上两节课我们学习了关于Function Calling和【思维范式】的各种理论知识和思路。
今天我们直接开始实战。
目标:做一个可以自动归类文件的AI助手。
先看看使用效果!
执行后: 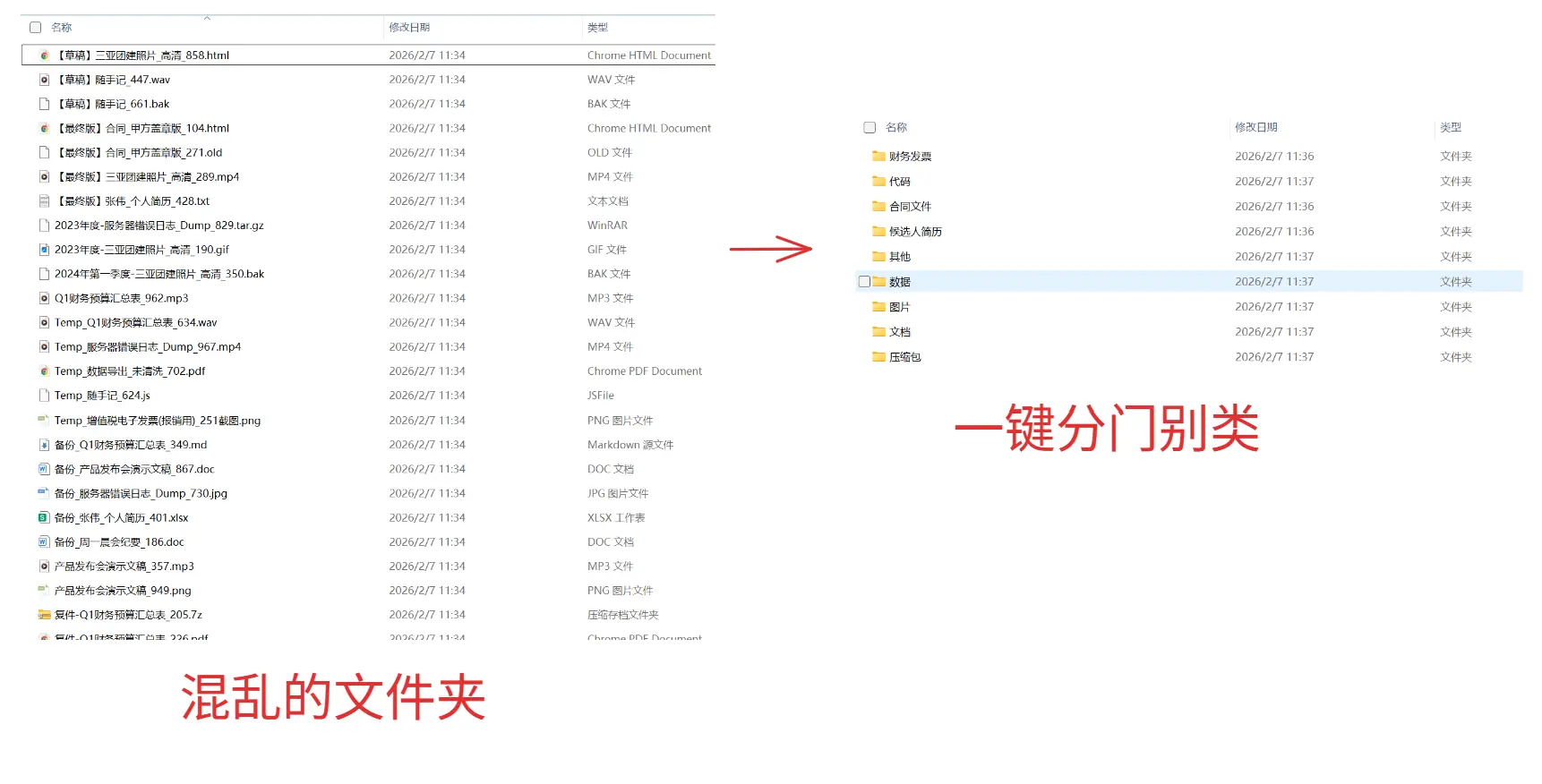
要做到这一点,至少得满足两个条件:
- AI能准确知道本地文件夹有哪些文件。
- AI能精准操控(移动)本地的文件。
而这,无疑就是 Function Calling 最核心的价值所在。
而调用这些 Function,则属于【思维范式】的领域。
01. 制造混乱
为了让大家的实践更有参与感,但是又不影响日常的工作,我写了一个脚本,可以一键产生一个混乱无比的文件夹。
执行脚本就能生成如下这样一个混乱的文件夹。
当然,这些文件都没有内容,只是为了模拟更为真实的职场环境。
一键生成模拟文件的脚本在demo工程里,自取:github.com/zhangshichu...
执行如下脚本即可:
python .\lesson_06\generate_files.py这个脚本和本节课关系不大,不展开了。
02. 梳理思路
上节课我们提到了 ReAct 思维范式,意思是,让AI按以下范式行动:
- 思考 -> 行动 -> 检查 -> 思考 -> 行动 -> ....
但幸运的是,目前的主流LLM模型底层都内置了这种范式,我们甚至可以在大多数时候省略使用提示词来要求这种范式,它们默认就是 ReAct 的。
接下来,我们首先要梳理清楚,我们解决这个问题需要分成几个步骤。
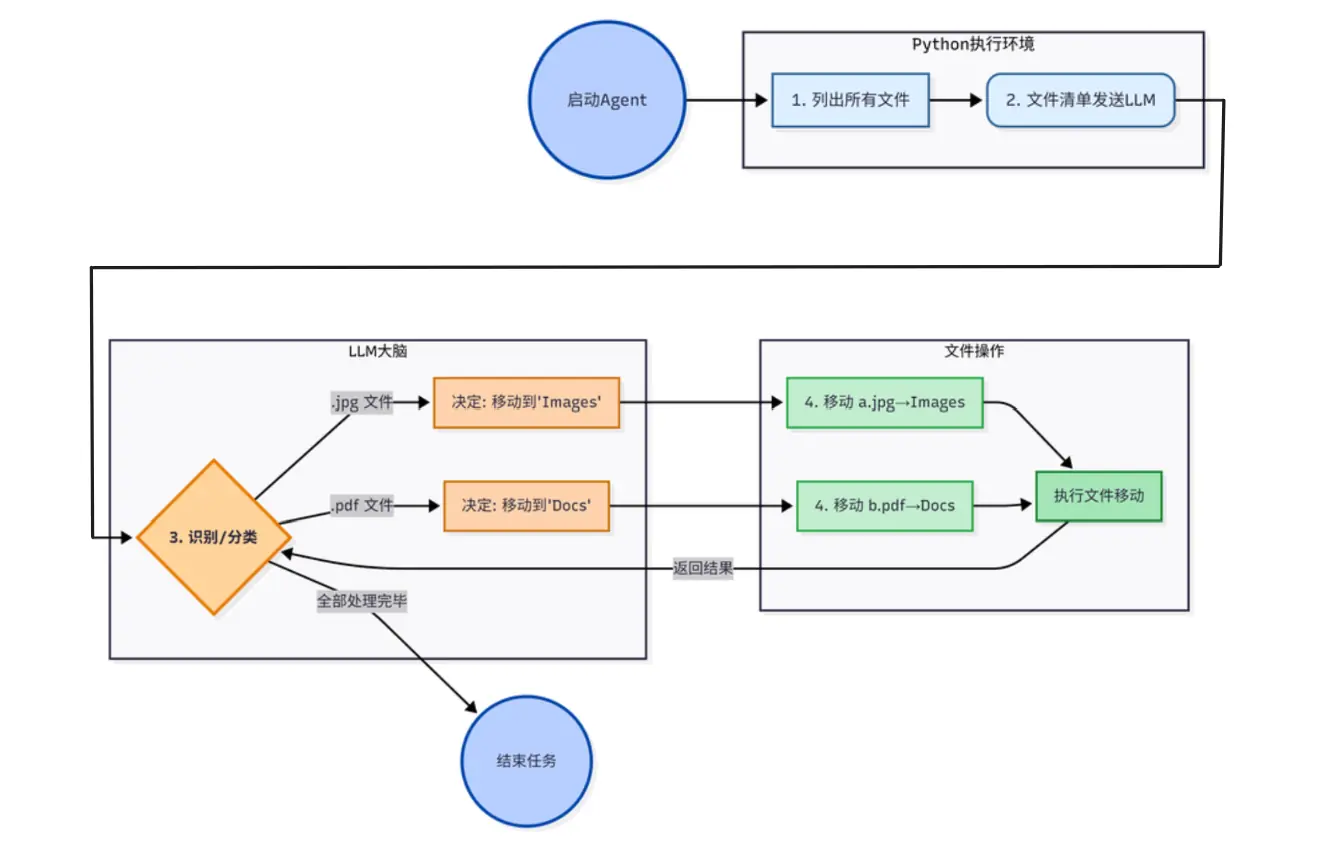
如上图,我们主要有三个核心步骤:
- 提供方法,允许AI读取文件夹内的所有文件
- 提供方法,允许AI移动文件夹内的文件
- 构建ReAct 循环,直到AI完成整个任务
03. 实现两个核心tools函数
这两个函数对于任何可以操作 File System 的编程语言来说,都不算困难。
首先是 list_files 方法,核心代码非常简单:
python
for f in os.listdir(BASE_PATH):
f_path = os.path.join(BASE_PATH, f)
# 过滤逻辑:只看文件,忽略隐藏文件(.开头)
if os.path.isfile(f_path) and not f.startswith('.'):
files.append(f)
# 必须返回 JSON 字符串,而不是 Python 列表
return json.dumps({"files": files}, ensure_ascii=False)稍微需要注意一点的时候,就是最后return出来的不能是数组,而是JSON字符串。
然后是 move_file 函数:
python
# 检查源文件
if not os.path.exists(source_file):
return json.dumps({"error": f"文件不存在: {filename}"}, ensure_ascii=False)
# 检查并创建目标目录
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 移动文件
shutil.move(source_file, target_file)也是非常容易,基本没啥特别要注意的,return 结果的时候序列化成JSON字符串即可。
04. 定义函数Schema
这一步是要构建一个【工具清单】以告诉AI,你的本地可以提供哪些有用的方法,分别叫什么名字,有什么用,以及接收哪些参数。

这样,当AI遇到困境的时候,才会想起来调用你本地提供的方法。
python
# 工具定义 (供 LLM 阅读)
tools_schema = [
{
"type": "function",
"function": {
# 方法名
"name": "list_files",
# 方法描述
"description": "查看当前文件夹里有哪些文件待处理。",
# 接收参数
"parameters": {
"type": "object",
"properties": {}
}
}
},
{
"type": "function",
"function": {
"name": "move_file",
"description": "将指定文件移动到目标文件夹中。",
"parameters": {
"type": "object",
"properties": {
"filename": {
"type": "string",
"description": "源文件名 (必须是 list_files 返回列表中存在的名字)"
},
"category": {
"type": "string",
"description": "目标文件夹名称 (例如 'Images', '合同文件', '简历')"
}
},
"required": ["filename", "category"]
}
}
}
]这块的详细细节可以查看本专栏第五课《春哥的Agent通关秘籍05:工具调用 Function Calling【知识与思路篇】》具体查看schema细节,实战篇就不赘述了。
05. ReAct 循环的构建
ReAct循环的核心是一个while循环。
我们需要把整个交互包裹在一个 while True 循环里,只要 AI 还想调工具,我们就一直陪它跑下去,直到它认为信息足够了,不再调用工具为止。
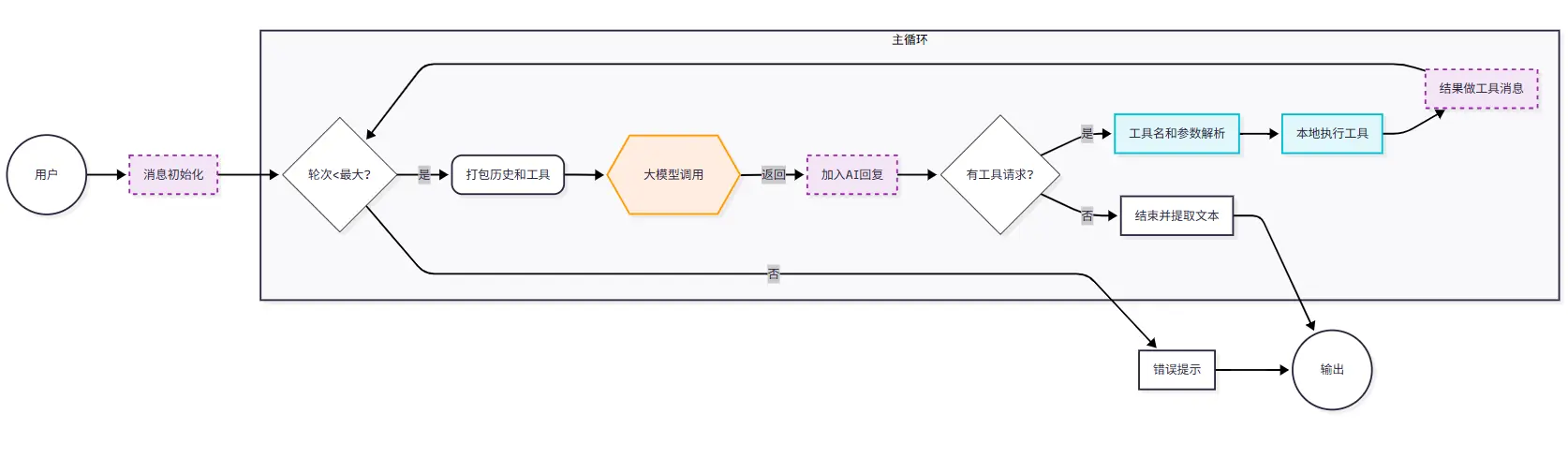
这里,我们按照Agent最常见的while循环逻辑画出了示意图,关键除了最大轮次判断之外,最需要注意的就是这里:
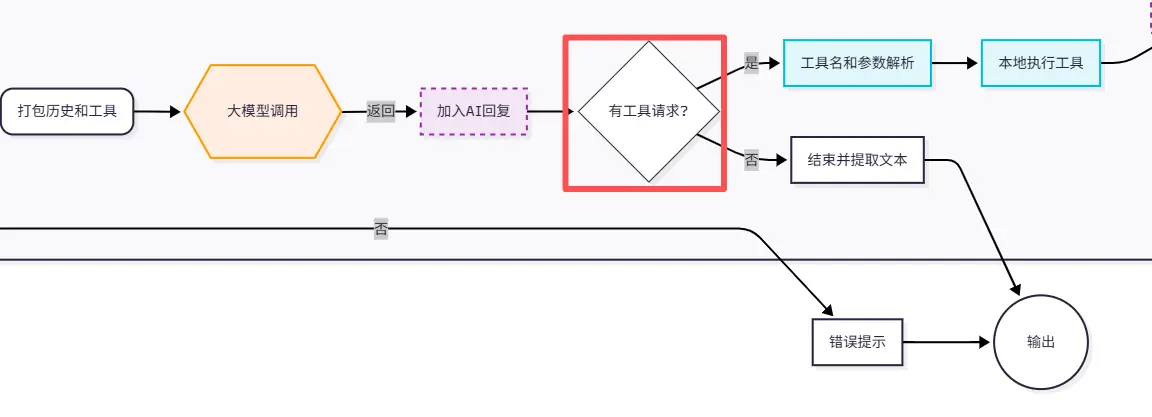
判断AI是否有工具调用的诉求。
没有的话,直接反馈给用户就行,否则的话,就需要进入while循环了。
因此,编程while循环版本,我们要引入两个重要的机制:
- MAX_ROUND 防护,防止 AI 陷入死循环把你的钱烧光。
- if not ai_msg.tool_calls 时,跳出循环,return final_result。
核心代码如下:
python
# 循环限制,防止死循环
MAX_TURNS = 60
for turn in range(MAX_TURNS):
print(f"🔄 第 {turn + 1} 轮思考中...")
# 1. 呼叫大模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools_schema,
)以及对其 response 的内容检查:
python
if ai_message.tool_calls:
print(f"⚡ 触发了 {len(ai_message.tool_calls)} 个操作请求!")
# 3. 遍历并执行所有工具调用 (Parallel Function Calling)
for tool_call in ai_message.tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# 略:根据方法名和参数调用方法
else:
# 如果没有工具调用,说明任务结束,AI 给出了总结
print(ai_message.content)
break06 管理你的message清单
众所周知,LLM是没有记忆的。
你每一次和它聊天,对于它来说,都是一次全新的相遇。
- 你看到小美,上去打招呼:小美你好,我是李雷。
- 小美回复你:李雷你好,我是小美。
- 你马上问小美:你复述一遍,我是谁?
- 小美:抱歉,我不知道你是谁,这是我们第一次聊天。
为了解决这个问题,为了能实现多轮会话,人们想到了一个简单而实用的方法:
- 你看到小美:"小美你好,我是李雷。"
- 小美回复:"李雷你好,我是小美。"
- 这次你学聪明了,给递过去一个清单,上面记载了你们刚才的聊天记录,顺便你问:"你复述一遍,我是谁?"
- 小美微笑:当然,你是李雷。
没错,你现在用到的看起来有记忆的LLM 聊天工具,其实每轮会话都把所有聊天记录都塞进去。

这是目前所有Agent开发者都不得避免对的一个世纪难题,因为这样你的每次会话的聊天清单都会越来越长,当Token长到一定程度后,就会导致一系列的问题。
- 收费
- 响应速度
- 降智
- 超出最大长度
等等,这里我们先按下不表,但你需要知道,你需要永远按如下方式维护你的message,来让LLM保持记忆:
- 永远把System Prompt放在第一个元素。
- 把用户的对话,和LLM的回复依次推入messages
- 包括AI请求调用 Function的要求,和终端调用Function的结果,也都要按顺序推入message。
- 你甚至需要每次调用都带上 tools schema,因为LLM同样不记得你有哪些方法,必须每次告诉它。
最终效果
可以访问demo仓库:github.com/zhangshichu... 获取demo原始代码。
依次执行如下指令:
bash
python .\lesson_06\generate_files.py
python .\lesson_06\ai_organizer.py执行后:
下一步预告
本节,我们使用前两节课的知识点,进行了一次简单的实操。
- 实现本地的Function作为tools传递给AI
- 在本地构建构建ReAct循环
- 维护messages清单,以保持AI的记忆
下节课,我们将深入理解AI的本质,学习什么是向量,什么是向量化,以及如何构建一个本地知识库,让AI能够快速检索你的私有知识!
敬请期待!
