DeepSeek-OCR-2 开源 OCR 模型的技术
OCR应用的场景和类型很广,本次使用Qwen2的架构,解决看的全(扫码方式优化)、看的的准(内容识别、视觉标记、降低重复率),多裁剪策略提取核心信息。和其他OCR模型项目还是看自己的引用场景,通用场景还是建议使用最新的模型,识别准、理解准、排版准。
2025-2026年,OCR(光学字符识别)领域迎来了开源大模型的黄金时代。继 DeepSeek 在自然语言处理领域掀起波澜之后,其于 2026 年 1 月 27 日开源的 DeepSeek-OCR-2 再次引发行业关注。几乎同期,腾讯也在 2025 年底开源了 HunyuanOCR(混元OCR)------一个仅 1B 参数却斩获多项 SOTA 的轻量级模型。
这两款模型代表了当前开源 OCR 技术的两大发展方向:DeepSeek-OCR-2 主打视觉因果流(Visual Causal Flow)的创新架构,而 HunyuanOCR 则以极致轻量化+端到端统一见长。本文将深入分析这两款模型的技术特点,并与 PaddleOCR、Qwen-VL、GOT-OCR2.0 等主流方案进行对比,帮助开发者理解各模型的适用场景。
一、DeepSeek-OCR-2:视觉因果流的革新
1.1 核心创新:DeepEncoder V2
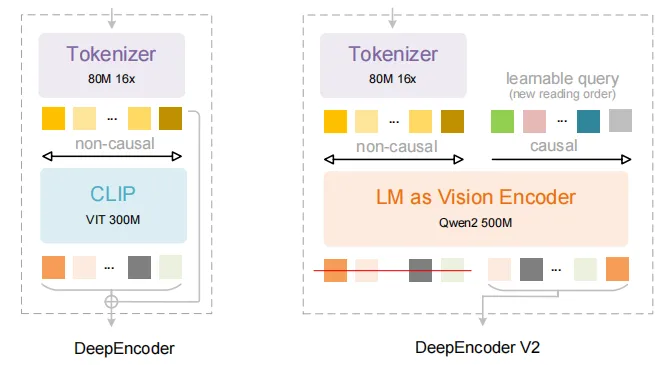
DeepSeek-OCR-2 最引人注目的创新在于其 DeepEncoder V2 视觉编码器。传统 OCR 模型(包括大多数 VLM)采用固定的栅格扫描方式(从左到右、从上到下)处理图像,这种方式与人类阅读习惯相悖,尤其在处理复杂版面(如多栏文档、表格、图文混排)时容易产生逻辑错误。
DeepEncoder V2 引入了**视觉因果流(Visual Causal Flow)**机制:
- 全局理解优先:模型首先建立对整页文档的全局语义理解
- 语义驱动阅读顺序:根据内容逻辑动态确定处理顺序,而非机械扫描
- 类人类阅读模式:能够正确处理多栏排版、表格单元格关联、图文穿插等复杂场景
技术亮点:DeepEncoder V2 采用轻量级 LLM 架构(基于 Qwen2-0.5B)替换了传统的 CLIP 视觉编码器,配合双流注意力机制------视觉 token 使用双向注意力提取全局特征,文本生成使用因果注意力保证阅读顺序合理性。
1.2 模型规格与性能
| 指标 | DeepSeek-OCR-2 |
|---|---|
| 参数量 | 3B |
| 视觉编码器 | DeepEncoder V2 (基于 Qwen2-0.5B) |
| 语言解码器 | DeepSeek3B-MoE-A570M |
| 支持分辨率 | 动态分辨率,最高 1024×1024 |
| 视觉 Token 数 | 256-1,120(根据内容自适应) |
| 上下文压缩 | 支持,大幅降低下游 LLM 计算成本 |
| 许可证 | Apache-2.0 |
动态分辨率配置:
- 默认方案:(0-6)×768×768 + 1×1024×1024
- Token 数:(0-6)×144 + 256
1.3 核心能力
- 复杂版面解析:在表格、多栏文档、公式混排等场景表现出色
- Markdown/结构化输出:支持将文档直接转换为带格式的 Markdown
- 多语言支持:基于 DeepSeek 的多语言优势,支持主流语种
- 推理加速:支持 vLLM 和 Transformers 两种推理方式

二、HunyuanOCR:轻量级全能选手
2.1 端到端一体化设计
腾讯 HunyuanOCR 采用端到端训推一体架构,这是其与传统 OCR 系统的根本差异:
传统 OCR 流水线:
图像 → 版面分析 → 文本检测 → 文本识别 → 后处理 → 输出HunyuanOCR 端到端流程:
图像 → 单次推理 → 直接输出结构化结果这种设计彻底消除了级联误差累积问题,同时大幅简化了部署流程。
2.2 架构组成
| 组件 | 技术细节 |
|---|---|
| 视觉编码器 | SigLIP-v2-400M,原生分辨率输入,自适应 Patching |
| 连接器 | 可学习池化操作,压缩高分辨率特征保留文本密集区语义 |
| 语言模型 | Hunyuan-0.5B,引入 XD-RoPE 技术解耦一维文本、二维版面、三维时空信息 |
XD-RoPE(扩展相对位置编码) 是 HunyuanOCR 的关键创新,它使模型能够:
- 理解跨栏排版的逻辑关系
- 处理跨页文档的长距离依赖
- 保持复杂表格的行列对应关系
2.3 性能表现
| 评测项目 | 成绩 | 备注 |
|---|---|---|
| OCRBench | 860 分 | 3B 参数以下模型 SOTA |
| OmniDocBench | 94.1 分 | 复杂文档解析最高分,超越 Gemini3-pro |
| 文字检测识别 | 70.92% | 自建基准,覆盖 9 大场景 |
| 信息抽取 | 92.29% | 卡片/收据/视频字幕 |
| 模型大小 | 2GB | 20GB GPU 显存可部署 |
| 支持语言 | 130+ | 含 14 种高频小语种 |
三、技术对比:DeepSeek-OCR-2 vs HunyuanOCR
| 对比维度 | DeepSeek-OCR-2 | HunyuanOCR |
|---|---|---|
| 参数规模 | 3B | 1B |
| 架构理念 | 视觉因果流,类人类阅读顺序 | 端到端统一,单次推理 |
| 视觉编码器 | DeepEncoder V2 (LLM-based) | SigLIP-v2-400M |
| 核心创新 | Visual Causal Flow 机制 | XD-RoPE 位置编码 |
| 文档解析 | ★★★★★ | ★★★★★ (94.1分 OmniDocBench) |
| 表格识别 | 强 | 强 (HTML 格式输出) |
| 公式识别 | LaTeX 格式 | LaTeX 格式 |
| 多语言 | 主流语种 | 130+ 语言,含小语种翻译 |
| 部署成本 | 中等 | 低 (20GB 显存) |
| 输出格式 | Markdown、纯文本 | Markdown、HTML、JSON、LaTeX |
| 特殊能力 | 上下文压缩,降低下游 LLM 成本 | 拍照翻译、视频字幕提取 |
| 开源时间 | 2026-01-27 | 2025-11-26 |
3.1 关键差异解读
1. 阅读顺序理解
DeepSeek-OCR-2 的 Visual Causal Flow 在处理非线性阅读顺序的文档时具有理论优势,例如:
- 报纸版面(多栏穿插)
- 学术论文(图表与正文引用关系)
- 复杂表格(跨行跨列单元格)
HunyuanOCR 则通过 XD-RoPE 在位置关系建模上达到类似效果,实测在 OmniDocBench 上取得更高分数。
2. 部署与成本
HunyuanOCR 的 1B 参数设计明显瞄准边缘部署场景,20GB 显存即可运行,适合:
- 中小企业私有化部署
- 移动端/嵌入式设备
- 高并发 API 服务
DeepSeek-OCR-2 的 3B 参数提供更强的语义理解能力,适合:
- 复杂文档的深度解析
- 需要上下文压缩降本的大规模文档处理
- 与 LLM 配合的多模态 RAG 系统
3. 功能覆盖
HunyuanOCR 功能更全面,内置:
- 拍照翻译(14 种语言互译)
- 视频字幕提取
- 开放字段信息抽取(JSON 输出)
DeepSeek-OCR-2 更专注于文档到结构化文本的转换,强调与下游 LLM 的协同。
四、与其他主流 OCR 方案的对比
4.1 PaddleOCR:工业级成熟方案
| 特点 | 详情 |
|---|---|
| 定位 | 传统 OCR 工具库(检测+识别两阶段) |
| 优势 | 生态完善、中文优化好、轻量模型多 |
| 模型大小 | 超轻量模型仅 8.6MB |
| 适用场景 | 移动端、边缘设备、已知版式文档 |
| 局限 | 复杂版面需配合版面分析工具,非端到端 |
对比结论 :PaddleOCR 适合需要精细控制 和低资源占用 的传统 OCR 任务,而 DeepSeek-OCR-2 和 HunyuanOCR 更适合需要端到端理解复杂文档的场景。
4.2 GOT-OCR2.0:学术界的统一模型
| 特点 | 详情 |
|---|---|
| 定位 | 统一端到端 OCR-2.0 模型 |
| 架构 | 生成式预训练(类似 LLM) |
| 特点 | 强调整体文档理解 |
| 适用场景 | 学术研究、复杂版式文档 |
对比结论:GOT-OCR2.0 与 DeepSeek-OCR-2 理念相近,但后者在视觉编码器创新和工程化(vLLM 支持)方面更进一步。
4.3 Qwen2-VL:通义千问多模态
| 特点 | 详情 |
|---|---|
| 定位 | 通用多模态大模型 |
| 参数 | 2B / 7B / 72B 可选 |
| 特点 | 视觉-语言理解能力强,不仅限于 OCR |
| 适用场景 | 需要多模态理解(图像+文本+推理)的综合应用 |
对比结论:Qwen2-VL 是"通用选手",OCR 只是其能力之一;DeepSeek-OCR-2 和 HunyuanOCR 是"OCR 专家",在文档解析专项上更精专。
4.4 综合对比表
| 模型 | 类型 | 参数量 | 端到端 | 复杂版面 | 部署难度 | 最佳场景 |
|---|---|---|---|---|---|---|
| DeepSeek-OCR-2 | OCR VLM | 3B | ✅ | ★★★★★ | 中 | 复杂文档+RAG |
| HunyuanOCR | OCR VLM | 1B | ✅ | ★★★★★ | 低 | 轻量部署+多功能 |
| PaddleOCR | 传统 OCR | 8.6M-100M | ❌ | ★★☆☆☆ | 极低 | 移动端/高并发 |
| GOT-OCR2.0 | OCR VLM | 1.5B | ✅ | ★★★★☆ | 中 | 学术研究 |
| Qwen2-VL | 通用 VLM | 2B-72B | ✅ | ★★★★☆ | 高 | 多模态综合应用 |
| Tesseract | 传统 OCR | - | ❌ | ★☆☆☆☆ | 极低 | 简单文字识别 |
五、选型建议:如何选择适合你的 OCR 方案
5.1 按应用场景选择
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 智能文档处理(IDP) | HunyuanOCR / DeepSeek-OCR-2 | 端到端,支持结构化输出 |
| 移动端 OCR | PaddleOCR 超轻量模型 | 资源占用极低 |
| 多模态 RAG | DeepSeek-OCR-2 | 上下文压缩降低 LLM 成本 |
| 拍照翻译 | HunyuanOCR | 内置翻译,14 语种支持 |
| 视频字幕提取 | HunyuanOCR | 专门优化 |
| 发票/卡证识别 | PaddleOCR / HunyuanOCR | 有专用模型或 JSON 输出 |
| 学术论文解析 | DeepSeek-OCR-2 | LaTeX 公式识别强 |
| 边缘设备部署 | HunyuanOCR | 1B 参数,20GB 显存可跑 |
5.2 按技术栈选择
如果你的系统已经基于 vLLM:
- DeepSeek-OCR-2 和 HunyuanOCR 都提供原生 vLLM 支持,集成成本低
如果你需要与现有 CV 流水线集成:
- PaddleOCR 提供更细粒度的模块化控制
如果你正在构建 LLM 应用(如知识库问答):
- DeepSeek-OCR-2 的上下文压缩特性可以显著降低文档预处理成本
六、总结与展望
DeepSeek-OCR-2 和 HunyuanOCR 的开源,标志着 OCR 技术进入了一个新的阶段------从传统的"字符识别"进化为"文档理解"。
核心趋势
- 端到端统一:告别检测→识别→后处理的级联流水线,单次推理直接输出结构化结果
- 轻量高效:1B-3B 参数即可达到商业级精度,降低部署门槛
- 复杂版面理解:不再局限于简单的文字识别,而是理解文档的逻辑结构和阅读顺序
- 多模态融合:OCR 与翻译、问答、信息抽取等功能深度融合
技术选型核心观点
- 追求极致轻量和功能全面 → 选 HunyuanOCR
- 专注复杂文档解析和 LLM 协同 → 选 DeepSeek-OCR-2
- 传统场景、资源极度受限 → 选 PaddleOCR
- 通用多模态理解需求 → 选 Qwen2-VL
这两款中国团队开源的 OCR 模型,不仅在技术指标上达到 SOTA,更重要的是它们代表了开源社区对"文档智能"这一核心场景的深度思考。对于开发者而言,2026 年是 OCR 技术选型最优的一年------既有成熟的传统方案,也有前沿的端到端模型,且都是免费开源的。
参考链接
- DeepSeek-OCR-2: https://github.com/deepseek-ai/DeepSeek-OCR-2
- HunyuanOCR: https://github.com/Tencent-Hunyuan/HunyuanOCR
- PaddleOCR: https://github.com/PaddlePaddle/PaddleOCR
- GOT-OCR2.0: https://github.com/Ucas-HaoranWei/GOT-OCR2.0
- Qwen2-VL: https://github.com/QwenLM/Qwen2-VL
(本文由 AI 辅助整理技术资料,核心数据来源于各模型官方技术报告和 GitHub 仓库。)