本文来源:https://datapythonista.me/blog/whats-new-in-pandas-3
pandas 3.0 刚刚发布。本文将通过一个真实案例,重点从性能、语法和用户体验三个方面,阐述 pandas 2 与全新的 pandas 3 之间的主要差异。
关于 pandas 版本管理的说明
在深入探讨 pandas 3 的技术细节之前,有必要先了解一下 pandas 的开发模式及其发布周期的预期。
许多软件项目是在主要版本(major releases)之间并行开发新功能的。如果 pandas 遵循这种模式,开发流程可能看起来像这样:
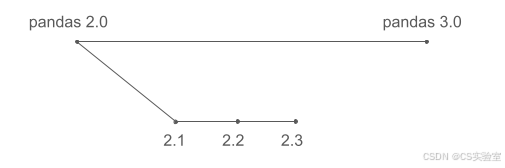
这通常是用户的预期。然而在现实中,pandas 的开发遵循一种不同的模式:
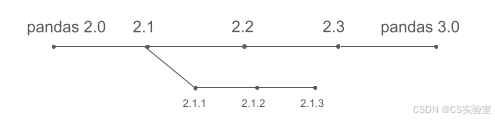
pandas 不会在跨主版本的不同分支上并行开发功能。相反,新功能会持续合并到主开发分支中,并在准备就绪后包含在下一个版本中(例如 2.1)。因此,pandas 3.0 并不包含自 pandas 2.0(大约三年前发布)以来开发的所有内容,而主要包含自 pandas 2.3(大约六个月前发布)以来新增的内容。
最重要的是,pandas 开发者始终优先考虑向后兼容性 (backward compatibility)。我们不会为了改进每一处细节而不断破坏 API,而是力求在不强制用户重写代码库的前提下进行合理的修复。维护大型 pandas 项目的用户,或者那些不想每年重新学习 pandas 语法的人,可能会对这一理念表示赞赏。
这种保守策略的缺点在于,pandas 无法时刻提供最顶尖的性能或完全整洁一致的 API,而是必须背负几十年前的一些设计决策包袱------如果我们今天从头开始构建 pandas,可能会采取完全不同的实现方式。对于从零开始构建基于 DataFrame 项目的用户,值得考虑 Polars,它可以从 pandas 的经验中吸取教训,提供具有惊人性能、全面 Arrow 支持以及更清晰一致 API 的 DataFrame 库。
话虽如此,pandas 3 仍然引入了若干重大变更,显著提升了性能、语法和整体用户体验。让我们来详细了解一下。
令人头疼的 pandas 警告
本文中的示例使用一个包含 2,231,577 条酒店房间记录的数据集,结构如下:
| name | country | property_type | room_size | max_people | max_children | is_smoking |
|---|---|---|---|---|---|---|
| Single Room | it | guest_house | 15.0503 | 1 | 0 | False |
| Single Room Sea View | gr | hotel | 19.9742 | 1 | 0 | False |
| Double Room with Two Double Beds -- Smoking | us | lodge | 32.5161 | 4 | 3 | True |
| Superior Double Room | de | hotel | 19.9742 | 2 | 1 | False |
| Single Bed in Female Dormitory Room | br | hostel | 6.0387 | 1 | 0 | False |
我们先从 pandas 2 开始。第一个操作是将房间可容纳的儿童最大数量加到最大人数(成人)上,但仅针对美国的酒店。
python
>>> all_rooms = pandas.read_parquet("rooms.parquet")
>>> us_hotel_rooms = all_rooms[(all_rooms.property_type == "hotel") & (all_rooms.country == "us")]
>>> us_hotel_rooms["max_people"] += us_hotel_rooms.max_children这会产生那个臭名昭著的警告:
text
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
us_hotel_rooms["max_people"] += us_hotel_rooms.max_children如果您使用 pandas 有一段时间了,几乎肯定见过这个警告。其发生原因可以总结如下:
us_hotel_rooms可能非常大,假设内存中占用 10 GB。- 复制这 10 GB 数据会很慢,并且需要额外的 10 GB RAM。
- 理想情况下,pandas 希望避免复制,而是保留对
all_rooms相关行的引用。 - 当用户修改
us_hotel_rooms时,问题就出现了,因为这种修改可能会意外地影响all_rooms。 - pandas 2 使用复杂的启发式方法来决定是否创建副本,而该警告的存在就是为了提示可能发生意外的副作用。
在实践中,大多数用户并不完全理解其根本问题,通常通过以下两种方式之一处理警告(往往基于 StackOverflow 或聊天机器人的建议):
- 使用
warnings.filterwarnings("ignore")全局抑制警告。 - 在每次操作后使用
df = df.copy()强制复制。
解决此类问题的标准方案是写时复制 (Copy-on-Write):
- 在过滤后绝不急切地(eagerly)复制数据。
- 仅当引用另一个 DataFrame 的 DataFrame 被修改时,才自动创建副本。
经过大量早在 pandas 3 之前就开始的工作,写时复制现已完全实现。警告消失了,升级到 pandas 3 后,代码中所有的 .copy() 调用都可以安全移除了。
改进的 pandas 语法
让我们重温同一个例子,这次关注的是语法而非内存行为。对于编写 pandas 管道(pipelines)而不是在 Notebook 中交互式探索数据的用户,前面的例子可以使用链式调用(method chaining)重写:
python
(
pandas.read_parquet("rooms.parquet")
[lambda df: (df.property_type == "hotel") & (df.country == "us")]
.assign(max_people=lambda df: df.max_people + df.max_children)
)这种风格避免了重复赋值,并使操作顺序显式化。然而,虽然链式调用本身提高了代码的可读性,但许多用户会觉得这个版本更难读,主要是因为必须使用 lambda,这是 pandas 中一个非直观的概念。
在 pandas 中,列访问通常使用 df.column 或 df["column"]。但在链式调用中,中间的 DataFrame 对象在每一步并不作为一个命名变量存在。即使我们创建了 df,assign 操作中的 df 也不是赋值时的 DataFrame 对象(仅包含美国酒店数据),而是包含所有行的原始 DataFrame:
python
df = pandas.read_parquet("rooms.parquet")
df = (
df[(df.property_type == "hotel") & (df.country == "us")]
.assign(max_people=df.max_people + df.max_children)
)使用 lambda 可以推迟求值,从而使列表达式针对正确的中间 DataFrame 进行解析。虽然有效,但这种使用 lambda 的方法使得阅读 pandas 代码变得明显更加困难。Polars 和 PySpark 等其他库通过 col() 表达式 API 更清晰地解决了这个问题。
pandas 3 引入了同样的机制:
python
(
pandas.read_parquet("rooms.parquet")
[(pandas.col("property_type") == "hotel") & (pandas.col("country") == "us")]
.assign(max_people=pandas.col("max_people") + pandas.col("max_children"))
)这是一个显著的进步,使得 pandas 代码的可读性大大提高,特别是在使用链式调用时。但仍有改进空间。作为对比,Polars 中的等效过滤代码如下:
python
.filter(polars.col("property_type") == "hotel", polars.col("country") == "us")使用显式的 .filter() 方法能更清晰地表达操作意图。经验丰富的 Python 开发者应该熟悉 Tim Peter 精彩的《Python 之禅》,其中提到"显式优于隐式"。虽然使用 df[...] 进行过滤和选择确实很方便(特别是在交互式使用中),但在链式管道中可能会变得令人困惑。
更重要的是,pandas 仍然依赖位运算符 & 来组合条件。理想情况下,用户应该写 condition1 and condition2,但 Python 保留了 and 关键字用于布尔求值,且不允许库对其进行重载。
使用 & 会导致这种令人惊讶的行为:
python
>>> 1 == 1 & 2 == 2
False该表达式被求值为 1 == (1 & 2) == 2,而不是 (1 == 1) and (2 == 2)。当 & 两侧是 pandas 表达式时也会发生同样的情况。这就是为什么在前一个例子 [(pandas.col("property_type") == "hotel") & (pandas.col("country") == "us")] 中,条件必须小心地加上括号。
由于在 Python 中无法重载 and, or 和 not,且短期内不太可能允许这样做,Polars 的方法可能是目前最佳的解决方案。在 pandas 中实现 .filter() 并允许将多个条件作为不同参数传递,是未来版本中有望实现并提供给用户的功能。
pandas 函数加速
pandas 3 的另一个重要改进是对用户定义函数 (UDF) 的更好支持。在 pandas 中,UDF 是传递给 .apply() 或 .map() 等方法的常规 Python 函数。
如果您使用 pandas 有一段时间,您可能听说过 .apply() 被认为是一种糟糕的实践:
这种名声往往也是"实至名归"的。例如,逐行将 max_people 和 max_children 相加:
python
def add_people(row):
return row["max_people"] + row["max_children"]
rooms.apply(add_people, axis=1)其结果与向量化版本相同,但执行时间从大约 3 毫秒增加到了 11 秒(慢了约 4,000 倍)。
然而,并非所有问题都能整洁地向量化。考虑将诸如 "Superior Double Room with Patio View" 之类的房间名称转换为结构化字符串,如:
text
property_type=hotel, room_type=superior double, view=patio完全向量化的解决方案很快会变得复杂且难以维护。在示例数据集上,此实现大约需要 14 秒:
python
name_lower = df["name"].str.lower()
before_with = name_lower.str.split(" with ").str[0]
after_with = name_lower.str.split(" with ").str[1]
view = (("view=" + after_with.str
.removesuffix(" view"))
.where(after_with.str.endswith(" view"),
""))
bathroom = (("bathroom=" + after_with.str
.removesuffix(" bathroom"))
.where(after_with.str.endswith(" bathroom"),
""))
result = (
"property_type="
+ df["property_type"]
+ ", room_type="
+ before_with.str.removesuffix(" room")
+ pandas.Series(", ", index=before_with.index).where(view != "", "")
+ view
+ pandas.Series(", ", index=before_with.index).where(bathroom != "", "")
+ bathroom
)而等效的 UDF(至少在我看来)要清晰得多:
python
def format_room_info(row):
result = "property_type=" + row["property_type"]
desc = row["name"].lower()
if " with " not in desc:
return result + ", room_type=" + desc.removesuffix(" room")
before, after = desc.split(" with ", 1)
result += ", room_type=" + before.removesuffix(" room")
if after.endswith(" view"):
result += ", view=" + after.removesuffix(" view")
elif after.endswith(" bathroom"):
result += ", bathroom=" + after.removesuffix(" bathroom")
return result
df.apply(format_room_info, axis=1)这个版本运行耗时约 22 秒,比向量化方法慢约 70%,但更易于阅读和维护。
pandas 3 引入了一个新的执行接口,允许第三方引擎加速 UDF。bodo.ai 就是一个例子,它可以对纯 Python 和 pandas 代码进行 JIT 编译:
python
import bodo
df.apply(format_room_info, axis=1, engine=bodo.jit())使用 bodo.ai,相同的代码运行仅需约 9 秒,不到标准 UDF 版本所需时间的一半,并且比向量化版本快 35%。这种速度提升是在保持 UDF 实现清晰度的同时获得的。
尽管 35% 的提速听起来并不惊人,但 JIT 编译有固定的启动成本,即编译代码的时间,这与后续处理的数据量无关。随着数据集变大,相对收益会显著增加。对于非常大的数据集,差异将是巨大的。因此,在这个例子中,如果我们有 1 亿行而不是 2 百万行,使用 bodo.ai 将极大提升性能。
至关重要的是,执行现在发生在 pandas 本身之外。这开启了专用执行引擎生态系统的大门。例如,Blosc 可以利用压缩内存执行来加速 NumPy 风格的工作负载,并且与 pandas 3 的配合就像 bodo 一样简单,只需使用 engine=blosc2.jit()。启用这个生态系统增加了无限的可能性。例如,bodo.ai 还支持在 HPC 集群上进行分布式执行,并且可能会出现针对不同用例和策略的其他引擎。
Apache Arrow 革命进展如何?
如果您读过我之前的文章《pandas 2.0 与 Arrow 革命》,您可能会想知道这一努力后来怎么样了。
在 pandas 2 发布时,核心团队致力于实施更激进的向 Apache Arrow 的过渡。主要是为了确保用户始终能从 Arrow 提供的性能和兼容性增强中受益。这对于字符串尤为相关,因为与 Arrow 实现相比,传统的实现确实并非最优。最终,这一计划被缩减了。简而言之,情况如下:
- PyArrow 最初计划作为必须的依赖项。没有这一点,传统的字符串无法被完全替换。
- 在短时间内,用户会看到关于即将实施此要求的警告。
- 反馈引起了担忧,主要关于磁盘占用和平台支持。
- 随后提出了一种混合方案:对于已安装 PyArrow 的用户,字符串将默认由 Arrow 支持;而未安装 PyArrow 的用户将继续使用传统字符串。但这种更改对用户来说在很大程度上是透明的。在这两种情况下,字符串都将使用新的
str数据类型,且缺失值的行为将类似于传统的NaN表示。 - 该提案获得批准,即使在 PyArrow 解决了大部分最初的担忧之后,强制要求 PyArrow 的计划仍被放弃,最终实施了混合方案。
举个例子,新的字符串看起来像这样:
python
>>> pandas.Series([None, "a", "b"])
0 NaN
1 a
2 b
dtype: str
>>> pandas.Series([None, "a", "b"]) == "a"
0 False
1 True
2 False
dtype: bool在示例中,数据类型是新的 str 类型,缺失值表示为 NaN,并且当比较 NaN == "a" 时返回 False。您无法仅凭上述代码知道内部使用的是 NumPy 对象还是 Arrow 字符串,因为这取决于环境而非代码本身。
相比之下,纯 Arrow 方法如下所示:
python
>>> pandas.Series([None, "a", "b"], dtype="string[pyarrow]")
0 <NA>
1 a
2 b
dtype: string
>>> pandas.Series([None, "a", "b"], dtype="string[pyarrow]") == "a"
0 <NA>
1 True
2 False
dtype: bool[pyarrow]缺失值不再是浮点型的 NaN,而是 pandas 的 <NA>,它本身并不完全是一个值,而是一个指示值是否缺失的引用。在 Arrow 中,使用一个单独的数组来确立哪些值是缺失的。示例中的主要区别在于,这种情况下 <NA> == "a" 返回 <NA>,而不是 pandas 3 默认实现中的 False。
我个人并未察觉到目前有任何显著改变 pandas 3 现状的计划或努力。虽然新方法在向后兼容性和允许用户默认受益于 Arrow 之间做出了很好的权衡,但它也有缺点。现在有 3 种不同的方式来表示字符串,因为上面的 PyArrow 示例在 pandas 3 中仍然有效(就像设置 dtype="object" 并使用原始实现一样)。对于某些用户来说,同一段代码根据是否安装了 PyArrow 而运行不同的实现可能并不理想。这对于其他库的开发者来说可能很棘手,因为他们无法假设 pandas 字符串内部是什么。
显然,从 pandas 3 新字符串中受益最大的用户是那些拥有现有代码库且关注向后兼容性的用户。虽然新的更改并非完全向后兼容,但迁移到 pandas 3 应该是非常直接的。
对于需要基于 Arrow 的更简单、现代的 DataFrame 体验,且不太关注 pandas 历史遗留问题的用户,Polars 是一个很好的替代选择。