该内容涉及Tensor Core的前置知识,建议看完下列文章再来看本文:
cuda编程笔记(20)-- 混合精度计算_cublasltmatmulpreferencecreate-CSDN博客 里面wmma api的介绍
cuda编程笔记(9)--使用 Shared Memory 实现 tiled GEMM _cuda tile-CSDN博客
直接应用
Tensor Core最基础的单元是16*16*16的矩阵计算,于是我们把大矩阵拆成多个小的16*16*16的运算即可。
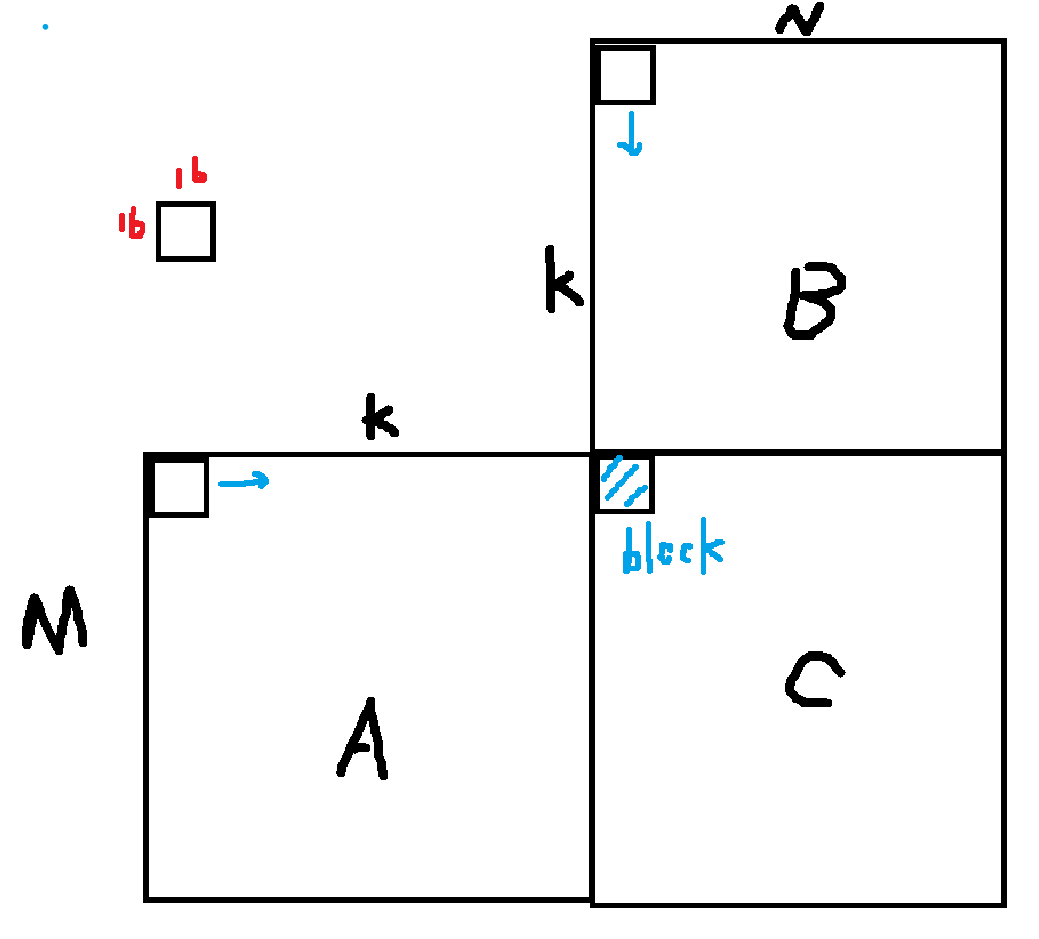
其中一个block就只有一个warp,负责C矩阵的蓝色区域。要计算C矩阵蓝色区域,需要A,B矩阵中的16*16小块在K方向上进行移动。
cpp
#include <cuda_runtime.h>
#include<cuda_fp16.h>
#include <iostream>
#include<mma.h>
#include <nvtx3/nvtx3.hpp>
using namespace nvcuda;
__device__ __host__ inline int div_ceil(int a, int b) {
return (a + b - 1) / b;
}
//一个block只有一个warp
template<const int WMMA_M=16,const int WMMA_N=16,const int WMMA_K=16>
__global__ void hgemm_wmma_m16n16k16_navie_kernel(
half *A,half *B,float *C,int M,int N,int K
){
//沿K方向移动的次数
const int NUM_K_TILES=div_ceil(K,WMMA_K);
const int bx=blockIdx.x;//bx是N方向的偏移
const int by=blockIdx.y;//by是M方向的偏移
const int load_gmem_a_m = by*WMMA_M;//A矩阵的行索引
const int load_gmem_b_n = bx*WMMA_N;//B矩阵的列索引
if(load_gmem_a_m>=M||load_gmem_b_n>=N)
return;
wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,float> C_frag;
wmma::fill_fragment(C_frag,0.0f);
//沿K方向移动
for(int k=0;k<NUM_K_TILES;k++){
wmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> A_frag;
wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> B_frag;
wmma::load_matrix_sync(A_frag,A+load_gmem_a_m*K+k*WMMA_K,WMMA_K);//load_gmem_a_m*K是前面的行*列,k*WMMA_K是本列的偏移
wmma::load_matrix_sync(B_frag,B+(k*WMMA_K)*N+load_gmem_b_n,WMMA_N);//(K*WMMA_K)*N是前面的行*列,load_gmem_b_n是本列的偏移
wmma::mma_sync(C_frag,A_frag,B_frag,C_frag);//C+=A*B
__syncthreads();
}
wmma::store_matrix_sync(C+load_gmem_a_m*N+load_gmem_b_n,C_frag,N,wmma::mem_row_major);
}
void hgemm_wmma_m16n16k16_navie(half *A,half *B,float *C,int M,int N,int K){
constexpr int WMMA_M=16;
constexpr int WMMA_N=16;
constexpr int WMMA_K=16;
dim3 block{16};
dim3 grid{div_ceil(N,WMMA_N),div_ceil(M,WMMA_M)};
hgemm_wmma_m16n16k16_navie_kernel<WMMA_M,WMMA_N,WMMA_K><<<grid,block>>>(
A,B,C,M,N,K
);
}
void launch_navie(){
const int M=512,N=2048,K=1024;
std::vector<half> h_A(M*K);
std::vector<half> h_B(K*N);
std::vector<float> h_C(M*N);
for(int i=0;i<M*K;i++) h_A[i]=__float2half(1.0f);
for(int i=0;i<K*N;i++) h_B[i]=__float2half(1.0f);
// device 内存
half *d_A, *d_B;
float *d_C;
cudaMalloc(&d_A, M*K*sizeof(half));
cudaMalloc(&d_B, K*N*sizeof(half));
cudaMalloc(&d_C, M*N*sizeof(float));
cudaMemcpy(d_A, h_A.data(), M*K*sizeof(half), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B.data(), K*N*sizeof(half), cudaMemcpyHostToDevice);
hgemm_wmma_m16n16k16_navie(d_A,d_B,d_C,M,N,K);
cudaMemcpy(h_C.data(), d_C, M*N*sizeof(float), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}利用shared memory
和普通矩阵乘法优化思路类似,直接从全局内存读取数据实在太慢,能否先搬到shared memory呢?答案是可以
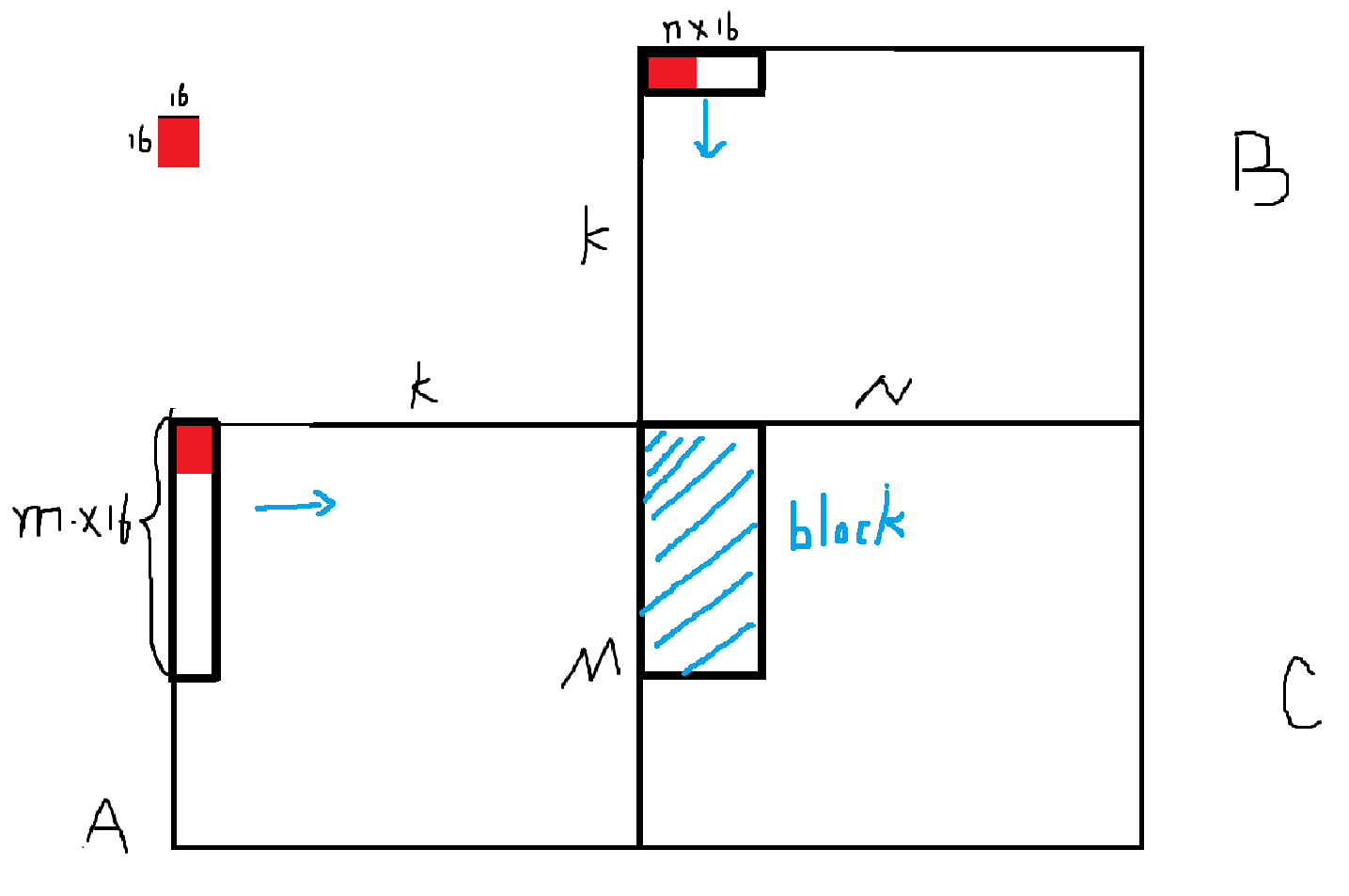
现在一个block有8个warp负责C矩阵蓝色区域。block内的共享内存暂存A,B矩阵里黑色框内的部分(由于黑色框会往K方向迭代,所以共享内存的数据也会对应更新)
这里选择A的M方向拓展,B的N方向拓展,两者的K方向依然wmma块为1.本例m为4,n为2,所以一个block启动8个warp。
cpp
#include <cuda_runtime.h>
#include<cuda_fp16.h>
#include <iostream>
#include<mma.h>
#include <nvtx3/nvtx3.hpp>
using namespace nvcuda;
__device__ __host__ inline half2* LDST32BITS(void *value){
return reinterpret_cast<half2*>(value);
}
//这里不要管数据形式,只用管字节量即可。2个float2即half4
__device__ __host__ inline float2* LDST64BITS(void *value){
return reinterpret_cast<float2*>(value);
}
template<const int WMMA_M=16,const int WMMA_N=16,const int WMMA_K=16,
//WMMA_TILE_M表示M方向wmma 块的个数,WMMA_TILE_N同理
const int WMMA_TILE_M=4,const int WMMA_TILE_N=2>
__global__ void hgemm_wmma_m16n16k16_mma4x2_kernel(
half *A,half *B,float *C,int M,int N,int K
){
//每个block有256线程(8个warp)
//bx是N方向的偏移,by是M方向的偏移
const int bx=blockIdx.x;
const int by=blockIdx.y;
const int NUM_K_TILES=div_ceil(K,WMMA_K);
//BM是一个block内,沿M维度的行数
//BN是一个block内,沿N维度的列数
//BK的一个block内,沿K维度的大小,本模式K方向只有一个wmma块,所以是16
constexpr int BM=WMMA_M*WMMA_TILE_M; //16*4=64 WMMA_TILE_M是4
constexpr int BN=WMMA_N*WMMA_TILE_N; //16*2=32 WMMA_TILE_N是2
constexpr int BK=WMMA_K; //16
//共享内存只在block内共享。s_a是A里BM*BM大小的矩阵,s_b是B里BK*BN的矩阵
__shared__ half s_a[BM][BK],s_b[BK][BN];//64*16*2=2KB,16*32*2=1KB
const int tid=threadIdx.x;//0-255 block内线程编号
const int warp_id=tid/warpSize; //0-7 block内warp编号
const int lane_id=tid%warpSize; //0-31 warp内线程编号
//通过warp_id分配warp对应的区域 warp_id->(warp_m,warp_n)[刚好对应M方向4个tile,N方向2个tile]
const int warp_m=warp_id/2; //0,1,2,3
const int warp_n=warp_id%2; //0,1
//256线程分别load s_a=64*16,s_b=16*32
//64*16/256=4 half4 每个线程load 4个half
//16*32/256=2 half2,每个线程load 2个half
//s_a(64行16列) 每个线程load 4half,每行需要4个线程,总共64行,对应总数256线程
const int load_smem_a_m=tid/4; // 0-63 M方向64行
const int load_smem_a_k=(tid%4)*4; //0,4,8,12 K方向开头是4的倍数
const int load_smem_b_k=tid/16; //0-15 K方向16行
const int load_smem_b_n=(tid%16)*2; //0,2,4... N方向开头是2的倍数
const int load_gmem_a_m=by*BM+load_smem_a_m; //计算本线程对应的A矩阵的行索引
const int load_gmem_b_n=bx*BN+load_smem_b_n; //计算本线程对应的B矩阵的列索引
if(load_gmem_a_m>=M||load_gmem_b_n>=N)
return;
wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,float> C_frag;
wmma::fill_fragment(C_frag,0.0);
wmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> A_frag;
wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> B_frag;
//沿着K方向移动,每个wmma对应的A_frag和B_frag都会移动
for(int k=0;k<NUM_K_TILES;k++){
int load_gmem_a_k=k*WMMA_K+load_smem_a_k;//计算本线程对应A矩阵的列索引
int load_gmem_a_addr=load_gmem_a_m*K+load_gmem_a_k;//计算本线程读取A矩阵的起始位置
int load_gmem_b_k=k*WMMA_K+load_smem_b_k;//计算本线程对应B矩阵的行索引
int load_gmem_b_addr=load_gmem_b_k*N+load_gmem_b_n;//计算本线程读取B矩阵的起始位置
//每次从A矩阵加载4个half到共享内存
*LDST64BITS(&s_a[load_smem_a_m][load_smem_a_k])=*LDST64BITS(&A[load_gmem_a_addr]);
//每次从B矩阵加载2个half到共享内存
*LDST32BITS(&s_b[load_smem_b_k][load_smem_b_n])=*LDST32BITS(&B[load_gmem_b_addr]);
//block内同步
__syncthreads();
wmma::load_matrix_sync(A_frag,&s_a[warp_m*WMMA_M][0],BK);
wmma::load_matrix_sync(B_frag,&s_b[0][warp_n*WMMA_N],BN);
//C+=A*B
wmma::mma_sync(C_frag,A_frag,B_frag,C_frag);
__syncthreads();
}
//by*BM和bx*BN是本block负责的C区域的左上角
const int store_gmem_a_m=by*BM+warp_m*WMMA_M;//本block内本warp负责的wmma的行索引开头
const int store_gmem_a_n=bx*BN+warp_n*WMMA_N;//本block内本warp负责的wmma的列索引开头
wmma::store_matrix_sync(C+store_gmem_a_m*N+store_gmem_a_n,C_frag,N,wmma::mem_row_major);
}
void hgemm_wmma_m16n16k16_mma4x2(half *A,half *B,float *C,int M,int N,int K){
constexpr int WMMA_M=16;
constexpr int WMMA_N=16;
constexpr int WMMA_K=16;
constexpr int WMMA_TILE_M=4;
constexpr int WMMA_TILE_N=2;
dim3 block{256};
dim3 grid(div_ceil(N,WMMA_N*WMMA_TILE_N),div_ceil(M,WMMA_M*WMMA_TILE_M));
hgemm_wmma_m16n16k16_mma4x2_kernel<WMMA_M,WMMA_N,WMMA_K,WMMA_TILE_M,WMMA_TILE_N><<<grid,block>>>(
A,B,C,M,N,K
);
}
void launch_mma4x2(){
const int M=512,N=2048,K=1024;
std::vector<half> h_A(M*K);
std::vector<half> h_B(K*N);
std::vector<float> h_C(M*N);
for(int i=0;i<M*K;i++) h_A[i]=__float2half(1.0f);
for(int i=0;i<K*N;i++) h_B[i]=__float2half(1.0f);
// device 内存
half *d_A, *d_B;
float *d_C;
cudaMalloc(&d_A, M*K*sizeof(half));
cudaMalloc(&d_B, K*N*sizeof(half));
cudaMalloc(&d_C, M*N*sizeof(float));
cudaMemcpy(d_A, h_A.data(), M*K*sizeof(half), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B.data(), K*N*sizeof(half), cudaMemcpyHostToDevice);
hgemm_wmma_m16n16k16_mma4x2(d_A,d_B,d_C,M,N,K);
cudaMemcpy(h_C.data(), d_C, M*N*sizeof(float), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}LDST64BITS和LDST32BITS是向量化读取,详见cuda编程笔记(24)-- Global Memory之间的拷贝_gpu cudamemcpy 到全局内存是复制到共享内存快,还是直接复制到共享内存快-CSDN博客
双缓冲+异步写
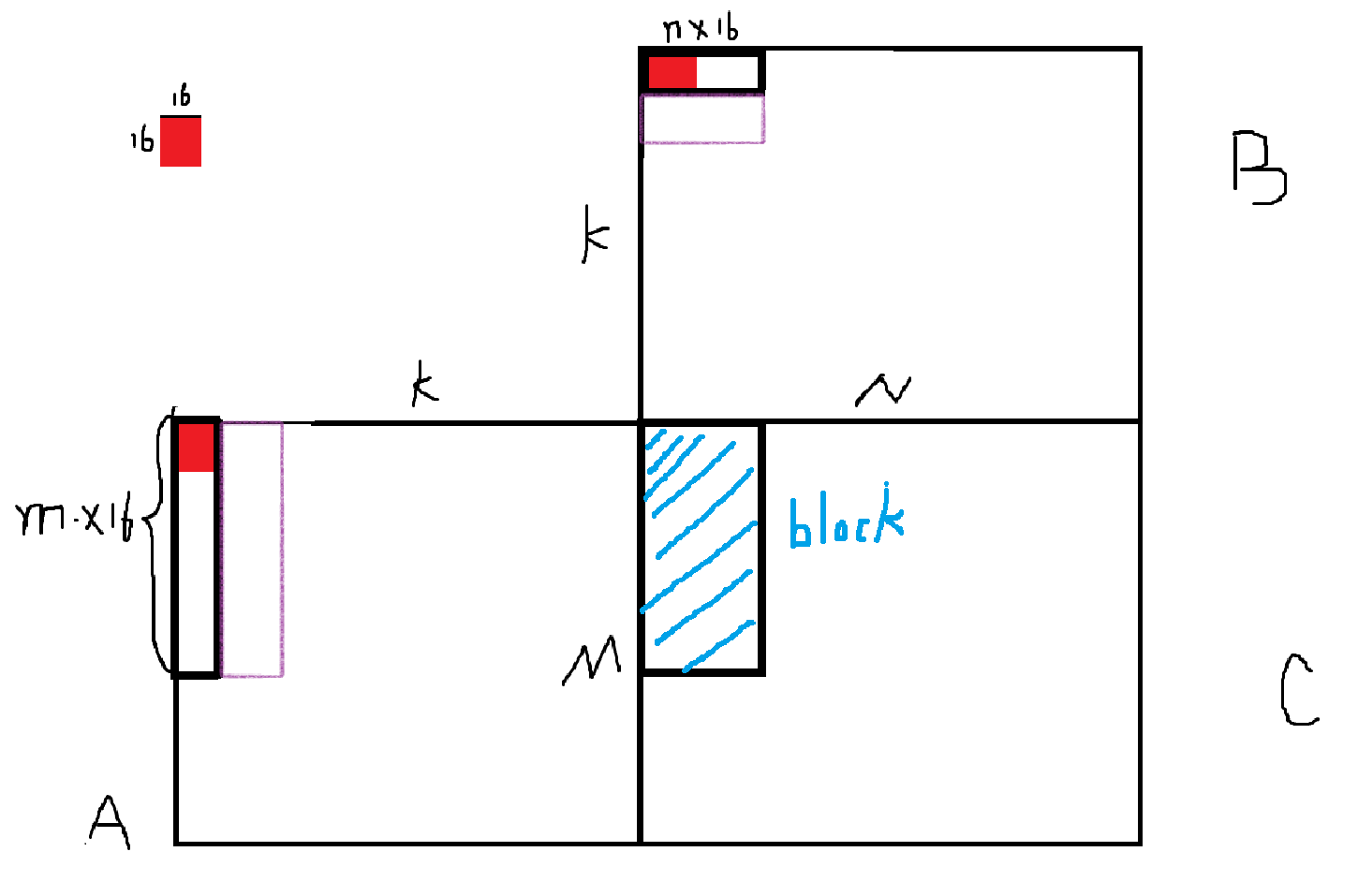
在上一个例子中,数据必须先从全局内存读到共享内存,然后才能执行计算。那能否读和算重叠呢?答案是可以。我们可以开双倍共享内存,在紫色区域异步读,黑色区域计算,这样能达到重叠的效果。
cpp
#include <cuda_runtime.h>
#include<cuda_fp16.h>
#include <iostream>
#include<mma.h>
#include <nvtx3/nvtx3.hpp>
using namespace nvcuda;
__device__ __host__ inline int div_ceil(int a, int b) {
return (a + b - 1) / b;
}
#define CP_ASYNC_CG(dst,src,Bytes)\
asm volatile("cp.async.cg.shared.global[%0],[%1],%2;\n"::"r"(dst),"l"(src),"n"(Bytes))
#define CP_ASYNC_COMMIT_GROUP() asm volatile("cp.async.commit_group;\n"::)
#define CP_ASYNC_WAIT_GROUP(N) asm volatile("cp.async.wait_group %0;\n"::"n"(N))
template<
const int WMMA_M=16,const int WMMA_N=16,const int WMMA_K=16,
const int WMMA_TILE_M=4,const int WMMA_TILE_N=2>
__global__ void hgemm_wmma_m16n16k16_mma4x2_doublebuffer_async_kernel(
half *A,half *B,float *C,int M,int N,int K
){
const int bx=blockIdx.x;
const int by=blockIdx.y;
const int NUM_K_TILES=div_ceil(K,WMMA_K);
constexpr int BM=WMMA_M*WMMA_TILE_M; //64
constexpr int BN=WMMA_N*WMMA_TILE_N; //32
constexpr int BK=WMMA_K; //16
// ---------- 双缓冲 ----------
__shared__ half s_a[2][BM][BK];
__shared__ half s_b[2][BK][BN];
const int tid=threadIdx.x;
const int warp_id=tid/warpSize;
const int lane_id=tid%warpSize;
const int warp_m=warp_id/2;
const int warp_n=warp_id%2;
const int load_smem_a_m=tid/4;
const int load_smem_a_k=(tid%4)*4;
const int load_smem_b_k=tid/16;
const int load_smem_b_n=(tid%16)*2;
const int load_gmem_a_m=by*BM+load_smem_a_m;
const int load_gmem_b_n=bx*BN+load_smem_b_n;
if(load_gmem_a_m>=M||load_gmem_b_n>=N)
return;
wmma::fragment<wmma::accumulator,WMMA_M,WMMA_N,WMMA_K,float> C_frag;
wmma::fill_fragment(C_frag,0.0f);
wmma::fragment<wmma::matrix_a,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> A_frag;
wmma::fragment<wmma::matrix_b,WMMA_M,WMMA_N,WMMA_K,half,wmma::row_major> B_frag;
int smem_stage=0;
// ======================
// 需要提前在缓冲区加载
// ======================
{
int k=0;
int load_gmem_a_k=k*WMMA_K+load_smem_a_k;
int load_gmem_a_addr=load_gmem_a_m*K+load_gmem_a_k;
int load_gmem_b_k=k*WMMA_K+load_smem_b_k;
int load_gmem_b_addr=load_gmem_b_k*N+load_gmem_b_n;
uint32_t load_smem_a_ptr=__cvta_generic_to_shared(
&s_a[smem_stage][load_smem_a_m][load_smem_a_k]);
CP_ASYNC_CG(load_smem_a_ptr,&A[load_gmem_a_addr],16);
uint32_t load_smem_b_ptr=__cvta_generic_to_shared(
&s_b[smem_stage][load_smem_b_k][load_smem_b_n]);
CP_ASYNC_CG(load_smem_b_ptr,&B[load_gmem_b_addr],16);
CP_ASYNC_COMMIT_GROUP();
CP_ASYNC_WAIT_GROUP(0);
}
__syncthreads();
// ======================
// main pipeline loop
// ======================
for(int k=0;k<NUM_K_TILES;k++){
int next_stage=smem_stage^1;//异或操作,拿到不在计算的共享内存
// 提前加载下一块共享内存
if(k+1<NUM_K_TILES){
int load_gmem_a_k=(k+1)*WMMA_K+load_smem_a_k;
int load_gmem_a_addr=load_gmem_a_m*K+load_gmem_a_k;
int load_gmem_b_k=(k+1)*WMMA_K+load_smem_b_k;
int load_gmem_b_addr=load_gmem_b_k*N+load_gmem_b_n;
uint32_t load_smem_a_ptr=__cvta_generic_to_shared(
&s_a[next_stage][load_smem_a_m][load_smem_a_k]);
CP_ASYNC_CG(load_smem_a_ptr,&A[load_gmem_a_addr],16);
uint32_t load_smem_b_ptr=__cvta_generic_to_shared(
&s_b[next_stage][load_smem_b_k][load_smem_b_n]);
CP_ASYNC_CG(load_smem_b_ptr,&B[load_gmem_b_addr],16);
CP_ASYNC_COMMIT_GROUP();
}
// 计算
wmma::load_matrix_sync(
A_frag,
&s_a[smem_stage][warp_m*WMMA_M][0],
BK
);
wmma::load_matrix_sync(
B_frag,
&s_b[smem_stage][0][warp_n*WMMA_N],
BN
);
wmma::mma_sync(C_frag,A_frag,B_frag,C_frag);
CP_ASYNC_WAIT_GROUP(0);
__syncthreads();
smem_stage=next_stage;
}
const int store_gmem_a_m=by*BM+warp_m*WMMA_M;
const int store_gmem_a_n=bx*BN+warp_n*WMMA_N;
wmma::store_matrix_sync(
C+store_gmem_a_m*N+store_gmem_a_n,
C_frag,
N,
wmma::mem_row_major
);
}
void hgemm_wmma_m16n16k16_mma4x2_doublebuffer_async(half *A,half *B,float *C,int M,int N,int K){
constexpr int WMMA_M=16;
constexpr int WMMA_N=16;
constexpr int WMMA_K=16;
constexpr int WMMA_TILE_M=4;
constexpr int WMMA_TILE_N=2;
dim3 block{256};
dim3 grid(div_ceil(N,WMMA_N*WMMA_TILE_N),div_ceil(M,WMMA_M*WMMA_TILE_M));
hgemm_wmma_m16n16k16_mma4x2_doublebuffer_async_kernel<WMMA_M,WMMA_N,WMMA_K,WMMA_TILE_M,WMMA_TILE_N><<<grid,block>>>(
A,B,C,M,N,K
);
}
void launch_doublebuffer_async(){
const int M=512,N=2048,K=1024;
std::vector<half> h_A(M*K);
std::vector<half> h_B(K*N);
std::vector<float> h_C(M*N);
for(int i=0;i<M*K;i++) h_A[i]=__float2half(1.0f);
for(int i=0;i<K*N;i++) h_B[i]=__float2half(1.0f);
// device 内存
half *d_A, *d_B;
float *d_C;
cudaMalloc(&d_A, M*K*sizeof(half));
cudaMalloc(&d_B, K*N*sizeof(half));
cudaMalloc(&d_C, M*N*sizeof(float));
cudaMemcpy(d_A, h_A.data(), M*K*sizeof(half), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B.data(), K*N*sizeof(half), cudaMemcpyHostToDevice);
hgemm_wmma_m16n16k16_mma4x2_doublebuffer_async(d_A,d_B,d_C,M,N,K);
cudaMemcpy(h_C.data(), d_C, M*N*sizeof(float), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}__cvta_generic_to_shared
cpp
size_t __cvta_generic_to_shared(const void *ptr);把"通用指针(generic pointer)"转换为"shared memory 地址"。
返回的是:shared memory address (32-bit)
注意不是普通指针,而是:shared memory address space offset
CUDA设备端存在不同地址空间:
cpp
global
shared
local
constant
generic(统一指针)而 PTX 指令(例如 cp.async)要求:.shared 地址
所以必须使用这个函数进行转化
ptx指令:cp.async
在 Ampere 之后,global→shared copy 可以:
不经过寄存器
不阻塞warp
可以pipeline
这就是 cp.async 的本质。
所以一个warp可以
cpp
发起copy
继续计算
稍后等待copy完成CP_ASYNC_CG
cpp
#define CP_ASYNC_CG(dst,src,Bytes) \
asm volatile("cp.async.cg.shared.global[%0],[%1],%2;\n"::"r"(dst),"l"(src),"n"(Bytes))对应 PTX:
cpp
cp.async.cg.shared.global [dst], [src], Bytes;从:global memory 拷贝到:shared memory
dst必须是:shared memory address;所以得通过__cvta_generic_to_shared()函数转化
src必须是:全局内存指针
Bytes在 SM80 上只能是:16
CP_ASYNC_COMMIT_GROUP
cpp
#define CP_ASYNC_COMMIT_GROUP() \
asm volatile("cp.async.commit_group;\n"::)PTX:
cpp
cp.async.commit_group;告诉硬件:
这一批 async copy 发射完了
一个 warp 可以发很多 cp.async,然后一次 commit。
CP_ASYNC_WAIT_GROUP
cpp
#define CP_ASYNC_WAIT_GROUP(N) \
asm volatile("cp.async.wait_group %0;\n"::"n"(N))PTX:
cpp
cp.async.wait_group N;等待 async copy 完成。
但不是全部,而是:等待 <= N 个未完成group
但是一般会等待全部都完成,所以N就直接写0
简单测试
用nvtx做一个简单测试,如果要测核函数时间,还是建议用cudaEvent。
nvtx使用见:cuda编程笔记(27)-- NVTX的使用-CSDN博客
cpp
{
nvtx3::scoped_range r{"navie wmma"};
launch_navie();
}
{
nvtx3::scoped_range r{"shared memory wmma"};
launch_mma4x2();
}
{
nvtx3::scoped_range r{"double buffer + async wmma"};
launch_doublebuffer_async();
}
cpp
Time (%),Total Time (ns),Instances,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Style,Range
78.5,843566071,1,843566071.0,843566071.0,843566071,843566071,0.0,PushPop,navie wmma
12.5,134134642,1,134134642.0,134134642.0,134134642,134134642,0.0,PushPop,double buffer + async wmma
9.1,97389179,1,97389179.0,97389179.0,97389179,97389179,0.0,PushPop,shared memory wmma可以看到第二种shared memory是最快的,第一种是最慢的