🚀 保姆级教程:在 Windows (WSL2) 下本地部署 Qwen3-ASR
------ 基于 uv + vLLM 的高性能语音识别方案 (2026版)
参考 https://github.com/QwenLM/Qwen3-ASR
📝 前言
本教程旨在帮助 Windows 用户利用 WSL2 和 RTX 系列显卡 ,在本地部署阿里最新的 Qwen3-ASR-1.7B 语音识别模型。
我们将使用 uv 进行极速环境管理,使用 vLLM 进行高吞吐推理。
特别优化: 本教程已包含针对国内网络环境 (HuggingFace 连不上)和WSL2 缺失编译环境的完美解决方案。
🛠️ 第一阶段:基础环境准备
1. Windows 端准备
- 显卡驱动: 请确保你的 Windows 系统已安装最新的 NVIDIA 显卡驱动(无需在 WSL 里安装驱动,它会自动透传)。
- 启用 WSL2:
以管理员身份打开 PowerShell,输入:
powershell
wsl --install打开 Ubuntu 设置用户名和密码。
2. Linux (WSL) 系统依赖修复【关键避坑点】
vLLM 在运行时需要实时编译组件,原生 WSL Ubuntu 缺少必要的编译器和 Python 头文件。
打开 Ubuntu 终端,一次性执行以下命令修复 (避免报错 Failed to find C compiler 或 Python.h: No such file):
bash
sudo apt update
sudo apt install build-essential python3-dev python3.12-dev(注:这里假设你安装的是 Ubuntu 24.04 默认带 Python 3.12,如果是其他版本请相应调整)
3. 安装新一代包管理器 uv
我们将使用 Rust 编写的 uv 替代 Conda,速度快且节省空间。
bash
curl -LsSf https://astral.sh/uv/install.sh | sh安装后建议关闭终端重新打开。
📦 第二阶段:项目部署与安装
1. 创建项目环境
不要污染系统 Python,我们为 ASR 单独建个"家"。
bash
mkdir qwen-asr
cd qwen-asr
# 创建虚拟环境
uv venv
# 激活环境
source .venv/bin/activate2. 安装 vLLM (支持 Qwen3 的开发版)
由于 Qwen3-ASR 是新模型,我们需要安装 vLLM 的 Nightly 版本。请整段复制以下命令执行:
bash
# 1. 安装 vLLM 核心及 PyTorch (自动适配 CUDA)
uv pip install -U vllm --pre \
--extra-index-url https://wheels.vllm.ai/nightly/cu121 \
--extra-index-url https://download.pytorch.org/whl/cu121 \
--index-strategy unsafe-best-match
# 2. 安装音频处理支持
uv pip install "vllm[audio]"🏃 第三阶段:启动模型服务
1. 启动命令 (加入国内镜像加速)
这是最关键的一步。我们通过设置 HF_ENDPOINT 环境变量,强制让 vLLM 走国内镜像站下载模型,解决 OSError: We couldn't connect to huggingface.co 的问题。
在终端输入:
bash
HF_ENDPOINT=https://hf-mirror.com vllm serve Qwen/Qwen3-ASR-1.7B \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--port 8000- 首次运行: 会自动下载约 3-4GB 模型权重,速度很快。
- 成功标志:
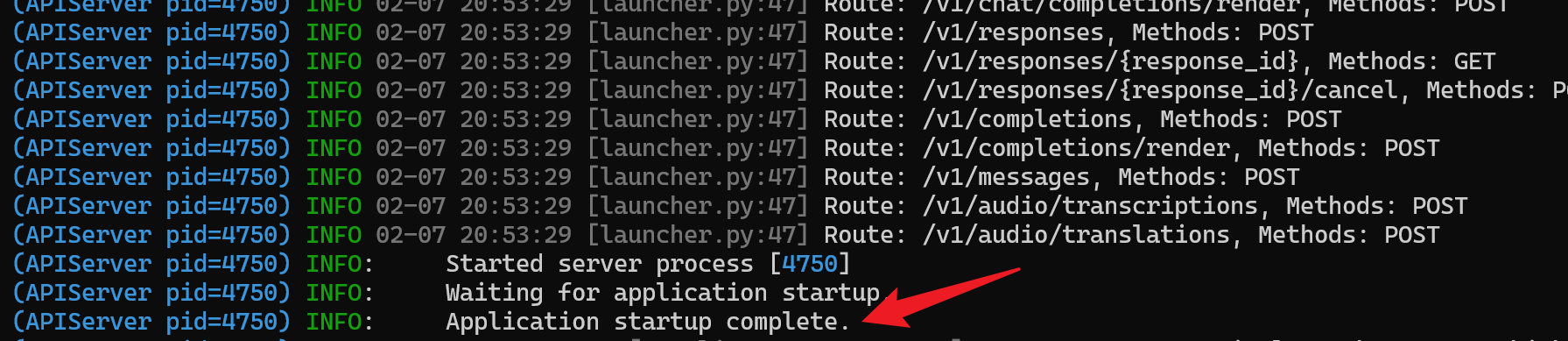
🧪 第四阶段:测试调用 (curl测试)
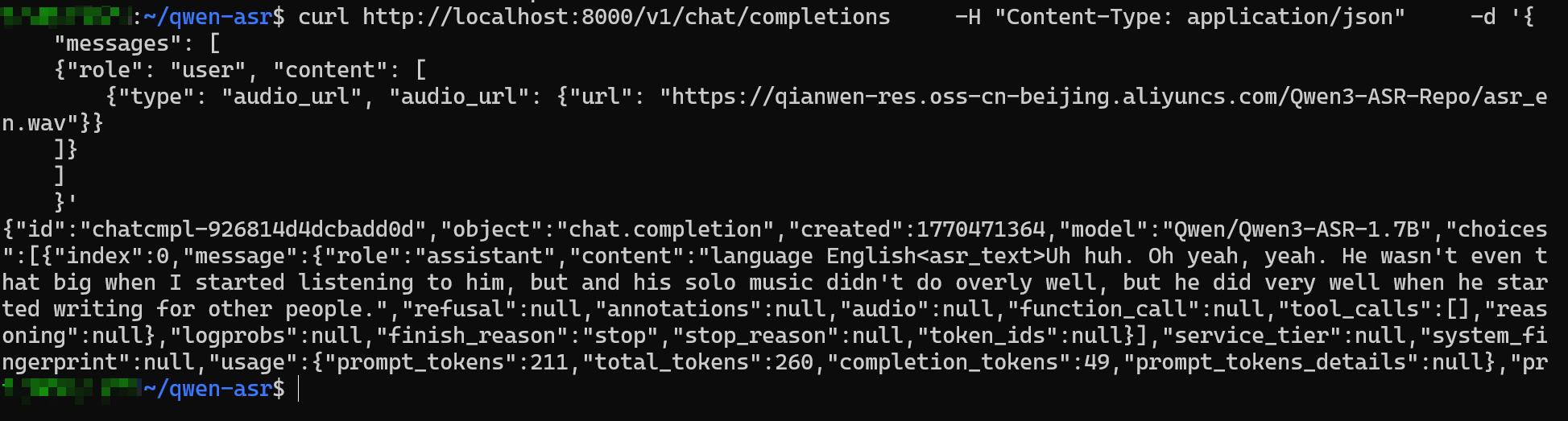
在wsl中测试
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": [
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav"}}
]}
]
}'
⚙️ 进阶:如何设置开机自启 (Systemd)
为了不用每次都开个黑框终端,我们可以把它做成后台服务。
- 编辑服务文件:
sudo nano /etc/systemd/system/qwen-asr.service - 写入以下内容 (注意修改
User为你的用户名,以及确认WorkingDirectory路径):
ini
[Unit]
Description=Qwen3 ASR Service
After=network.target
[Service]
User=你的用户名
WorkingDirectory=/home/你的用户名/qwen-asr
Environment="HF_ENDPOINT=https://hf-mirror.com"
Environment="PATH=/home/你的用户名/qwen-asr/.venv/bin:/usr/bin:/bin"
# 注意:下面的路径必须写绝对路径
ExecStart=/home/你的用户名/qwen-asr/.venv/bin/vllm serve Qwen/Qwen3-ASR-1.7B --gpu-memory-utilization 0.9 --trust-remote-code --port 8000
Restart=always
[Install]
WantedBy=multi-user.target- 启用服务:
bash
sudo systemctl daemon-reload
sudo systemctl enable --now qwen-asr现在,你的 Windows 电脑已经拥有了一个随时待命的高性能 AI 语音识别引擎!
🔧 进阶优化:如何限制显存占用 (给 LLM 腾地方)
默认情况下,vLLM 会暴力占用 90% 的显存,导致你无法同时运行其他模型(比如用于润色的 DeepSeek 或 Qwen-Chat)。
如果你尝试直接将显存限制调低(例如 --gpu-memory-utilization 0.5),可能会遇到如下报错导致启动失败:
ValueError: ... (7.0 GiB KV cache is needed ... available ... 2.69 GiB)
原因: Qwen3-ASR 默认支持超长音频(65536 context length),这需要巨大的显存来预留缓存。当我们限制了总显存,预留空间就不够了。
解决方法: 降低显存占用的同时,必须限制最大上下文长度。
1. 修改服务配置
我们需要同时修改 gpu-memory-utilization (显存比例) 和 max-model-len (最大长度)。
打开配置文件:
bash
sudo nano /etc/systemd/system/qwen-asr.service2. 更新启动参数
找到 ExecStart= 这一行,将其替换为以下内容(请确保它是完整的一行):
ini
ExecStart=/home/你的用户名/qwen-asr/.venv/bin/vllm serve Qwen/Qwen3-ASR-1.7B --gpu-memory-utilization 0.5 --max-model-len 8192 --trust-remote-code --port 8000参数详解:
--gpu-memory-utilization 0.5: 强制只使用 50% (约 8GB) 的显存。--max-model-len 8192: 将最大识别长度限制为 8192 token。- 注:8192 足够连续说话 10-15 分钟,完全满足输入法需求,且能大幅降低显存需求。
3. 重启生效
保存文件 (Ctrl+O -> Enter -> Ctrl+X) 后,执行重启:
bash
sudo systemctl daemon-reload
sudo systemctl restart qwen-asr4. 验证结果
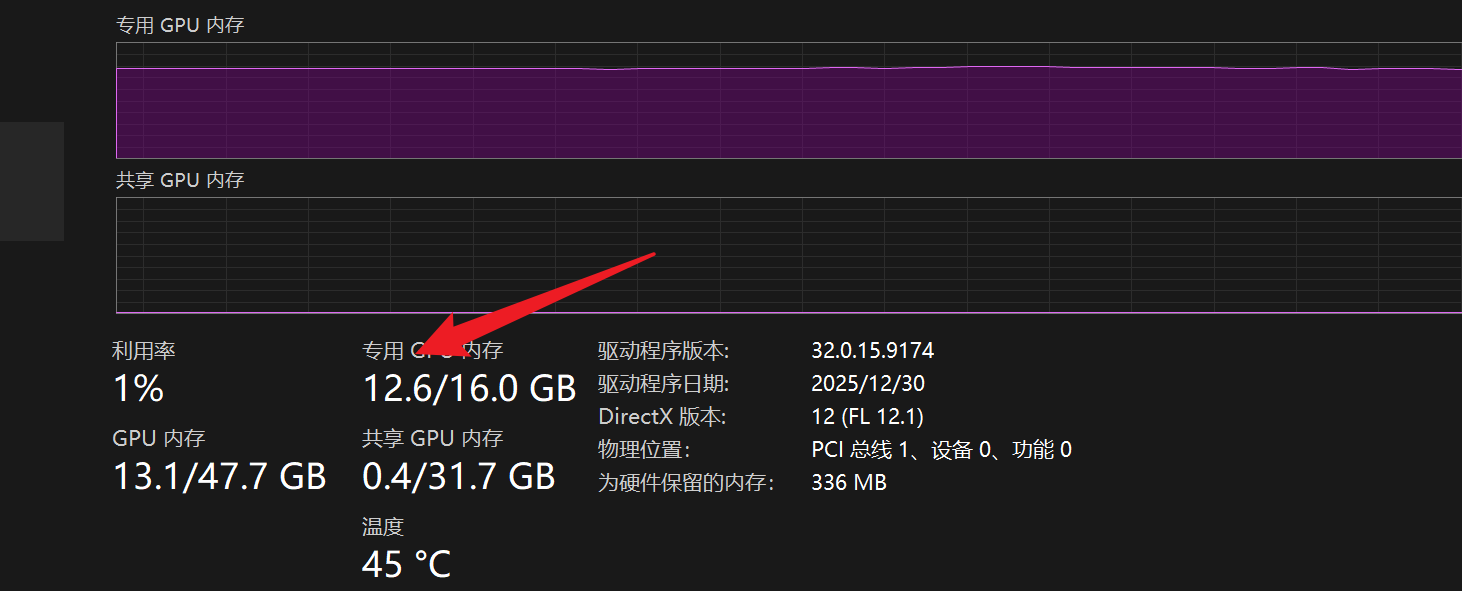
此时打开 Windows 任务管理器查看 GPU 显存,你会发现占用稳定在 7GB - 10GB 左右
《附录:日常维护与故障排查命令速查》
1. 服务状态与日志监控 (最常用)
当服务跑不起来,或者想看模型有没有在处理请求时,用这些:
- 查看服务运行状态 (活没活着):
bash
sudo systemctl status qwen-asr-
看点: 绿色的
active (running)表示正常;红色的failed表示挂了。 -
实时查看服务日志 (正在干啥):
bash
journalctl -u qwen-asr -f-
作用: 像看电影字幕一样,实时滚动显示最新的日志。按
Ctrl+C退出。 -
查看最近 50 行报错 (死因排查):
bash
journalctl -u qwen-asr -n 50 --no-pager- 作用: 服务启动失败时,用这个看最后几行红色的报错信息。
2. 显存与端口检查 (资源冲突)
当显存爆了或者端口被占用时:
- 实时监控显存占用 (Watch GPU):
bash
watch -n 1 nvidia-smi-
作用: 每秒刷新一次显卡状态,看显存是不是被 vLLM 吃掉了,还是被其他程序占了。
-
查看 8000 端口被谁占用了:
bash
sudo lsof -i :8000-
作用: 如果启动报错
Address already in use,用这个查出 PID。 -
强制杀掉占用端口的进程:
bash
# 把 <PID> 换成上面查到的数字
sudo kill -9 <PID>3. 环境与模型更新 (保持最新)
Qwen3-ASR 和 vLLM 都在快速迭代,有时需要更新:
- 更新 vLLM 到最新版:
(先确保服务已停止:sudo systemctl stop qwen-asr)
bash
source ~/qwen-asr/.venv/bin/activate
uv pip install -U vllm --pre \
--extra-index-url https://wheels.vllm.ai/nightly/cu121 \
--index-strategy unsafe-best-match- 进入/退出 虚拟环境 (手动调试必用):
bash
# 进入
source ~/qwen-asr/.venv/bin/activate
# 退出
deactivate4. 完整的"手动调试"标准流程
你列出的最后一行代码是手动启动,但我建议把它标准化一下,因为手动启动前必须先激活环境。
场景: Systemd 服务启动失败,我想在终端里直接运行看看报什么错。
bash
# 1. 先停止后台服务,防止端口冲突
sudo systemctl stop qwen-asr
# 2. 进入项目目录并激活环境
cd ~/qwen-asr
source .venv/bin/activate
# 3. 手动运行 (参数要和配置文件保持一致,方便复现问题)
HF_ENDPOINT=https://hf-mirror.com vllm serve Qwen/Qwen3-ASR-1.7B \
--gpu-memory-utilization 0.5 \
--max-model-len 8192 \
--trust-remote-code \
--port 80005. 极端的 WSL 重置
当 WSL2 彻底卡死(比如 nvidia-smi 都没反应了):
- 在 Windows PowerShell (管理员) 中执行:
powershell
# 强制关闭所有 WSL 实例
wsl --shutdown