前言:正当我沉浸在将draw call从52000优化到1的喜悦中无法自拔时,产品经理这时候又杀过来了:"客户说模型加载要30秒,还没进去就关页面了,你优化一下?"我打开Network面板一看,卧槽,86MB的GLB文件!这谁顶得住啊...
如果你也遇到过这种情况:精心打磨的3D场景,本地运行丝滑流畅,一上线用户骂娘------"破网站卡死了"、"怎么还在转圈"、"手机直接闪退"。别急着怪用户网速慢,先看看你的模型是不是太胖了。
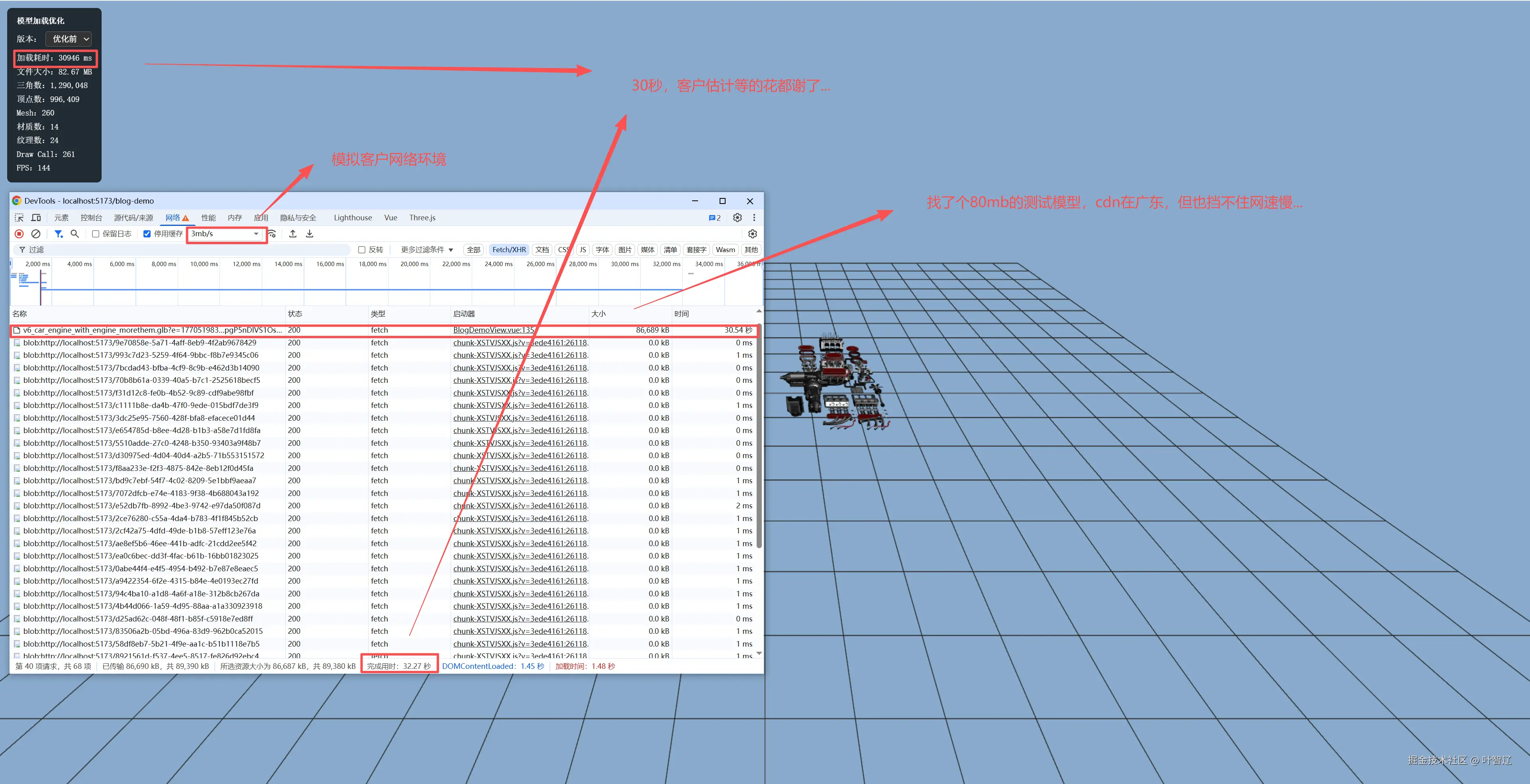
我这有个复杂模型,几何体+贴图一共86MB ,在4G网络下加载需要30秒 (Chrome模拟Slow 4G(3mb/s)一直加载...)。今天咱们不讲Blender操作模型(之前用Blender是因为没招,现在有更狠的),直接用命令行黑魔法 把它压到4MB!! ,加载时间从30秒干到1.5秒。
以下是优化前的绝望现场整整加载了30多秒...
一、优化思路
既然知道了加载为什么那么慢的原因,那我们就可以开始想想该怎么优化了
我目前的思路就是用gltf-transform 先把模型体积压下来,要不然渲染的时候再流畅,客户等到第二十秒的时候关闭浏览器,也没有意义了。。
二、DRACOLoader
ThreeJS DRACOLoader直接无缝解压缩被压缩的模型
安装压缩模型工具(不用Blender,命令行搞定)
bash
# 安装gltf-transform(一行命令搞定Draco压缩+WebP+KTX2)
npm install -g @gltf-transform/cli至于我为什么选择gltf-transform而不是gltf-pipeline,以下是它们的对比:
| 特性 | gltf-pipeline | gltf-transform |
|---|---|---|
| Draco压缩 | ✅ 支持 | ✅ 支持(更快) |
| WebP纹理 | ❌ 不支持 | ✅ 支持(关键!) |
| KTX2/Basis | ❌ 不支持 | ✅ 支持 |
| 安装体积 | 大(依赖多) | 小(WASM核心) |
| 推荐度 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
压缩你的GLB(80MB → 4MB)
bash
gltf-transform optimize input.glb output.glb \
--compress draco \
--texture-compress webp \
--texture-size 2048以下是我压缩之后的体积:
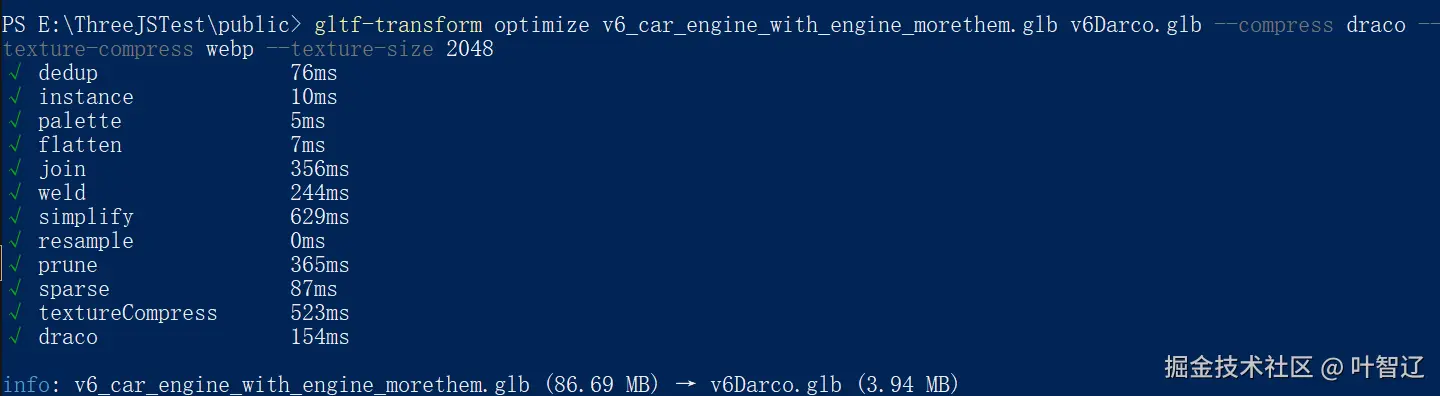
可以看到,模型的体积得到了巨大的缩减,从原来的86mb到现在的4mb左右!
参数说明:
| 参数 | 说明 | 建议值 |
|---|---|---|
--texture-compress webp |
贴图转WebP格式 | 必加,体积减半 |
--texture-compress ktx2 |
贴图转KTX2(GPU直读) | 如果目标设备支持,比WebP更好 |
--texture-size 2048 |
限制最大贴图尺寸 | 必加,4096→2048省4倍显存 |
--compress draco |
启用Draco几何压缩 | 必加,默认就是sequential模式 |
--compress-method sequential |
Draco编码模式 | sequential(默认,小体积)或 edgeloop(快解码) |
--compress-level 10 |
Draco压缩级别 | 0-10,10压最狠但解压慢,建议7-10 |
--flatten |
打平节点层级 | 如果模型层级太深,加这个减少DrawCall(但会丢失动画) |
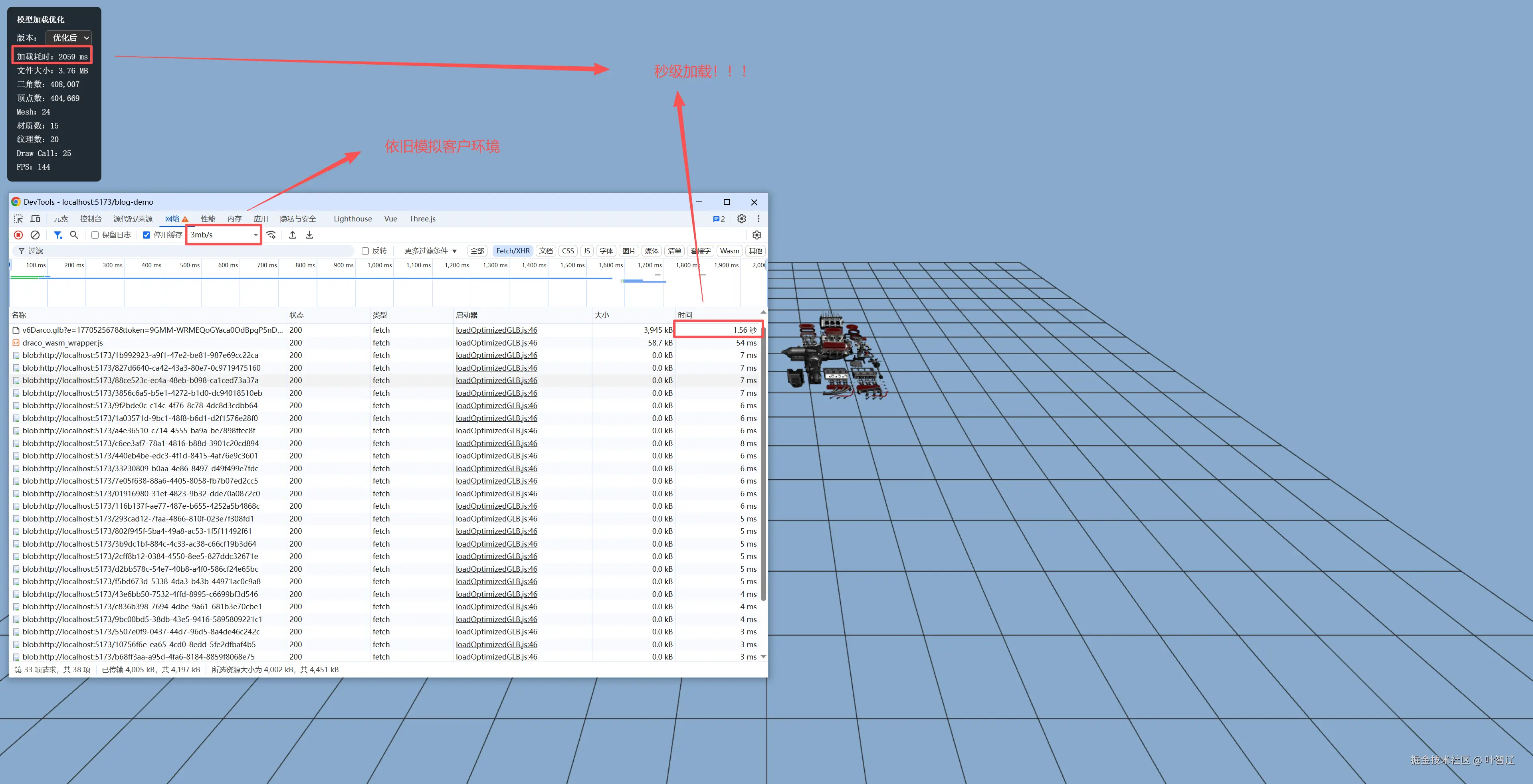
以下是优化之后的加载时间,就问你快不快!
Three.js加载代码(关键!)
javascript
/**
* 优化后的 GLB 加载步骤(Draco / gltf-transform)
*
* 依赖:Three.js、GLTFLoader、DRACOLoader
* 解码器:把 three 的 examples/jsm/libs/draco/gltf/ 放到站点 /draco/ 下,或使用 CDN 路径
*/
import { GLTFLoader } from 'three/examples/jsm/loaders/GLTFLoader';
import { DRACOLoader } from 'three/examples/jsm/loaders/DRACOLoader';
// --------------- 步骤 1:创建 Draco 解码器并指定路径 ---------------
const dracoLoader = new DRACOLoader();
dracoLoader.setDecoderPath('/draco/');
// 或用 CDN(与项目 three 版本一致):'https://cdn.jsdelivr.net/npm/three@0.182.0/examples/jsm/libs/draco/gltf/'
// --------------- 步骤 2:把 DRACOLoader 挂到 GLTFLoader 上 ---------------
const loader = new GLTFLoader();
loader.setDRACOLoader(dracoLoader);
// --------------- 步骤 3:正常 load,普通 GLB 与 Draco 压缩的 GLB 都能加载 ---------------
loader.load(
'https://your-cdn.com/model-optimized.glb',
(gltf) => {
scene.add(gltf.scene);
},
undefined,
(err) => console.error(err),
);
// Promise 写法(可选):
export function loadOptimizedGLB(url) {
return new Promise((resolve, reject) => {
loader.load(url, resolve, undefined, reject);
});
}
// 使用方式:const gltf = await loadOptimizedGLB(url);注意 :setDecoderPath 指向的是 Draco 的 WASM 解码文件,需要从 Three.js 的 examples/jsm/libs/draco/ 目录复制到你的 public 文件夹,或者用 CDN(上面示例用的是从threejs复制的本地解码文件)。
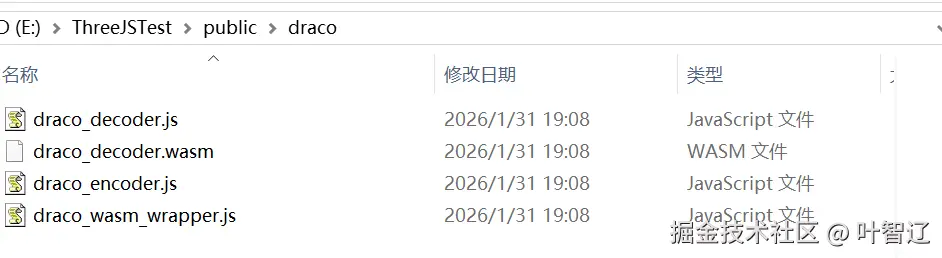
避坑指南
- 别重复压缩 :Draco是有损压缩,压一次损失一点精度,别压两遍!先备份原文件。
- WebP兼容性:虽然现代浏览器都支持WebP,但如果你要兼容IE11(虽然不应该),只能用PNG/JPG。
- KTX2谨慎用:KTX2(Basis Universal)压缩率最高,但需要 GPU 支持,老旧手机可能解码失败,建议 WebP 更稳妥。
- 量化精度 :如果你发现压缩后的模型出现裂缝 (顶点没对齐),把
--quantization-position从 10 调到 14。
还有一件事 :Draco是有损压缩,但视觉上几乎看不出差别(工业模型顶点精度够高),解压是在Web Worker里进行的,不会卡主线程。
三、又到了喜闻乐见的前后对比(刺激!)
| 指标 | 原始模型 | Draco压缩 |
|---|---|---|
| 文件体积 | 86MB | 4MB |
| 4G加载时间 | 30秒 | 1.5秒 |
可以看到加载时间跨度很大,从30秒到1.5秒,足足提升了20倍,客户本来都要睡着了,但现在客户眨了一下眼睛,就发现眼前屏幕里的世界都不一样了~
总结
优化路径:86MB(原始)→ 4MB(Draco+WebP)→ 1.5秒加载完成
核心认知:
- gltf-transform:一站式解决几何体+贴图压缩,不用Blender,一行命令搞定
- Draco:解决"下载慢"(几何体从18MB压到2MB)
- WebP:解决"贴图肥"(68MB压到2MB,兼容性最好)
没用到的手段(进阶可选):
- KTX2:比WebP体积更小且GPU直读,但需要设备支持,老旧手机可能解码失败
- 分块加载:如果4MB还是大,可以拆成"外壳1MB+细节3MB",首屏秒开
不用Blender,全程命令行+代码搞定,这才是工程师的浪漫。
下篇预告:【ThreeJS实战】GPU还是100%?LOD策略:让远处模型自动"减肥"
互动 :你用gltf-transform压了多少倍?我20倍 算不算狠?评论区报出你的原始体积vs优化后体积,看看谁是真正的"压王"😏