如原论文所说,尽管 VLAs 成功继承了语言先验,能够在多样化的语言指令之间进行泛化,尤其是在操控各类不同对象方面表现突出(Brohan et al.,2023,即RT-2),但它们在泛化到新环境,且更关键的是泛化到新的动作或技能时仍然能力有限『Guruprasad et al.,2025-即Benchmarking Vision, Language, & Action Models in Procedurally Generated, Open-Ended Action Environments;Zhou et al.,2025』
例如,VLAs可以成功执行"move coke can to Taylor Swift"(Brohan et al.,2023)这一指令:它们利用 VLM 预训练期间从网络获取的知识来识别目标位置,并将其与从机器人数据中学到的"移动"技能相连接
然而,如果机器人训练数据中不存在该特定技能,它们在完成诸如"untie the shoelace"这样的任务时就会失败
尽管 VLM 的先验在语义层面编码了应该"做什么",但它们缺乏关于动作应该如何执行的表示,也就是缺少在与几何结构、动力学和运动控制相一致的精确空间感知下对动作执行方式的表征『Chen et al.,2024-即SpatialVLM;Feng et al.,2025-即Seeing Across Views: Benchmarking Spatial Reasoning of Vision-Language Models in Robotic Scenes』 说白了,会纸上谈兵,但实际操作时 则不会,除非人类示教
这种方法带来了三个核心进展,使DreamZero 有别于以往的工作,包括其他WAM『Kim et al., 2026-即Cosmos Policy ; Liang et al., 2025-即Video Policy 框架:Video Generators are Robot Policies; Pai et al., 2025-即mimic-video』
其次,对DreamZero 进行任务实验表明,可以从多样且异质的数据中有效地学习通用策略,打破了通用型机器人策略需要针对每项任务进行多次重复演示的传统观念
尽管其他WAMs 表明,与VLAs 相比,从视频预测中学习到的先验可以提高动作学习的样本效率(Liao et al., 2025; Pai et al., 2025),但大多数工作仍然聚焦于重复示范
有一类工作通常采用模块化系统结构,其中基础模型生成一系列指令------用于处理高层任务规划、视觉轨迹或可供性(affordances),随后由专门的低层机器人策略或控制器加以执行Brohan et al.,2023;即On the Opportunities and Risks of Foundation Models
Driess et al.,2023,即PaLM-E
Huang et al.,2023,即VoxPoser Kumaret al.,2026,即Open-World Task and Motion Planning via Vision-Language Model Generated Constraints
Singh et al.,2023,即ProgPrompt
说白了,就是++不对VLM做微调,纯粹prompt VLM++,让其做动作预测
尽管这种模块化能够简化复杂规划,并提升泛化能力 Kaelbling and Lozano-Pérez,即Rationally Engineering Rational Robots
Lee et al.,2025,即MolmoAct
Li et al.,2025,即HAMSTER
和效率
Dreczkowski etal.,2025,即Learning a Thousand Tasks in a Day
对于VLA而言 Bjorck et al., 2025,即Gr00t n1
Black et al., 2024,即π0
Brohan et al., 2022, 2023,即RT-1
Bu et al., 2025,即Univla
Gemini Robotics Team, 2025,即Gemini robotics: Bringing ai into the physical world
Kim et al., 2024,即Openvla
Physical Intelligence, 2025,即π0.5
Yang et al., 2025,即Magma
Ye et al., 2025,即Latent Action Pretraining from Videos
Zheng et al., 2025,即TraceVLA
机器人领域中的视频生成
先前的工作表明,视频生成模型可以用于合成机器人轨迹,并在测试时通过多种方法提取可执行动作:逆动力学模型 Du et al., 2023,即Learning universal policies via text-guided video generation,将策略学习视为视频生成问题,通过文本指令引导视频扩散模型生成执行路径
Zhou et al., 2024,即Robodreamer: Learning compositional world models for robot imagination,提出了一种可组合的世界模型,允许机器人在动作执行前进行视觉想象与模拟
将光流作为稠密对应关系 Ko et al., 2024,即Learning to act from actionless videos through dense correspondences,即利用大规模无动作标签视频,通过学习像素级对应关系来提取可执行动作
或将轨迹预测作为高层规划 Du et al., 2024,即Video language planning,利用生成视频作为高层规划的视觉蓝图,辅助低层动作的精准执行
Yanget al., 2024,即Learning interactive real-world simulators,训练了一种可交互的世界模型,能预测机器人干预后真实世界的视觉变化
其他工作会生成与人类相关的视频 要么结合 3D 追踪 Liang et al.,2024,即Dreamitate: Real-world visuomotor policy learning via video generation,通过模拟未来视频序列来辅助现实世界的视觉运动策略训练 要么面向新场景和新动作------并使用点追踪目标来训练策略 Bharadhwaj et al., 2024,即Gen2act: Human video generation in novel scenarios enables,即证明了生成描述人类动作的视频能够帮助机器人泛化到全新的操作任务
Chen et al., 2025,即Large video planner enables generalizable robot control,即采用大规模视频生成模型作为通用的规划器,指导多样的机器人控制任务
最新的研究 Jang et al., 2025,即Dreamgen: Unlocking generalization in robot learning through,利用视频世界模型生成模拟数据,以解决机器人学习中高质量样本匮乏的问题
Luo et al., 2025,即Solving new tasks by adapting internet video knowledge,即展示了如何将互联网上的海量人类行为视频知识适配到具体的机器人任务中
先前的工作 Cheang et al., 2024,即Gr-2: A generative video-language-action model,集成了视频生成与动作生成的通用模型,利用互联网规模的知识进行控制
Li et al., 2025
Won et al., 2025,即Dual-stream diffusion for world-model augmented VLA,提出双流扩散模型,将世界模型(视觉预测)与 VLA(动作决策)深度融合
Wu et al., 2024,即Unleashing large-scale video generative pre-training,探讨了如何将视频生成的预训练能力直接转化为物理世界的机器人操控力
Zhao et al., 2025,即Cot-vla: Visual chain-of-thought reasoning,引入视觉思维链(Visual Chain-of-Thought),使模型能进行分步骤的视觉规划
Zheng et al., 2025
Zhu et al.,2025,Unified world models: Coupling video and action diffusion,提出联合视频与动作的统一世界模型,作为大型机器人数据集的预训练基础
从零开始或基于 VLAs 学习联合的世界建模与动作预测
而更近期的工作
*Hu etal., 2024,即Video prediction policy: A generalist robot policy,强调了预测性视觉表示在构建通用机器人策略中的关键作用
Kim et al., 2026,即Cosmos policy,系统性地研究了微调大规模视频生成模型作为闭环控制策略的方法
Liang et al., 2025,即Video generators are robot policies,验证了高性能视频生成模型在经过适当调整后,本身就能充当优秀的机器人策略
Liao et al., 2025,即Genie envisioner,提供了一个统一的平台,旨在通过视频模拟和动作预测统一机器人操控
Pai et al., 2025,*即mimic-video,提出了 WAM(世界动作模型)概念,主张动作学习应与视觉未来预测强对齐
则利用预训练的视频扩散模型,以继承丰富的视觉动态先验
作者统称这些模型为 World Action Models(WAMs),因为它们利用世界建模能力(预测未来状态)来进行动作预测
且使用 World Action Models(WAMs)这一术语,而不是 Video Action Models(VAMs),以体现视频只是世界建模目标的一种可能形式------未来的 WAMs 可能会将动作与其他预测模态对齐,例如触觉传感、力反馈或学习得到的潜在表征
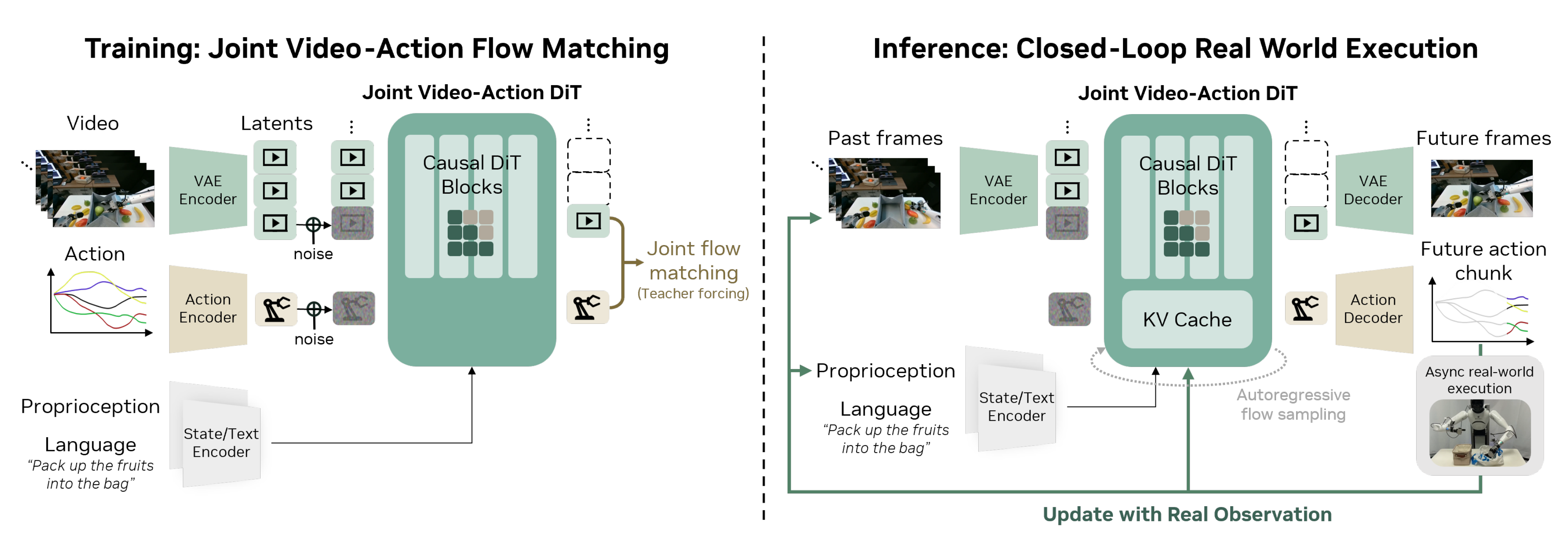
与近期的视频扩散模型和 VLAs 类似,作者采用流匹配(flow-matching)(Albergo etal.,2023;Lipman et al.,2022;Liu et al.,2022)作为训练目标(Ali et al.,2025;Team Wan,2025;Teng et al.,2025)
不同于最近的 WAMs(Kim et al.,2026;Li et al.,2025;Liao et al.,2025;Zhu etal.,2025),DreamZero 在视频模态和动作模态之间共享去噪时间步,从而在训练初期实现更快的收敛
此外,作者采用教师强制(teacher forcing)(Gao et al.,2024;Jin et al.,2024)作为训练目标;在以前面干净的片段为条件的情况下,训练模型对当前含噪的片段进行去噪




要么结合 3D 追踪