文章目录
- [引言:为什么该重视 Agent Skill?](#引言:为什么该重视 Agent Skill?)
- [一、先搞清楚:Skill 到底解决什么问题?](#一、先搞清楚:Skill 到底解决什么问题?)
-
- [1.1 传统用法的三大痛点](#1.1 传统用法的三大痛点)
- [1.2 一句话理解 Skill](#1.2 一句话理解 Skill)
- [1.3 Skill 相比其他方案的定位](#1.3 Skill 相比其他方案的定位)
- [1.4 什么时候值得做成 Skill?](#1.4 什么时候值得做成 Skill?)
- [二、四个核心设计原则:决定 Skill 上限的关键](#二、四个核心设计原则:决定 Skill 上限的关键)
-
- [2.1 渐进式披露:别一股脑塞东西](#2.1 渐进式披露:别一股脑塞东西)
- [2.2 把上下文当公共资源:少一句是一句](#2.2 把上下文当公共资源:少一句是一句)
- [2.3 按任务脆弱性调节自由度](#2.3 按任务脆弱性调节自由度)
- [2.4 记住读者是模型,不是人](#2.4 记住读者是模型,不是人)
- [三、五种 Skill 结构模式:先选结构,再写内容](#三、五种 Skill 结构模式:先选结构,再写内容)
-
- [3.1 模式 A:极简指导型](#3.1 模式 A:极简指导型)
- [3.2 模式 B:示例模板型](#3.2 模式 B:示例模板型)
- [3.3 模式 C:工具脚本型](#3.3 模式 C:工具脚本型)
- [3.4 模式 D:知识库型](#3.4 模式 D:知识库型)
- [3.5 模式 E:完整工作流型](#3.5 模式 E:完整工作流型)
- [四、SKILL.md:一个 Skill 的「心脏」](#四、SKILL.md:一个 Skill 的「心脏」)
-
- [4.1 推荐的文件结构](#4.1 推荐的文件结构)
- [4.2 Frontmatter:name 和 description 写法](#4.2 Frontmatter:name 和 description 写法)
- [4.3 正文三种常用结构](#4.3 正文三种常用结构)
- [4.4 代码示例的硬性要求](#4.4 代码示例的硬性要求)
- [五、附加文件:references、scripts、assets 怎么设计?](#五、附加文件:references、scripts、assets 怎么设计?)
-
- [5.1 目录总览与角色分工](#5.1 目录总览与角色分工)
- [5.2 references/:写给模型看的「长文档」](#5.2 references/:写给模型看的「长文档」)
- [5.3 scripts/:给模型用的 CLI 工具](#5.3 scripts/:给模型用的 CLI 工具)
- [5.4 assets/:模板和资源文件](#5.4 assets/:模板和资源文件)
- [六、脚本开发:让 Skill 真正「有手有脚」](#六、脚本开发:让 Skill 真正「有手有脚」)
-
- [6.1 一个好脚本应该长什么样?](#6.1 一个好脚本应该长什么样?)
- [6.2 常见的错误处理模式](#6.2 常见的错误处理模式)
- [6.3 CLI 入口推荐写法](#6.3 CLI 入口推荐写法)
- [七、从 0 到 1:六步创建你的第一个 Skill](#七、从 0 到 1:六步创建你的第一个 Skill)
-
- [Step 1:先把场景说清楚](#Step 1:先把场景说清楚)
- [Step 2:根据场景选结构模式](#Step 2:根据场景选结构模式)
- [Step 3:写好 description(这一步最关键)](#Step 3:写好 description(这一步最关键))
- [Step 4:搭出核心流程骨架](#Step 4:搭出核心流程骨架)
- [Step 5:补充 references / scripts / assets](#Step 5:补充 references / scripts / assets)
- [Step 6:用真问题反复测试和迭代](#Step 6:用真问题反复测试和迭代)
- 八、发布前的质量检查:别把半成品丢给业务
- 九、常见反模式:这些坑可以直接绕开
- [结语:把 Skill 当成「产品」而不是「提示词」](#结语:把 Skill 当成「产品」而不是「提示词」)
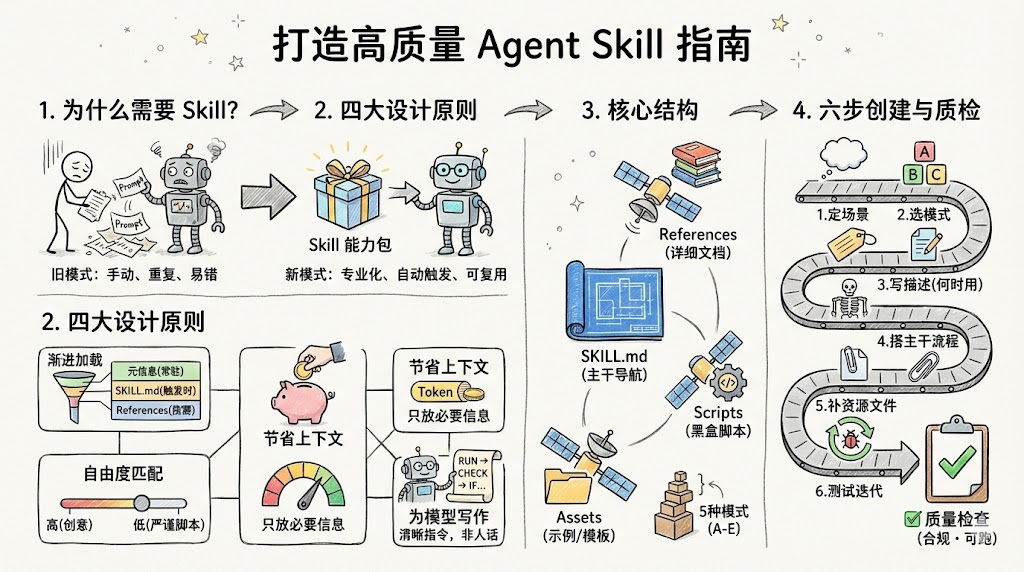
引言:为什么该重视 Agent Skill?
如果你最近在用 Claude、GPT 这类助手做事,大概率踩过这些坑:每次对话都要重新讲规则、项目里写了一堆自定义指令却没法复用、各种长 Prompt 到处复制粘贴,时间久了谁也不记得最新版本是哪份。
接下来我们将探讨:如何用「Agent Skill」把这些零散的 Prompt 和经验,收拢成一套可复用、可维护、能上线跑业务的专业能力包。它不是再教你写一段牛逼的提示词,而是教你设计一个「专业技能模块」,能自动触发、按需加载文档、调用脚本,真正接到业务里去跑。
一、先搞清楚:Skill 到底解决什么问题?
1.1 传统用法的三大痛点
在没有 Skill 之前,大部分人的用法是这样的:
- 靠记忆:每次跟模型说「你现在扮演 XXX 专家,要遵守以下规则......」,一长串废话来回贴。
- 靠项目指令:在某个项目里写一大段自定义指令,但换个项目就全没了。
- 靠复制粘贴:整理一堆「万能 Prompt」,需要的时候翻记录、粘过去用。
对应的问题也很直观:
- 重复劳动:同样的话反复讲,心累。
- 容易漏:今天版本跟昨天不一样,谁也不知道哪句才算最新规范。
- 难维护:一堆长 Prompt 四处散落,想改统一规则非常困难。
1.2 一句话理解 Skill
Skill 是一个可复用的知识包,让 Claude 在任何地方、任何时候自动触发某种专业能力。
翻译成人话就是:你把一套专业能力(流程、规范、脚本、模板)封装成一个模块,模型在遇到相关需求时,可以自动加载,用你预先设计好的方法来处理问题,而不是临场自由发挥。
1.3 Skill 相比其他方案的定位
我们把Skill 和 MCP、项目指令、系统提示做了一个对比,
| 能力维度 | Skill | MCP | 项目指令 | 系统提示 |
|---|---|---|---|---|
| 跨对话复用 | 支持 | 支持 | 不支持 | 不支持 |
| 自动触发 | 支持 | 不支持 | 不支持 | 支持 |
| 能否执行代码 | 支持 | 支持 | 不支持 | 不支持 |
| 是否渐进加载信息 | 支持 | 不支持 | 不支持 | 不支持 |
| 核心定位 | 专业技能与业务流程 | 接外部系统 / 工具 | 当前项目的上下文 | 人设与基础行为规则 |
一句总结:MCP 更像「接外部工具的接口层」,Skill 更像「带流程和示例的专业应用层」。
1.4 什么时候值得做成 Skill?
适合做 Skill 的场景有几个共同特点:
- 经常反复做:比如固定格式的报告、代码审查流程、公众号推文模板。
- 有领域门槛:比如专利解读、合同风险识别、财报分析。
- 有明确流程:多步骤、需要判断分支,而不是简单问答。
- 涉及工具或脚本:需要跑脚本、处理文件、调接口。
不适合做 Skill 的场景也很清楚:
- 一次性的需求。
- 简单事实查询(天气、汇率这种)。
- 严重依赖实时数据且更适合直接用 MCP。
- 简单格式转换(如「帮我转成表格」这类)。
二、四个核心设计原则:决定 Skill 上限的关键
设计高质量的 Skill 需要遵循四个核心原则。这些原则源自 Anthropic 官方最佳实践,能够确保 Skill 既高效又易用。
2.1 渐进式披露:别一股脑塞东西
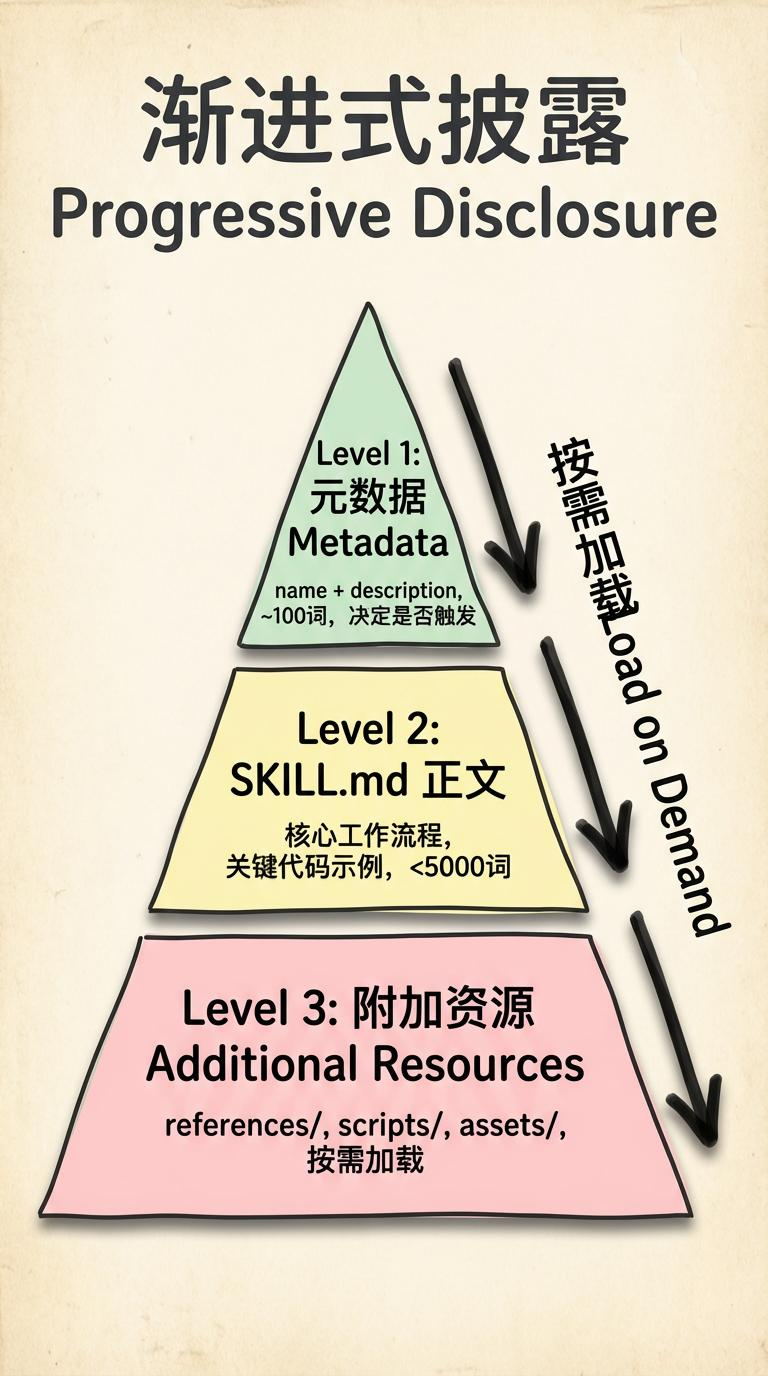
核心思路:把信息分层,用「目录思维」组织 Skill。
把 Skill 里要写的内容分成三层:
-
Level 1:元信息(永远加载)
- name:技能唯一标识。
- description:干什么、在什么情况下触发。
- 大约 100 词,决定「是否触发」这个 Skill。
-
Level 2:SKILL.md 正文(触发时加载)
- 核心工作流程。
- 关键代码示例。
- 各种参考文件的导航。
- 建议控制在 500 行以内,少于 5000 词。
-
Level 3:附加资源(按需加载)
- references/:详细文档。
- scripts/:可执行脚本。
- assets/:模板、示例文件等。
- 这里理论上没有上限,但要通过导航让模型按需读取。
实践上的关键动作是两点:
- SKILL.md 只写「主干流程」,细节拆到 references/。
- 对互斥内容(比如「Windows 方案」和「macOS 方案」)必须拆开文件,避免无脑全塞。
2.2 把上下文当公共资源:少一句是一句
第二个原则很简单:上下文是大家抢着用的资源,每个 token 都要问一句「值吗?」
几个自查问题:
- 这段话 Claude 本来是不是就知道?
- 这段解释是不是业务无关、属于教科书知识?
- 这段是否可以换成一个直接可跑的例子?
- 这几十个字,值不值得占用上下文?
例如, 反对这种长篇背景解释 PDF 是什么,
java
PDF(Portable Document Format,便携式文档格式)是一种用于呈现文档的文件格式,它独立于应用程序软件、硬件和操作系统...而更推荐直接给一个可用示例:
python
from pypdf import PdfReader
reader = PdfReader('document.pdf')
for page in reader.pages:
text = page.extract_text()
print(text)这就是典型的「用例代替废话」。
2.3 按任务脆弱性调节自由度
第三个原则是:窄桥要装护栏,平地就给自由发挥。
- 高自由度:像前端设计方向这类创意任务,只给审美方向和原则,别把模型绑死。
- 中等自由度:有推荐做法,但允许变通的,比如代码重构建议,给流程框架和可调参数。
- 低自由度:一旦出错代价很大(批量删库、报税报表、法律文本生成),就要写严格步骤和具体命令。
举两个例子:前端风格 Skill 是「高自由度」(大胆选择视觉风格),PDF 表单脚本 Skill 是「低自由度」(按指定脚本和步骤执行)。
java
# 高自由度示例(frontend-design)
Choose a BOLD aesthetic direction: brutally minimal, maximalist chaos,
retro-futuristic, organic/natural, luxury/refined...
# 低自由度示例(pdf forms)
1. Run: python
scripts/extract_form_fields.py input.pdf
2. Review the extracted fields
3. Run: python scripts/fill_form.py input.pdf output.pdf --data fields.json2.4 记住读者是模型,不是人
最后一个原则:你在写的不是教程,而是「给 Claude 的操作手册」。
写作要点很直白:
- 多用祈使句:Run、Check、If...then...。
- 假设模型有基础技能,只补它不知道的业务规则和流程。
- 重点写「什么时候、做什么」,而不是大段「你能做什么」的功能宣言。
- 代码示例要能复制就跑,而不是到处 TODO。
三、五种 Skill 结构模式:先选结构,再写内容
五种常见的 Skill 目录结构,可以把它当成「设计前的选型表」。
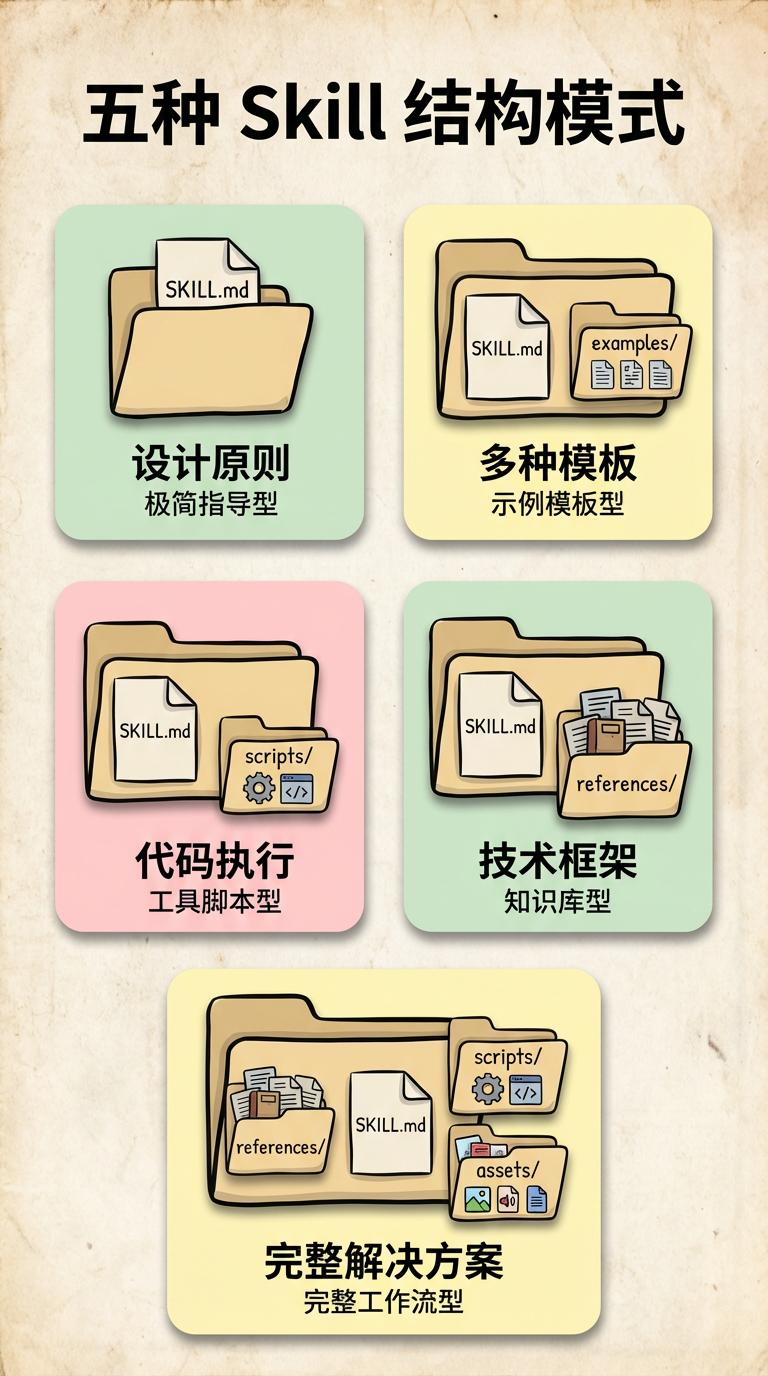
3.1 模式 A:极简指导型
目录结构大概是这样:
text
my-skill/
├── SKILL.md # 全部内容
└── LICENSE.txt # 可选适合场景:
- 风格指南(品牌语气、写作规范)。
- 思维框架、方法论。
- 简单工具的用法。
SKILL.md 推荐行数:50--200 行。
3.2 模式 B:示例模板型
典型结构:
text
my-skill/
├── SKILL.md # 导航 + 选择逻辑
├── examples/ # 或 templates/
│ ├── template-a.md
│ ├── template-b.md
│ └── template-c.md
└── LICENSE.txt使用场景:
- 多种模板选择(比如不同类型的邮件 / 报告)。
- 格式规范。
- 各种固定文本模版。
SKILL.md 一般控制在 50--150 行左右。
3.3 模式 C:工具脚本型
结构大概是这样:
text
my-skill/
├── SKILL.md # 工作流程 + 调用脚本
├── scripts/ # 可执行脚本
│ ├── main_tool.py
│ └── helper.py
├── references/ # 可选:详细文档
│ └── advanced.md
└── LICENSE.txt适用:
- 需要执行代码的任务。
- 稍复杂的数据处理流程。
- 与外部工具结合(比如下载器、测试工具)。
SKILL.md 行数建议 100--300 行。
3.4 模式 D:知识库型
目录大致如下:
text
my-skill/
├── SKILL.md # 极简导航,<100 行
├── rules/ # 或 references/
│ ├── topic-1.md
│ ├── topic-2.md
│ └── ...
├── assets/ # 可选:示例代码
│ └── example.tsx
└── LICENSE.txt适合用来承载:
- 某个技术框架完整指南。
- 知识点众多且相对独立的主题。
- 需要较多参考文档的场景。
SKILL.md 保持在 30--100 行,核心作用是「导航」。
3.5 模式 E:完整工作流型
这是最重型的一种,目录大致长这样:
text
my-skill/
├── SKILL.md # 核心流程 + Quick Start
├── references/
│ ├── forms.md # 条件加载:特定场景
│ ├── advanced.md # 条件加载:高级用法
│ └── api.md # 条件加载:API 参考
├── scripts/
│ ├── process.py
│ ├── validate.py
│ └── export.py
├── assets/
│ └── template.docx
└── LICENSE.txt适合:
- 专业领域的一整套解决方案(PDF、Office 套件处理等)。
- 多场景、多功能,需要工作流的。
- 希望直接放到生产环境里用的场景。
SKILL.md 一般在 200--500 行之间。
四、SKILL.md:一个 Skill 的「心脏」
这一章可以直接当你的写作模板用。
4.1 推荐的文件结构
一个通用模板,大致是这样:
markdown
***
name: skill-name
description: |
[做什么的一句话描述]。
[触发条件/场景列表]。
[可选:触发关键词]
***
# [技能名称]
# Overview / 概述
[1-2 段话说明这个技能做什么]
# When to Use / 何时使用
[列出触发场景]
# Quick Start / 快速开始
[最简单的使用示例]
# Workflow / 工作流程
[核心步骤或决策树]
# Reference Files / 参考文件
- [file1.md](references/file1.md) - 用途说明
# Error Handling / 错误处理
[常见问题和解决方案]自上而下分别解决:是谁、干嘛的、什么时候用、怎么快速上手、完整流程是什么、要看细节去哪看、出错怎么办。
4.2 Frontmatter:name 和 description 写法
name 规则:
- 全小写。
- 单词用短横线连接。
- 不超过 64 字符。
- 不能包含
anthropic、claude这些品牌词。 - 不要用大写和下划线。
例如:
youtube-transcript✅ip-patent-analyzer✅IP_Patent_Analyzer❌claude-helper❌
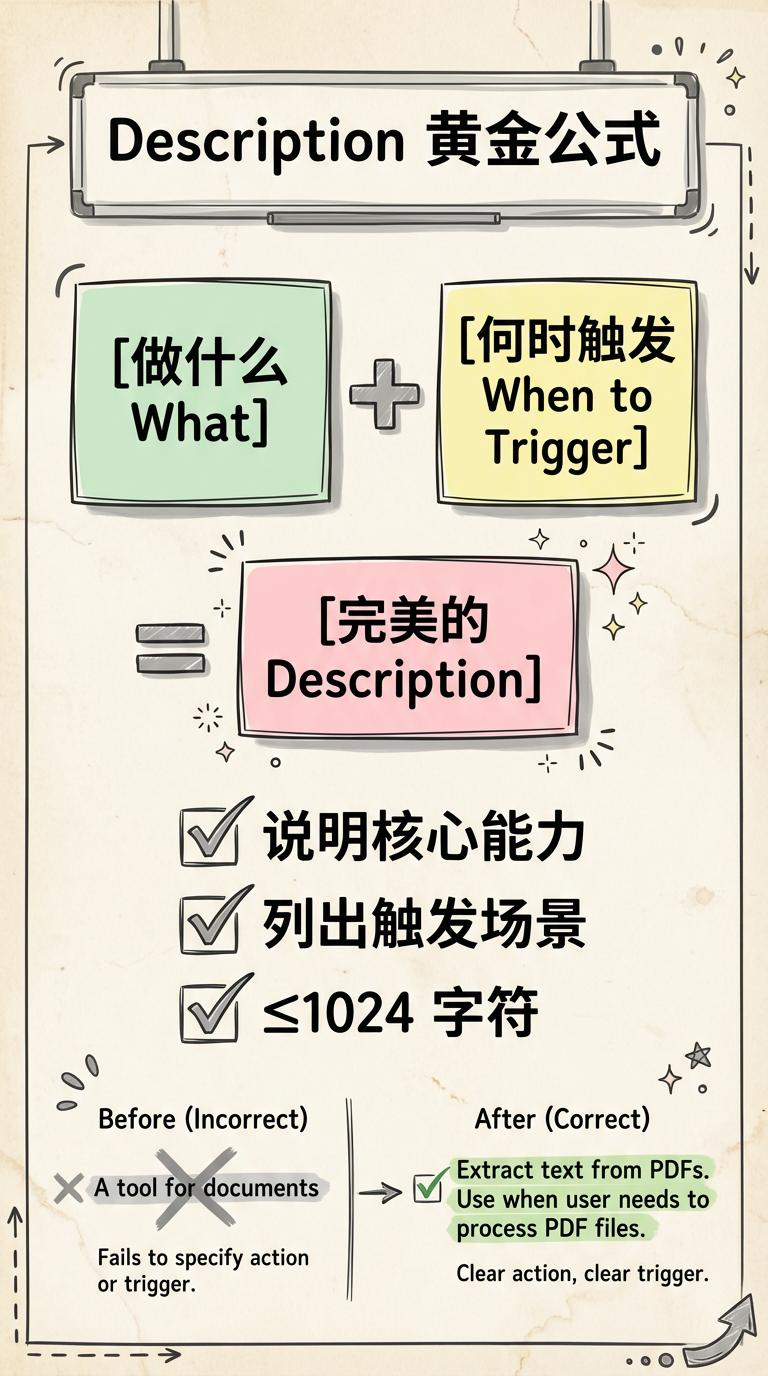
description 是触发的核心,建议用这样的「黄金公式」:
做什么 + 何时触发/使用场景 +(可选)触发关键词
好的例子长这样:
- 工具类:
描述下载 YouTube 字幕的能力,并明确「当用户提供 YouTube URL 或说要获取字幕/转写时触发」。 - 文档处理类:
概括 PDF 提取、合并、表单处理能力,并加上一句「当需要大规模处理 PDF 文档时使用」。 - 支持多语言+触发词:
开头一句中文功能说明,下面一句英文,再列一个「触发方式:下载图片、找视频、download media...」。
反例也很好记:
- 太模糊:
A helpful tool for working with documents. - 只说干嘛,不说什么时候用。
- 啰嗦地科普 PDF 是什么,却没说清它在 Skill 里干嘛。
java
# 示例 1:工具类
description: |
Download YouTube video transcripts when user provides a YouTube URL
or asks to download/get/fetch a transcript from YouTube. Also use
when user wants to transcribe or get captions/subtitles from a YouTube video.
# 示例 2:文档处理类
description: |
Comprehensive PDF manipulation toolkit for extracting text and tables,
creating new PDFs, merging/splitting documents, and handling forms.
When Claude needs to fill in a PDF form or programmatically process,
generate, or analyze PDF documents at scale.
# 示例 3:双语 + 触发词
description: |
智能媒体下载器。根据用户描述自动搜索和下载图片、视频片段,支持视频自动剪辑。
Smart media downloader. Automatically search and download images/video clips
based on user description, with auto-trimming support.
触发方式 Triggers: "下载图片", "找视频", "download media", "download images"
反面示例
# ❌ 太模糊
description: A helpful tool for working with documents.
# ❌ 只说做什么,没说何时用
description: Extract text from PDFs and create new PDF documents.
# ❌ 太长太啰嗦
description: |
This is a comprehensive skill that helps users work with PDF documents.
PDF stands for Portable Document Format and is widely used for sharing
documents. This skill can help you extract text, merge documents, split
documents, rotate pages, add watermarks, and much more...4.3 正文三种常用结构
正文主要有三种模式,可以按任务类型选:
-
决策树型:适合多分支、多场景。先写「Workflow Decision Tree」,再为每个场景开子章节写步骤。
c## Workflow Decision Tree User task → Is it scenario A? ├─ Yes → Use Method 1 (see section below) └─ No → Is it scenario B? ├─ Yes → Use Method 2 └─ No → Use Method 3 (default) ## Method 1: [Scenario A] [详细步骤] ## Method 2: [Scenario B] [详细步骤] -
顺序流程型:适合线性流程,比如「检查前置条件 → 准备输入 → 执行任务 → 后处理」。
c## Workflow ### Step 1: Check Prerequisites [说明 + 命令] ### Step 2: Prepare Input [说明 + 命令] ### Step 3: Execute Main Task [说明 + 命令] ### Step 4: Post-processing [说明 + 命令] -
工具箱型:先给 Quick Start,再按功能拆章节,每个功能里有基础用法和高级用法(高级部分跳到 references)。
c## Quick Start [最简示例] ## Feature 1: [功能名] ### Basic Usage [代码示例] ### Advanced Options See [advanced.md](references/advanced.md) ## Feature 2: [功能名] [同上结构]
4.4 代码示例的硬性要求
一条标准:示例要能直接复制执行,不需要用户「自己补完」。
- 正例:直接给好文件名、循环、打印逻辑,用户粘贴运行就能看到结果。
- 反例:留空字符串、写 TODO、留注释让用户补逻辑,这会严重影响模型学习用法。
五、附加文件:references、scripts、assets 怎么设计?
如果说 SKILL.md 是「大纲和说明书」,那附加文件就是「补充教材、工具箱和模板库」。
5.1 目录总览与角色分工
一个典型 Skill 的目录会长成这样:
text
skill-name/
│
├── SKILL.md # [必需] 核心文件
│
├── references/ # [可选] 详细参考文档
│ ├── getting-started.md # 入门指南
│ ├── advanced.md # 高级用法
│ ├── api.md # API 参考
│ └── troubleshooting.md # 问题排查
│
├── scripts/ # [可选] 可执行脚本
│ ├── main.py # 主工具脚本
│ ├── utils.py # 工具函数
│ └── validate.py # 验证脚本
│
├── assets/ # [可选] 资源文件
│ ├── templates/ # 模板文件
│ ├── examples/ # 示例文件
│ └── fonts/ # 字体等资源
│
└── LICENSE.txt # [推荐] 许可证可以这样记:
- references/:模型要读完再用的内容。
- scripts/:模型直接调用的黑盒工具。
- assets/:输出用素材,模型只会拿来复制或修改。
- examples/:示例内容,帮助模型学格式。
5.2 references/:写给模型看的「长文档」
设计原则:
- 每个文件自包含,不依赖其它 reference 文件。
- 文件长度控制在 100--500 行,超过就拆。
- 超过 100 行最好加一个小目录(TOC)。
推荐结构大致如下:
markdown
***
name: topic-name
description: Brief description of this reference
metadata:
tags: tag1, tag2, tag3
***
# [主题名称]
# Overview
[概述]
# [Section 1]
[内容 + 代码示例]
# Common Patterns
[常用模式、最佳实践]
# Troubleshooting
[常见问题与排查]5.3 scripts/:给模型用的 CLI 工具
这里的原则有几条很重要:
- 当黑盒用:通过
--help就能知道用途和参数。 - 单一职责:一个脚本只做一件事。
- 幂等:同样输入,多次执行结果一样。
- 清晰输出:明确的「成功 / 失败」信息。
- 错误处理:错误信息要能指导后续操作。
Python 脚本模板 ,包含说明、用法示例、参数解析、异常处理、退出码等。可以直接拿来改:
python
#!/usr/bin/env python3
"""
Brief description of what this script does.
Usage:
python script.py <input> [options]
Examples:
python script.py input.pdf
python script.py input.pdf --output result.pdf
"""
import argparse
import sys
def main():
parser = argparse.ArgumentParser(
description='Brief description'
)
parser.add_argument('input', help='Input file path')
parser.add_argument('-o', '--output', help='Output file path')
args = parser.parse_args()
try:
result = process(args.input, args.output)
print(f"✓ Success: {result}")
sys.exit(0)
except Exception as e:
print(f"✗ Error: {e}", file=sys.stderr)
sys.exit(1)
if __name__ == '__main__':
main()
"""后面配合 argparse、try/except、sys.exit(0/1) 等完整模式。
5.4 assets/:模板和资源文件
assets/ 里的内容模型一般不会读,而是当作「素材」来用:
- 各种文档模板(.docx、.pptx、.html)。
- 图片资源(logo、图标)。
- 字体、配置模版等。
Skill 的作用是指挥模型拷贝或改这些文件,而不是让模型把它们读到上下文里。
六、脚本开发:让 Skill 真正「有手有脚」
如果你的 Skill 会跑脚本,这一章基本就是一份脚本开发标准。
6.1 一个好脚本应该长什么样?
六个特点:
- 自描述:
--help足够详细。 - 单一职责:一个脚本就做一件清晰的事情。
- 幂等:多次执行不会产生奇怪的副作用。
- 输出清晰:成功用 ✓,失败用 ✗,不要一堆难懂的日志。
- 出错友好:错误信息里最好带解决建议。
- 对模型透明:模型可以当工具直接调用,无需理解内部实现。
6.2 常见的错误处理模式
3个小模式:
- 前置检查:比如先检查 ffmpeg、yt-dlp 是否安装,不满足就列出缺什么,并退出。
- 操作前确认:对于可能耗时或有风险的操作,用
Proceed? (y/n)让用户确认。 - 分步骤反馈:处理一批 items 时,按
[i/total]打印进度,失败的给出错误原因。
这套方式对人类用户也友好。
6.3 CLI 入口推荐写法
推荐用 argparse + 子命令 的方式搭结构,比如 status、process 两个子命令,对应不同功能。这样 Skill 在调用脚本时也更清晰,不需要记一堆参数顺序。
七、从 0 到 1:六步创建你的第一个 Skill
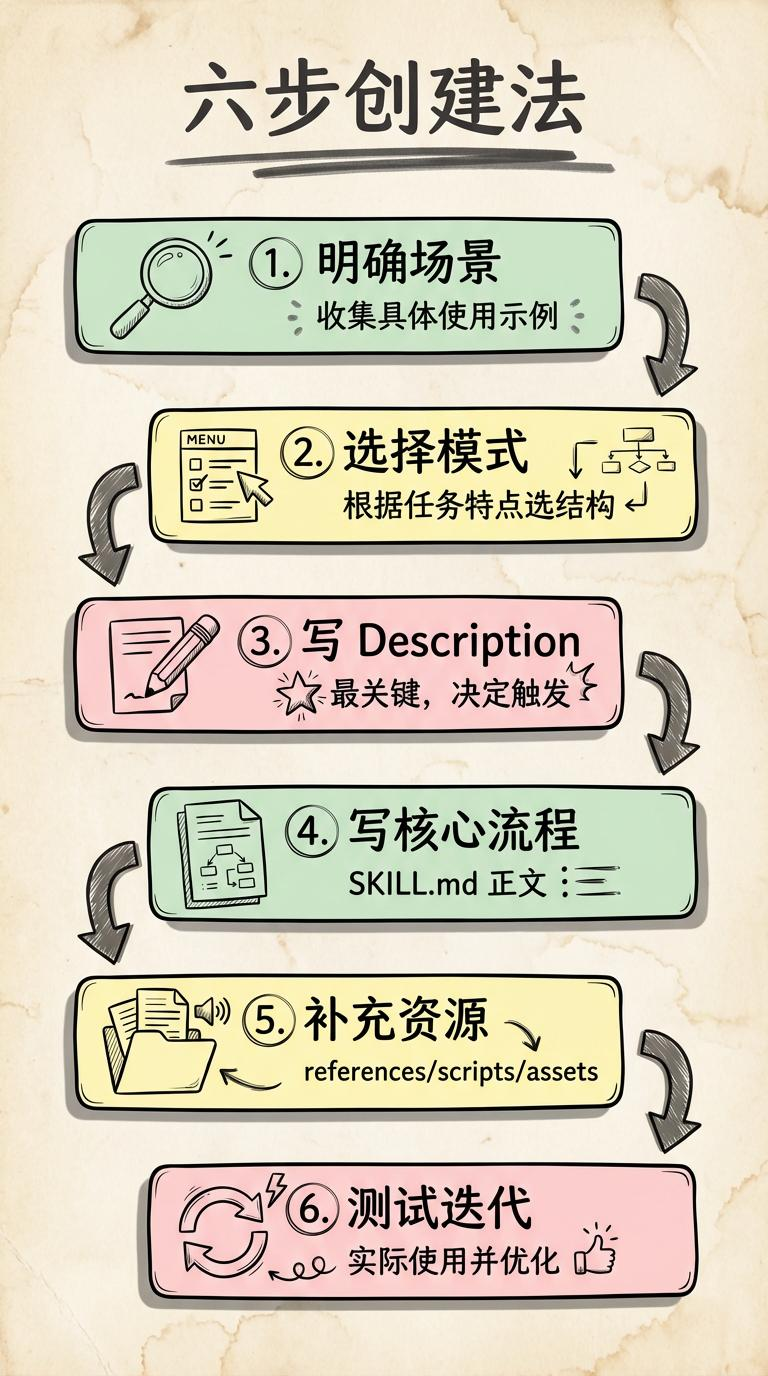
这部分可以直接当你的工作流程用。
Step 1:先把场景说清楚
先别写代码,先写清楚「Skill 要解决什么真实问题」。
可以用这些问题引导自己:
- 这个 Skill 要解决的具体问题是什么?
- 用户会用什么话来触发它?
- 有哪些典型场景?每个场景的输入输出是什么?
比如专利场景做了示例,列了「专利检索」「专利分析」「侵权判断」三个具体场景,每个都写了用户怎么说、输入和输出。你可以照抄这个格式,替换成自己业务。
java
## 场景分析
### 场景1: 专利检索
用户说: "帮我检索关于XX技术的专利"
输入: 技术关键词
输出: 专利列表 + 摘要
### 场景2: 专利分析
用户说: "分析这份专利的权利要求"
输入: 专利号或PDF
输出: 权利要求解读 + 保护范围
### 场景3: 侵权判断
用户说: "判断这个产品是否侵犯专利"
输入: 产品描述 + 专利号
输出: 侵权分析报告Step 2:根据场景选结构模式
对照五种结构模式,选一个最贴合的,顺便把理由写下来。
例如:专利 Skill 选择「模式 E 完整工作流型」,理由是:
- 有多个功能(检索 / 分析 / 判断)。
- 需要跑接口调用(脚本或 MCP)。
- 部分场景需要法律条款等长文档支撑。
这一步相当于给后续目录画了个线框图。
Step 3:写好 description(这一步最关键)
description 决定 Skill 能不能被正确触发,要格外上心。
可以用这个模板开头:
text
description: |
[一句话说明核心能力]。
Use when... / When user...:(列出 1-3 个场景)
[可选:触发关键词列表]写完后,用这几个问题自查:
- 有没有说清楚「做什么」?
- 触发场景有没有具体到「用户会说的原话」?
- 有没有把常见关键词写进去?
- 字数有没有超过 1024 字?
Step 4:搭出核心流程骨架
先把框架搭好,再往里填内容,不要一上来就写长篇说明。
推荐骨架:
markdown
# [Skill 名字]
# Overview
[简要说明]
# When to Use
[把 Step 1 里的场景复制过来整理]
# Quick Start
[最简单的一次调用示例]
# Workflow
[流程图 / 决策树 / 步骤列表]
# [具体功能章节]
[按功能拆详细说明]
# Reference Files
[列出 references/ 里的文件及用途]Step 5:补充 references / scripts / assets
根据前面设计的模式,把长文、脚本、模板拆出去:
- 长文档 → references/。
- 工具脚本 → scripts/。
- 模板资源 → assets/。
记得遵守前面讲的长度和结构原则。
Step 6:用真问题反复测试和迭代
最后一步是不断打磨:
- 用不同说法尝试触发 Skill,看是否精准。
- 跑一遍每个场景的完整流程。
- 故意制造错误,确认报错和引导是否友好。
- 把遇到的问题和修改记录下来(比如发现少写了「检索」这个关键词,就加回 description 里)。
一个「迭代记录」示例,建议你也在自己项目里保留一份简单的迭代日志,方便回顾。
c
## 迭代记录
### 问题1: Description 触发不准确
现象: 用户说"检索专利"时没有触发
解决: 在 description 中添加"检索"、"搜索"关键词
### 问题2: 流程中途中断
现象: Claude 执行到第3步就停止了
解决: 在 SKILL.md 中添加明确的步骤编号和"继续下一步"提示
### 问题3: 脚本报错信息不清晰
现象: 用户不知道如何解决报错
解决: 改进脚本的错误信息,添加解决建议八、发布前的质量检查:别把半成品丢给业务
8.1 Frontmatter 检查
- name 符合命名规则(小写、短横线、不含品牌词、长度合规)。
- description 清楚描述「做什么」和「何时触发」。
- 字数不超过 1024 字符。
8.2 SKILL.md 检查
- 有 Quick Start 或最小可用示例。
- 有清晰的工作流程描述。
- 示例代码能直接跑。
- 所有引用的文件都真实存在。
- 总行数不超过 500 行,超过就拆。
8.3 附加文件检查
- references/ 里的每个文件都是自包含的。
- scripts/ 中的脚本都带
--help。 - 脚本都有基础错误处理。
- 没有多余文件(README、CHANGELOG、CONTRIBUTING 等)。
8.4 功能与维护性自查
从四个角度做一次自我评估:
- 内容精简度:有没有废话?能不能用例子替代长篇解释?
- 触发准确度:description 是否覆盖用户常用说法?会不会误触?
- 执行可靠度:流程是否无歧义?脚本和示例是否都跑过?
- 维护友好度:结构是否清晰?后续扩展新功能是否容易?
九、常见反模式:这些坑可以直接绕开
下面列了一些典型「反例」,非常值得收藏。
- 描述太模糊:只说「用于处理文档」,完全看不出具体能力和触发条件。
- 一次性塞太多内容:把所有细节都堆在 SKILL.md 里,不拆到 references。
- 不写触发条件:只说「能做什么」,不说「什么时候用」。
- 代码示例不可执行:充满占位符和 TODO。
- 脚本没帮助信息:直接用
sys.argv读参数,没有 argparse,也没有--help。 - 创建一堆没用的说明文件:README、INSTALLATION、CHANGELOG 等,反而把目录搞乱。
java
# ❌ 差
skill/
├── SKILL.md
├── README.md # ❌ 不需要
├── INSTALLATION.md # ❌ 不需要
├── CHANGELOG.md # ❌ 不需要
└── CONTRIBUTING.md # ❌ 不需要
# ✅ 好
skill/
├── SKILL.md
├── references/
│ └── advanced.md
└── scripts/
└── process.py结语:把 Skill 当成「产品」而不是「提示词」
一个好的 Agent Skill,本质上是一个可维护、可扩展的「小产品」,而不是一段高级 Prompt。
可以用本文的思路落地一整套实践方式:
- 先用六步法把业务场景、流程、脚本整理出来。
- 按五种结构模式给 Skill 做「架构设计」。
- 严格按四大原则写 SKILL.md 和附加文件。
- 再用那份 Checklist 做一次完整体检,然后再推给业务团队试用。
只要你肯花一两天,认真做一两个高质量 Skill,你会发现:后面很多复杂的需求,不用从头想 Prompt 了,直接往这个 Skill 上加场景,就能稳定复用。
这才是「从玩工具」到「做产品」的真正分界线。
