标题:GenRec: Unifying Video Generation and Recognition with Diffusion Models
作者:Zejia Weng, Xitong Yang, Zhen Xing, Zuxuan Wu, Yu-Gang Jiang
单位:1. 复旦大学计算机科学技术学院智能信息处理上海市重点实验室;2. 上海智能视觉计算协同创新中心;3. 马里兰大学计算机科学系
发表:NeurIPS 2024
论文链接 :https://arxiv.org/pdf/2408.15241
代码链接 :https://github.com/wengzejia1/GenRec
关键词:视频扩散模型、视频生成、视频识别、任务统一、时空表征、鲁棒性、随机帧条件、联合优化
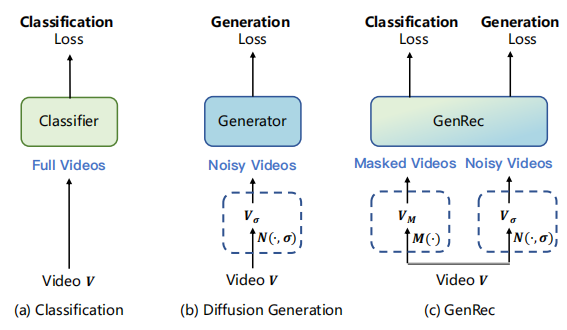
在计算机视觉领域,视频生成与视频识别长期以来被视为两个独立的研究方向,前者聚焦于从噪声或条件信号中生成符合真实世界规律的视频内容,后者则致力于从已有视频中提取语义信息以完成分类等任务。随着扩散模型在视觉生成领域的爆发式发展,研究者们逐渐意识到,扩散模型在学习生成高质量视频过程中捕获的时空先验,或许能为视频识别任务提供新的解决思路。
由复旦大学等机构提出的GenRec框架,首次实现了视频生成与识别任务的深度统一 ------ 在单个扩散模型架构下,既保留了高质量视频生成能力,又能在视频识别任务上达到业界领先水平,尤其在帧信息不完整的场景中展现出极强的鲁棒性。本文将从研究背景、核心方法、实验验证、创新价值等维度,对 GenRec 进行全面且深入的技术解读。
一、研究背景与动机
在深入 GenRec 的技术细节前,我们首先需要理解其诞生的背景 ------ 为何要 "统一" 视频生成与识别?当前研究存在哪些痛点?
1.1 扩散模型的双重潜力:从生成到理解
扩散模型(Diffusion Models)在图像与视频生成领域已取得里程碑式成果:从文本驱动的图像生成(如 Stable Diffusion)到图像条件的视频生成(如 Stable Video Diffusion, SVD),扩散模型通过学习 "噪声还原" 过程,能够捕获数据分布中的复杂时空规律。
近年来,研究发现图像扩散模型学习到的表征可迁移至图像识别、分割等理解类任务(如用 Stable Diffusion 的特征做图像分类),但视频扩散模型的潜力尚未被充分挖掘:
- 视频扩散模型是否能为视频识别提供有效的时空表征?
- 能否在保留生成能力的前提下,联合优化生成与识别任务?
- 这种统一框架是否能在帧信息有限(如早期动作预测、低带宽传输)的场景中表现更优?
这三个核心问题,正是 GenRec 框架试图解答的关键。
1.2 现有研究的两大痛点
在 GenRec 提出之前,视频生成与识别的研究存在明显割裂,主要体现在以下两点:
- 任务孤立性:生成类方法(如 SVD、SEER)仅关注视频质量,无法完成识别任务;识别类方法(如 MVD、Hiera)仅优化分类 accuracy,缺乏生成能力。
- 训练 - 推理鸿沟:
- 视频扩散模型的训练依赖 "带噪声的输入" 或 "单帧条件",以实现无约束或图像条件生成;
- 视频识别模型的训练则依赖 "完整、干净的多帧输入",以学习帧间时序关系。若直接用扩散模型的训练范式(噪声输入、单帧条件)优化识别任务,会导致模型优化困难,且训练与推理场景严重不匹配。
1.3 研究目标
GenRec 的核心目标是构建一个统一框架,实现:
- 保留高质量视频生成能力(如图像条件生成、类别条件生成);
- 在标准视频识别任务上达到业界领先精度;
- 在帧信息不完整场景(如仅观察前半帧、稀疏采样帧)中具备强鲁棒性;
- 生成与识别任务相互促进,而非相互妥协。
二、基础知识铺垫
在解读 GenRec 的核心方法前,照例先回顾其依赖的关键技术基础 ------ 视频扩散模型的基本原理,尤其是 EDM 框架与 SVD 模型。
2.1 EDM 框架:简化的扩散模型训练范式
GenRec 基于EDM(Elucidating the Design Space of Diffusion Models) 框架构建,该框架通过简化噪声调度与目标函数,大幅提升了扩散模型的训练效率与生成质量。其核心公式如下:
-
扩散过程 :将干净的 latent 特征
加入高斯噪声,得到带噪声的 latent
-
去噪目标 :训练一个去噪网络
-
得分函数关联 :去噪输出与扩散过程的 "得分函数"(描述数据分布的梯度)存在直接关联,这为后续结合生成与识别提供了理论基础:
2.2 SVD 模型:GenRec 的基础架构
GenRec 基于Stable Video Diffusion(SVD) 进行扩展,SVD 是当前主流的图像条件视频生成模型,其核心特点包括:
- ** latent 空间处理 **:通过预训练的 VAE 编码器,将视频帧逐帧映射到低维 latent 空间(减少计算量),生成后再通过 VAE 解码器还原为像素空间;
- 时空建模:采用时空 UNet(Spatial-Temporal UNet)作为去噪网络,能有效捕捉视频的帧内空间信息与帧间时序信息;
- 单帧条件生成 :仅需输入第一帧,即可生成后续连贯帧,但无法处理多帧条件或帧缺失场景,且不具备识别能力 ------ 这正是 GenRec 需要改进的核心方向。
三、GenRec 核心方法详解
GenRec 的创新点可概括为 "一个核心策略 + 两大任务统一 + 三种推理模式",即通过随机帧条件策略 打破生成与识别的训练鸿沟,通过联合损失函数优化两大任务,最终支持生成、识别、帧补全等多种下游场景。
3.1 整体架构:从输入到输出的全流程
GenRec 的完整 pipeline 如图 2 所示,可分为编码 - 处理 - 解码三个阶段,核心是在 latent 空间引入 "随机掩码" 与 "噪声结合",实现生成与识别的协同训练。
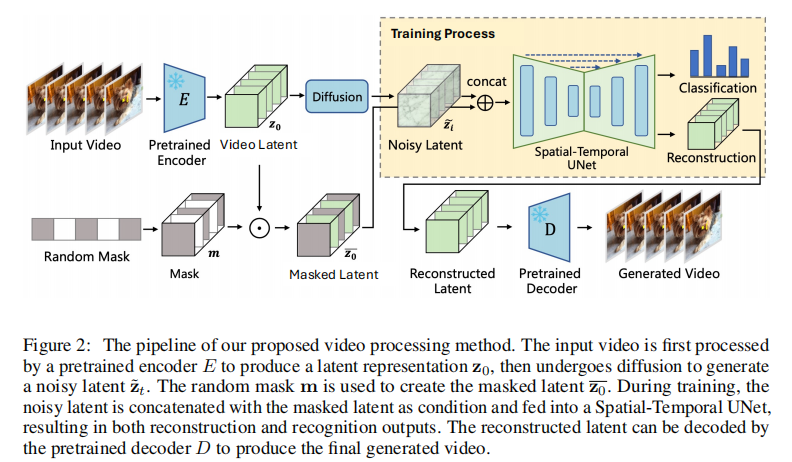
阶段 1: latent 编码与预处理
- 视频到 latent 映射 :输入视频
- 随机帧掩码(核心创新) :对
- 噪声添加 :根据 EDM 框架,对
阶段 2:时空 UNet 与双任务学习
将 "带噪声的 latent " 与 "掩码后的 latent
" 在通道维度拼接,输入到时空 UNet中,同时完成两大任务:
- 生成任务分支 :UNet 输出还原后的干净 latent
- 识别任务分支 :从 UNet 的中间层提取紧凑的时空表征
阶段 3:解码与推理
- 生成任务 :还原后的 latent
- 识别任务:分类头直接输出类别预测,无需经过解码器。
3.2 关键创新:随机帧条件策略
GenRec 能统一两大任务的核心,在于随机帧条件策略(Random-Frame Conditioning),其设计初衷是解决 "生成与识别训练范式不兼容" 的问题:
- 对生成任务:突破 SVD "仅单帧条件" 的限制,支持 "任意数量帧作为条件" 的生成(如仅给首帧、首尾帧、稀疏帧),模型需通过掩码帧的还原学习帧间依赖,生成更灵活;
- 对识别任务:训练过程中模拟 "帧缺失" 场景,模型被迫从有限帧中提取关键时空特征,提升识别鲁棒性,同时避免 "训练用完整帧、推理用缺失帧" 的鸿沟。
该策略的灵活性体现在:
- 当掩码率为 100%(无帧保留):退化为无约束视频生成;
- 当掩码率为 0%(全帧保留):退化为标准视频识别;
- 当仅保留首帧:与 SVD 的生成模式一致。
3.3 损失函数:双任务联合优化
为平衡生成与识别任务的学习,GenRec 设计了加权联合损失函数 ,公式如下:,其中:
3.4 多场景推理模式
GenRec 通过调整输入条件与网络分支,支持三种核心推理场景,覆盖生成与识别的主流需求:
1. 条件视频生成
GenRec 支持 "任意帧条件" 的生成,推理过程遵循 EDM 的随机采样策略,核心是通过迭代去噪还原完整 latent:
- 输入条件帧(如首帧、稀疏帧),转换为掩码 latent
- 初始化噪声 latent
- 按噪声强度从大到小迭代,每一步用 UNet 预测干净 latent,更新噪声 latent:
- 噪声强度降至 0 后,得到干净 latent,解码为视频。
2. 类别条件生成
当帧条件极有限(如仅 1 帧)时,生成的运动轨迹可能不可靠。GenRec 引入分类器引导(Classifier Guidance),利用识别任务的分类头引导生成方向:
- 通过贝叶斯定理,将 "类别条件" 融入去噪过程:
- 为增强引导强度,对
3. 缺失帧识别
针对 "早期动作预测"(仅观察前半帧)、"稀疏帧识别"(低带宽传输导致帧采样稀疏)等场景,GenRec 的推理方式为:
- 将不可见帧对应的 latent 掩码,仅保留可见帧的 latent
- 用随机噪声替换带噪声 latent
- 分类头直接从
四、实验验证:全面评估性能
GenRec 的实验设计覆盖生成质量、识别精度、鲁棒性、消融分析四大维度,使用的数据集包括:
- SSV2(Something-Something V2):细粒度动作识别,174 类,22 万视频;
- K400(Kinetics-400):通用动作识别,400 类,30 万视频;
- EK-100(Epic-Kitchens-100):第一视角动作识别,97 类动词 + 300 类名词;
- UCF-101:动作识别,101 类,1.3 万视频。
评估指标:
- 识别任务:Top-1 准确率;
- 生成任务:FVD(Fréchet Video Distance),值越低表示生成视频与真实视频的分布越接近,质量越高。
4.1 核心实验 1:标准任务性能对比
GenRec 与当前业界领先方法的对比结果如表 1 所示:
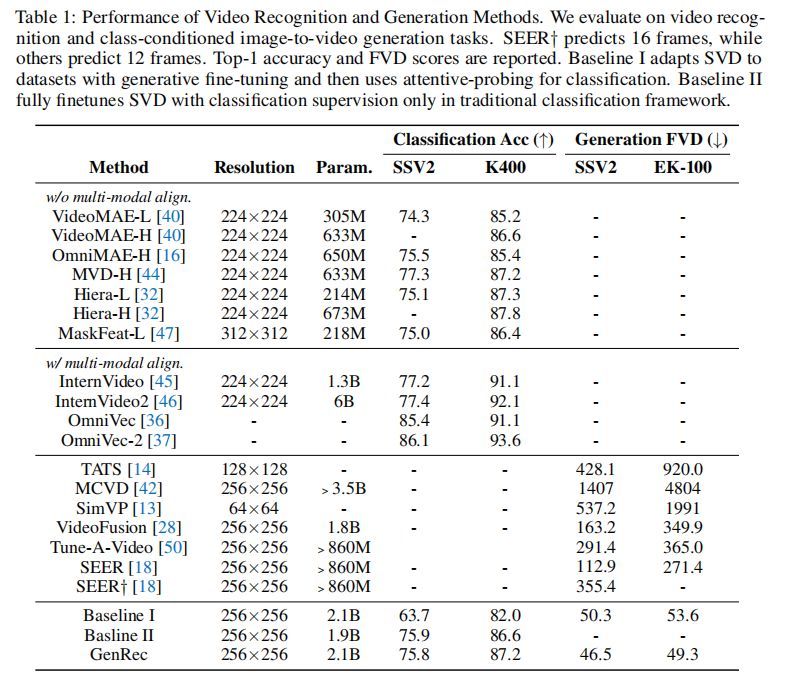
关键结论:
-
视频识别性能:
- 在 SSV2 上达到 75.8% Top-1 准确率,超过多数专用识别模型(如 MVD-H 的 75.1%);
- 在 K400 上达到 87.2% Top-1 准确率,与 Hiera(87.3%)、MVD-H(87.2%)持平,超过 SEER 等生成模型;
- 对比两个基线(Baseline I:SVD 冻结骨干做识别;Baseline II:SVD 仅训识别),GenRec 在保持生成能力的同时,识别精度更优。
-
视频生成性能:
- 类别条件图像到视频生成任务中,SSV2 上 FVD=46.5,EK-100 上 FVD=49.3,显著低于 SEER(SSV2 上 FVD=112.9);
- 需注意:GenRec 生成的是 16 帧视频,而多数方法生成 12 帧,生成难度更高,但 FVD 仍更低,证明其生成质量优势。
-
任务统一性优势:
- 现有方法要么仅能生成(如 SEER),要么仅能识别(如 MVD、Hiera);
- GenRec 是首个在两大任务上均达到业界领先的框架,实现 "1 个模型顶 2 个专用模型"。
4.2 核心实验 2:缺失帧场景鲁棒性
GenRec 的核心优势之一是在 "帧信息不完整" 场景中的鲁棒性,实验分为早期动作预测 (仅观察前 ρ 比例的帧)和稀疏帧识别(仅观察 2/3/4 帧),结果如表 2 所示:
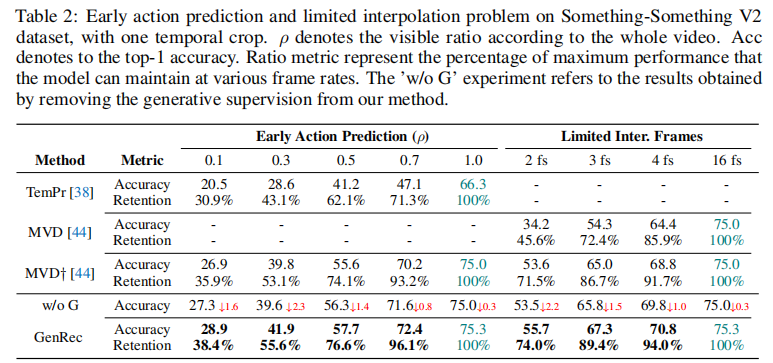
关键结论:
-
早期动作预测:
- 当仅观察 50% 帧(ρ=0.5)时,GenRec 准确率为 57.7%,保留了全帧场景(75.3%)的 76.6% 性能,远高于 MVD(保留 64.4%)、TemPr(保留 41.2%);
- 当帧比例降至 10%(ρ=0.1)时,GenRec 仍能保持 28.9% 准确率,是 TemPr(20.5%)的 1.4 倍,鲁棒性优势显著。
-
稀疏帧识别:
- 仅观察 2 帧时,GenRec 准确率为 55.7%,高于 MVD(53.6%)、TemPr(47.1%);
- 仅观察 4 帧时,GenRec 准确率达 70.8%,接近全帧性能(75.3%),证明其能从有限帧中提取关键时空特征。
-
生成监督的必要性:
- 对比 "去除生成监督的 GenRec(w/o G)" 与完整 GenRec,发现缺失生成监督后,早期预测准确率下降 2.3%(ρ=0.3 时),证明生成任务的 "帧还原学习" 能显著提升识别鲁棒性。
4.3 核心实验 3:生成与识别的关联性
为验证 "生成能力与识别能力是否相互促进",GenRec 分析了 "帧位置" 对两大任务的影响,结果如表 3 所示:
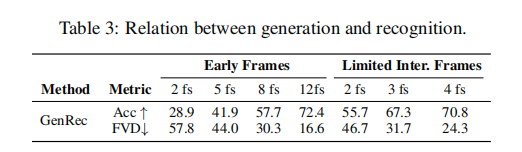
关键发现:
-
帧位置比帧数量更重要:
- 相同帧数量下,"均匀采样帧" 比 "仅前缀帧" 的识别准确率更高(如 2 帧时,均匀采样 55.7% vs 前缀 28.9%);
- 生成质量(FVD)也呈现相同趋势(2 帧均匀采样 FVD=46.7 vs 前缀 FVD=57.8),证明 "完整覆盖视频时序的帧" 更能反映视频语义。
-
生成质量可反映识别难度:
- 当仅观察 3 帧时,FVD=31.7,与观察 8 帧前缀的 FVD(30.3)接近,且识别准确率更高(67.3% vs 57.7%),说明生成质量好的场景,识别难度更低,两者存在正相关性。
4.4 消融实验:关键组件有效性
为验证各创新组件的必要性,GenRec 进行了多组消融实验:
1. 掩码比例的影响
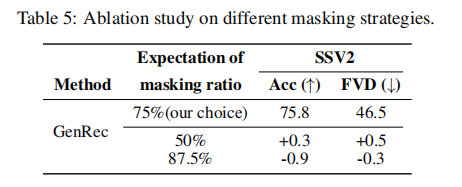
- 当掩码比例为 75%(平均保留 25% 帧)时,识别准确率最高(75.8%),FVD 最低(46.5%);
- 掩码比例过高(87.5%):识别准确率下降 0.9%(帧信息过少,特征不足);
- 掩码比例过低(50%):FVD 上升 0.3%(生成任务的帧还原压力不足,泛化性下降)。
- 结论:75% 的掩码比例是生成与识别的最优平衡点。
2. UNet 特征层选择
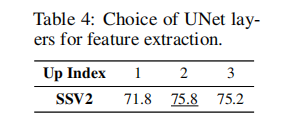
GenRec 从 UNet 的 4 个上采样块(Up Index 1-4)中选择特征提取层,结果显示:
- Up Index 2(第二个上采样块)的特征最优,识别准确率达 75.8%;
- Up Index 1(浅层):特征语义性不足,准确率仅 71.8%;
- Up Index 3(深层):特征过拟合,准确率降至 75.2%;
- 结论:中层特征兼顾语义性与泛化性,最适合视频识别。
3. 损失平衡系数的影响

- 当 γ=10 时,识别准确率(75.8%)与生成质量(FVD=46.5)均最优;
- 当 γ=0(仅训识别):生成能力完全丧失(FVD=1579.2);
- 当 γ>20(过度侧重生成):识别准确率下降至 75.5%;
- 结论:γ=10 能有效平衡两大任务,避免一方被另一方 "压制"。
4.5 可视化验证:生成质量对比
GenRec 与 SEER(当前优秀的类别条件生成模型)的生成质量对比如图 6 所示(以 "推物体""覆盖物体" 等动作为例):

关键观察:
- GenRec 生成的视频在 "动作连贯性" 与 "视觉真实性" 上均优于 SEER;
- 例如 "覆盖物体" 动作中,GenRec 能准确生成 "手将物体覆盖" 的完整时序过程,而 SEER 存在帧间动作跳跃;
- 类别条件引导有效:GenRec 生成的视频严格符合目标动作类别,无语义偏移。
五、创新价值与局限性
5.1 核心创新价值
GenRec 的技术贡献不仅在于 "性能领先",更在于其为视频理解与生成领域提供了新的研究范式:
- 任务统一范式:首次证明 "扩散模型可同时高效支持生成与识别",打破两大任务的研究壁垒,为多任务视觉模型提供新思路;
- 鲁棒性提升机制:通过 "随机帧掩码" 模拟帧缺失场景,使模型在低质量输入(如低带宽、早期预测)下的表现远超专用识别模型,更贴近真实应用场景;
- 生成 - 识别协同:生成任务的 "帧还原学习" 增强了模型对时空依赖的理解,反哺识别任务;识别任务的 "类别引导" 提升了生成任务的语义可控性,实现双向促进。
5.2 局限性与未来方向
尽管 GenRec 表现出色,但仍存在可改进的方向:
- 模型复杂度:GenRec 基于 SVD 构建,总参数量达 2.1B,训练需 8 张 A100 显卡,计算成本较高;未来可通过模型蒸馏,将其压缩为轻量级版本,适配端侧设备;
- 多模态扩展:当前 GenRec 仅支持 "帧条件" 与 "类别条件",未来可融入文本、音频等多模态信号,实现 "文本 + 图像 + 类别" 联合引导的视频生成;
- 长视频生成:GenRec 当前生成 16 帧视频(约 0.5 秒),未来需优化时空注意力机制,支持更长时长(如 5 秒以上)的视频生成,同时保持动作连贯性。
六、总结
GenRec 作为首个 "统一视频生成与识别" 的扩散模型框架,通过随机帧条件策略 与联合损失优化,成功解决了两大任务的训练鸿沟,在标准任务与鲁棒性任务上均达到业界领先水平。其核心启示在于:扩散模型学习到的 "生成先验" 不仅是生成高质量内容的工具,更是理解数据语义的关键 ------ 通过生成任务迫使模型学习更全面的时空规律,能为识别任务提供更强的泛化能力。
未来,随着多模态融合、模型压缩等技术的发展,GenRec 的范式有望扩展到更广泛的视觉任务(如视频编辑、异常检测),推动计算机视觉向 "通用智能" 更进一步。