一、MQ架构设计原理
1、什么是消息中间件
消息中间件基于队列模型实现异步/同步传输数据
作用:可以实现支撑高并发、异步解耦、流量削峰、降低耦合度。
2、传统的http请求存在那些缺点
1.Http请求基于请求与响应的模型,在高并发的情况下,客户端发送大量的请求达到服务器端有可能会导致我们服务器端处理请求堆积。
2.Tomcat服务器处理每个请求都有自己独立的线程,如果超过最大线程数会将该请求缓存到队列中,如果请求堆积过多的情况下,有可能会导致tomcat服务器崩溃的问题。
所以一般都会在nginx入口实现限流熔断 网关整合Sentinal,整合服务保护框架。
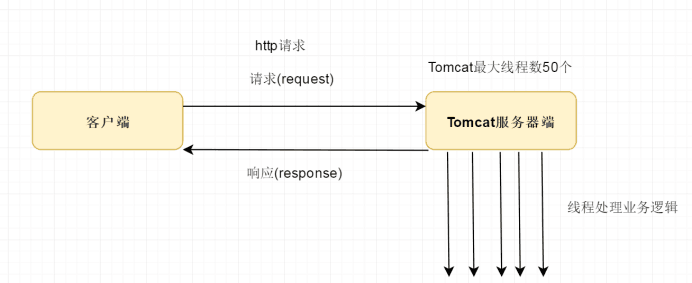
3.http请求处理业务逻辑如果比较耗时的情况下,容易造成客户端一直等待,阻塞等待
过程中会导致客户端超时发生重试策略,有可能会引发幂等性问题

注意事项:接口是为http 协议的情况下,最好不要处理比较耗时的业务逻辑,耗时的业务逻辑应该单独交给多线程或者是mq处理。
3、Mq应用场景有那些
- 异步发送短信
- 异步发送新人优惠券
- 处理一些比较耗时的操作
4、为什么需要使用mq
可以实现支撑高并发 、异步解耦 、流量削峰 、降低耦合度。
4.1同步发送http请求
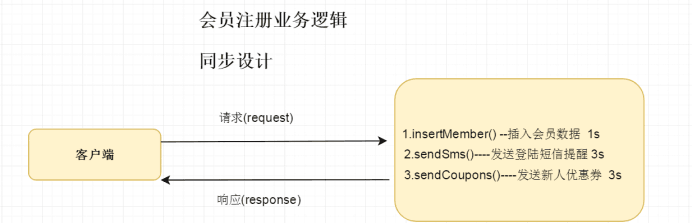
客户端发送请求到达服务器端,服务器端实现会员注册业务逻辑
1.insertMember() --插入会员数据 1s
2.sendSms()----发送登陆短信提醒 3s
3.sendCoupons()----发送新人优惠券 3s
总共响应需要7s时间,可能会导致客户端阻塞7s时间,对用户体验不是很好。
多线程与MQ方式实现异步
互联网项目:
客户端 安卓/IOS
服务器端:php/java
最好使用mq实现异步
4.2多线程处理业务逻辑
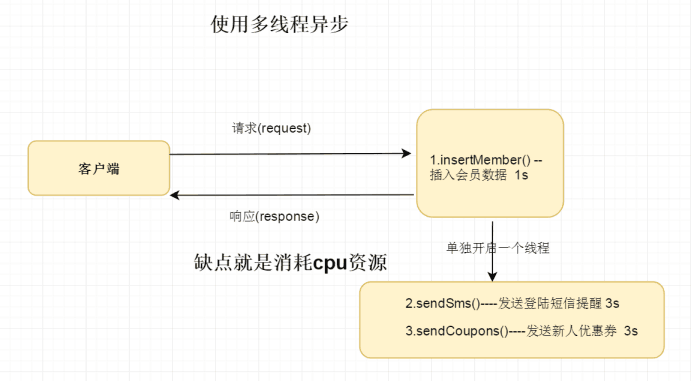
用户向数据库中插入一条数据之后,在单独开启一个线程异步发送短信和优惠操作。
客户端只需要等待1s时间
**优点:**适合于小项目 实现异步
**缺点:**有可能会消耗服务器cpu资源资源
4.3Mq处理业务逻辑
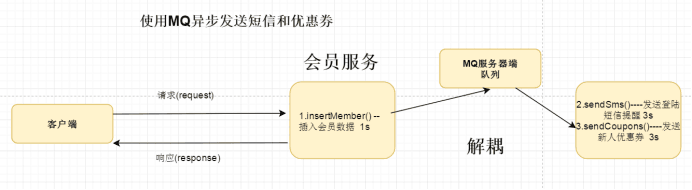
先向数据库中插入一条会员数据,然后再向MQ中投递一个消息,MQ服务器端在将消息推送给消费者异步解耦处理发送短信和优惠券。
5、Mq与多线程之间区别
MQ可以实现异步/解耦/流量削峰问题;
多线程也可以实现异步 ,但是消耗到cpu资源,没有实现解耦。
6、Mq设计基础知识
多线程版本mq;
基于网络通讯版本mq netty实现
6.1基于多线程队列简单实现mq
java
package como.qcby.thread_mq;
import com.alibaba.fastjson2.JSONObject;
import java.util.concurrent.LinkedBlockingDeque;
public class BoyatopThreadMQ {
/**
* Broker
*/
private static LinkedBlockingDeque<JSONObject> broker = new LinkedBlockingDeque<JSONObject>();
public static void main(String[] args) {
// 创建生产者线程
Thread producer = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000);
JSONObject data = new JSONObject();
data.put("phone", "18611111111");
broker.offer(data);
} catch (Exception e) {
}
}
}
}, "生产者");
producer.start();
Thread consumer = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
JSONObject data = broker.poll();
if (data != null) {
System.out.println(Thread.currentThread().getName() + ",获取到数据:" + data.toJSONString());
}
} catch (Exception e) {
}
}
}
}, "消费者");
consumer.start();
}
}6.2基于netty实现mq
消费者netty客户端与nettyServer端MQ服务器端保持长连接,MQ服务器端保存消费者连接。
生产者netty客户端发送请求给nettyServer端MQ服务器端,MQ服务器端在将该消息内容发送给消费者。
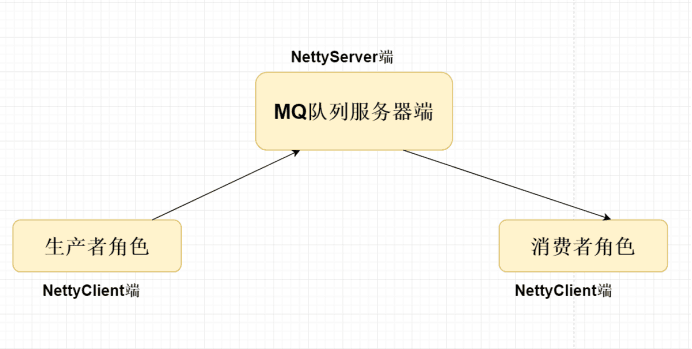
生产者投递消息给MQ服务器端,MQ服务器端需要缓存该消息
如果mq服务器端宕机之后,消息如何保证不丢失?
- 持久化机制
如果mq接收到生产者投递消息,如果消费者不在的情况下,该消息是否会丢失?
不会丢失,消息确认机制必须要消费者消费该消息成功之后,在通知给mq服务器端删除该消息。
Mq服务器端将该消息推送消费者:
消费者已经和mq服务器保持长连接。
消费者主动拉取消息:消费者第一次刚启动的时候
Mq如何实现抗高并发思想?
Mq消费者根据自身能力情况 ,拉取mq服务器端消息消费。
默认的情况下是取出一条消息。
**缺点:**存在延迟的问题
需要考虑mq消费者提高速率的问题:
如何消费者提高速率:消费者实现集群、消费者批量获取消息即可。
7、Mq消息中间件名词
Producer 生产者:投递消息到MQ服务器端;
Consumer 消费者:从MQ服务器端获取消息处理业务逻辑;
Broker: MQ服务器端
Topic 主题:分类业务逻辑发送短信主题、发送优惠券主题
Queue 存放消息模型 队列 先进先出 后进后出原则 数组/链表
Message 生产者投递消息报文:json
8、主流mq区别对比
|-------|---------------------------------|---------------------------------------|---------------|------------------------------------------------------|
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | kafka |
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低管理界面较丰富 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |
二、RabbitMQ介绍
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件),RabbitMQ服务器是用Erlang语言编写的
1.点对点(简单)的队列
2.工作(公平性)队列模式
3.发布订阅模式
4.路由模式Routing
5.通配符模式Topics
6.RPC
1、RabbitMQ环境的基本安装
安装erlang环境,配置环境变量,安装rabbitMQ
启动rabbitMQ
1.1、Rabbitmq管理平台中心
RabbitMQ 管理平台地址 http://127.0.0.1:15672
默认账号:guest/guest 用户可以自己创建新的账号
Virtual Hosts:
像mysql有数据库的概念并且可以指定用户对库和表等操作的权限。
RabbitMQ也有类似的权限管理。在RabbitMQ中可以虚拟消息服务器VirtualHost,每个VirtualHost相当于一个相对独立的RabbitMQ服务器,每个VirtualHost之间是相互隔离的。exchange、queue、message不能互通。
默认的端口15672:rabbitmq管理平台端口
默认的端口5672: rabbitmq消息中间内部通讯的端口
默认的端口号25672 rabbitmq集群的端口号
1.2、RabbitMQ常见名词
Virtual Hosts---分类
队列 存放我们消息
Exchange 分派我们消息在那个队列存放起来 类似于nginx
15672---rabbitmq控制台管理平台 http协议
25672rabbitmq 集群通信端口号
AMQP 5672 rabbitmq内部通信的一个端口号
1.3、RabbitMQ如何保证消息不丢失
Mq如何保证消息不丢失:
1、生产者角色
确保生产者投递消息到MQ服务器端成功。
Ack 消息确认机制
同步或者异步的形式
方式1:Confirms
方式2:事务消息
2、消费者角色
在rabbitmq情况下:
必须要将消息消费成功之后,才会将该消息从mq服务器端中移除。
在kafka中的情况下:
不管是消费成功还是消费失败,该消息都不会立即从mq服务器端移除。
3、Mq服务器端在默认的情况下都会对队列中的消息实现持久化:持久化硬盘。
真正的"持久化"是指 RabbitMQ 服务重启后,消息依然存在。
1.3.1消息持久化
要保证 RabbitMQ 重启后消息不丢失,必须同时满足以下三点:
1. 交换机持久化
如果交换机不持久化,RabbitMQ 重启后交换机会消失,消息也无法路由。
代码设置: 在声明交换机时将 durable 参数设为 true。
2. 队列持久化
作用: 保证 RabbitMQ 重启后,队列元数据依然存在。
注意: 仅将队列设为持久化,不能保证队列里的消息不丢失(消息可能会丢,只是队列空壳还在)。
3. 消息持久化
即使队列是持久的,发送的消息默认可能是内存驻留的。
作用: 指示 RabbitMQ 将消息写入磁盘。
代码设置:
01.在 channel.basicPublish 时,设置 BasicProperties 中的 deliveryMode
1: 非持久化 (Non-persistent)
2: 持久化 (Persistent)
java
// 示例:发送持久化消息
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 关键:2代表持久化
.build();
channel.basicPublish("", QUEUE_NAME, props, msg.getBytes());1.3.2消息投递的可靠性
需要保证消息确实从生产者到了 Broker ,以及从 Broker 到了消费者。
1. 生产者端:确保消息"发送成功"
为了防止消息在网络传输中丢失,或者 RabbitMQ 在写入磁盘前宕机,生产者需要知道消息是否被接收。
方案 A:事务机制 (Transaction) ------ 你提到的第 2 点
-
特点: 也就是你写的
txSelect->publish->txCommit。 -
缺点: 性能极差,会严重阻塞吞吐量,生产环境通常不建议使用。
-
场景: 仅用于对性能无要求但对数据绝对一致性要求极高的场景。
方案 B:发布确认机制 (Publisher Confirms) ------ 你提到的第 1.B 点
-
特点: 轻量级,性能高。RabbitMQ 收到消息并(如果是持久化消息)写入磁盘后,会异步通知生产者。
-
模式:
-
普通确认: 发一条确认一条。
-
批量确认: 发一批确认一次。
-
异步确认: 提供回调接口,这是性能最好的方式。
-
2. 消费者端:确保消息"处理成功"
为了防止消费者刚收到消息还没处理就挂了,导致消息丢失。
手动应答
-
关闭自动应答:
channel.basicConsume(QUEUE_NAME, false, ...)。这里的false即代表关闭autoAck。 -
业务处理完成后确认:
channel.basicAck(deliveryTag, false)。- 如果不 Ack,RabbitMQ 会认为该消费者忙或已掉线,会将消息重新投递给其他消费者。
-
补充: "true表示为自动应答模式"。
-
在
basicConsume方法中:参数autoAck = true代表自动应答(RabbitMQ 发送给消费者后立即删除消息,不安全)。 -
在
basicAck方法中:参数multiple = true代表批量确认(确认当前 tag 及其之前的所有消息)。
-