㊙️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!
㊗️爬虫难度指数:⭐
🚫声明:本数据&代码仅供学习交流,严禁用于商业用途、倒卖数据或违反目标站点的服务条款等,一切后果皆由使用者本人承担。公开榜单数据一般允许访问,但请务必遵守"君子协议",技术无罪,责任在人。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 摘要(Abstract)](#1️⃣ 摘要(Abstract))
- [2️⃣ 背景与需求(Why)](#2️⃣ 背景与需求(Why))
- [3️⃣ 合规与注意事项(必写)](#3️⃣ 合规与注意事项(必写))
- [4️⃣ 技术选型与整体流程(What/How)](#4️⃣ 技术选型与整体流程(What/How))
- [5️⃣ 环境准备与依赖安装(可复现)](#5️⃣ 环境准备与依赖安装(可复现))
- [6️⃣ 核心实现:请求层(Fetcher)](#6️⃣ 核心实现:请求层(Fetcher))
- [7️⃣ 核心实现:解析层(Parser)](#7️⃣ 核心实现:解析层(Parser))
- [8️⃣ 数据存储与导出(Storage)](#8️⃣ 数据存储与导出(Storage))
- [9️⃣ 运行方式与结果展示(必写)](#9️⃣ 运行方式与结果展示(必写))
- [🔟 常见问题与排错(强烈建议写)](#🔟 常见问题与排错(强烈建议写))
- [1️⃣1️⃣ 进阶优化(可选但加分)](#1️⃣1️⃣ 进阶优化(可选但加分))
- [1️⃣2️⃣ 总结与延伸阅读](#1️⃣2️⃣ 总结与延伸阅读)
- [🌟 文末](#🌟 文末)
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏👉《Python爬虫实战》👈
💕订阅后更新会优先推送,按目录学习更高效💯~
1️⃣ 摘要(Abstract)
本文将带你通过 requests 和 lxml 库,构建一个稳健的轻量级爬虫。我们将把目光对准 Python 官网的下载列表页,精准提取出每一个历史版本的版本号 、发布日期 以及对应的文档/详情页链接,并最终清洗为标准化的 CSV 报告。
读完这篇,你将获得:
- 🎯 掌握
lxml+XPath处理 HTML 列表数据的核心技巧(比正则更稳,比 BS4 更快)。 - 🛠️ 学会如何处理非结构化的时间字符串,将其转化为标准日期格式。
- 📂 拥有一份完整的 Python 语言版本进化史数据,可用于后续的数据可视化分析。
2️⃣ 背景与需求(Why)
为什么要爬这个?
想象一下,你是一个技术负责人,需要分析 Python 各个版本的迭代周期,或者你想找出那些已经停止维护的古老版本以便在公司内部做安全预警。手动去网页上一行行复制粘贴?那太 Low 了!我们需要自动化。
目标站点: https://www.python.org/downloads/
目标数据清单:
| 字段名 (En) | 字段含义 | 示例值 |
|---|---|---|
version |
版本号 | Python 3.11.5 |
release_date |
更新时间 | 2023-08-24 |
details_url |
文档/详情入口 | https://www.python.org/downloads/release/python-3115/ |
3️⃣ 合规与注意事项(必写)
做爬虫,"讲武德" 是第一条。🚧
- Robots协议检查: 访问
https://www.python.org/robots.txt,我们可以看到 Python 官网对常规的爬虫比较宽容,只要你不去爬 admin 后台或者频繁请求搜索接口即可。 - 频率控制(Rate Limiting): 虽然这是公开数据,但不要用并发(Asyncio/Threading)去轰炸它。这只是一个简单的列表页,单线程、加个
time.sleep(1)是对目标站点的基本尊重。 - 数据用途: 我们仅做学习和数据分析使用,不涉及任何用户隐私或敏感商业数据。Don't be evil.
4️⃣ 技术选型与整体流程(What/How)
技术栈决策:
- 请求库:
requests。杀鸡焉用牛刀(Scrapy)?对于单页面或少量页面的采集,requests是最优雅的选择。 - 解析库:
lxml。很多新手喜欢 BeautifulSoup,但我更推荐lxml。它的XPath语法虽然不仅要学,一旦学会,那个解析速度和定位的精准度,真的是"指哪打哪",效率吊打 BS4。 - 类型: 静态采集。Python 官网的下载列表是服务器端渲染(SSR)的 HTML,源码里就有数据,不需要搞 Selenium 或 Playwright 这种重型武器。
数据流转图:
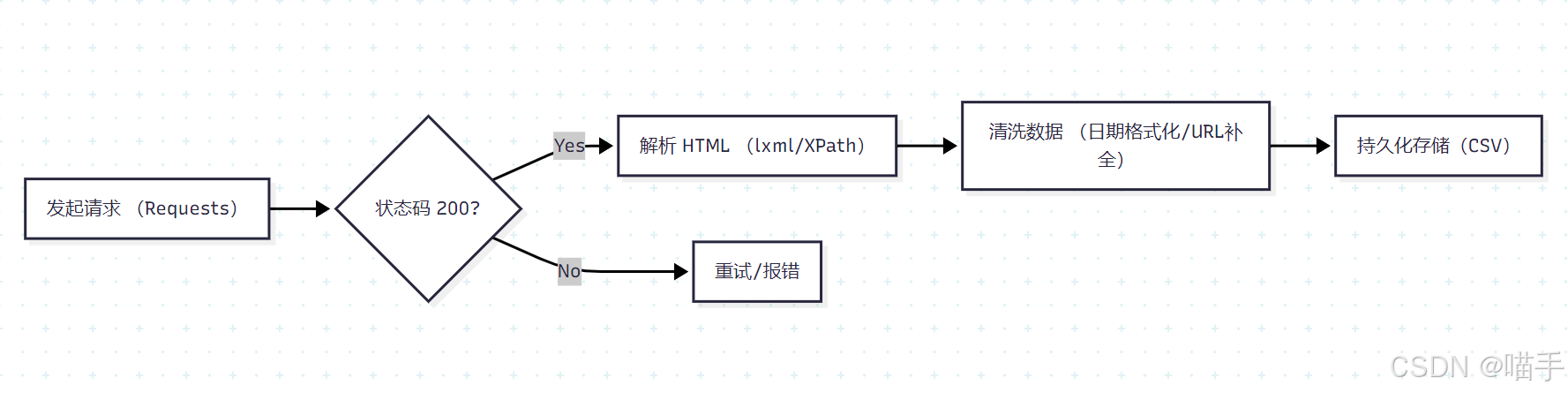
5️⃣ 环境准备与依赖安装(可复现)
我的环境是 Python 3.10,但 3.8+ 应该都没问题。
项目结构:
text
python_version_spider/
├── data/
│ └── python_versions.csv # 结果文件
├── main.py # 主程序
└── requirements.txt # 依赖依赖安装:
打开终端,运行:
bash
pip install requests lxml pandas(注:这里引入 pandas 主要是为了最后存 CSV 方便,其实用内置的 csv 模块也行,但 pandas 逼格高且方便后续分析)
6️⃣ 核心实现:请求层(Fetcher)
在 main.py 中,我们首先构建一个健壮的请求函数。这里有几个关键细节:
- Headers:必须伪装成浏览器(User-Agent),否则有些服务器会直接拒绝 python-requests 的默认头。
- Session :使用
requests.Session()可以复用 TCP 连接,稍微提升一点性能。
python
import requests
from lxml import etree
import pandas as pd
import time
import random
# 定义全局请求头,模拟真实浏览器
HEADERS = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36",
"Referer": "https://www.google.com/"
}
def fetch_content(url):
"""
抓取网页源码,包含基础的异常处理
"""
print(f"🚀 正在发起请求: {url}")
try:
# 使用 Session 对象,虽是单次请求,但养成好习惯
session = requests.Session()
# 设置超时时间,防止网络卡死
response = session.get(url, headers=HEADERS, timeout=10)
# 显式抛出 HTTP 错误(如 404, 500)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(f"❌ 请求失败: {e}")
return None7️⃣ 核心实现:解析层(Parser)
这是最见功力的地方。我们要分析 HTML DOM 结构。
打开 Python 官网下载页,右键"检查",你会发现列表包裹在 div.download-list-widget 下的 ol.list-row-container li 中。
XPath 策略:
- 列表项:
//div[contains(@class, "download-list-widget")]//ol/li - 版本号:
.//span[@class="release-number"]/a/text() - 发布日期:
.//span[@class="release-date"]/text() - 详情链接:
.//span[@class="release-number"]/a/@href
python
def parse_html(html_content):
"""
使用 lxml 解析 HTML 并提取字段
"""
if not html_content:
return []
print("🔍 正在解析 HTML DOM...")
tree = etree.HTML(html_content)
# 定位到所有的版本行 (li 标签)
# 技巧:使用 contains 匹配 class,防止 class 包含多余空格或其他样式名
rows = tree.xpath('//div[contains(@class, "download-list-widget")]//ol/li')
data_list = []
for row in rows:
try:
# 1. 提取版本号
# xpath 返回的是列表,我们需要取第一个元素,并做防空处理
raw_ver = row.xpath('.//span[@class="release-number"]/a/text()')
version = raw_ver[0].strip() if raw_ver else "Unknown"
# 2. 提取发布日期
raw_date = row.xpath('.//span[@class="release-date"]/text()')
release_date = raw_date[0].strip() if raw_date else "Unknown"
# 3. 提取链接 (相对路径)
raw_link = row.xpath('.//span[@class="release-number"]/a/@href')
link = raw_link[0].strip() if raw_link else ""
# URL 补全:如果是相对路径,需要拼上域名
full_link = f"https://www.python.org{link}" if link.startswith("/") else link
# 将提取的数据存入字典
item = {
"version": version,
"release_date": release_date,
"docs_url": full_link
}
data_list.append(item)
except Exception as e:
# 解析单行报错不应阻断整个循环,记录日志即可
print(f"⚠️ 解析某行数据出错: {e}")
continue
print(f"✅ 成功提取 {len(data_list)} 条记录")
return data_list8️⃣ 数据存储与导出(Storage)
这里我们做一点微小的数据清洗工作,特别是日期。通常网页上的日期可能是 "Aug. 24, 2023",我们最好把它转成 YYYY-MM-DD,方便以后排序。
python
def save_data(data_list, filepath):
"""
数据清洗并保存为 CSV
"""
if not data_list:
print("📭 没有数据可保存")
return
df = pd.DataFrame(data_list)
# --- 数据清洗部分 ---
# 假设日期格式是 "Aug. 24, 2023",pandas 的 to_datetime 通常很智能
# errors='coerce' 表示如果转换失败,就设为 NaT,不要报错
print("🧹 正在清洗日期格式...")
df['release_date'] = pd.to_datetime(df['release_date'], errors='coerce').dt.strftime('%Y-%m-%d')
# 去重:防止万一抓到了重复的行
df.drop_duplicates(subset=['version'], inplace=True)
# 保存
df.to_csv(filepath, index=False, encoding='utf-8-sig') # utf-8-sig 解决 Excel 打开乱码问题
print(f"💾 文件已保存至: {filepath}")9️⃣ 运行方式与结果展示(必写)
这是程序的入口。把上面的代码拼在一起(为了演示清晰,我把它们放在逻辑块里)。
入口代码:
python
if __name__ == "__main__":
TARGET_URL = "https://www.python.org/downloads/"
OUTPUT_FILE = "python_release_history.csv"
# 1. 获取
html = fetch_content(TARGET_URL)
# 2. 解析
data = parse_html(html)
# 3. 存储
save_data(data, OUTPUT_FILE)
# 4. 展示结果样例
print("\n--- 📊 结果预览 (Top 5) ---")
if data:
# 简单打印前5条看看效果
df_preview = pd.DataFrame(data).head(5)
print(df_preview.to_markdown(index=False)) # 需要 pip install tabulate
else:
print("无数据展示")运行结果预览:
运行 python main.py 后,控制台会输出类似下表的内容:
text
--- 📊 结果预览 (Top 5) ---
| version | release_date | docs_url |
|:-------------|:-------------|:-----------------------------------------------------|
| Python 3.11.5| 2023-08-24 | https://www.python.org/downloads/release/python-3115/|
| Python 3.10.13| 2023-08-24 | https://www.python.org/downloads/release/python-31013/|
| Python 3.9.18| 2023-08-24 | https://www.python.org/downloads/release/python-3918/|
| Python 3.8.18| 2023-08-24 | https://www.python.org/downloads/release/python-3818/|
| Python 3.12.0rc1| 2023-08-06| https://www.python.org/downloads/release/python-3120rc1/|🔟 常见问题与排错(强烈建议写)
在实战中,你可能会遇到这些"坑":
-
AttributeError: 'NoneType' object has no attribute 'text'
- 原因:选择器没定位到元素(比如某一行刚好没有发布日期)。
- 对策 :看我在
parse_html里写的if raw_ver else ...逻辑了吗?这就是防御性编程。永远不要假设网页结构是完美的。
-
HTTP 403 Forbidden
- 原因:通常是没加 Headers,对方服务器识别出你是脚本。
- 对策 :把 Headers 里的
User-Agent换成最新的 Chrome 浏览器版本。
-
日期解析失败
- 原因:网页上的日期可能是 "Aug. 24" (如果不带年份) 或者 "2023/08/24"。
- 对策 :使用
pandas.to_datetime是最省事的,它能兼容多种格式。实在不行就得手写正则提取。
1️⃣1️⃣ 进阶优化(可选但加分)
如果你想让这个脚本更"专业":
- 🔍 增量更新:
每次运行前,先读取旧的 CSV。只有当爬到的version不在旧 CSV 里时,才追加写入。这样可以做成一个每日运行的监控脚本,一旦有 Python 新版本发布,就发邮件通知你。 - 🕷️ 深入爬取:
目前的脚本只拿到了入口链接。你可以写一个二级循环,点进docs_url,去抓取该版本具体的 MD5 校验码或 Release Notes 详细文本。那就要用到time.sleep(random.uniform(1, 3))来严格控制频率了,毕竟那是内页请求。
1️⃣2️⃣ 总结与延伸阅读
复盘:
今天我们只用了不到 50 行核心代码,就从 Python 官网扒下了一份结构化的版本历史数据。我们实践了从 请求 -> DOM 解析 -> 数据清洗 -> 存储 的全链路。这虽然是一个简单的静态爬虫,但它涵盖了数据采集 80% 的核心逻辑。
下一步做什么?
- 试试去爬 Django 或 Pandas 的官网,它们的结构大同小异,用来练习举一反三最好不过。
- 如果遇到那种这就一行"Loading..."数据的网页(Vue/React 写的),记得去学学如何抓取 XHR/Fetch 接口,那才是爬虫的高阶战场!
加油吧,数据猎人!任何伟大的数据分析,都始于一次成功的 requests.get!
🌟 文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。