目录
- 一、理解缓冲区
-
- [1.1 文件打开和读写的基本过程](#1.1 文件打开和读写的基本过程)
- [1.2 为什么要有缓冲区?](#1.2 为什么要有缓冲区?)
- [1.3 语言级的输入输出缓冲区具体在哪里?](#1.3 语言级的输入输出缓冲区具体在哪里?)
- 二、理论验证
-
- [2.1 没有刷新的问题](#2.1 没有刷新的问题)
- [2.2 语言级缓冲区的刷新问题](#2.2 语言级缓冲区的刷新问题)
- [2.3 exit 与 _exit](#2.3 exit 与 _exit)
- [2.4 向显示器打印的几种做法,以及一个问题](#2.4 向显示器打印的几种做法,以及一个问题)
- [2.5 内核文件缓冲区](#2.5 内核文件缓冲区)
- 三、封装体验缓冲
- 三、理解标准错误
个人主页:矢望
个人专栏:C++、Linux、C语言、数据结构、Coze-AI
一、理解缓冲区
1.1 文件打开和读写的基本过程
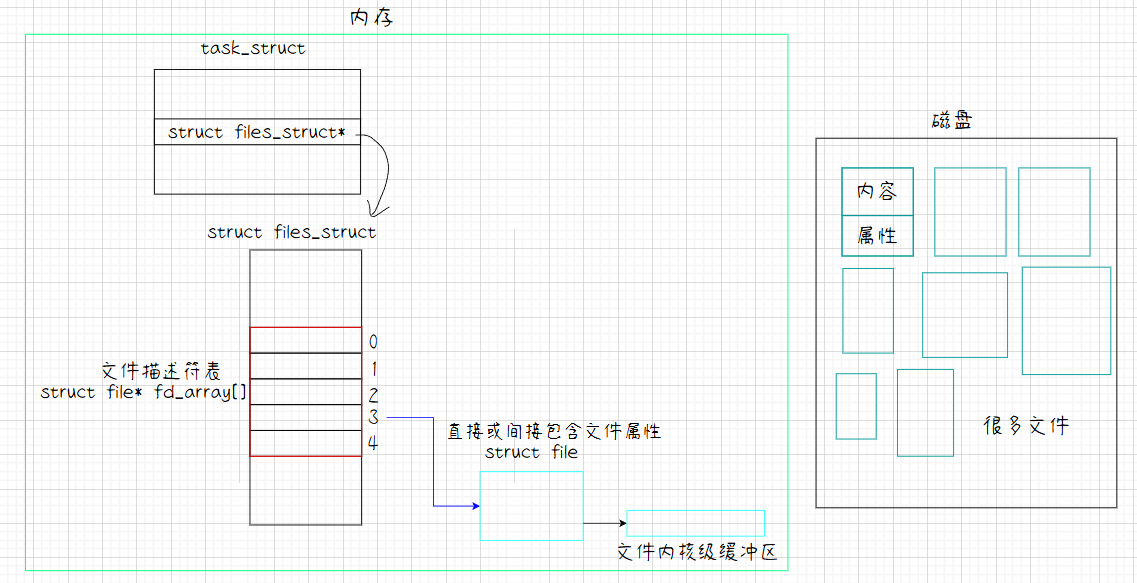
如上图,如果你打开一个文件,在进程PCB中的文件描述表里就会找一个文件描述符给这个被打开的文件,这个struct file的结构体里直接或间接的包含被打开文件的属性,其中重要的是有一个文件内核级缓冲区。
如果你要读 文件,系统提供了相应的系统调用read。

fd是被打开的文件的文件描述符,buf是你自己定义的用户缓冲区数组,count是你要获取的字节数。
当你在程序中调用read时,这个系统调用就会通过fd找到对应的struct file,并且详细的去看文件内核级缓冲区,如果这个缓冲区中没有内容,read就和scanf一样,进程就堵塞在那里了。所以使用read函数首先OS会将磁盘中的文件内容加载到文件内核级缓冲区,之后read函数就会将内核级缓冲区的数据拷贝到buf用户级缓冲区中 。所以read函数本质是拷贝函数。
当你要写 文件,系统提供了相应的系统调用,并且我们之前已经使用过了,就是write。

它的参数和read相同,只不过它是将用户缓冲区buf的数据写入到fd对应的struct file结构体里的文件内核级缓冲区 中,之后OS会自动将文件内核级缓冲区里的数据刷新到磁盘文件中。所以它本质也是拷贝函数。
如果要修改文件的内容也一样,也是先将磁盘中的文件内容加载到文件内核级缓冲区,然后将这个缓冲区中的内容做修改,最后再刷新到磁盘文件中完成修改。
所以read和write它们都不是直接访问物理磁盘,它们做不到!
read的简单使用
我们的scanf函数底层封装的就是read。 read函数:

返回值含义 :n > 0,实际读取的字节数;n = 0,已到达文件末尾EOF;n = -1,发生错误。
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
const char* filename = "log.txt";
int fd = open(filename, O_RDONLY);
if(fd < 0)
{
perror("open");
return 1;
}
char buff[256]; // 用户级缓冲区
ssize_t n = read(fd, buff, sizeof(buff) - 1); // -1 是为了给 '\0' 留空间
if(n > 0)
{
buff[n] = '\0';
printf("下面是读取到的内容\n");
printf("%s\n", buff);
}
close(fd);
return 0;
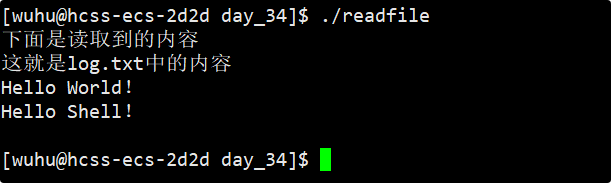
}上面的程序是从fd对应的文件中读取数据到用户缓冲区,然后打印出来查看内容,这是log.txt中的内容:
cpp
这就是log.txt中的内容
Hello World!
Hello Shell!运行结果 :
1.2 为什么要有缓冲区?
调用系统调用是有成本的,系统调用的过程会比较慢,比如调用read或write过程中OS会将磁盘中的内容加载到文件内核级缓冲区,或者将文件内核级缓冲区的内容加载到磁盘,这个过程是很消耗时间的。
比如我们在学习vector的时候,它的一次扩容都是扩1.5-2倍的,它为什么不每次需要多少扩容多少呢?比如它需要一个整型的空间就开辟一个整型的空间不好吗? 不好,这样它调用系统调用的次数太多了,这就会导致时间的浪费,而一下子开辟1-2倍的空间,这样你需要少量的空间时,直接从这个已申请好的空间拿就好了,不需要频繁进行系统调用。
所以如果解决成本呢? 就是尽量减少系统调用的次数。
当我们进行写入的时候,成本就是read或write,所以我们需要减少它们调用的次数。C语言中给我们提供了输入缓冲区 和输出缓冲区 ,它们都是语言级缓冲区 。
当我们使用我们熟知的int fputs(const char *s, FILE *stream);进行输出数据时,实际是这个函数将数据从用户级缓冲区打印到了语言级缓冲区 ,等到写完或者语言级输出缓冲区打印满时,就会调用一次write将缓冲区中的数据刷新到文件内核级缓冲区!
所以我们之前所说的缓冲区,都指的是语言级缓冲区,而不是文件内核级缓冲区!有了语言级的输入输出缓冲区,就提高了C语言的IO函数的运行效率,这就是为什么C/C++要有语言级缓冲区的原因!
1.3 语言级的输入输出缓冲区具体在哪里?

上图是fopen函数,它的返回值是FILE*类型,我们知道FILE是一个结构体,它里面封装了文件描述符fd,但它里面还封装了缓冲区!
cpp
struct FILE {
// ...
int fd;
char inbuffer[BUFSIZ]; // 语言级输入缓冲区
char outbuffer[BUFSIZ]; // 语言级输出缓冲区
// ...
};所以调用它int fputs(const char *s, FILE *stream);是将用户级缓冲区中的数据拷贝到语言级缓冲区,本质就是拷贝到了fputs接收的stream的FILE结构体里。
因此语言级缓冲区在每一个文件的FILE对象中。
fopen是一个C语言的库函数可是它返回的是一个FILE*的指针,FILE是需要创建的,这个FILE对象是在哪里创建的呢? 它是在fopen内部创建的,所以最后还需要进行fclose,fclose(fp)所做的工作 :关闭文件描述符,刷新缓冲区,释放fp指针所指向的FILE对象。
相关FILE结构体,在/usr/include/stdio.h中:
cpp
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的⽂件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
typedef struct _IO_FILE FILE;二、理论验证
2.1 没有刷新的问题
现在有这么一段代码,是一段关于输出重定向的代码。
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("fd is %d\n", fd);
printf("fd is %d\n", fd);
printf("fd is %d\n", fd);
return 0;
}运行结果 :
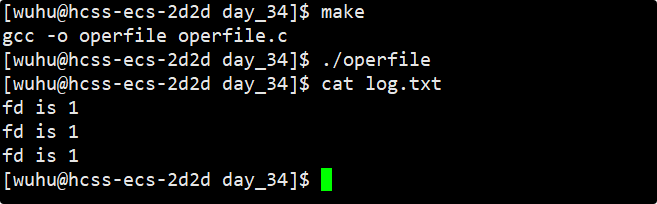
如上,我们的打印信息果然打印在了log.txt中,现在我要在代码末尾加上close(fd);我们再次看现象。
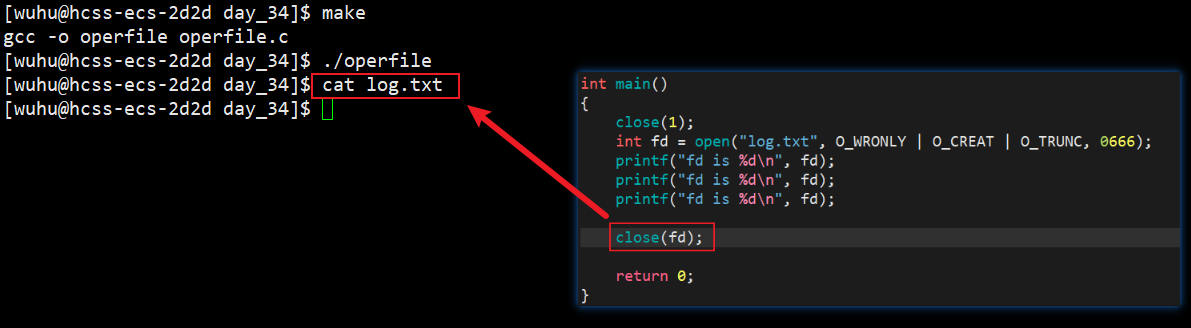
这次再次运行log.txt中竟然没有内容了,为什么?
我们分析一下,printf是向stdout打印的,它就是将用户级数据拷贝到stdout对象的语言级缓冲区中的 ,也就是说打印完成后,现在数据在语言级缓冲区中,但还没来的及刷新到文件内核级缓冲区就执行了close(fd),那自然log.txt中就没有数据被写入了。
那么我就要看到它被写入该怎么办,可以使用fflush(stdout)。
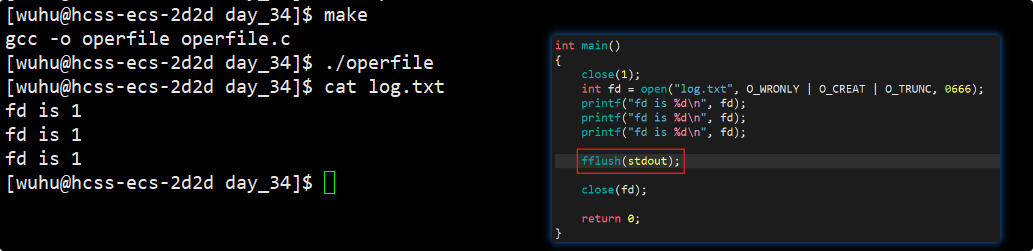
fflush(stdout)的本质就是强制把语言级缓冲区的数据刷新到文件内核级缓冲区。
2.2 语言级缓冲区的刷新问题
刷新的本质是将语言级缓冲区的数据拷贝到文件内核级缓冲区,是把你的数据交给操作系统。
语言级缓冲区刷新的三个核心规则 :
1、当进程结束的时候,会自动刷新,默认会调用fflush。
2、如果目标文件是显示器,默认时进行行缓冲 (行刷新),因为人在看的时候是以行为单位的。
3、普通文件一般是全缓冲,就是缓冲区写满了才会刷新。
扩充 :调用fclose会刷新语言级缓冲区。
2.3 exit 与 _exit
在进程控制这一期博客中,我们提到exit会刷新缓冲区,而_exit不会刷新缓冲区时,说"这也侧面显示出缓冲区与刷新缓冲区的操作,一定不在内核中进行"。
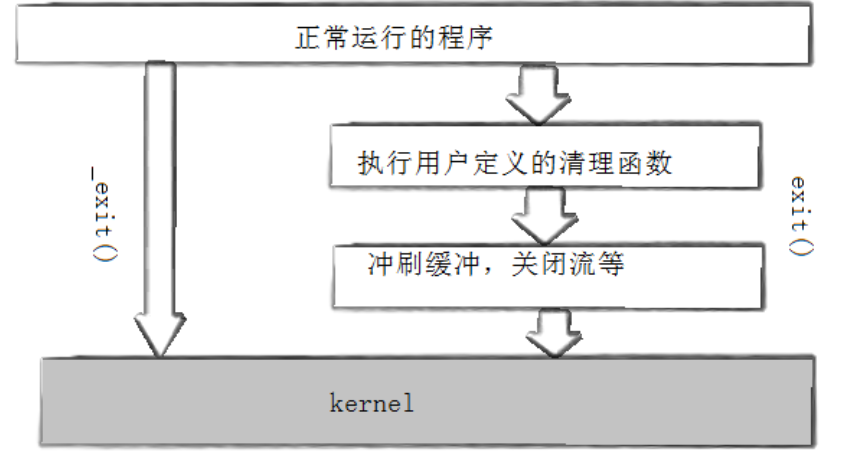
如上图,今天我们就知道缓冲区与刷新缓冲区的操作在语言层。
2.4 向显示器打印的几种做法,以及一个问题
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
// C库函数
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
const char* ch = "hello fputs\n";
fputs(ch, stdout);
// 系统调用
const char* ch1 = "hello write\n";
write(1, ch1, strlen(ch1));
return 0;
}如上就是向显示器打印的几种做法,接下来我们看看运行效果:
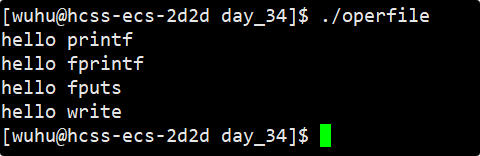
如上就是我们的预期结果。
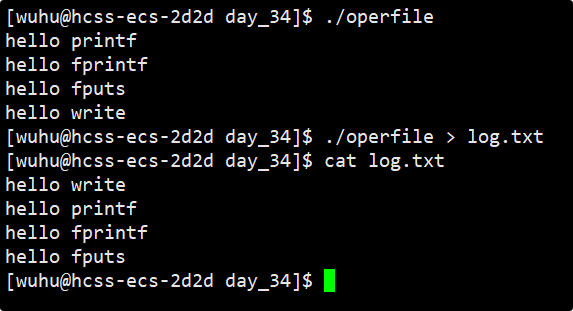
如上,这样重定向运行之后为什么系统调用在最前面呢? 因为系统调用是直接向文件内核级缓冲区写的,所以它在最前面,C库函数的都是向语言级缓冲区写的,所以会在系统调用的后面。
- 问题
接下来,我在代码的结尾加上一个fork,我们再来看看现象。
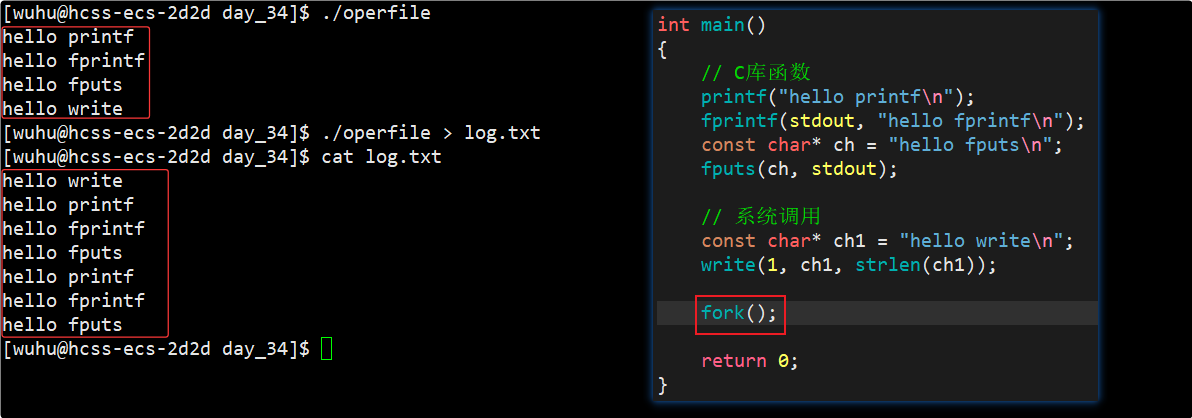
如上图,为什么向显示器打印的是四条消息,而向文件重定向之后却是七条消息?
首先来看向显示器打印,显示器打印是行刷新,也就是fork之前,它们都已经打印到显示器上了,系统调用就更不用说了,它直接就写了,不需要刷新。
其次再来看重定向,重定向就将向显示器写,转化成了向普通文件里写。看上图的打印结果,我们发现重复的都是使用C库函数打印的消息。
向普通文件中写入是全缓冲,只有当语言级缓冲区写满时才会刷新,很明显这三句话根本写不满语言级缓冲区,之后就fork创建子进程了,此时父子进程的语言级缓冲区里都有这三条消息,之后就return了,此时父子进程都要主动进行刷新,所以我们才看到了重复的那三条消息。而系统调用早在fork之前就已经写给文件内核级缓冲区了,它不需要刷新。
2.5 内核文件缓冲区
只要把数据从用户缓冲区拷贝到了内核文件缓冲区,就相当于将数据交给了硬件。客观上讲,就是将数据写给了FILE对应的文件内核级缓冲区,之后OS就会对这些数据进行自主刷新,OS有自己的刷新策略,比如立即刷新或者等OS空闲时再自主刷新。总之,这个工作是OS自己决定的。
OS向磁盘做刷新也是有成本的,这也是文件内核级缓冲区存在的原因!这样就可以提高OS的效率。
如果用户要求OS立即进行刷新,操作系统也给了相关的系统调用,fsync。

三、封装体验缓冲
上面我们了解了那么多,现在我们也要对上面所描述的系统调用进行封装,我们要封装实现fopen、fputs、fflush、fclose等等。
上面我们看到了FILE结构体,typedef struct _IO_FILE FILE;,接下来我们就简单实现一下这个结构体。我们整体采用头文件+头文件实现+源文件的形式展开。

mystdio.h:
cpp
#pragma once
#include <stdio.h>
#define SIZE 1024
#define NONE_BUFFER 1 // 无缓冲
#define LINE_BUFFER 2 // 行缓冲
#define FULL_BUFFER 4 // 全缓冲
#define MODE 0666 // 默认创建文件的权限
typedef struct my_IO_FILE
{
int fd; // 文件描述符
int flags; // 打开文件方式
int flush_mode; // 缓冲区刷新方式
char outbuffer[SIZE]; // 输出缓冲区
int pos; // 在缓冲区的书写位置
int capcaity; // 缓冲区容量
}myFILE;
myFILE* myfopen(const char* filename, const char* mode); // a、w、r
int myfputs(const char* str, myFILE* fp);
void myfflush(myFILE* fp);
void myfclose(myFILE* fp);如上,我只设置了一个语言级输出缓冲区。
myfopen函数的具体实现:
cpp
myFILE* myfopen(const char* filename, const char* mode) // a、w、r
{
int fd = -1;
int flags = 0; //记录文件打开方式
if(strcmp(mode, "r") == 0) // 只读
{
flags = O_RDONLY;
fd = open(filename, flags);
}
else if(strcmp(mode, "w") == 0) // 写
{
flags = O_WRONLY | O_CREAT | O_TRUNC;
fd = open(filename, flags, MODE);
}
else if(strcmp(mode, "a") == 0) // 追加
{
flags = O_WRONLY | O_CREAT | O_APPEND;
fd = open(filename, flags, MODE);
}
else
{
// 其它模式,暂不添加
}
if(fd < 0)
return NULL;
myFILE* fp = (myFILE*)malloc(sizeof(myFILE)); // 申请 myFILE 对象
if(fp == NULL)
return NULL;
// 维护 myFILE 结构体中的内容
fp->fd = fd;
fp->flags = flags;
fp->flush_mode = LINE_BUFFER;
fp->capcaity = SIZE;
fp->pos = 0;
return fp;
}我们在之前了解到FILE对象就是在fopen内部申请的,所以我们也是这样实现的。具体实现了三种文件的打开方式,有r、w、a。
fflush函数的具体实现:
这里我们的fflush设计的是会调用我们内部实现的一个函数。因为C库函数中的fputs中也会有尝试刷新的逻辑,但C库中是将尝试刷新函数和强制刷新函数fflush分开实现的,感觉有点麻烦,不如我们自己实现一个函数,尝试刷新和强制刷新都调用这一个函数。
cpp
#define TRY_FLUSH 1 // 尝试刷新
#define MUST_FLUSH 2 // 强制刷新
static void myFFlush(myFILE* fp, int mode)
{
if(fp->pos == 0)
{
return;
}
if(fp->flush_mode == LINE_BUFFER) // 行缓冲
{
if((fp->outbuffer[fp->pos - 1] == '\n') || (mode == MUST_FLUSH))
{
// 写到文件内核级缓冲区
write(fp->fd, fp->outbuffer, fp->pos);
fp->pos = 0; // 清空缓冲区
}
}
else if(fp->flush_mode == FULL_BUFFER)
{
// ...
}
else if(fp->flush_mode == NONE_BUFFER)
{
// ...
}
}
void myfflush(myFILE* fp)
{
myFFlush(fp, MUST_FLUSH);
}如上,我们的FILE结构体中的刷新模式默认设置的就是行刷新,所以剩下的刷新方式就不实现了。
fputs的具体实现:
cpp
int myfputs(const char* str, myFILE* fp)
{
if(strlen(str) == 0)
return 0;
// 将数据拷贝到语言级缓冲区
memcpy(fp->outbuffer + fp->pos, str, strlen(str));
fp->pos += strlen(str);
// 尝试刷新
myFFlush(fp, TRY_FLUSH);
return strlen(str);
}这里实现的时候使用到了C库拷贝函数memcpy,具体用法见博客:点击跳转。
fclose的具体实现:
它只做这几件事:强制刷新,关闭文件,释放FILE对象。
cpp
void myfclose(myFILE* fp)
{
// 1、强制刷新到内核
myFFlush(fp, MUST_FLUSH);
// 1.2 强制刷新到磁盘
//fsync(fp->fd); // 不必选
// 2、关闭文件
close(fp->fd);
// 3、释放 FILE 对象
free(fp);
}主函数的内容:
cpp
#include "mystdio.h"
#include <unistd.h>
int main()
{
myFILE* fp = myfopen("log1.txt", "w");
if(fp == NULL)
{
perror("myfopen file");
return 1;
}
int cnt = 3;
const char* str = " hello world!";
while(cnt--)
{
myfputs(str, fp);
printf("outbuffer: %s, pos: %d\n", fp->outbuffer, fp->pos);
sleep(1);
}
myfclose(fp);
return 0;
}现在我们要进行程序运行测试,如上我们的fputs一共执行3次,打印一次暂停一秒,现在我们要在程序运行的时候,同时观测log1.txt中的内容变化。上面的程序中,我们要输入的内容没有加\n,也就是不会触发行缓冲,但我们最后调用了myclose函数,所以我们观察到的现象应该是最后一下子出现了三条内容。
测试结果 :
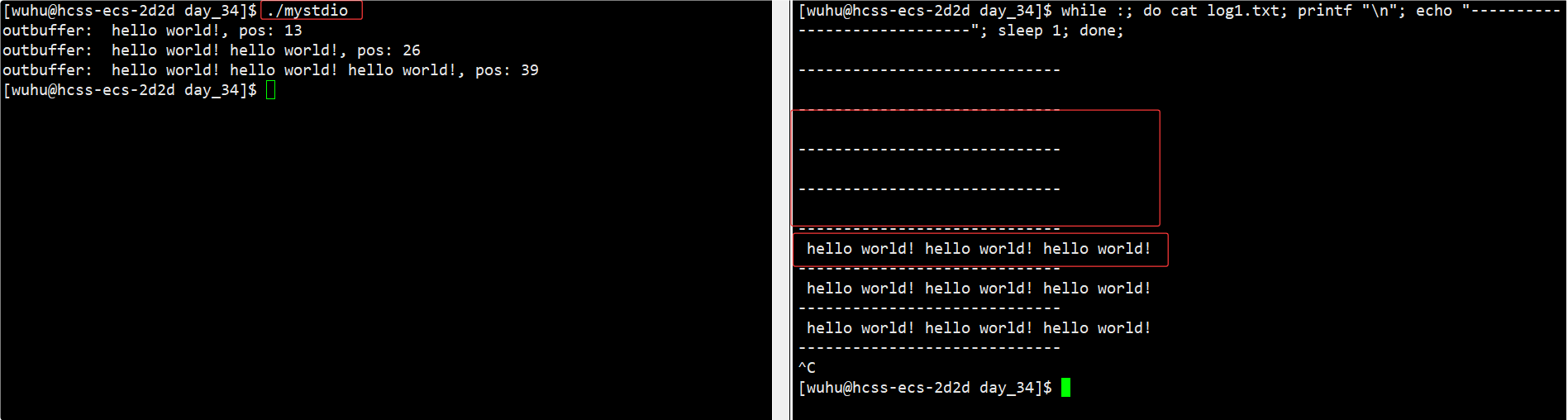
如上,我们再右边每隔一秒观测一次这个文件,结果果然是运行的前三秒文件中没有内容,等到程序结束时,fclose强制刷新缓冲区后文件中才有内容。
我们再把要打印的内容加上\n:
cpp
const char* str = " hello world!\n";再次运行测试:
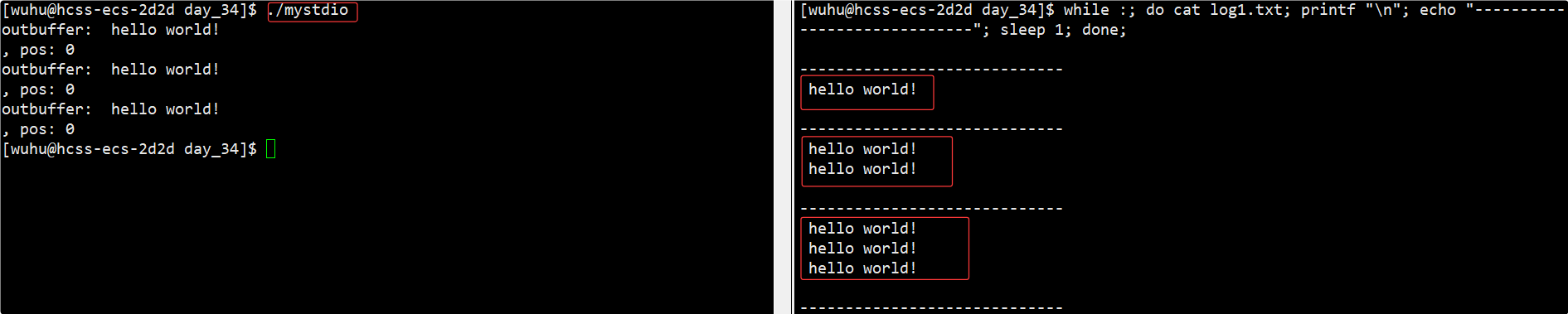
如上,每打印一次就刷新一次,这就是行缓冲。
三、理解标准错误
我们执行进程是为了完成任务,也就是我们要对数据做加工处理,只要有数据就存在数据的源头也就是输入,也就存在数据的处理结果也就是输出,所以标准输入,0,stdin和标准输出,1,stdout的存在我们都能理解,它们的存在也方便我们对程序进行debug。那么为什么要存在标准错误呢?
在你的程序处理好的数据结果里面,有你想看的正常数据,也可能有你不想看的错误信息,而有了标准错误,2,stderr,我们就可以对这些结果数据进行分流处理。
标准错误的存在确实是为了让程序的输出意图更清晰,让用户能够选择性地接收和处理不同类型的程序输出。
重定向的灵活性:
cpp
# 只重定向标准输出,错误信息仍显示在终端
./program > output.txt
# 只重定向标准错误
./program 2> error.log
# 分别重定向输出和错误到不同文件
./program > output.txt 2> error.log
# 合并输出和错误到同一文件
./program > combined.txt 2>&1我们接下来写一个程序,你就知道上面这些指令是干嘛用的了。
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
// 正常数据, 标准输入:1
printf("正常数据1\n");
fprintf(stdout, "正常数据2\n");
const char* str = "这是由 write 打印的正常消息\n";
write(1, str, strlen(str));
// 错误信息, 标准错误:2
fprintf(stderr, "错误数据1\n");
const char* str1 = "这是由 write 打印的错误消息\n";
write(2, str1, strlen(str1));
perror("hello perror");
return 0;
}这是分别向stdout打印和向stderr打印的信息。
正常运行 :
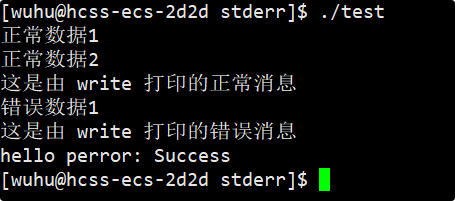
标准输出和标准错误默认都是向显示器打印,其中标准错误是无缓冲,它是直接打印的,而标准输出面对显示器是行缓冲。
执行./program > output.txt和./program 2> error.log命令。
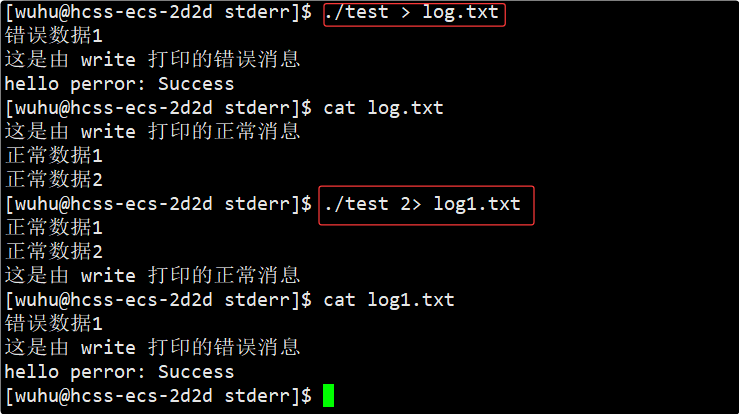
如上当执行./test > log.txt时,>默认是将1文件描述符中的内容指向log.txt,这是一种省略写法,其实是1>。所以这个命令就会将向stdout: 1写的正常消息重定向到log.txt文件中。
当执行./test 2> log1.txt时,2>默认是将2文件描述符中的内容指向log1.txt,所以这个命令就会将向stderr: 2写的错误消息重定向到log1.txt文件中。
而完整的命令应该是./test > log.txt 2> log1.txt,这样一条命令就分别将正常消息打印到了log.txt中,将错误消息打印到了log1.txt中。
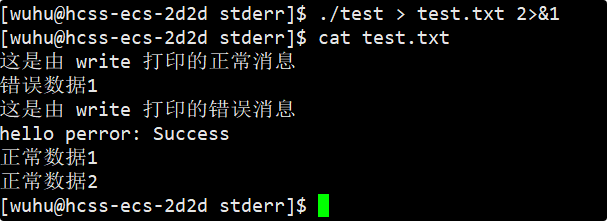
而如果你想要合并输出和错误到同一文件,你就执行./test > test.txt 2>&1 ,这条命令是先重定向stdout,再让stderr跟随,其中2>&1是让stderr指向stdout当前指向的地方,也就是让文件描述符2指向的也是test.txt文件了,这样信息就打印到同一个文件中了。
对数据的理解 :操作系统在存储数据的时候它可不管你存的是字符串、整型还是图片,在它看来你存储的都是void*的。那么这些字符串、图片等等都有实际类型,这是谁在区分呢?是语言和用户在区分,因为用户可以区分不同的类型,所以语言给了不同的类型接口。
最佳实践:对文件进行操作使用语言级函数,除非特殊情况使用系统调用。
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~