), 机器学习 ( Machine Learning ) 是通往彼岸的船(让机器从数据中找规律), 那么 深度学习 就是驱动这艘船的核反应堆。
它是机器学习的一个子集,灵感来源于人类大脑的运作方式------神经网络 ( Neural Networks )。
1.🧅 什么是"深度" (Deep)?
这里的"深",指的不是思想深刻,而是数学层数多。
传统的机器学习(如决策树、支持向量机)通常只有 1-2 层计算结构,被称为"浅层学习"。 而深度学习模型,通常包含几十、几百甚至上千层隐层 (Hidden Layers)。
我们可以把它想象成一个**"层层过滤的超级漏斗"** :
-
输入层:接收原始数据(比如一张猫的照片,就是一堆像素点)。
-
第 1 层 (隐层) :识别出简单的线条和边缘。
-
第 2 层 (隐层) :把线条组合成形状(圆圈、三角形)。
-
第 3 层 (隐层) :把形状组合成五官(眼睛、耳朵)。
-
... (中间无数层):组合出更复杂的纹理和结构。
-
输出层:得出结论------"这是一只猫"。
所谓"深度",就是这个处理链条的长度。层数越多,模型能理解的特征就越抽象、越高级。
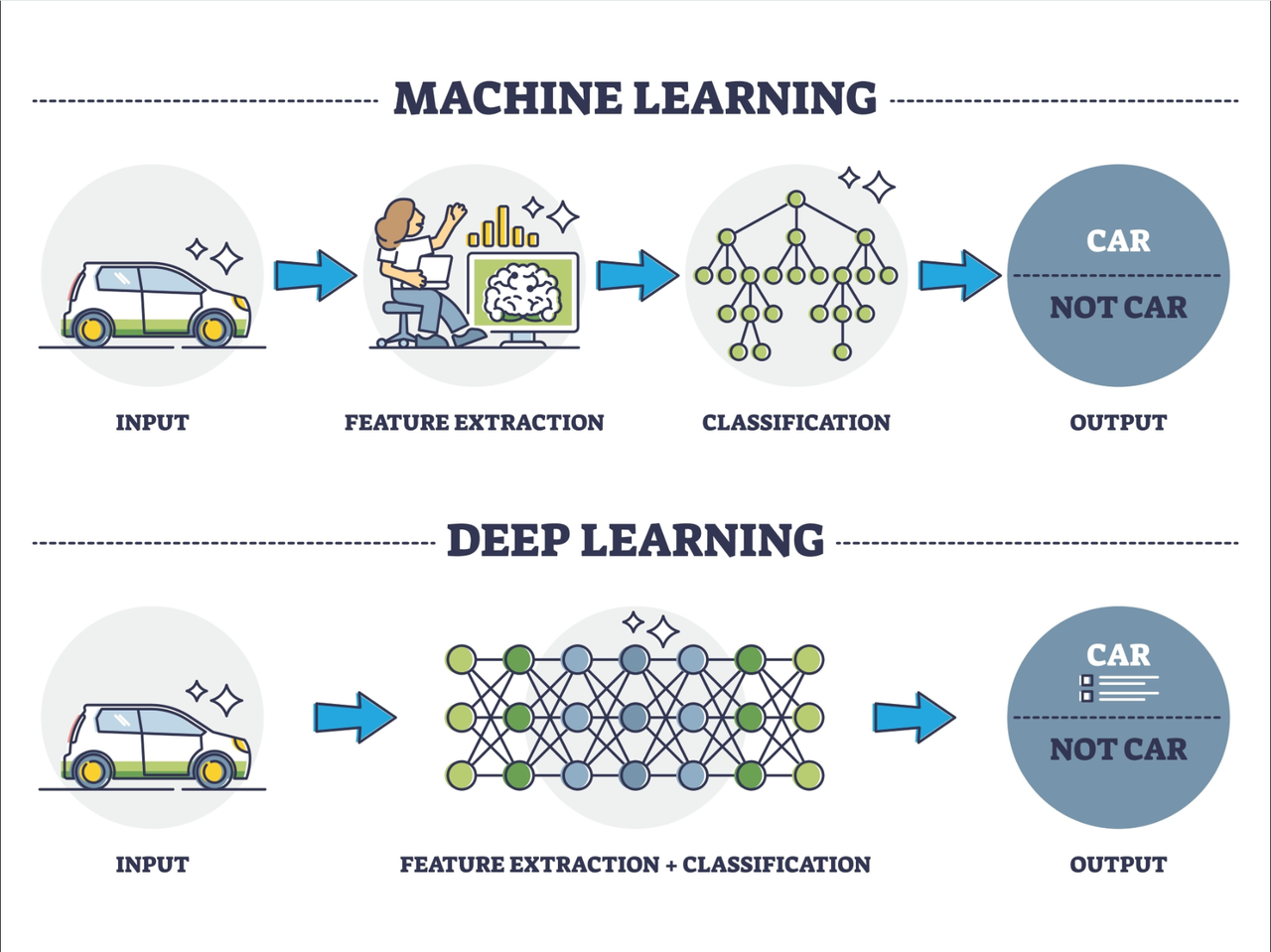
2.⚡ 核心魔法:自动特征提取 (Feature Extraction)
这是深度学习与传统机器学习最本质的区别,也是它统治 AI 界的根本原因。
-
传统 机器学习 (旧时代):
-
需要人类专家先告诉机器:"找猫的话,你要看有没有尖耳朵、有没有胡须。"(这叫人工 特征工程)。
-
缺点:如果专家没定义"猫有尾巴",机器就认不出来背对着的猫。
-
-
深度学习 (新时代):
-
你什么都不用说,直接把 100 万张猫的照片扔给它。
-
模型会通过多层网络,自己学会:"哦,原来这些照片里都有一个毛茸茸的东西,那个东西很重要。"
-
优点:它能发现人类都忽略的微小特征,不再依赖人类的经验。
-
3.🧠 它如何学习?(反向传播)
深度学习的训练过程,本质上是一个**"猜谜 - 挨打 - 改正"** 的循环:
-
前向传播 (Forward Propagation):
- 模型看一眼照片,瞎猜:"这是狗!"(因为它刚出生,参数是随机的)。
-
计算损失 ( Loss Function ):
- 裁判(损失函数)说:"错!这是猫。你的误差 (Loss) 很大。"
-
反向传播 (Backpropagation):
-
这是深度学习的灵魂。
-
误差信号会从输出层倒着传回输入层。
-
模型会责问每一层的神经元:"是不是你算错了?是你把'圆耳朵'当成特征了吗?"
-
每个神经元根据这个反馈,微调自己的权重 (Weights)。
-
-
迭代:这个过程重复几亿次,直到模型每次都能猜对。
4.🏗️ 三大主流架构
深度学习不是只有一种长相,针对不同的任务,它进化出了不同的"脑部结构":
-
CNN ( 卷积神经网络 ):
-
专长:看图 (Computer Vision)。
-
原理:像人类的视神经一样,通过滑动窗口扫描图片,提取局部特征。
-
应用:人脸识别、自动驾驶、医疗影像诊断。
-
-
RNN ( 循环神经网络 ) / LSTM:
-
专长:处理序列 (时间、语音)。
-
原理:有记忆功能,能记住上文说了什么。
-
应用 :语音识别、股票预测。(注:现在已被 Transformer 取代)。
-
-
Transformer (自注意力机制):
-
专长:理解全局关系。
-
原理:并行处理,关注力聚焦(我们在前几条详细讨论过)。
-
应用 :ChatGPT、Gemini、Sora。这是目前 深度学习 的巅峰。
-
5.🚀 为什么现在才爆发?
深度学习的理论早在上世纪 80 年代就有了(Geoffrey Hinton 等人提出),但直到 2012 年(AlexNet 时刻)才真正爆发,主要因为三要素集齐了:
-
大数据 (Data):互联网产生了海量数据,用来喂养贪婪的深层网络。
-
算力 ( GPU ):NVIDIA 显卡的出现,让矩阵运算速度提升了数千倍,原本要算 10 年的模型现在只需算 1 天。
-
算法 (Algorithm):解决了深层网络难以训练(梯度消失)的数学难题。
总结
深度学习 是让机器拥有**"直觉"** 的技术。
它不再需要人类手把手教它"什么是猫",而是通过模拟大脑的神经网络,在海量数据中自我进化,自动提炼出理解世界的抽象规律。它是 AlphaGo 战胜柯洁、ChatGPT 通过图灵测试背后的真正功臣。