摘要
本周学习了强化学习中是如何对actor的行为进行评估的,了解了critic的基本概念与工作原理,并进一步学习了Advantage Actor-Critic架构
abstract
This week, I learned about how the actor's behavior is evaluated in reinforcement learning, understood the basic concepts and working principles of the critic, and further studied the Advantage Actor-Critic architecture.
Critic
Critic 在强化学习系统中用于评估和预测价值。通过提供对未来回报的预测来指导 Actor(策略)的学习和优化。 它使得强化学习的学习过程更加稳定和高效
Critic 如何工作?
-
观察:Critic 观看 Actor 与环境互动,看到大量的(状态,动作,奖励,下一个状态)数据。
-
学习:Critic 使用这些数据,通过时间差分误差等方法来训练自己,目标是让自己对价值的预测越来越准确
-
反馈:Critic 将这个预测误差(TD Error)或梯度信息反馈给 Actor。这个误差是 Actor 学习的核心信号:
-
如果误差为正:说明实际结果比预期好,Actor 应该加强导致这个结果的行为。
-
如果误差为负:说明实际结果比预期差,Actor 应该减弱导致这个结果的行为。
-

强化学习两种方法
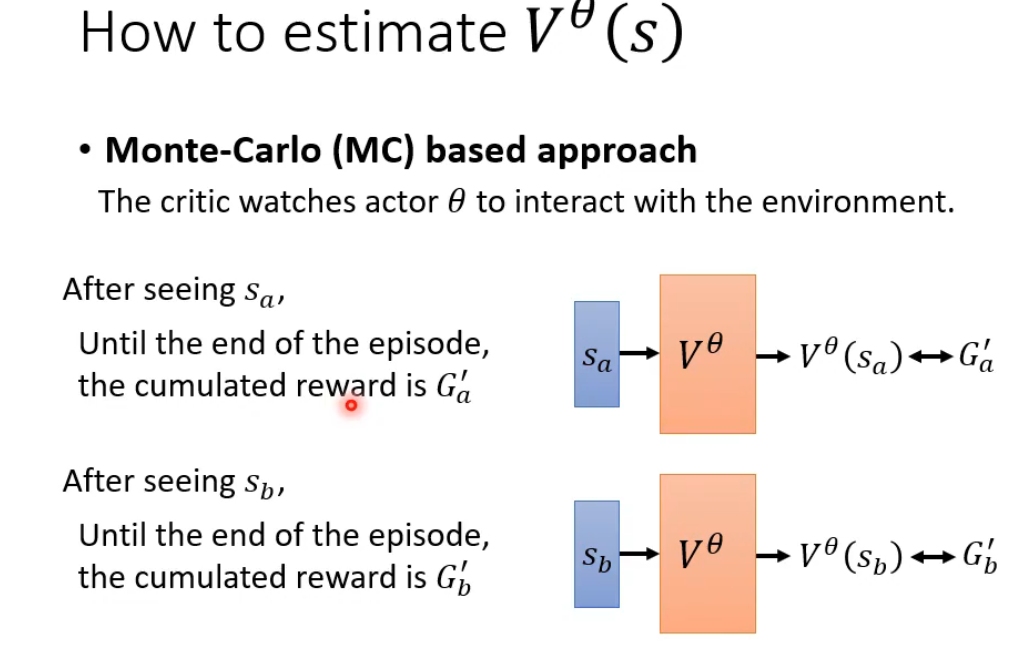
强化学习中两个核心概念:蒙特卡洛方法 和时序差分学习。蒙特卡洛(MC) :通过完整轨迹的真实回报 来更新价值估计。时序差分(TD) :通过相邻状态的估计值差分来更新价值估计。
| 特性 | 蒙特卡洛 | 时序差分 |
|---|---|---|
| 更新时机 | 必须等到一幕结束 | 每步之后立即更新 |
| 学习目标 | 实际累积回报 GtGt | TD目标 Rt+1+γV(St+1)Rt+1+γV(St+1) |
| 偏差/方差 | 无偏,高方差 | 有偏,低方差 |
| 对环境的了解 | 不需要环境模型 | 不需要环境模型(都是无模型方法) |
| 收敛性 | 收敛性较好,但慢 | 通常收敛更快,但不一定收敛到全局最优 |
| 核心概念 | 采样,完整回报 | 自举,TD误差 |

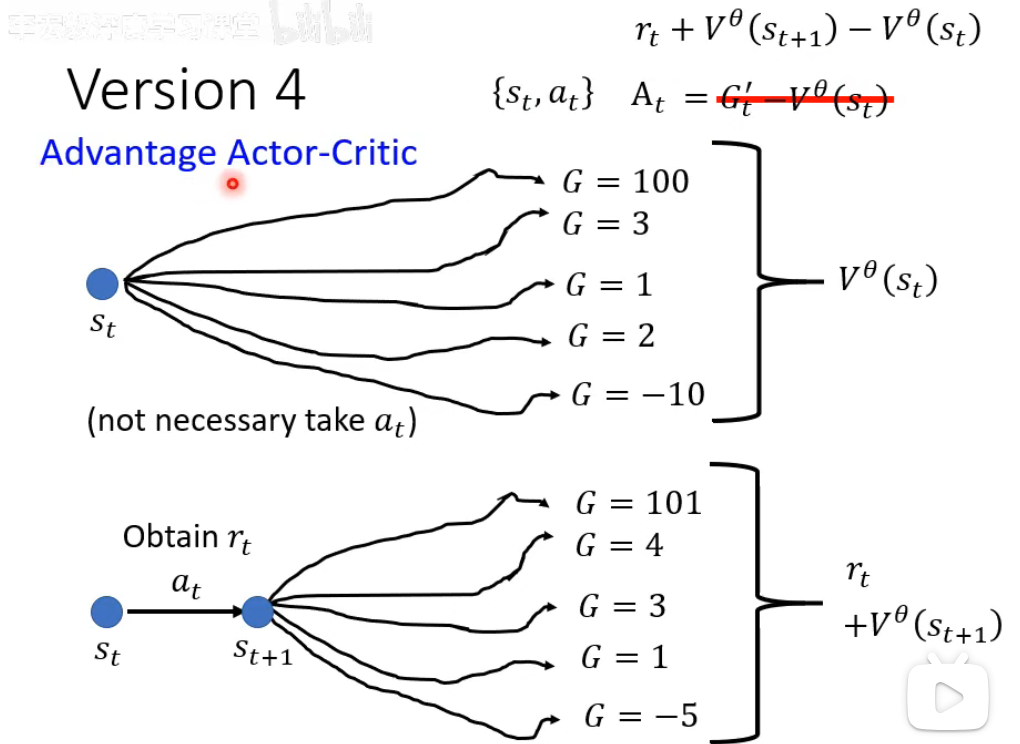
Advantage Actor-Critic
A2C的核心是引入优势函数的Actor-Critic架构。Critic学习状态价值V(s)作为基线,通过TD误差估计优势函数A(s,a)=Q(s,a)-V(s),衡量动作相对平均水平的优劣。Actor使用优势估计而非原始回报更新策略,大幅降低方差。这种"评估优势+策略优化"的双网络结构,使智能体既获得低方差更新信号,又能精确分配动作价值,成为现代策略梯度算法的稳定基础。