YOLOv1 核心结构解析
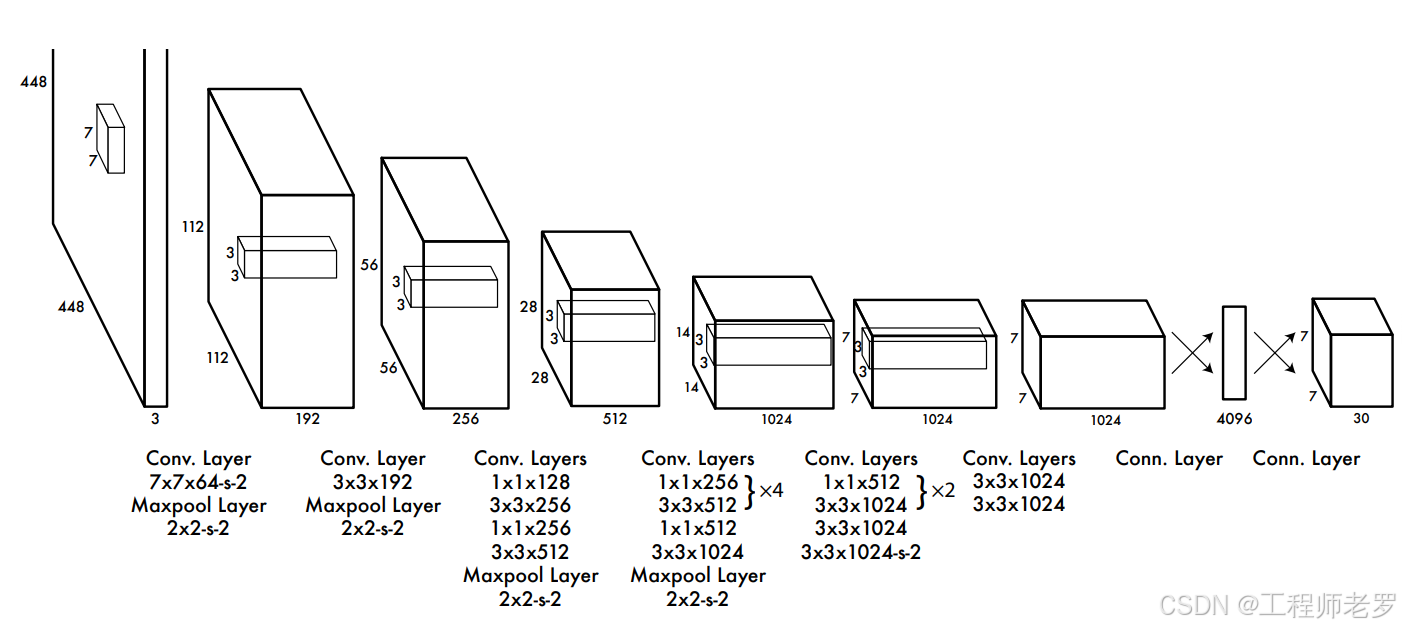
这张图展示了原始 YOLOv1 的完整网络结构,它是一个单阶段目标检测模型,将目标检测任务转化为一个单一的回归问题,直接从图像中预测边界框和类别概率。
1. 网络整体流程
YOLOv1 的网络可以分为三个主要部分:
- 卷积主干网络 :提取图像特征,将输入图像从
448×448×3压缩为7×7×1024的特征图。 - 全连接层 :将
7×7×1024的特征图展平为一维向量,通过全连接层进行最终预测。 - 输出层 :输出一个
7×7×30的张量,代表在 7×7 的网格上,每个网格预测 2 个边界框和对应的类别。
2. 逐层拆解(从左到右)
| 模块 | 操作 | 输入尺寸 | 输出尺寸 | 核心作用 |
|---|---|---|---|---|
| Conv1 | 7×7×64-s-2 + MaxPool(2×2-s-2) | 448×448×3 | 112×112×64 | 初步提取特征,大幅降采样 |
| Conv2 | 3×3×192 + MaxPool(2×2-s-2) | 112×112×64 | 56×56×192 | 加深网络,继续降采样 |
| Conv3 | 1×1×128 → 3×3×256 → 1×1×256 → 3×3×512 + MaxPool(2×2-s-2) | 56×56×192 | 28×28×512 | 交替使用1×1和3×3卷积,压缩并丰富特征 |
| Conv4 | (1×1×256 → 3×3×512)×4 + MaxPool(2×2-s-2) | 28×28×512 | 14×14×1024 | 重复4次"1×1+3×3"结构,提取深层特征 |
| Conv5 | (1×1×512 → 3×3×1024)×2 → 3×3×1024-s-2 | 14×14×1024 | 7×7×1024 | 重复2次"1×1+3×3"结构,最后一次卷积降采样到7×7 |
| Conv6 | 3×3×1024 ×2 | 7×7×1024 | 7×7×1024 | 进一步提取特征,保持尺寸不变 |
| FC | 全连接层 | 7×7×1024 | 4096 → 30 | 将特征图展平,回归出最终检测结果 |
3. 关键设计思想
- 单阶段检测:不像两阶段检测器(如Faster R-CNN)先生成候选区域,YOLOv1 直接在一个网络中完成所有预测,速度更快。
- 网格划分 :将输入图像划分为
7×7的网格。如果一个目标的中心落在某个网格内,该网格就负责检测这个目标。 - 统一输出 :最终输出
7×7×30的张量,其中:7×7:网格数量。30:每个网格预测 2 个边界框(每个框包含x, y, w, h, confidence共5个参数),以及 20 个类别概率,总计2×5 + 20 = 30维。
4. 与改进版 YOLOv1 的对比
| 特性 | 原始 YOLOv1 | 改进版 YOLOv1 |
|---|---|---|
| 主干网络 | 自定义24层卷积 | ResNet-18 |
| 颈部网络 | 无 | SPP/SPPF |
| 检测头 | 全连接层 | 双分支解耦卷积检测头 |
| 输出特征图 | 7×7×30 | 13×13×(1+Nc+4) |
| 优势 | 速度快,结构简单 | 精度更高,对小目标更友好 |